【转】Senior Data Structure · 浅谈线段树(Segment Tree)
本文章转自洛谷 原作者: _皎月半洒花
一、简介线段树
ps: _此处以询问区间和为例。实际上线段树可以处理很多符合结合律的操作。(比如说加法,a[1]+a[2]+a[3]+a[4]=(a[1]+a[2])+(a[3]+a[4]))
线段树之所以称为“树”,是因为其具有树的结构特性。线段树由于本身是专门用来处理区间问题的(包括RMQ、RSQ问题等。
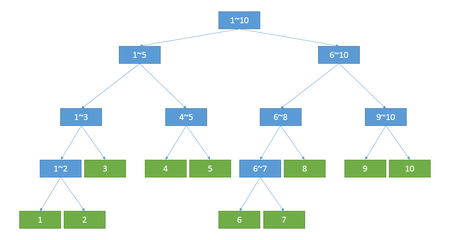
图片来源于互联网。
对于每一个子节点而言,都表示整个序列中的一段子区间;对于每个叶子节点而言,都表示序列中的单个元素信息;子节点不断向自己的父亲节点传递信息,而父节点存储的信息则是他的每一个子节点信息的整合。
有没有觉得很熟悉?对,线段树就是分块思想的树化,或者说是对于信息处理的二进制化——用于达到O(logn)级别的处理速度,log以2为底。(其实以几为底都只不过是个常数,可忽略)。而分块的思想,则是可以用一句话总结为:通过将整个序列分为有穷个小块,对于要查询的一段区间,总是可以整合成k个所分块与m个单个元素的信息的并(0<=k,m<=√n)。但普通的分块不能高效率地解决很多问题,所以作为log级别的数据结构,线段树应运而生。
Extra Tips
其实,虽然线段树的时间效率要高于分块但是实际上分块的总合并次数不会超过√n但是线段树在最坏情况下的合并次数显然是要大于这个时间效率的qwq。
但是毕竟也只是一个很大的常数而已
However,虽说如此,分块的应用范围还是要广于线段树的,因为虽然线段树好像很快,但是它只能维护带有结合律的信息,比如区间max/min、sum、xor之类的,但是不带有结合律的信息就不能维护(且看下文分解);而分块则灵活得多,可以维护很多别的东西,因为实际上分块的本质就是优雅的暴力qwq。
其实越暴力的算法可以支持的操作就越多、功能性就越强呐!你看n^2的暴力几乎什么都可以维护
二、逐步分析线段树的构造实现
1、建树与维护
由于二叉树的自身特性,对于每个父亲节点的编号i,他的两个儿子的编号分别是2i和2i+1,所以我们考虑写两个O(1)的取儿子函数:
1 int n;
2 int ans[MAXN*4];
3
4 inline int ls(int p){return p<<1;}//左儿子
5 inline int rs(int p){return p<<1|1;}//右儿子 Extra Tips
1、此处的inline可以有效防止无需入栈的信息入栈,节省时间和空间。
2、二进制位左移一位代表着数值*2,而如果左移完之后再或上1,由于左移完之后最后一位二进制位上一定会是0,所以|1等价于+1。
用二进制运算不是为了装X,相信我,会快的!
那么根据线段树的服务对象,可以得到线段树的维护:
1 void push_up_sum(int p){
2 t[p]=t[lc(p)]+t[rc(p)];
3 }// 向上不断维护区间操作
4
5 void push_up_min(int p){//max and min
6 t[p]=min(t[lc(p)],t[rc(p)]);
7 //t[p]=max(t[lc(p)],t[rc(p)]);
8 }此处一定要注意,push up操作的目的是为了维护父子节点之间的逻辑关系。当我们递归建树时,对于每一个节点我们都需要遍历一遍,并且电脑中的递归实际意义是先向底层递归,然后从底层向上回溯,所以开始递归之后必然是先去整合子节点的信息,再向它们的祖先回溯整合之后的信息。(这其实是正确性的证明啦)
呐,我们在这儿就能看出来,实际上push_up是在合并两个子节点的信息,所以需要信息满足结合律!
那么对于建树,由于二叉树自身的父子节点之间的可传递关系,所以可以考虑递归建树(emmmm之前好像不小心剧透了qwq),并且在建树的同时,我们应该维护父子节点的关系:
void build(ll p,ll l,ll r)
{if(l==r){ans[p]=a[l];return ;}//如果左右区间相同,那么必然是叶子节点啦,只有叶子节点是被真实赋值的ll mid=(l+r)>>1;build(ls(p),l,mid);build(rs(p),mid+1,r);
//此处由于我们采用的是二叉树,所以对于整个结构来说,可以用二分来降低复杂度,否则树形结构则没有什么明显的优化
push_up(p);
//此处由于我们是要通过子节点来维护父亲节点,所以pushup的位置应当是在回溯时。
} 2、接下来谈区间修改
为什么不讨论单点修改呢qwq?因为其实很显然,单点修改就是区间修改的一个子问题而已,即区间长度为1时进行的区间修改操作罢了qwq
那么对于区间操作,我们考虑引入一个名叫“lazy tag”(懒标记)的东西——之所以称其“lazy”,是因为原本区间修改需要通过先改变叶子节点的值,然后不断地向上递归修改祖先节点直至到达根节点,时间复杂度最高可以到达O(nlogn)的级别。但当我们引入了懒标记之后,区间更新的期望复杂度就降到了O(logn)的级别且甚至会更低.
(1)首先先来从分块思想上解释如何区间修改:
分块的思想是通过将整个序列分为有穷个小块,对于要查询的一段区间,总是可以整合成kk个所分块与m个单个元素的信息的并(0<=k,m<=logn)(小小修改了一下的上面的前言qwq)
那么我们可以反过来思考这个问题:对于一个要修改的、长度为l的区间来说,总是可以看做由一个长度为2^log(⌊n⌋)和剩下的元素(或者小区间组成)。那么我们就可以先将其拆分成线段树上节点所示的区间,之后分开处理:
如果单个元素被包含就只改变自己,如果整个区间被包含就修改整个区间
其实好像这个在分块里不是特别简单地实现,但是在线段树里,无论是元素还是区间都是线段树上的一个节点,所以我们不需要区分区间还是元素,加个判断就好。
(2)懒标记的正确打开方式
首先,懒标记的作用是记录每次、每个节点要更新的值,也就是delta,但线段树的优点不在于全记录(全记录依然很慢qwq),而在于传递式记录:
整个区间都被操作,记录在公共祖先节点上;只修改了一部分,那么就记录在这部分的公共祖先上;如果四环以内只修改了自己的话,那就只改变自己。
After that,如果我们采用上述的优化方式的话,我们就需要在每次区间的查询修改时pushdown一次,以免重复或者冲突或者爆炸qwq
那么对于pushdown而言,其实就是纯粹的pushup的逆向思维(但不是逆向操作): 因为修改信息存在父节点上,所以要由父节点向下传导lazy tag
那么问题来了:怎么传导pushdown呢?这里很有意思,开始回溯时执行pushup,因为是向上传导信息;那我们如果要让它向下更新,就调整顺序,在向下递归的时候pushdown不就好惹~qwqqwq:
1 inline void f(ll p,ll l,ll r,ll k)
2 {
3 tag[p]=tag[p]+k;
4 ans[p]=ans[p]+k*(r-l+1);
5 //由于是这个区间统一改变,所以ans数组要加元素个数次啦
6 }
7 //我们可以认识到,f函数的唯一目的,就是记录当前节点所代表的区间
8 inline void push_down(ll p,ll l,ll r)
9 {
10 ll mid=(l+r)>>1;
11 f(ls(p),l,mid,tag[p]);
12 f(rs(p),mid+1,r,tag[p]);
13 tag[p]=0;
14 //每次更新两个儿子节点。以此不断向下传递
15 }
16 inline void update(ll nl,ll nr,ll l,ll r,ll p,ll k)
17 {
18 //nl,nr为要修改的区间
19 //l,r,p为当前节点所存储的区间以及节点的编号
20 if(nl<=l&&r<=nr)
21 {
22 ans[p]+=k*(r-l+1);
23 tag[p]+=k;
24 return ;
25 }
26 push_down(p,l,r);
27 //回溯之前(也可以说是下一次递归之前,因为没有递归就没有回溯)
28 //由于是在回溯之前不断向下传递,所以自然每个节点都可以更新到
29 ll mid=(l+r)>>1;
30 if(nl<=mid)update(nl,nr,l,mid,ls(p),k);
31 if(nr>mid) update(nl,nr,mid+1,r,rs(p),k);
32 push_up(p);
33 //回溯之后
34 }对于复杂度而言,由于完全二叉树的深度不超过logn,那么单点修改显然是O(logn)的,区间修改的话,由于我们的这个区间至多分lognlogn个子区间,对于每个子区间的查询是O(1)的,所以复杂度自然是O(logn)不过带一点常数
3、那么对于区间查询
没什么好说的,由于是信息的整合,所以还是要用到分块思想,我实在是不想再码一遍了qwq
1 ll query(ll q_x,ll q_y,ll l,ll r,ll p)
2 {
3 ll res=0;
4 if(q_x<=l&&r<=q_y)return ans[p];
5 ll mid=(l+r)>>1;
6 push_down(p,l,r);
7 if(q_x<=mid)res+=query(q_x,q_y,l,mid,ls(p));
8 if(q_y>mid) res+=query(q_x,q_y,mid+1,r,rs(p));
9 return res;
10 }最后贴高清无码的标程:
(还有,输入大数据一定不要用不加优化的cin/cout啊)
1 #include<iostream>
2 #include<cstdio>
3 #define MAXN 1000001
4 #define ll long long
5 using namespace std;
6 unsigned ll n,m,a[MAXN],ans[MAXN<<2],tag[MAXN<<2];
7 inline ll ls(ll x)
8 {
9 return x<<1;
10 }
11 inline ll rs(ll x)
12 {
13 return x<<1|1;
14 }
15 void scan()
16 {
17 cin>>n>>m;
18 for(ll i=1;i<=n;i++)
19 scanf("%lld",&a[i]);
20 }
21 inline void push_up(ll p)
22 {
23 ans[p]=ans[ls(p)]+ans[rs(p)];
24 }
25 void build(ll p,ll l,ll r)
26 {
27 tag[p]=0;
28 if(l==r){ans[p]=a[l];return ;}
29 ll mid=(l+r)>>1;
30 build(ls(p),l,mid);
31 build(rs(p),mid+1,r);
32 push_up(p);
33 }
34 inline void f(ll p,ll l,ll r,ll k)
35 {
36 tag[p]=tag[p]+k;
37 ans[p]=ans[p]+k*(r-l+1);
38 }
39 inline void push_down(ll p,ll l,ll r)
40 {
41 ll mid=(l+r)>>1;
42 f(ls(p),l,mid,tag[p]);
43 f(rs(p),mid+1,r,tag[p]);
44 tag[p]=0;
45 }
46 inline void update(ll nl,ll nr,ll l,ll r,ll p,ll k)
47 {
48 if(nl<=l&&r<=nr)
49 {
50 ans[p]+=k*(r-l+1);
51 tag[p]+=k;
52 return ;
53 }
54 push_down(p,l,r);
55 ll mid=(l+r)>>1;
56 if(nl<=mid)update(nl,nr,l,mid,ls(p),k);
57 if(nr>mid) update(nl,nr,mid+1,r,rs(p),k);
58 push_up(p);
59 }
60 ll query(ll q_x,ll q_y,ll l,ll r,ll p)
61 {
62 ll res=0;
63 if(q_x<=l&&r<=q_y)return ans[p];
64 ll mid=(l+r)>>1;
65 push_down(p,l,r);
66 if(q_x<=mid)res+=query(q_x,q_y,l,mid,ls(p));
67 if(q_y>mid) res+=query(q_x,q_y,mid+1,r,rs(p));
68 return res;
69 }
70 int main()
71 {
72 ll a1,b,c,d,e,f;
73 scan();
74 build(1,1,n);
75 while(m--)
76 {
77 scanf("%lld",&a1);
78 switch(a1)
79 {
80 case 1:{
81 scanf("%lld%lld%lld",&b,&c,&d);
82 update(b,c,1,n,1,d);
83 break;
84 }
85 case 2:{
86 scanf("%lld%lld",&e,&f);
87 printf("%lld\n",query(e,f,1,n,1));
88 break;
89 }
90 }
91 }
92 return 0;
93 }转载于:https://www.cnblogs.com/DarkValkyrie/p/10846324.html
【转】Senior Data Structure · 浅谈线段树(Segment Tree)相关推荐
- 【算法微解读】浅谈线段树
浅谈线段树 (来自TRTTG大佬的供图) 线段树个人理解和运用时,认为这个是一个比较实用的优化算法. 这个东西和区间树有点相似,是一棵二叉搜索树,也就是查找节点和节点所带值的一种算法. 使用线段树可以 ...
- 浅谈线段树(Segment Tree)
线段树的概念与性质 线段树首先是一棵树,而且是二叉树.树上的每个节点对应于一个区间[a,b],a,b通常为整数.同一层的节点所代表的区间,互相不重叠.并且同一层的区间加起来是连续的区间,叶子节点的区间 ...
- 线段树(Segment Tree)
1.概述 线段树,也叫区间树,是一个完全二叉树,它在各个节点保存一条线段(即"子数组"),因而常用于解决数列维护问题,基本能保证每个操作的复杂度为O(lgN). 线段树是一种二叉搜 ...
- BZOJ.4695.最假女选手(线段树 Segment tree Beats!)
题目链接 区间取\(\max,\ \min\)并维护区间和是普通线段树无法处理的. 对于操作二,维护区间最小值\(mn\).最小值个数\(t\).严格次小值\(se\). 当\(mn\geq x\)时 ...
- 从MySQL Bug#67718浅谈B+树索引的分裂优化
从MySQL Bug#67718浅谈B+树索引的分裂优化 1月 6th, 2013 发表评论 | Trackback 问题背景 今天,看到Twitter的DBA团队发布了其最新的MySQL分支:Cha ...
- 浅谈oracle树状结构层级查询
oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只要精通数据库那么对于java开发你 ...
- 浅谈oracle树状结构层级查询测试数据
浅谈oracle树状结构层级查询 oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的,虽然我是一个java程序开发者,我一直觉得只 ...
- C语言实现段树segment tree(附完整源码)
C语言实现段树segment tree 段树结构体定义 实现以下6个接口 完整实现和main测试源码 段树结构体定义 typedef struct segment_tree {void *root; ...
- 浅谈虚树(虚仙人掌)
虚树是什么? 在 OI 比赛中,有这样一类题目:给定一棵树,另有多次询问,每个询问给定一些关键点,需要求这些关键点之间的某些信息.询问数可能很多,但满足所有询问中关键点数量的总和比较小. 由于询问数可 ...
最新文章
- linux文件操作函数程序,linux 文件操作函数
- Redux 学习总结 (React)
- HTML DOM appendChild() 方法
- Binder Driver浅析:Binder线程池
- nyc检测Javascript代码覆盖率
- 正则表达式——获取指定IP的物理地址
- Hadoop jobhistory历史服务器
- spring cloud(一) 副 consul
- 用于函数优化的一维 (1D) 测试函数
- 极客大学架构师训练营 大数据 三驾马车 GFS、MapReduce、BigTable,Hadoop HDFS 第23课 听课总结
- 89C51使用ADC0808模数转换
- 旧手机上的微信数据丢失怎么才能恢复回来
- PL/SQL通过 scan ip 连接数据库
- 红米note4x装linux,红米Note4X自己安装Magisk的过程
- Android应用生命周期实现简单的秒表App
- MFC界面布局、效果
- [译]无迹卡尔曼滤波教程
- ant-design,解决格式化Table中的时间
- 2022-2028全球与中国智能家居解决方案市场现状及未来发展趋势
- 赖世雄老师---主语