机器学习cnn如何改变权值_五个机器学习悖论将改变您对数据的思考方式
机器学习cnn如何改变权值
Paradoxes are one of the marvels of human cognition that are hard to using math and statistics. Conceptually, a paradox is a statement that leads to an apparent self-contradictory conclusion based on the original premises of the problem. Even the best-known and well-documented paradoxes regularly fool domain experts as they fundamentally contradict common sense. As artificial intelligence(AI) looks to recreate human cognition, it’s very common for machine learning models to encounter paradoxical patterns in the training data and arrive to conclusions that seem contradictory at first glance. Today, I would like to explore some of the famous paradoxes that are commonly found in machine learning models.
悖论是人类难以理解的数学和统计数据之一。 从概念上讲,悖论是一种根据问题的原始前提得出明显的自相矛盾结论的陈述。 即使是最著名和有据可查的悖论,也经常愚弄领域专家,因为它们从根本上与常识相矛盾。 随着人工智能(AI)试图重现人类认知,机器学习模型在训练数据中遇到悖论模式并得出乍一看似乎矛盾的结论是非常普遍的。 今天,我想探讨一些机器学习模型中常见的著名悖论。
Paradoxes are typically formulated at the intersection of mathematics and philosophy. A notorious philosophical paradox is known as the Ship of Theseus questions whether an object that has had all of its components replaced remains fundamentally the same object. First, suppose that the famous ship sailed by the hero Theseus in a great battle has been kept in a harbor as a museum piece. As the years go by some of the wooden parts begin to rot and are replaced by new ones. After a century or so, all of the parts have been replaced. Is the “restored” ship still the same object as the original? Alternatively, suppose that each of the removed pieces were stored in a warehouse, and after the century, technology develops to cure their rotting and enable them to be put back together to make a ship. Is this “reconstructed” ship the original ship? And if so, is the restored ship in the harbor still the original ship too?
悖论通常是在数学和哲学的交叉点上提出的。 一个臭名昭著的哲学悖论被称为These修斯之船,它质疑一个已经将其所有组成部分都替换掉的物体是否根本上仍然是同一物体。 首先,假设英雄These修斯(Thusus)在一场激战中航行的那艘著名船已被保留在港口中作为博物馆作品。 随着时间的流逝,一些木制零件开始腐烂,并被新的木制零件取代。 一个世纪左右后,所有零件都被更换了。 “恢复”的船是否仍与原始船相同? 或者,假设每个拆下的零件都存储在仓库中,并且在本世纪之后,技术不断发展,可以治愈它们的腐烂,并使它们重新组合在一起制成一艘船。 这艘“改建”的船是原船吗? 如果是这样,港口中恢复的船舶还是原始船舶吗?

The field of mathematics and statistics if full of famous paradoxes. To use a couple of famous examples, legendary mathematician and philosopher Bertrand Russell formulated a paradox that highlighted a contradiction in some of the most powerful ideas in set theory formulated one of the greatest mathematicians of all time: Greg Cantor. In essence, the Russell paradox questions whether a “list of all lists that do not contain themselves”. The paradox arises within native set theory by considering the set of all sets that are not members of themselves. Such a set appears to be a member of itself if and only if it is not a member of itself. Hence the paradox. Some sets, such as the set of all teacups, are not members of themselves. Other sets, such as the set of all non-teacups, are members of themselves. Call the set of all sets that are not members of themselves “R.” If R is a member of itself, then by definition it must not be a member of itself. Similarly, if R is not a member of itself, then by definition it must be a member of itself. What????
数学和统计领域,如果充满着著名的悖论。 举几个著名的例子,传说中的数学家和哲学家贝特朗·罗素提出了一个悖论,突显了集合论中某些最强大的思想中的矛盾,而这是有史以来最伟大的数学家之一: 格雷格·坎托 。 本质上,罗素悖论质疑“一个不包含自己的所有列表的列表”。 在本机集合论中,通过考虑不是自身成员的所有集合的集合而产生了悖论。 当且仅当它不是其自身的成员时,这样的集合才似乎是其自身的成员。 因此自相矛盾。 某些集合(例如所有茶杯的集合)不是其成员。 其他集合,例如所有非茶杯的集合,都是它们自己的成员。 将所有非其自身成员的集合称为“ R” 。 如果R是其自身的成员,那么根据定义,它一定不能是其自身的成员。 类似地,如果R不是其自身的成员,那么根据定义,它必须是其自身的成员。 什么????

机器学习模型中的著名悖论 (Famous Paradoxes in Machine Learning Models)
As any form of knowledge building based on data, machine learning models are not exempt of cognitive paradoxes. Quite the opposite, as machine learning try to infer patterns hidden in training datasets and validate their knowledge against a specific environment, they are constantly vulnerable to paradoxical conclusions. Here are a few of the most notorious paradoxes that surface in machine learning solutions.
作为基于数据的任何形式的知识构建,机器学习模型都不能免除认知悖论。 恰恰相反,当机器学习试图推断隐藏在训练数据集中的模式并针对特定环境验证其知识时,它们总是容易受到悖论性结论的攻击。 这是机器学习解决方案中出现的一些最臭名昭著的悖论。
辛普森悖论 (The Simpson’s Paradox)
Named after British mathematician Edward Simpson, the Simpson’s Paradox describes a phenomenon in which a trend that is very apparent several groups of data dissipates as the data within those groups in combined. A real-life case of the paradox happened in 1973. Admission rates were investigated at the University of Berkeley’s graduate schools. The university was sued by women for the gender gap in admissions. The results of the investigation were: When each school was looked at separately (law, medicine, engineering etc.), women were admitted at a higher rate than men! However, the average suggested that men were admitted at a much higher rate than women. How is that possible?
以英国数学家爱德华·辛普森(Edward Simpson)的名字命名的辛普森悖论描述了一种现象,其中一种趋势非常明显,几组数据随着这些组内数据的组合而消失。 1973年发生了一个真实的悖论案例。伯克利大学的研究生院对入学率进行了调查。 妇女因录取中的性别差距而起诉该大学。 调查的结果是:当分别检查每所学校(法律,医学,工科等)时,女生的入学率高于男生! 但是,平均数表明,男性的入学率比女性高得多。 那怎么可能?

The explanation to the previous use case is that a simple average doesn’t account for the relevance of a specific group within the overall dataset. In this specific example, women applied in large numbers to schools with low admission rates: Like law and medicine. These schools admitted less than 10 percent of students. Therefore the percentage of women accepted was very low. Men, on the other hand, tended to apply in larger numbers to schools with high admission rates: Like engineering, where admission rates are about 50%. Therefore the percentage of men accepted was very high.
对前一个用例的解释是,简单的平均值并不能说明整个数据集中特定组的相关性。 在这个具体例子中,妇女大量申请入学率低的学校:法律和医学一样。 这些学校录取的学生不到10%。 因此,接受女性的比例非常低。 另一方面,男人往往更多地被录取率高的学校使用:像工程学一样,录取率约为50%。 因此,接受男人的比例很高。
In the context of machine learning, many unsupervised learning algorithms infer patterns different training datasets that result in contradictions when combined across the board.
在机器学习的背景下,许多无监督的学习算法会推断出不同的训练数据集的模式,这些数据集在整体组合时会产生矛盾。
布莱斯悖论 (The Braess’s Paradox)
This paradox was proposed in 1968 by German mathematician Dietrich Braes. Using an example of congested traffic networks, Braes explained that, counterintuitively, adding a road to a road network could possibly impede its flow (e.g. the travel time of each driver); equivalently, closing roads could potentially improve travel times. Braess reasoning is based on the fact that, in a Nash equilibrium game, drivers have no incentive to change their routes. In terms of game theory, an individual has nothing to gain from applying new strategies if others stick to the same ones. Here in the case of drivers, a strategy is a route taken. In the case of Braess’s paradox, drivers will continue to switch until they reach Nash equilibrium despite the reduction in overall performance. So, counter-intuitively, closing the roads might ease the congestion.
这种悖论是由德国数学家Dietrich Braes于1968年提出的。 布雷斯以拥挤的交通网络为例,解释说,与直觉相反,在道路网络中增加道路可能会阻碍其流量(例如,每个驾驶员的出行时间); 同样,封闭道路可能会改善出行时间。 Braess推理基于以下事实:在Nash均衡博弈中,驾驶员没有动力改变路线。 就博弈论而言,如果其他人坚持相同的策略,则个人从采用新策略中不会获得任何收益。 在这里,对于驾驶员而言,策略是采取的路线。 在Braess悖论的情况下,尽管整体表现有所下降,但驾驶员将继续转换直到达到Nash平衡。 因此,违反直觉,关闭道路可能会缓解交通拥堵。
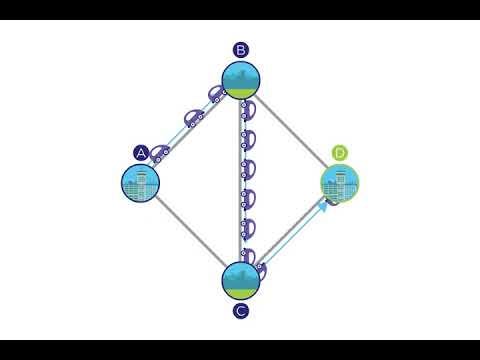
The Braess’s Paradox is very relevant in autonomous, multi-agent reinforcement learning scenarios in which the models needs to reward agents based on specific decisions in unknown environments.
Braess悖论在自主的多主体强化学习场景中非常相关,在该场景中,模型需要根据未知环境中的特定决策来奖励主体。
莫拉韦克悖论 (The Moravec’s Paradox)
Hans Moravec can be considered one of the greatest AI thinkers of the last few decades. In the 1980s, Moravec formulated a counter-intuitive proposition to the way AI models acquire knowledge. The Moravec Paradox states that, contrary to popular believe, high-level reasoning requires less computation than low-level unconscious cognition. This is an empirical observation that goes against the notion that greater computational capability leads to more intelligent systems.
汉斯·莫拉维克(Hans Moravec)被认为是过去几十年来最伟大的AI思想家之一。 在1980年代,Moravec对AI模型获取知识的方式提出了违反直觉的主张。 莫拉维克悖论指出,与普遍的看法相反,高级推理比低级无意识认知所需的计算更少。 这是一个经验性观察,与以下观点相反:更高的计算能力会导致更智能的系统。
A simpler way to frame the Moravec’s Paradox is that AI models can do incredibly complex statistical and data inference tasks that result impossible for humans. However, many tasks that result trivial for humans like grabbing an object will require expensive AI models. As Moravec writes, “it is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility”.
构造Moravec悖论的一种更简单的方法是,AI模型可以执行极其复杂的统计和数据推断任务,而这对于人类来说是不可能的。 但是,许多对人类来说都是微不足道的任务,例如抓住一个物体,将需要昂贵的AI模型。 正如Moravec所说,“使计算机在智力测验或游戏检查中表现出成年人水平的性能相对容易,而就感知和移动性而言,很难或不可能赋予他们一岁的技能”。

From the perspective of machine learning, the Moravec’s Paradox is very applicable in aspect of transfer learning that look to generalize knowledge across different machine learning models. Additionally, the Moravec’s Paradox teaches us that some of the best applications of machine intelligence will come as a combination of humans and algorithms.
从机器学习的角度来看,Moravec的悖论在转移学习方面非常适用,该学习旨在跨不同的机器学习模型概括知识。 此外,Moravec的悖论告诉我们,机器智能的一些最佳应用将是人类和算法的结合。
准确性悖论 (The Accuracy Paradox)
Directly related to machine learning, the Accuracy Paradox states that, counterintuitively, accuracy is not always a good metric to classify the effectiveness of predictive models. How is that for a confusing statement? The Accuracy Para has its roots in imbalanced training datasets. For instance, in a dataset in which the incidence of category A is dominant, being found in 99% of cases, then predicting that every case is category A will have an accuracy of 99% is completely misleading.
与机器学习直接相关的“准确性悖论”指出,与直觉相反,准确性并非总是对预测模型的有效性进行分类的好指标。 对于一个令人困惑的陈述,这是怎么回事? Accuracy Para起源于不平衡的训练数据集。 例如,在一个类别为A的事件占主导地位的数据集中,在99%的案例中均被发现,然后预测每个案例均为类别A的准确性将达到99%,这完全是误导性的。
A simpler way to understand the Accuracy Paradox is to find the balance between precision and recall in machine learning models. In machine learning algorithms, precision is often defined as measuring what fraction of your predictions for the positive class are valid. It is formulated by (True Positives / True Positives + False Positives). Complementary, the recall metric measures how often your predictions actually capture the positive class. It is formulated by (True Positives / True Positives + False Negatives).
理解“准确性悖论”的一种简单方法是在机器学习模型中找到精度和召回率之间的平衡。 在机器学习算法中,精度通常被定义为衡量您对肯定类别的预测中有多少有效。 它由(真肯定/真肯定+假肯定)表示。 作为补充,召回指标用于衡量您的预测多长时间获得一次肯定的评价。 它由(真肯定/真肯定+假否定)表示。

In many machine learning models, the balance between precision and recall results a better metric for accuracy. For instance, in case of an algorithm for fraud detection recall is a more important metric. It is obviously important to catch every possible fraud even if it means that the authorities might need to go through some false positives. On the other hand, if the algorithm is created for sentiment analysis and all you need is a high-level idea of emotions indicated in tweets then aiming for precision is the way to go.
在许多机器学习模型中,精度和召回率之间的平衡导致了更好的精度指标。 例如,在欺诈检测算法的情况下,召回是更重要的指标。 即使这意味着当局可能需要进行一些误报,显然也必须抓住一切可能的欺诈行为。 另一方面,如果创建用于情感分析的算法,而您所需要的只是对推文中所指示的情绪的高级理解,那么追求精确性就是路要走。
学习能力-戈德尔悖论 (The Learnability-Godel Paradox)
Saving the most controversial for last, this is a very recent paradox that was published in a research paper earlier this year. The paradox links the ability of a machine learning model to learn to one of the most controversial theories of mathematics: Gödel’s Incompleteness Theorem.
最后,最有争议的是这是今年早些时候发表在研究论文上的一个最新悖论。 悖论将机器学习模型的学习能力与最有争议的数学理论之一: 哥德尔不完全性定理 。
Kurt Gödel is one of the brightest mathematicians of all time and one that pushed the boundaries of philosophy, physics and mathematics like a few of its predecessors. In 1931, Gödel published his two incompleteness theorems that essentially say some statements cannot be proved either true or false using standard mathematical language. In other words, math is an insufficient language to understand some aspects of the universe. The theorems have come to be known as Gödel ‘s continuum hypothesis.
库尔特·哥德尔(KurtGödel)是有史以来最杰出的数学家之一,并且像其几位前辈一样,推动了哲学,物理学和数学的发展。 1931年,哥德尔发表了他的两个不完全性定理 ,这些定理本质上说,使用标准数学语言无法证明某些陈述是对还是错。 换句话说,数学不足以理解宇宙的某些方面。 这些定理已被称为哥德尔连续统假设。
In a recent work, AI researchers from the Israel Institute of Technology linked Gödel’s continuum hypothesis to the learnability of a machine learning model. In a paradoxical statement that challenges all common wisdom, the researchers define the notion of a learnability limbo. Essentially, the researchers go on to show that if the continuum hypothesis is true, a small sample is sufficient to make the extrapolation. But if it is false, no finite sample can ever be enough. This way they show that the problem of learnability is equivalent to the continuum hypothesis. Therefore, the learnability problem, too, is in a state of limbo that can be resolved only by choosing the axiomatic universe.
在最近的工作中,以色列理工学院的AI研究人员将Gödel的连续体假设与机器学习模型的可学习性联系在一起。 在挑战所有常识的矛盾陈述中,研究人员定义了可学习性的概念。 从本质上讲,研究人员继续表明,如果连续假设是正确的,则仅需少量样本就可以进行推断。 但是,如果它是错误的,则没有任何有限的样本就足够了。 通过这种方式,他们表明可学习性问题等同于连续性假设。 因此,可学习性问题也处于困境,只能通过选择公理宇宙来解决。
In simple terms, the mathematical proofs in the study show that AI problems are subjected to Gödel ‘s continuum hypothesis which means that many problems might be effectively unsolvable by AI. Although this paradox has very little applications to real world AI problems today, it will be paramount to the evolution of the field in the near future.
简而言之,研究中的数学证明表明,人工智能问题服从于哥德尔的连续假设,这意味着许多问题可能是人工智能无法有效解决的。 尽管这种悖论在当今现实世界中的AI问题中几乎没有应用,但在不久的将来对领域的发展至关重要。
Paradoxes are omnipresent in machine learning problems in the real world. You can argue that as, algorithms don’t have a notion of common sense, they might be immune to statistical paradoxes. However, given that most machine learning problems require human analysis and interventions and are based on human-curated datasets, we are going to live in an universe of paradoxes for quite some time.
在现实世界中,机器学习问题中普遍存在悖论。 您可以辩称,由于算法没有常识,它们可能不受统计悖论的影响。 但是,鉴于大多数机器学习问题都需要人工分析和干预,并且都是基于人工编排的数据集,因此我们将在相当长的一段悖论中生存。
翻译自: https://medium.com/dataseries/five-machine-learning-paradoxes-that-will-change-the-way-you-think-about-data-3b82513482b8
机器学习cnn如何改变权值
http://www.taodudu.cc/news/show-1873980.html
相关文章:
- DeepStyle(第2部分):时尚GAN
- 肉体之爱的解释圣经_可解释的AI的解释
- 机器学习 神经网络 神经元_神经网络如何学习?
- 人工智能ai应用高管指南_理解人工智能指南
- 机器学习 决策树 监督_监督机器学习-决策树分类器简介
- ai人工智能数据处理分析_建立数据平台以实现分析和AI驱动的创新
- 极限学习机和支持向量机_极限学习机的发展
- 人工智能时代的危机_AI信任危机:如何前进
- 不平衡数据集_我们的不平衡数据集
- 建筑业建筑业大数据行业现状_建筑—第4部分
- 线性分类模型和向量矩阵求导_自然语言处理中向量空间模型的矩阵设计
- 离散数学期末复习概念_复习第1部分中的基本概念
- 熵 机器学习_理解熵:机器学习的金标准
- heroku_如何通过5个步骤在Heroku上部署机器学习UI
- detr 历史解析代码_视觉/ DETR变压器
- 人工神经网络方法学习步长_人工神经网络-一种直观的方法第1部分
- 机器学习 声音 分角色_机器学习对儿童电视节目角色的痴迷
- 遗传算法是一种进化算法_一种算法的少量更改可以减少种族主义的借贷
- 无监督模型 训练过程_监督使用训练模型
- 端到端车道线检测_弱监督对象检测-端到端培训管道
- feynman1999_AI Feynman 2.0:从数据中学习回归方程
- canny edge_Canny Edge检测器简介
- 迄今为止2020年AI的奋斗与成功
- 机器学习算法应用_机器学习:定义,类型,算法,应用
- 索尼爱立信k510驱动_未来人工智能驱动的电信网络:爱立信案例研究
- ai驱动数据安全治理_利用AI驱动的自动协调器实时停止有毒信息
- ai人工智能_古典AI的简要史前
- 正确的特征点匹配对_了解如何正确选择特征
- 在Covid-19期间测量社交距离
- nlp gpt论文_GPT-3是未来。 但是NLP目前可以做什么?
机器学习cnn如何改变权值_五个机器学习悖论将改变您对数据的思考方式相关推荐
- 如何理解CNN中的权值共享
记录一下深度学习中CNN中的权值共享 首先,卷积网络的核心思想是将:局部感受野.权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移.尺度.形变不变性. 通俗理解,所 ...
- java二叉树求权值_百度笔试题目:二叉树路径权值和【转】
数据结构课程 百度笔试题目: 给出一个二叉树,和一个整型值,求出二叉树上所有从根到叶子的路径,并且此路径上各个节点的权值之和等于给出的整型值. 解题思路: 根据二叉树的先根遍历思想,通过一个栈保存从根 ...
- java二叉树求权值_二叉树中的权值是什么?
展开全部 二叉树中的权值就是对叶子结点赋予的一个有意义的数量值. 一棵深度为k,且有2^k-1个节点的二叉树,32313133353236313431303231363533e58685e5aeb93 ...
- 机器学习中用到的概率知识_山顶洞人学机器学习之——几种常见的概率分布
机器学习是实现人工智能的重要技术之一.在学习机器学习的过程中,必须要掌握一些基础的数学与统计知识.之前的两篇文章我们分别讲述了中心极限定理与大数定律,它们是数据分析的理论基础.今天我们来介绍几种常见的 ...
- python 直方图每个bin中的值_使用python中的matplotlib进行绘图分析数据
matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中. 它的文档相当完备, ...
- ios 获取一个枚举的所有值_凯哥带你从零学大数据系列之Java篇---第十一章:枚举...
温馨提示:如果想学扎实,一定要从头开始看凯哥的一系列文章(凯哥带你从零学大数据系列),千万不要从中间的某个部分开始看,知识前后是有很大关联,否则学习效果会打折扣. 系列文章第一篇是拥抱大数据:凯哥带你 ...
- python字典获取关联值_【Python实战12】使用字典关联数据
现在我的手里有了新的一组数据,数据内容如下: james.txt: James Lee,2002-3-14,2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22,2 ...
- 几百万的数据查找重复值_如何快速查找出Excel中的重复数据,多角度分析
如何多角度查找出重复数据,是数据分析中必不可少的一项.办公中经常遇到重复数据,想要标识出来,再进一步分析,避免数据出错.像人事部门,经常遇到同名不同人这种情况,如果工资发错了,很容易出现大问题,如何来 ...
- 苹果改变手机型号_苹果的低碳铝将改变气候
苹果改变手机型号 By Maria Gallucci 玛丽亚·加卢奇(Maria Gallucci) When Apple announced new climate goals last week, ...
- angularjs 获取复选框的值_基于uFUN开发板的心率计(一)DMA方式获取传感器数据
前言 从3月8号收到板子,到今天算起来,uFUN到手也有两周的时间了,最近利用下班后的时间,做了个心率计,从单片机程序到上位机开发,到现在为止完成的差不多了,实现很简单,uFUN开发板外加一个Puls ...
最新文章
- Java学习总结:39(反射机制)
- WP7版社交程序现真容,与Bing Map的完美结合。
- html5游戏暂停按钮,HTML5 圆形进度控制(播放、暂停)按钮
- fgetcsv php,PHP - fgetcsv - 分隔符被忽略?
- 通过ssh证书远程登录
- html5swf小游戏源码,亲测可用120个H5小游戏实例源码
- 小学计算机课的微案例,小学信息技术教学案例分析
- 自定义 Chrome (谷歌浏览器) 主题
- 单相全控桥有源逆变电路matlab仿真,单相桥式全控整流与有源逆变电路的MATLAB仿真设计...
- 计算机中sqrt函数是什么意思,sqrt是什么函数
- win10服务器系统要设置要密码是什么,云服务器win10系统初始密码
- 4 个方法养成大神级 “反内耗“ 体质
- dplyr包 mutate 和 transmute 函数
- 基于Revit铝模板设计-区域配模
- 吉尔电子烟获1200万天使轮融资 1
- 平行世界真的存在吗?镜像宇宙的三个科学奥秘
- 《人生的智慧》读后感
- Hibernate-validator(HV)异常
- RoBERTa VS BERT
- C#重要知识点在游戏开发中的应用
热门文章
- linux系统学习(常用命令)
- OpenCV_轮廓例子
- Python机器登陆新浪微博代码示例
- 第11章 支撑向量机 SVM 学习笔记 上
- 如何选择适合自己的相机?
- latex减少图片和图片解释文字之间的距离
- HTC 手柄扣动板机出现射线以及碰撞点用小球表示
- Atitit db deadlock prblm cause and solu 数据库死锁原因与解决 在数据库中有两种基本的锁类型:排它锁(Exclusive Locks,即X锁)和共享
- Atitit 源码语句解析结构 目录 1.1. 栈帧(stack frame).每个独立的栈帧一般包括: 1 1.2. 局部变量表(Local Variable Table) 2 2. ref 2
- Atitit 大数据体系树 艾提拉著 数据采集 gui自动化 爬虫 Nui自动化 Ocr技术 Tts语音处理 文档处理(office zip等) html文档处理解析 转换与处理