阿里天池大赛实战记录之菜鸟-需求预测与分仓规划 1
概述
新赛季,天池终于迎来了我本专业的命题:菜鸟物流规划和需求预测。接下来的比赛中,本文会陆续记录比赛的详细过程,但是不能保证最后的结果优劣,希望对大家有一些启发,文章仅供参考,请勿模仿。
什么是天池大赛
下面是官方介绍
天池平台基于阿里云的海量数据离线处理服务ODPS,向学术界提供科研数据和云计算资源,旨在打造“数据众智、众创”第一平台。
简单来说,天池就是类似于 Kaggle 的一个数据挖掘比赛平台,不同于 Kaggle 的是,天池提供的比赛命题更与实际结合,提供的数据也需要我们做更多的清洗工作。
问题概述
赛题介绍
下面是官方介绍
阿里巴巴旗下电商拥有海量的买家和卖家交易场景下的数据。利用数据挖掘技术,我们能对未来的商品需求量进行准确地预测,从而帮助商家自动化很多供应链过程中的决策。这些以大数据驱动的供应链能够帮助商家大幅降低运营成本,提升用户的体验,对整个电商行业的效率提升起到重要作用。这是一个困难但是非常重要的问题。我们希望通过这次的大数据竞赛中得到一些对这个问题的新颖解法,朝智能化的供应链平台方向更加迈进一步。
高质量的商品需求预测是供应链管理的基础和核心功能。本赛题以历史一年海量买家和卖家的数据为依据,要求参赛者预测某商品在未来二周全国和区域性需求量。选手们需要用数据挖掘技术和方法精准刻画商品需求的变动规律,对未来的全国和区域性需求量进行预测,同时考虑到未来的不确定性对物流成本的影响,做到全局的最优化。更精确的需求预测,能够大大地优化运营成本,降低收货时效,提升整个社会的供应链物流效率。
简单的说就是物流的需求预测
评测指标
在本赛题中,参赛者需要提供对于每个商品在未来两周的全国最优目标库存和分仓区域最优目标库存的预测。我们会提供每一个商品的补少成本(A)和补多成本(B),然后根据用户预测的目标库存值跟实际的需求的差异来计算总的成本。参赛者的目标是让总的成本最低。
这里的补多主要是 商品积压带来的资金成本、仓储成本等。补少成本主要是商品不足带来的错失销售时机等缺货成本。
过多的供应会带来库存成本的增加,过少的供应又会错失销售时机,所以需求预测是供应链管理非常关键的一环。
简单来说,目标函数是全国的物流成本最低,变量是各个仓库的商品数量,约束条件是补多和补少。
数据说明
下面是官方说明:
我们提供商品从20141001到20151227的全国和区域分仓数据。参赛者需给出后面两周(20151228-20160110)的全国和区域分仓目标库存。 商品在全国的特征包括商品的本身的一些分类:类目、品牌等,还有历史的一些用户行为特征:浏览人数、加购物车人数,购买人数。注意我们要预测的未来需求是“非聚划算支付件数”(qty_alipay_njhs)
我们同时也提供商品的区域分仓历史数据,这些数据的维度跟全国的数据一样,仅有的差别是这些数据表达的是某个仓负责的地理区域内的用户行为。比如qty_alipay_njhs在这里表达的是这个仓负责的区域内的用户的“非聚划算支付件数”。
我们还提供每个商品在全国和分仓区域的补少、补多的成本,可以用来计算总成本
请注意我们这里需要预测的是未来两周的“非聚划算”销量,即去掉了商品参加聚划算产生的销量。我们提供的数据经过了脱敏,和实际商品的销量、浏览量和成本等有一些差距,但是不会影响这个问题的可解性。
下载官网数据我们可以看到:
-rwxr-xr-x@ 1 harryzhu staff 116K Mar 25 17:57 config1.csv # 每个商品在全国和分仓区域的补少、补多的成本
-rwxr-xr-x@ 1 harryzhu staff 22M Apr 8 12:03 item_feature1.csv # 商品粒度相关特征
-rwxr-xr-x@ 1 harryzhu staff 84M Apr 8 12:04 item_store_feature1.csv # 商品和分仓区域粒度相关特征
-rw-r-----@ 1 harryzhu staff 63K Apr 9 20:47 sample_submission.csv # 提交示例
数据清洗
# 加载依赖包
library(data.table)
library(tidyr)
library(dplyr)# read data 数据读取
config1 = fread("config1.csv")
item_feature1 = fread("item_feature1.csv")
item_store_feature1 = fread("item_store_feature1.csv")
sample_submission = fread("sample_submission.csv")# structure 构建表结构
colnames(item_feature1) = c("date","item_id","cate_id","cate_level_id","brand_id","supplier_id","pv_ipv","pv_uv","cart_ipv","cart_uv","collect_uv","num_gmv","amt_gmv","qty_gmv","unum_gmv","amt_alipay","num_alipay","qty_alipay","unum_alipay","ztc_pv_ipv","tbk_pv_ipv","ss_pv_ipv","jhs_pv_ipv","ztc_pv_uv","tbk_pv_uv","ss_pv_uv","jhs_pv_uv","num_alipay_njhs","amt_alipay_njhs","qty_alipay_njhs","unum_alipay_njhs")
colnames(item_store_feature1) = c("date","item_id","store_code","cate_id","cate_level_id","brand_id","supplier_id","pv_ipv","pv_uv","cart_ipv","cart_uv","collect_uv","num_gmv","amt_gmv","qty_gmv","unum_gmv","amt_alipay","num_alipay","qty_alipay","unum_alipay","ztc_pv_ipv","tbk_pv_ipv","ss_pv_ipv","jhs_pv_ipv","ztc_pv_uv","tbk_pv_uv","ss_pv_uv","jhs_pv_uv","num_alipay_njhs","amt_alipay_njhs","qty_alipay_njhs","unum_alipay_njhs")
colnames(config1) = c("item_id","store_code","a_b")
colnames(sample_submission) = c("item_id","store_code","target")# 建立新表
hc = as.numeric(as.vector(tstrsplit(config1$a_b,"_")[[1]]))
lc = as.numeric(as.vector(tstrsplit(config1$a_b,"_")[[2]]))
config = cbind(config1,hc,lc)[,.(item_id,store_code,hc,lc),]
head(config)
##
hc_config <- config %>% dplyr::select(item_id,store_code,hc) %>% tidyr::spread(key=store_code,value=hc)
lc_config <- config %>% dplyr::select(item_id,store_code,lc) %>% tidyr::spread(key=store_code,value=lc)# 结果表转化
wide_sumbmission = sample_submission %>% tidyr::spread(key=store_code,value=target)
wide_sumbmission$all <- apply(wide_sumbmission[,-1,with=F][,-6,with=F],1,sum)
long_submission = wide_sumbmission %>% tidyr::gather(key=item_id,value=target)目标函数
# 计算成本
zeroMatrix = matrix(0,dim(wide_sumbmission)[1],dim(wide_sumbmission)[2]-1)
hc_configMatrix = as.matrix(hc_config[,-1,with=F]);rownames(hc_configMatrix) = hc_config$item_id
lc_configMatrix = as.matrix(lc_config[,-1,with=F]);rownames(lc_configMatrix) = lc_config$item_id
wide_sumbmissionMatrix = as.matrix(wide_sumbmission[,-1,with=F]);rownames(wide_sumbmissionMatrix) = wide_sumbmission$item_idtargetSales = wide_sumbmissionMatrix
actualSales = zeroMatrixmarginSalesHc = targetSales - actualSales
marginSalesLc = actualSales - targetSales# 将 <= 0 的部分变成 0
marginSalesHc[marginSalesHc<=zeroMatrix]<-0# 将 >= 0 的部分变成 0
marginSalesLc[marginSalesLc<=zeroMatrix]<-0# 总成本计算
sum(hc_configMatrix*marginSalesHc + lc_configMatrix*marginSalesLc)数据探索
以1号仓库的所有商品为例,我们先将数据转化为时间序列格式。经过测试发现,数据存在大量的缺失值。有的是某些商品缺失开始一段的数据,有的是缺失后面一段的数据,还有的是该种商品没有出现任何销售记录。
结合实际经验,这里应该理解为,有的商品还没有上架所以起初的销售量是缺失值,或者后来被下架了最后一段时间的销售量是缺失值,亦或者在该仓库从未出现任何销售记录。
这里,我统一将这些缺失值都置为0。
library(dplyr)
library(zoo)
library(quantmod)
library(tseries)
library(forecast)store1 = item_store_feature1[store_code==1][,.(date,item_id,qty_alipay_njhs),] %>%tidyr::spread(key=item_id,value=qty_alipay_njhs)store1$date <- as.POSIXct(as.character(store1$date),tz="",format="%Y%m%d")store1[is.na(store1)] <- 0tstore1 = read.zoo(store1)通过快速数据可视化,我们对这里的时间序列有一个总体的观察。
for(i in seq(names(tstore1))){plot(tstore1[,i])
}问题分析
题目的目标是预测未来几天各个仓库各种商品的平均非聚划算销量,这里除了基本的时间序列外,还提供了用户行为特征、商品特征信息。
所以总体思想就是分析时间序列、用户行为、商品特征这三方面的因素对非聚划算销量的影响。
而传统的时间序列分析方法通常会将时间序列从这三个方面拆分:
趋势因素:总的来看长期的走势是增长、下降或者停滞。
季节因素:许多时间序列(比如销售指标、温度指数)都是以一定周期变化的(比如年),我们需要移除这些数据的季节因素。
不规则波动:从数据集中除了趋势和周期性波动因素外,对剩下的序列我们还需要观察它是否是纯随机的。
以1号仓库为例,这里的库存量非常符合上述规律。
chartSeries(apply(tstore1,1,sum),name="No.1 Store")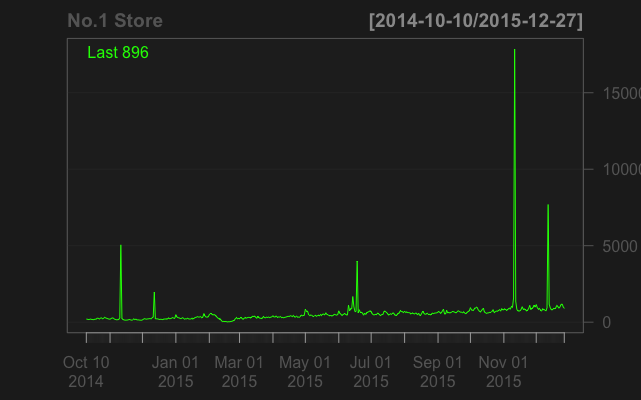
一阶差分之后:
chartSeries(apply(diff(tstore1),1,sum),name="No.1 Store")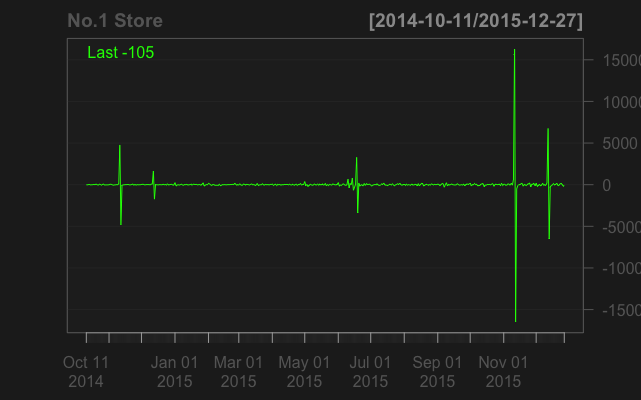
问题假设
假设电商物流量的变化收到消费周期、消费趋势的影响最大,暂时忽略各平台的流量影响,和用户偏好的影响。
模型设计
时间序列模型
对于短期的时间预测,ARIMA模型是公认的有效手段。首先,我们对时间序列的平稳性做一下平稳性检验。接着,我们构建ARIMA模型,利用forecast包,自动选择参数,并作出预测。由于这里参数选择的过程按部就班,这里我单独写了一个函数来处理每一个商品的情况。
predictItemStore <- function(tstore){if(sum(tstore) != 0){(adfTestPvalue = broom::tidy(adf.test(tstore,alternative = "stationary"))$p.value)if(adfTestPvalue < 0.1){(predictValue = broom::tidy(forecast::forecast(forecast::auto.arima(na.omit(tstore)),14)$mean)[1,])print(paste0("prediction value: ",predictValue))}}else{(predictValue = 0)print(paste0("prediction value: ",predictValue))}return(predictValue)
}system.time(apply(tstore1,2,predictItemStore))运行时间还算可以接受 总共花费了140s。
# user system elapsed
# 128.453 10.216 140.872 结果检验

参考文献
Gianluca Bontempi:Machine Learning Strategies for Time Series Prediction
深谈御膳房架构演进
阿里天池大赛实战记录之菜鸟-需求预测与分仓规划 1相关推荐
- 菜鸟—需求预测与分仓规划季军——“我们为R代言”团队赛后总结
在菜鸟-需求预测与分仓规划比赛上,"我们为R代言"团队获得了季军.在分享中,"我们为R代言"团队主要对赛题进行了分析,提出了选择机器学习的理由,介绍了团队线下解 ...
- 阿里天池——Numpy实战
文章目录 阿里天池--Numpy实战 一.数据集 二.导入鸢尾属植物数据集,保持文本不变. 三.求出鸢尾属植物萼片长度的平均值.中位数和标准差(第1列,sepallength) 四.创建一种标准化形式 ...
- 深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径
作者 | 刘昕 责编 | 胡永波 深度学习本质上是深层的人工神经网络,它不是一项孤立的技术,而是数学.统计机器学习.计算机科学和人工神经网络等多个领域的综合.深度学习的理解,离不开本科数学中最为基础的 ...
- 阿里天池大赛-工业蒸汽预测
一:赛题理解 1.1:数据说明 数据可以直接在阿里云天池官网下载.其格式如下: 上图所示为训练数据,其中V0-V37共38个特征变量,target字段是目标变量. 1.1:评估指标 预测结果以均方差M ...
- 阿里天池大赛脱敏多标签文本分类初赛20名方案分享
本次数据为脱敏文本,相当一种新语言了,直接用中文预训练的模型是不行的,故我们需要通过自己训练一个预训练模型. 做法就是将训练集,测试集放一起,构建专属词表,进行MLM无监督训练,训练属于脱敏文字的预训 ...
- 阿里天池大赛[人工智能辅助糖尿病遗传风险预测]赛后总结
题目以及数据介绍 人工智能辅助糖尿病遗传风险预测 Github 代码以及数据 Github 初始思想 1.从头开始,先看一下初始数据以及数据的简单分析吧 训练数据,最后一列是血糖: A榜测试数据 第九 ...
- 阿里天池数据挖掘大赛——贷款违约预测之探索性分析(可视化展示)
项目背景: 选题出自阿里天池大赛--金融风控_贷款违约预测.赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款. *以下作图基于一个前提 ...
- 阿里天池大数据竞赛——口碑商家客流量预测 A2
阿里天池大赛koubeiyuce1 2017年二月份,天池大数据比赛,口碑商家客流量预测,参赛地址及详情: https://tianchi.shuju.aliyun.com/competition/i ...
- 阿里云天池大赛赛题(机器学习)——O2O优惠券预测(完整代码)
目录 赛题背景 全代码 算法包及全局变量 工具函数 训练及结果输出 算法分析 调参 整合及输出结果 赛题实践 结果生成 绘制学习曲线 参数调优 赛题背景 O2O行业天然关联着数亿消费者,各类App每天 ...
- 数据竞赛江湖录:打破阿里天池战神不败神话,南京人工智能应用大赛杀出黑马...
2018全球(南京)人工智能应用大赛于8月最后一天落下帷幕. 600万人民币奖金,吸引2855人次,1022支队伍参赛. 如果能从5727道答题方案中脱颖而出,并找到能够落地的人工智能方案,会获得一项 ...
最新文章
- 排序算法汇总——转载自http://blog.csdn.net/zhanglong_daniel/article/details/52513058
- Git常见疑难解答集锦
- es统计有多少个分组_es多字段分组去重统计
- 内部链接和外部链接【转】
- html5的音乐标签使用,html5 音乐播放器 audio 标签使用概述_html5教程技巧
- Sublime text3关闭自动更新(hosts屏蔽)
- 【转】我该 不该学习VULKAN
- Debug深度学习中的NAN Loss
- centos7下编译openjdk11
- android8 呼吸灯,红米note8pro呼吸灯颜色如何设置?
- 【目标检测】FPN(Fature Pyramid Network)详解
- Postgres 数据库大批量单表导入数据引发性能故障的处理
- 【项目源码】个人博客源码推荐
- 精读《useEffect 完全指南》
- Laravel学习笔记(33)后台切换前台模板(修改默认的加载模版路径)
- python写txt怎么首行缩进_text-indent首行缩进两个字符和图片缩进的问题
- ElasticSearch、ki、head、kibana安装与基本使用
- Keystore介绍
- 浅论信息流广告与DSP营销推广的区别有哪些
- DN2540的 spice 模型