数据科学项目:适用于App Store和Google Play的有利可图的应用配置文件

At Dataquest, we strongly advocate portfolio projects as a means of getting a first data science job. In this blog post, we’ll walk you through an example portfolio project. This is the third project in our Data Science Portfolio Project series:
在Dataquest,我们强烈主张将项目组合作为获得第一份数据科学工作的一种手段。 在此博客文章中,我们将引导您完成一个示例项目组合项目。 这是我们的数据科学组合项目系列中的第三个项目:
- Is Fandango Still Inflating Ratings?
- Where to Advertise an E-learning Product
- Profitable App Profiles for App Store and Google Play
- Fandango是否仍在夸大评级?
- 在何处宣传电子学习产品
- 适用于App Store和Google Play的有利可图的应用配置文件
In the first two projects, we used a few advanced Python libraries, like pandas, matplotlib or seaborn. In this project, we limit ourselves to using only basic Python to prove that we can still perform analysis that adds business value. This project is part of our Python for Data Science: Fundamentals course, and it assumes familiarity with:
在前两个项目中,我们使用了一些高级Python库,例如pandas , matplotlib或seaborn 。 在这个项目中,我们仅限于使用基本的Python来证明我们仍然可以执行增加业务价值的分析。 此项目是我们的“ Python for Data Science:基础知识”课程的一部分,并且假定您熟悉以下内容:
- Basic Python concepts (variables, lists, dictionaries, if statements, for loops, etc.)
- Basic data analysis concepts (arithmetical mean, percentages, frequency tables, etc.)
- 基本的Python概念(变量,列表,字典,if语句,for循环等)
- 基本数据分析概念(算术平均值,百分比,频率表等)
If you think you need to fill in any gaps before moving forward, we cover the topics above in our Python for Data Science: Fundamentals course, which is free. This course will also give you deeper instructions on how to build this project, and code it in your browser.
如果您认为在继续前进之前需要弥补所有空白,我们将在“数据科学的Python:基础知识”课程(免费)中介绍以上主题。 本课程还将为您提供有关如何构建此项目以及如何在浏览器中进行编码的更深入的说明。
This project follows the guidelines presented in our style guide for data science projects.
该项目遵循我们针对数据科学项目的样式指南中介绍的准则。
适用于App Store和Google Play市场的有利可图的应用配置文件 (Profitable App Profiles for the App Store and Google Play Markets)
Our aim in this project is to find mobile app profiles that are profitable for the App Store and Google Play markets. We’re working as data analysts for a company that builds Android and iOS mobile apps, and our job is to enable our team of developers to make data-driven decisions with respect to the kind of apps they build.
我们在此项目中的目的是找到对App Store和Google Play市场有利可图的移动应用配置文件。 我们正在为一家构建Android和iOS移动应用程序的公司担任数据分析师,我们的工作是使我们的开发人员团队能够针对其构建的应用程序类型做出以数据为依据的决策。
At our company, we only build apps that are free to download and install, and our main source of revenue consists of in-app ads. This means that our revenue for any given app is mostly influenced by the number of users that use our app. Our goal for this project is to analyze data to help our developers understand what kinds of apps are likely to attract more users.
在我们公司,我们仅构建可免费下载和安装的应用,我们的主要收入来源包括应用内广告。 这意味着我们给定应用程序的收入主要受到使用我们应用程序的用户数量的影响。 我们对该项目的目标是分析数据,以帮助我们的开发人员了解哪些类型的应用程序可能会吸引更多用户。
打开和浏览数据 (Opening and Exploring the Data)
As of September 2018, there were approximately 2 million iOS apps available on the App Store, and 2.1 million Android apps on Google Play.
截至2018年9月,App Store上约有200万个iOS应用可用,Google Play上有210万个Android应用可用。
Source: Statista
资料来源: Statista
Collecting data for over four million apps requires a significant amount of time and money, so we’ll try to analyze a sample of data instead. To avoid spending resources with collecting new data ourselves, we should first try to see whether we can find any relevant existing data at no cost. Luckily, these are two data sets that seem suitable for our purpose:
收集超过四百万个应用程序的数据需要大量时间和金钱,因此我们将尝试分析数据样本。 为了避免自己花费资源来收集新数据,我们应该首先尝试看看是否可以免费找到任何相关的现有数据。 幸运的是,以下两个数据集似乎很适合我们的目的:
- A data set containing data about approximately ten thousand Android apps from Google Play
- A data set containing data about approximately seven thousand iOS apps from the App Store
- 一个数据集,包含来自Google Play的大约一万个Android应用程序的数据
- 包含来自App Store的大约七千个iOS应用程序的数据的数据集
Let’s start by opening the two data sets and then continue with exploring the data.
让我们从打开两个数据集开始,然后继续探索数据。
from csv import reader### The Google Play data set ### opened_file = open('googleplaystore.csv') read_file = reader(opened_file) android = list(read_file) android_header = android[0] android = android[1:]### The App Store data set ### opened_file = open('AppleStore.csv') read_file = reader(opened_file) ios = list(read_file) ios_header = ios[0] ios = ios[1:]from csv import reader### The Google Play data set ### opened_file = open('googleplaystore.csv') read_file = reader(opened_file) android = list(read_file) android_header = android[0] android = android[1:]### The App Store data set ### opened_file = open('AppleStore.csv') read_file = reader(opened_file) ios = list(read_file) ios_header = ios[0] ios = ios[1:]
To make it easier to explore the two data sets, we’ll first write a function named explore_data() that we can use repeatedly to explore rows in a more readable way. We’ll also add an option for our function to show the number of rows and columns for any data set.
为了使浏览这两个数据集更加容易,我们将首先编写一个名为explore_data()的函数,该函数可以重复使用,以一种更具可读性的方式浏览行。 我们还将为函数添加一个选项,以显示任何数据集的行数和列数。
['App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', 'Android Ver']['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['Coloring book moana', 'ART_AND_DESIGN', '3.9', '967', '14M', '500,000+', 'Free', '0', 'Everyone', 'Art & Design;Pretend Play', 'January 15, 2018', '2.0.0', '4.0.3 and up']['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']Number of rows: 10841 Number of columns: 13['App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', 'Android Ver']['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['Coloring book moana', 'ART_AND_DESIGN', '3.9', '967', '14M', '500,000+', 'Free', '0', 'Everyone', 'Art & Design;Pretend Play', 'January 15, 2018', '2.0.0', '4.0.3 and up']['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']Number of rows: 10841 Number of columns: 13
We see that the Google Play data set has 10841 apps and 13 columns. At a quick glance, the columns that might be useful for the purpose of our analysis are 'App', 'Category', 'Reviews', 'Installs', 'Type', 'Price', and 'Genres'.
我们看到Google Play数据集包含10841个应用程序和13列。 快速浏览一下,可能对我们的分析有用的列是'App' , 'Category' , 'Reviews' , 'Installs' , 'Type' , 'Price'和'Genres' 。
Now let’s take a look at the App Store data set.
现在,让我们看一下App Store数据集。
['id', 'track_name', 'size_bytes', 'currency', 'price', 'rating_count_tot', 'rating_count_ver', 'user_rating', 'user_rating_ver', 'ver', 'cont_rating', 'prime_genre', 'sup_devices.num', 'ipadSc_urls.num', 'lang.num', 'vpp_lic']['284882215', 'Facebook', '389879808', 'USD', '0.0', '2974676', '212', '3.5', '3.5', '95.0', '4+', 'Social Networking', '37', '1', '29', '1']['389801252', 'Instagram', '113954816', 'USD', '0.0', '2161558', '1289', '4.5', '4.0', '10.23', '12+', 'Photo & Video', '37', '0', '29', '1']['529479190', 'Clash of Clans', '116476928', 'USD', '0.0', '2130805', '579', '4.5', '4.5', '9.24.12', '9+', 'Games', '38', '5', '18', '1']Number of rows: 7197 Number of columns: 16['id', 'track_name', 'size_bytes', 'currency', 'price', 'rating_count_tot', 'rating_count_ver', 'user_rating', 'user_rating_ver', 'ver', 'cont_rating', 'prime_genre', 'sup_devices.num', 'ipadSc_urls.num', 'lang.num', 'vpp_lic']['284882215', 'Facebook', '389879808', 'USD', '0.0', '2974676', '212', '3.5', '3.5', '95.0', '4+', 'Social Networking', '37', '1', '29', '1']['389801252', 'Instagram', '113954816', 'USD', '0.0', '2161558', '1289', '4.5', '4.0', '10.23', '12+', 'Photo & Video', '37', '0', '29', '1']['529479190', 'Clash of Clans', '116476928', 'USD', '0.0', '2130805', '579', '4.5', '4.5', '9.24.12', '9+', 'Games', '38', '5', '18', '1']Number of rows: 7197 Number of columns: 16
We have 7197 iOS apps in this data set, and the columns that seem interesting are: 'track_name', 'currency', 'price', 'rating_count_tot', 'rating_count_ver', and 'prime_genre'. Not all column names are self-explanatory in this case, but details about each column can be found in the data set documentation.
在此数据集中,我们有7197个iOS应用程序,看起来有趣的列是: 'track_name' , 'currency' , 'price' , 'rating_count_tot' , 'rating_count_ver'和'prime_genre' 。 在这种情况下,并非所有列名都是不言自明的,但是有关每个列的详细信息可以在数据集文档中找到 。
清理数据 (Cleaning the Data)
The Google Play data set has a dedicated discussion section, and we can see that one of the discussions outlines an error for row 10472. Let’s print this row and compare it against the header and another row that is correct.
Google Play数据集有专门的讨论部分 ,我们可以看到其中一个讨论概述了10472行的错误。让我们打印此行,并将其与标题和另一正确的行进行比较。
['Life Made WI-Fi Touchscreen Photo Frame', '1.9', '19', '3.0M', '1,000+', 'Free', '0', 'Everyone', '', 'February 11, 2018', '1.0.19', '4.0 and up']['App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', 'Android Ver']['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['Life Made WI-Fi Touchscreen Photo Frame', '1.9', '19', '3.0M', '1,000+', 'Free', '0', 'Everyone', '', 'February 11, 2018', '1.0.19', '4.0 and up']['App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', 'Android Ver']['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']
The row 10472 corresponds to the app Life Made WI-Fi Touchscreen Photo Frame, and we can see that the rating is 19. This is clearly off because the maximum rating for a Google Play app is 5. As a consequence, we’ll delete this row.
第10472行对应于应用程序“制造的WI-Fi触摸屏相框”,我们可以看到其评分为19。这显然是不正确的,因为Google Play应用程序的最高评分为5。因此,我们将删除此行。
10841 1084010841 10840
删除重复的条目 (Removing Duplicate Entries)
If we explore the Google Play data set long enough, we’ll find that some apps have more than one entry. For instance, the application Instagram has four entries:
如果我们在足够长的时间内浏览Google Play数据集,则会发现某些应用包含多个条目。 例如,应用程序Instagram具有四个条目:
['Instagram', 'SOCIAL', '4.5', '66577313', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device'] ['Instagram', 'SOCIAL', '4.5', '66577446', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device'] ['Instagram', 'SOCIAL', '4.5', '66577313', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device'] ['Instagram', 'SOCIAL', '4.5', '66509917', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device']['Instagram', 'SOCIAL', '4.5', '66577313', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device'] ['Instagram', 'SOCIAL', '4.5', '66577446', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device'] ['Instagram', 'SOCIAL', '4.5', '66577313', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device'] ['Instagram', 'SOCIAL', '4.5', '66509917', 'Varies with device', '1,000,000,000+', 'Free', '0', 'Teen', 'Social', 'July 31, 2018', 'Varies with device', 'Varies with device']
In total, there are 1,181 cases where an app occurs more than once:
总共有1,181个应用程序发生多次的情况:
1181 ['Quick PDF Scanner + OCR FREE', 'Box', 'Google My Business', 'ZOOM Cloud Meetings', 'join.me - Simple Meetings', 'Box', 'Zenefits', 'Google Ads', 'Google My Business', 'Slack', 'FreshBooks Classic', 'Insightly CRM', 'QuickBooks Accounting: Invoicing & Expenses', 'HipChat - Chat Built for Teams', 'Xero Accounting Software']1181 ['Quick PDF Scanner + OCR FREE', 'Box', 'Google My Business', 'ZOOM Cloud Meetings', 'join.me - Simple Meetings', 'Box', 'Zenefits', 'Google Ads', 'Google My Business', 'Slack', 'FreshBooks Classic', 'Insightly CRM', 'QuickBooks Accounting: Invoicing & Expenses', 'HipChat - Chat Built for Teams', 'Xero Accounting Software']
We don’t want to count certain apps more than once when we analyze data, so we need to remove the duplicate entries and keep only one entry per app. One thing we could do is remove the duplicate rows randomly, but we can probably find a better way.
在分析数据时,我们不想对某些应用计数一次,因此我们需要删除重复的条目,并且每个应用仅保留一个条目。 我们可以做的一件事是随机删除重复的行,但是我们可能会找到更好的方法。
If you examine the rows we printed for the Instagram app, the main difference happens on the fourth position of each row, which corresponds to the number of reviews. The different numbers show that the data was collected at different times. We can use this to build a criterion for keeping rows. We won’t remove rows randomly; instead, we’ll keep the rows with the highest number of reviews, on the assumption that the higher the number of reviews, the more reliable the ratings.
如果您检查我们为Instagram应用程序打印的行,则主要区别发生在每行的第四个位置,这与评论数相对应。 不同的数字表明数据是在不同的时间收集的。 我们可以使用它来建立保留行的标准。 我们不会随机删除行; 相反,我们将保留评论数最高的行,前提是评论数越高,评级越可靠。
To do that, we will:
为此,我们将:
- Create a dictionary where each key is a unique app name, and the value is the highest number of reviews of that app
- Use the dictionary to create a new data set, which will have only one entry per app (and we only select the apps with the highest number of reviews)
- 创建一个字典,其中每个键是唯一的应用程序名称,值是该应用程序的最高评论数
- 使用字典创建一个新数据集,每个应用程序只有一个条目(并且我们仅选择评论数最高的应用程序)
Let’s start by building the dictionary.
让我们从构建字典开始。
In a previous code cell, we found that there are 1,181 cases where an app occurs more than once, so the length of our dictionary (of unique apps) should be equal to the difference between the length of our data set and 1,181.
在上一个代码单元中,我们发现有1181种情况下一个应用程序不止一次发生,因此(唯一应用程序的)字典的长度应等于我们的数据集长度与1,181个之间的差。
print('Expected length:', len(android) - 1181) print('Actual length:', len(reviews_max))print('Expected length:', len(android) - 1181) print('Actual length:', len(reviews_max))
Now, let’s use the reviews_max dictionary to remove the duplicates. For the duplicate cases, we’ll only keep the entries with the highest number of reviews. In the code cell below:
现在,让我们使用reviews_max字典删除重复项。 对于重复的案例,我们将仅保留评论数最多的条目。 在下面的代码单元中:
- We start by initializing two empty lists,
android_cleanandalready_added. - We loop through the
androiddata set, and for every iteration:- We isolate the name of the app and the number of reviews.
- We add the current row (
app) to theandroid_cleanlist, and the app name (name) to thealready_cleanedlist if:- The number of reviews of the current app matches the number of reviews of that app as described in the
reviews_maxdictionary; and - The name of the app is not already in the
already_addedlist. We need to add this supplementary condition to account for those cases where the highest number of reviews of a duplicate app is the same for more than one entry (for example, the Box app has three entries, and the number of reviews is the same). If we just check forreviews_max[name] == n_reviews, we’ll still end up with duplicate entries for some apps.
- The number of reviews of the current app matches the number of reviews of that app as described in the
- 我们首先初始化两个空列表,
android_clean和已经already_added。 - 我们遍历
android数据集,并进行每次迭代:- 我们将应用程序的名称和评论数分开。
- 如果存在以下情况,我们将当前行(
app)添加到android_clean列表中,并将应用程序名称(name)添加到already_cleaned列表中:- 当前应用的评论数量与该应用的评论数量匹配,如
reviews_max词典中所述; 和 - 该应用程序的名称是不是已经在
already_added列表。 我们需要添加此补充条件,以解决重复多个应用程序对多个条目的最高评论数相同的情况(例如,Box应用程序具有三个条目,并且评论数相同) 。 如果仅检查reviews_max[name] == n_reviews,那么对于某些应用程序,我们仍然会得到重复的条目。
- 当前应用的评论数量与该应用的评论数量匹配,如
android_clean = [] already_added = []for app in android:name = app[0]n_reviews = float(app[3])if (reviews_max[name] == n_reviews) and (name not in already_added):android_clean.append(app)already_added.append(name) # make sure this is inside the if blockandroid_clean = [] already_added = []for app in android:name = app[0]n_reviews = float(app[3])if (reviews_max[name] == n_reviews) and (name not in already_added):android_clean.append(app)already_added.append(name) # make sure this is inside the if block
Now let’s quickly explore the new data set, and confirm that the number of rows is 9,659.
现在,让我们快速浏览新数据集,并确认行数为9,659。
['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']['Sketch - Draw & Paint', 'ART_AND_DESIGN', '4.5', '215644', '25M', '50,000,000+', 'Free', '0', 'Teen', 'Art & Design', 'June 8, 2018', 'Varies with device', '4.2 and up']Number of rows: 9659 Number of columns: 13['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']['Sketch - Draw & Paint', 'ART_AND_DESIGN', '4.5', '215644', '25M', '50,000,000+', 'Free', '0', 'Teen', 'Art & Design', 'June 8, 2018', 'Varies with device', '4.2 and up']Number of rows: 9659 Number of columns: 13
We have 9659 rows, just as expected.
正如预期的那样,我们有9659行。
删除非英语应用 (Removing Non-English Apps)
If you explore the data sets enough, you’ll notice the names of some of the apps suggest they are not directed toward an English-speaking audience. Below, we see a couple of examples from both data sets:
如果您对数据集进行了足够的探索,您会发现某些应用程序的名称表明它们并不针对英语使用者。 下面,我们从两个数据集中看到几个示例:
爱奇艺PPS -《欢乐颂2》电视剧热播 【脱出ゲーム】絶対に最後までプレイしないで 〜謎解き&ブロックパズル〜 中国語 AQリスニング لعبة تقدر تربح DZ爱奇艺PPS -《欢乐颂2》电视剧热播 【脱出ゲーム】絶対に最後までプレイしないで 〜謎解き&ブロックパズル〜 中国語 AQリスニング لعبة تقدر تربح DZ
We’re not interested in keeping these kind of apps, so we’ll remove them. One way to go about this is to remove each app whose name contains a symbol that is not commonly used in English text — English text usually includes letters from the English alphabet, numbers composed of digits from 0 to 9, punctuation marks (., !, ?, ;, etc.), and other symbols (+, *, /, etc.).
我们对保留此类应用程序不感兴趣,因此我们将其删除。 解决此问题的一种方法是删除每个应用程序,其名称包含英文文本中不常用的符号-英文文本通常包含英文字母,由0到9的数字组成的数字,标点符号(。,! ,?,;等)和其他符号(+,*,/等)。
All these characters that are specific to English texts are encoded using the ASCII standard. Each ASCII character has a corresponding number between 0 and 127 associated with it, and we can take advantage of that to build a function that checks an app name and tells us whether it contains non-ASCII characters.
所有这些特定于英语文本的字符均使用ASCII标准进行编码。 每个ASCII字符都有一个对应的0到127之间的数字,我们可以利用它来构建一个函数来检查应用程序名称并告诉我们它是否包含非ASCII字符。
We built this function below, and we use the built-in ord() function to find out the corresponding encoding number of each character.
我们在下面构建了此函数,并使用内置的ord()函数找出每个字符的对应编码编号。
True FalseTrue False
The function seems to work fine, but some English app names use emojis or other symbols (™, — (em dash), – (en dash), etc.) that fall outside of the ASCII range. Because of this, we’ll remove useful apps if we use the function in its current form.
该功能似乎可以正常工作,但是某些英文应用名称使用表情符号或超出ASCII范围的其他符号(™,-(破折号),-(破折号)等)。 因此,如果我们以当前形式使用该功能,我们将删除有用的应用程序。
False False 8482 128540False False 8482 128540
To minimize the impact of data loss, we’ll only remove an app if its name has more than three non-ASCII characters:
为了最大程度地减少数据丢失的影响,我们将仅删除名称超过三个的非ASCII字符的应用程序:
True TrueTrue True
The function is still not perfect, and very few non-English apps might get past our filter, but this seems good enough at this point in our analysis — we shouldn’t spend too much time on optimization at this point.
该功能仍然不够完善,很少有非英语应用程序可能无法通过我们的过滤器,但这在我们的分析中这一点似乎已经足够了–我们此时不应花太多时间进行优化。
Below, we use the is_English() function to filter out the non-English apps for both data sets:
下面,我们使用is_English()函数过滤两个数据集的非英语应用程序:
['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']['Sketch - Draw & Paint', 'ART_AND_DESIGN', '4.5', '215644', '25M', '50,000,000+', 'Free', '0', 'Teen', 'Art & Design', 'June 8, 2018', 'Varies with device', '4.2 and up']Number of rows: 9614 Number of columns: 13['284882215', 'Facebook', '389879808', 'USD', '0.0', '2974676', '212', '3.5', '3.5', '95.0', '4+', 'Social Networking', '37', '1', '29', '1']['389801252', 'Instagram', '113954816', 'USD', '0.0', '2161558', '1289', '4.5', '4.0', '10.23', '12+', 'Photo & Video', '37', '0', '29', '1']['529479190', 'Clash of Clans', '116476928', 'USD', '0.0', '2130805', '579', '4.5', '4.5', '9.24.12', '9+', 'Games', '38', '5', '18', '1']Number of rows: 6183 Number of columns: 16['Photo Editor & Candy Camera & Grid & ScrapBook', 'ART_AND_DESIGN', '4.1', '159', '19M', '10,000+', 'Free', '0', 'Everyone', 'Art & Design', 'January 7, 2018', '1.0.0', '4.0.3 and up']['U Launcher Lite – FREE Live Cool Themes, Hide Apps', 'ART_AND_DESIGN', '4.7', '87510', '8.7M', '5,000,000+', 'Free', '0', 'Everyone', 'Art & Design', 'August 1, 2018', '1.2.4', '4.0.3 and up']['Sketch - Draw & Paint', 'ART_AND_DESIGN', '4.5', '215644', '25M', '50,000,000+', 'Free', '0', 'Teen', 'Art & Design', 'June 8, 2018', 'Varies with device', '4.2 and up']Number of rows: 9614 Number of columns: 13['284882215', 'Facebook', '389879808', 'USD', '0.0', '2974676', '212', '3.5', '3.5', '95.0', '4+', 'Social Networking', '37', '1', '29', '1']['389801252', 'Instagram', '113954816', 'USD', '0.0', '2161558', '1289', '4.5', '4.0', '10.23', '12+', 'Photo & Video', '37', '0', '29', '1']['529479190', 'Clash of Clans', '116476928', 'USD', '0.0', '2130805', '579', '4.5', '4.5', '9.24.12', '9+', 'Games', '38', '5', '18', '1']Number of rows: 6183 Number of columns: 16
We can see that we’re left with 9614 Android apps and 6183 iOS apps.
我们可以看到我们剩下9614个Android应用程序和6183个iOS应用程序。
隔离免费应用 (Isolating the Free Apps)
As we mentioned in the introduction, we only build apps that are free to download and install, and our main source of revenue consists of in-app ads. Our data sets contain both free and non-free apps, and we’ll need to isolate only the free apps for our analysis. Below, we isolate the free apps for both our data sets.
正如我们在简介中所提到的,我们仅构建可免费下载和安装的应用,我们的主要收入来源包括应用内广告。 我们的数据集包含免费和非免费应用程序,我们仅需要隔离免费应用程序即可进行分析。 下面,我们隔离了两个数据集的免费应用程序。
8864 32228864 3222
We’re left with 8864 Android apps and 3222 iOS apps, which should be enough for our analysis.
我们剩下8864个Android应用程序和3222个iOS应用程序,这对于我们的分析应该足够了。
类型最常见的应用 (Most Common Apps by Genre)
As we mentioned in the introduction, our aim is to determine the kinds of apps that are likely to attract more users because our revenue is highly influenced by the number of people using our apps.
正如我们在引言中提到的,我们的目标是确定可能吸引更多用户的应用程序类型,因为我们的收入很大程度上受使用我们应用程序的人数的影响。
To minimize risks and overhead, our validation strategy for an app idea is comprised of three steps:
为了最大程度地降低风险和开销,我们对应用程序创意的验证策略包括三个步骤:
- Build a minimal Android version of the app, and add it to Google Play.
- If the app has a good response from users, we then develop it further.
- If the app is profitable after six months, we also build an iOS version of the app and add it to the App Store.
- 构建该应用的最低Android版本,并将其添加到Google Play。
- 如果该应用程序得到用户的好评,那么我们将进一步开发它。
- 如果六个月后该应用程序开始盈利,我们还将构建该应用程序的iOS版本并将其添加到App Store。
Because our end goal is to add the app on both the App Store and Google Play, we need to find app profiles that are successful on both markets. For instance, a profile that might work well for both markets might be a productivity app that makes use of gamification.
由于我们的最终目标是将应用程序同时添加到App Store和Google Play上,因此我们需要找到在两个市场都成功的应用程序配置文件。 例如,可能对两个市场都适用的配置文件可能是利用游戏化的生产力应用程序。
Let’s begin the analysis by getting a sense of the most common genres for each market. For this, we’ll build a frequency table for the prime_genre column of the App Store data set, and the Genres and Category columns of the Google Play data set.
让我们从了解每个市场最常见的流派开始分析。 为此,我们将为App Store数据集的prime_genre列以及Google Play数据集的Genres和Category列构建频率表。
We’ll build two functions we can use to analyze the frequency tables:
我们将构建两个函数来分析频率表:
- One function to generate frequency tables that show percentages
- Another function that we can use to display the percentages in a descending order
- 生成频率表以显示百分比的一项功能
- 我们可以使用另一个功能以降序显示百分比
We start by examining the frequency table for the prime_genre column of the App Store data set.
我们首先检查App Store数据集的prime_genre列的频率表。
display_table(ios_final, -5)display_table(ios_final, -5)
We can see that among the free English apps, more than a half (58.16%) are games. Entertainment apps are close to 8%, followed by photo and video apps, which are close to 5%. Only 3.66% of the apps are designed for education, followed by social networking apps which amount for 3.29% of the apps in our data set.
我们可以看到,在免费的英语应用程序中,有一半以上(58.16%)是游戏。 娱乐应用接近8%,其次是照片和视频应用,接近5%。 仅3.66%的应用程序设计用于教育,其次是社交网络应用程序,占我们数据集中应用程序的3.29%。
The general impression is that App Store (at least the part containing free English apps) is dominated by apps that are designed for fun (games, entertainment, photo and video, social networking, sports, music, etc.), while apps with practical purposes (education, shopping, utilities, productivity, lifestyle, etc.) are more rare. However, the fact that fun apps are the most numerous doesn’t also imply that they also have the greatest number of users — the demand might not be the same as the offer.
总体印象是,App Store(至少包含免费的英语应用程序的部分)以娱乐性应用程序(游戏,娱乐,照片和视频,社交网络,体育,音乐等)为主,而实用性较高的应用程序目的(教育,购物,公用事业,生产力,生活方式等)更为罕见。 但是,有趣的应用程序最多,这并不意味着它们也拥有最多的用户-需求可能与报价不尽相同。
Let’s continue by examining the Genres and Category columns of the Google Play data set (two columns which seem to be related).
让我们继续检查Google Play数据集的“ Genres和“ Category列(两个似乎相关的列)。
display_table(android_final, 1) # Categorydisplay_table(android_final, 1) # Category
The landscape seems significantly different on Google Play: there are not that many apps designed for fun, and it seems that a good number of apps are designed for practical purposes (family, tools, business, lifestyle, productivity, etc.). However, if we investigate this further, we can see that the family category (which accounts for almost 19% of the apps) means mostly games for kids.
在Google Play上,情况似乎大不相同:为娱乐而设计的应用程序并不多,而且似乎有许多应用程序是为实用目的而设计的(家庭,工具,业务,生活方式,生产力等)。 但是,如果我们进一步调查,我们会发现家庭类别(占应用程序的将近19%)主要是针对儿童的游戏。
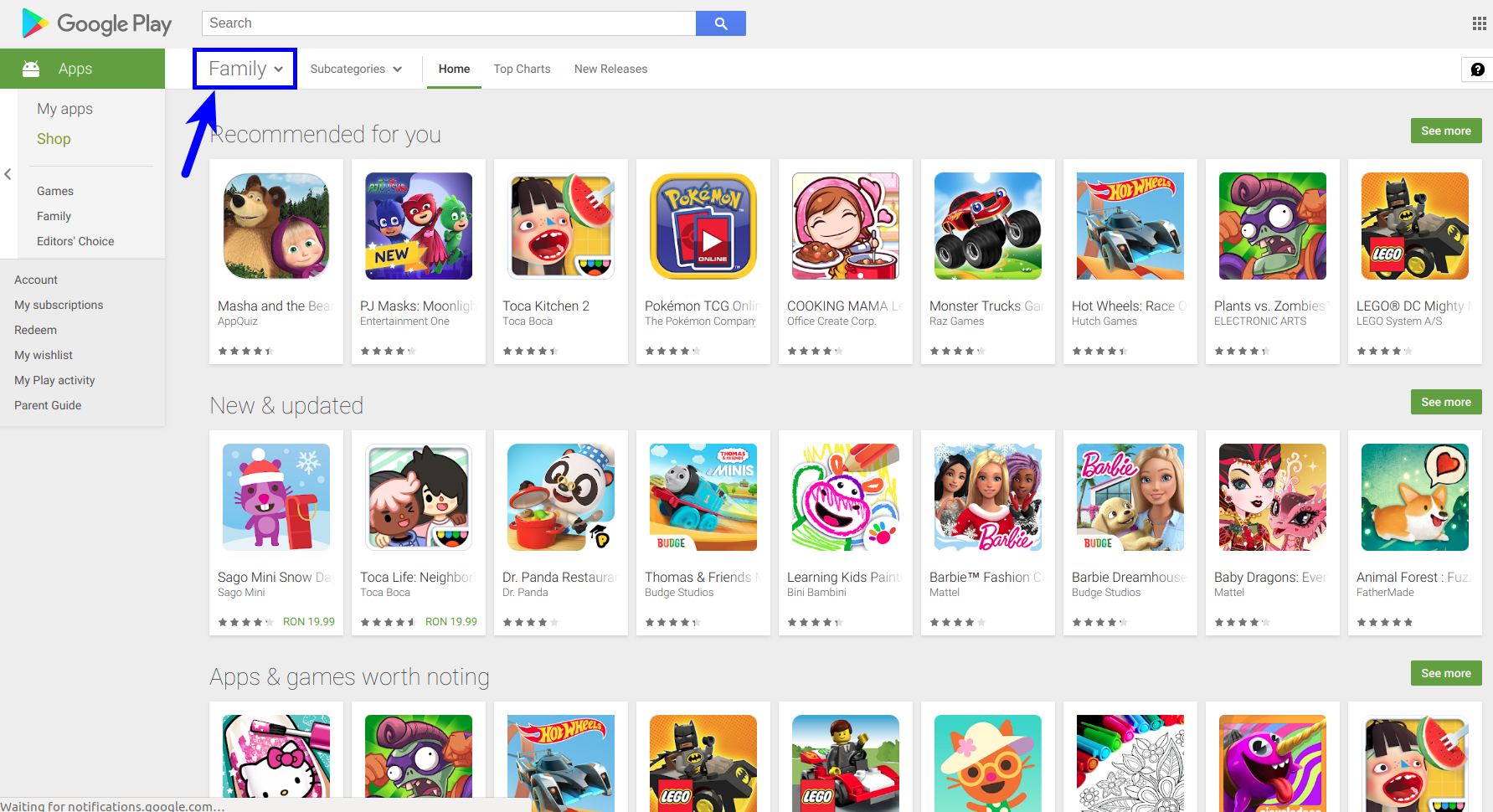
Source: play.google.com
资料来源: play.google.com
Even so, practical apps seem to have a better representation on Google Play compared to App Store. This picture is also confirmed by the frequency table we see for the Genres column:
即便如此,与App Store相比,实用的应用似乎在Google Play上的表现更好。 我们在“ Genres列中看到的频率表也确认了这张图片:
display_table(android_final, -4)display_table(android_final, -4)
The difference between the Genres and the Category columns is not crystal clear, but one thing we can notice is that the Genres column is much more granular (it has more categories). We’re only looking for the bigger picture at the moment, so we’ll only work with the Category column moving forward.
“ Genres和“ Category列之间的区别不是很清晰,但我们可以注意到的一件事是,“ Genres列的粒度要大得多(它具有更多的类别)。 目前,我们只是在寻找更大的图景,因此,我们只会继续使用“ Category列。
Up to this point, we found that the App Store is dominated by apps designed for fun, while Google Play shows a more balanced landscape of both practical and for-fun apps. Now we’d like to get an idea about the kinds of apps that have most users.
到目前为止,我们发现App Store的主要目的是娱乐性的应用程序,而Google Play则显示了实用性和趣味性应用程序之间更为平衡的格局。 现在,我们想了解一下拥有最多用户的应用程序的种类。
Genre最受欢迎的应用程序:在App Store上的内容 (Most Popular Apps by Genre on the App Store)
One way to find out what genres are the most popular (have the most users) is to calculate the average number of installs for each app genre. For the Google Play data set, we can find this information in the Installs column, but for the App Store data set this information is missing. As a workaround, we’ll take the total number of user ratings as a proxy, which we can find in the rating_count_tot app.
找出哪种类型最流行(拥有最多用户)的一种方法是计算每种应用类型的平均安装次数。 对于Google Play数据集,我们可以在“ Installs列中找到此信息,但是对于App Store数据集,此信息会丢失。 作为解决方法,我们将用户评分的总数作为代理,可以在rating_count_tot应用程序中找到该rating_count_tot 。
Below, we calculate the average number of user ratings per app genre on the App Store:
下面,我们在App Store中计算每种类型的平均用户评分:
### Generating a frequency table to get the unique app genres ### genres_ios = freq_table(ios_final, -5)### Looping over the unique genres ### for genre in genres_ios:total = 0len_genre = 0## Looping over the App Store data set ##for app in ios_final:genre_app = app[-5]if genre_app == genre: n_ratings = float(app[5])total += n_ratingslen_genre += 1## Compute and display the average number of user ratings ##avg_n_ratings = total / len_genreprint(genre, ':', avg_n_ratings)### Generating a frequency table to get the unique app genres ### genres_ios = freq_table(ios_final, -5)### Looping over the unique genres ### for genre in genres_ios:total = 0len_genre = 0## Looping over the App Store data set ##for app in ios_final:genre_app = app[-5]if genre_app == genre: n_ratings = float(app[5])total += n_ratingslen_genre += 1## Compute and display the average number of user ratings ##avg_n_ratings = total / len_genreprint(genre, ':', avg_n_ratings)
On average, navigation apps have the highest number of user reviews, but this figure is heavily influenced by Waze and Google Maps, which have close to half a million user reviews together:
平均而言,导航应用程序具有最高的用户评论数量,但这个数字受到Waze和Google Maps的严重影响,后者总共有近500万用户评论:
for app in ios_final:if app[-5] == 'Navigation':print(app[1], ':', app[5]) # print name and number of ratingsfor app in ios_final:if app[-5] == 'Navigation':print(app[1], ':', app[5]) # print name and number of ratings
The same pattern applies to social networking apps, where the average number is heavily influenced by a few giants like Facebook, Pinterest, Skype, etc. Same applies to music apps, where a few big players like Pandora, Spotify, and Shazam heavily influence the average number.
相同的模式适用于社交网络应用程序,其平均数量受Facebook,Pinterest,Skype等几大巨头的严重影响。同样适用于音乐应用程序,其中诸如Pandora,Spotify和Shazam的一些大公司严重影响平均数。
Our aim is to find popular genres, but navigation, social networking or music apps might seem more popular than they really are. The average number of ratings seem to be skewed by very few apps which have hundreds of thousands of user ratings, while the other apps may struggle to get past the 10,000 threshold. We could get a better picture by removing these extremely popular apps for each genre and then rework the averages, but we’ll leave this level of detail for later.
我们的目标是找到流行的类型,但导航,社交网络或音乐应用似乎比实际流行。 评分应用的平均数量似乎受到很少的具有数十万用户评分的应用程序的扭曲,而其他应用程序可能难以超过10,000个阈值。 我们可以通过针对每种流派删除这些非常流行的应用,然后重新计算平均值来获得更好的图像,但是稍后我们将保留这一详细级别。
Reference apps have 74,942 user ratings on average, but it’s actually the Bible and Dictionary.com which skew up the average rating:
参考应用平均有74,942个用户评分,但这实际上是Bible and Dictionary.com的平均评分偏高:
for app in ios_final:if app[-5] == 'Reference':print(app[1], ':', app[5])for app in ios_final:if app[-5] == 'Reference':print(app[1], ':', app[5])
However, this niche seems to show some potential. One thing we could do is take another popular book and turn it into an app where we could add different features besides the raw version of the book. This might include daily quotes from the book, an audio version of the book, quizzes about the book, etc. On top of that, we could also embed a dictionary within the app, so users don’t need to exit our app to look up words in an external app.
但是,这个利基市场似乎显示出一些潜力。 我们可以做的一件事是拿另一本受欢迎的书,并将其变成一个应用程序,在其中可以添加除本书原始版本以外的其他功能。 这可能包括该书的每日报价,该书的音频版本,该书的测验等。此外,我们还可以在应用程序中嵌入字典,因此用户无需退出我们的应用程序即可查看外部应用程序中的单词。
This idea seems to fit well with the fact that the App Store is dominated by for-fun apps. This suggests the market might be a bit saturated with for-fun apps, which means a practical app might have more of a chance to stand out among the huge number of apps on the App Store.
这个想法似乎很适合以下事实:App Store由有趣的应用程序主导。 这表明有趣的应用程序市场可能会有点饱和,这意味着实用的应用程序可能有更多机会在App Store中的众多应用程序中脱颖而出。
Other genres that seem popular include weather, book, food and drink, or finance. The book genre seem to overlap a bit with the app idea we described above, but the other genres don’t seem too interesting to us:
似乎很受欢迎的其他类型包括天气,书籍,食物和饮料或金融。 图书类型似乎与我们上面描述的应用程序概念有些重叠,但是其他类型对我们来说似乎不太有趣:
Weather apps — people generally don’t spend too much time in-app, and the chances of making profit from in-app adds are low. Also, getting reliable live weather data may require us to connect our apps to non-free APIs.
Food and drink — examples here include Starbucks, Dunkin’ Donuts, McDonald’s, etc. So making a popular food and drink app requires actual cooking and a delivery service, which is outside the scope of our company.
Finance apps — these apps involve banking, paying bills, money transfer, etc. Building a finance app requires domain knowledge, and we don’t want to hire a finance expert just to build an app.
天气应用程序—人们通常不会在应用程序上花费太多时间,并且从应用程序内添加中获利的机会很低。 另外,要获得可靠的实时天气数据,可能需要我们将应用程序连接到非免费的API。
餐饮-例如星巴克,邓肯甜甜圈,麦当劳等。因此,制作流行的餐饮应用程序需要实际的烹饪和送货服务,这不在我们公司的范围内。
财务应用程序-这些应用程序涉及银行业务,支付账单,汇款等。构建财务应用程序需要领域知识,并且我们不想聘请财务专家来构建应用程序。
Now let’s analyze the Google Play market a bit.
现在让我们分析一下Google Play市场。
Genre在Google Play上最受欢迎的应用 (Most Popular Apps by Genre on Google Play)
For the Google Play market, we actually have data about the number of installs, so we should be able to get a clearer picture about genre popularity. However, the install numbers don’t seem precise enough — we can see that most values are open-ended (100+, 1,000+, 5,000+, etc.):
对于Google Play市场,我们实际上具有有关安装数量的数据,因此我们应该能够更清楚地了解类型流行度。 但是,安装数量似乎不够精确-我们可以看到大多数值都是开放式的(100 +,1,000 +,5,000 +等):
display_table(android_final, 5) # the Installs columnsdisplay_table(android_final, 5) # the Installs columns
One problem with this data is that is not precise. For instance, we don’t know whether an app with 100,000+ installs has 100,000 installs, 200,000, or 350,000. However, we don’t need very precise data for our purposes — we only want to get an idea which app genres attract the most users, and we don’t need perfect precision with respect to the number of users.
该数据的一个问题是不精确。 例如,我们不知道安装量超过100,000的应用程序的安装量是100,000、200,000还是350,000。 但是,我们不需要非常精确的数据来满足我们的目的-我们只想了解哪种应用类型吸引最多的用户,就用户数量而言,我们并不需要完美的精度。
We’re going to leave the numbers as they are, which means that we’ll consider that an app with 100,000+ installs has 100,000 installs, and an app with 1,000,000+ installs has 1,000,000 installs, and so on.
我们将保持数字不变,这意味着我们将考虑具有100,000+安装的应用程序具有100,000安装,而具有1,000,000+安装的应用程序具有1,000,000安装,依此类推。
To perform computations, however, we’ll need to convert each install number to float — this means that we need to remove the commas and the plus characters, otherwise the conversion will fail and raise an error. We’ll do this directly in the loop below, where we also compute the average number of installs for each genre (category).
但是,要执行计算,我们需要将每个安装号转换为float ,这意味着我们需要删除逗号和加号,否则转换将失败并引发错误。 我们将直接在下面的循环中执行此操作,在该循环中,我们还将计算每种类型(类别)的平均安装次数。
### Generating a frequency table to get the unique app genres ### categories_android = freq_table(android_final, 1)### Looping over the unique app genres ### for category in categories_android:total = 0len_category = 0## Looping over the Google Play data set ##for app in android_final:category_app = app[1]if category_app == category: n_installs = app[5]n_installs = n_installs.replace(',', '')n_installs = n_installs.replace('+', '')total += float(n_installs)len_category += 1## Compute and display the average number of installs ## avg_n_installs = total / len_categoryprint(category, ':', avg_n_installs)### Generating a frequency table to get the unique app genres ### categories_android = freq_table(android_final, 1)### Looping over the unique app genres ### for category in categories_android:total = 0len_category = 0## Looping over the Google Play data set ##for app in android_final:category_app = app[1]if category_app == category: n_installs = app[5]n_installs = n_installs.replace(',', '')n_installs = n_installs.replace('+', '')total += float(n_installs)len_category += 1## Compute and display the average number of installs ## avg_n_installs = total / len_categoryprint(category, ':', avg_n_installs)
On average, communication apps have the most installs: 38,456,119. This number is heavily skewed up by a few apps that have over one billion installs (WhatsApp, Facebook Messenger, Skype, Google Chrome, Gmail, and Hangouts), and a few others with over 100 and 500 million installs:
平均而言,通信应用程序的最多安装数量:38,456,119。 一些安装过10亿次的应用(WhatsApp,Facebook Messenger,Skype,Google Chrome,Gmail和环聊)和其他安装过100亿和5亿次的应用严重地错开了这个数字:
for app in android_final:if app[1] == 'COMMUNICATION' and (app[5] == '1,000,000,000+'or app[5] == '500,000,000+'or app[5] == '100,000,000+'):print(app[0], ':', app[5])for app in android_final:if app[1] == 'COMMUNICATION' and (app[5] == '1,000,000,000+'or app[5] == '500,000,000+'or app[5] == '100,000,000+'):print(app[0], ':', app[5])
If we removed all the communication apps that have over 100 million installs, the average would be reduced by more than ten times:
如果我们删除所有安装了超过1亿个通信应用程序,则平均减少量将超过10倍:
under_100_m = []for app in android_final:n_installs = app[5]n_installs = n_installs.replace(',', '')n_installs = n_installs.replace('+', '')if float(n_installs) < 100000000:under_100_m.append(float(n_installs))sum(under_100_m) / len(under_100_m)under_100_m = []for app in android_final:n_installs = app[5]n_installs = n_installs.replace(',', '')n_installs = n_installs.replace('+', '')if float(n_installs) < 100000000:under_100_m.append(float(n_installs))sum(under_100_m) / len(under_100_m)
We see the same pattern for the video players category, which is the runner-up with 24,727,872 installs. The market is dominated by apps like Youtube, Google Play Movies & TV, and MX Player. The pattern is repeated for social apps (where we have giants like Facebook, Instagram, Google+, etc.), photography apps (Google Photos and other popular photo editors), or productivity apps (Microsoft Word, Dropbox, Google Calendar, Evernote, etc.).
我们在视频播放器类别中看到了相同的模式,它获得了24,727,872次安装,位居第二。 该市场由Youtube,Google Play影视和MX Player等应用主导。 对于社交应用程序(我们拥有巨人,如Facebook,Instagram,Google +等),摄影应用程序(Google相册和其他流行的照片编辑器)或生产力应用程序(Microsoft Word,Dropbox,Google Calendar,Evernote等)重复这种模式)。
Again, the main concern is that these app genres might seem more popular than they really are. Moreover, these niches seem to be dominated by a few giants who are hard to compete against.
同样,主要的担心是这些应用程序类型似乎比实际流行。 而且,这些壁ni似乎由一些难以与之抗衡的巨人所统治。
The game genre seems pretty popular, but previously we found out this part of the market seems a bit saturated, so we’d like to come up with a different app recommendation if possible.
游戏类型似乎很受欢迎,但之前我们发现市场的这一部分似乎有些饱和,因此,如果可能的话,我们想提出一个不同的应用程序推荐。
The books and reference genre looks fairly popular as well, with an average number of installs of 8,767,811. It’s interesting to explore this in more depth, since we found this genre has some potential to work well on the App Store, and our aim is to recommend an app genre that shows potential for being profitable on both the App Store and Google Play.
这些书籍和参考风格也相当受欢迎,平均安装数量为8,767,811。 对此进行更深入的研究很有趣,因为我们发现这种类型在App Store上具有一定的潜力,我们的目标是推荐一种在App Store和Google Play上都具有获利潜力的应用类型。
Let’s take a look at some of the apps from this genre and their number of installs:
让我们来看看这种类型的一些应用程序及其安装数量:
for app in android_final:if app[1] == 'BOOKS_AND_REFERENCE':print(app[0], ':', app[5])for app in android_final:if app[1] == 'BOOKS_AND_REFERENCE':print(app[0], ':', app[5])
The book and reference genre includes a variety of apps: software for processing and reading ebooks, various collections of libraries, dictionaries, tutorials on programming or languages, etc. It seems there’s still a small number of extremely popular apps that skew the average:
这本书和参考书目包括各种应用程序:用于处理和阅读电子书的软件,各种图书馆,词典,编程或语言教程等。似乎仍然有少数极受欢迎的应用程序使平均水平出现偏差:
for app in android_final:if app[1] == 'BOOKS_AND_REFERENCE' and (app[5] == '1,000,000,000+'or app[5] == '500,000,000+'or app[5] == '100,000,000+'):print(app[0], ':', app[5])for app in android_final:if app[1] == 'BOOKS_AND_REFERENCE' and (app[5] == '1,000,000,000+'or app[5] == '500,000,000+'or app[5] == '100,000,000+'):print(app[0], ':', app[5])
However, it looks like there are only a few very popular apps, so this market still shows potential. Let’s try to get some app ideas based on the kind of apps that are somewhere in the middle in terms of popularity (between 1,000,000 and 100,000,000 downloads):
但是,似乎只有几个非常流行的应用程序,因此这个市场仍然显示出潜力。 让我们尝试根据流行程度介于中间(介于1,000,000到1亿次下载之间)的应用程序类型来获取一些应用程序创意:
for app in android_final:if app[1] == 'BOOKS_AND_REFERENCE' and (app[5] == '1,000,000+'or app[5] == '5,000,000+'or app[5] == '10,000,000+'or app[5] == '50,000,000+'):print(app[0], ':', app[5])for app in android_final:if app[1] == 'BOOKS_AND_REFERENCE' and (app[5] == '1,000,000+'or app[5] == '5,000,000+'or app[5] == '10,000,000+'or app[5] == '50,000,000+'):print(app[0], ':', app[5])
This niche seems to be dominated by software for processing and reading ebooks, as well as various collections of libraries and dictionaries, so it’s probably not a good idea to build similar apps since there’ll be some significant competition.
这个利基市场似乎主要由用于处理和阅读电子书的软件以及各种图书馆和词典的集合所主导,因此构建类似的应用程序可能不是一个好主意,因为将会有一些激烈的竞争。
We also notice there are quite a few apps built around the book Quran, which suggests that building an app around a popular book can be profitable. It seems that taking a popular book (perhaps a more recent book) and turning it into an app could be profitable for both the Google Play and the App Store markets.
我们还注意到,围绕《古兰经》构建了许多应用程序,这表明围绕一本受欢迎的书构建应用程序可能会有利可图。 对于Google Play和App Store市场而言,似乎将一本受欢迎的书(也许是一本较新的书)并将其转变为一个应用可能是有利可图的。
However, it looks like the market is already full of libraries, so we need to add some special features besides the raw version of the book. This might include daily quotes from the book, an audio version of the book, quizzes on the book, a forum where people can discuss the book, etc.
但是,似乎市场上已经充满了图书馆,因此我们需要在本书的原始版本之外添加一些特殊功能。 这可能包括该书的每日报价,该书的音频版本,该书的测验,人们可以讨论该书的论坛等。
结论 (Conclusion)
In this project, we analyzed data about the App Store and Google Play mobile apps with the goal of recommending an app profile that can be profitable for both markets.
在此项目中,我们分析了有关App Store和Google Play移动应用程序的数据,目的是推荐一个对两个市场都有利可图的应用程序配置文件。
We concluded that taking a popular book (perhaps a more recent book) and turning it into an app could be profitable for both the Google Play and the App Store markets. Of course, we could do further analysis of this dataset to glean further insights, but as you can see, we can find some very valuable trends using just basic Python and the techniques covered in our free Python Fundamentals course.
我们得出的结论是,对于Google Play和App Store市场而言,拿一本受欢迎的书(也许是一本较新的书)并将其变成应用程序可能会有利可图。 当然,我们可以对该数据集做进一步分析以收集更多的见解,但是如您所见,仅使用基本的Python和免费的Python基础知识课程中介绍的技术,我们就能发现一些非常有价值的趋势。
(Ready to move on to the next level? Our intermediate Python programming course is free, too).
(准备进入下一个级别?我们的中级Python编程课程也是免费的)。
翻译自: https://www.pybloggers.com/2019/01/data-science-project-profitable-app-profiles-for-app-store-and-google-play/
数据科学项目:适用于App Store和Google Play的有利可图的应用配置文件相关推荐
- pca针对初学者_针对初学者和专家的12酷数据科学项目创意
pca针对初学者 The domain of Data Science brings with itself a variety of scientific tools, processes, alg ...
- 独家 | 手把手教你组织数据科学项目!(附代码)
作者:kdnuggets 翻译:和中华 校对:丁楠雅 本文约4200字,建议阅读10分钟. 本文介绍了一个工具可以帮助迅速构建一个标准但灵活的数据科学项目结构,便于实施和分享数据科学工作. 由Driv ...
- Apple App Store和Google Play 进行ASO有哪些区别?
今天柚鸥ASO带大家了解下Apple App Store和Google Play 进行ASO优化的区别: iTunes和Google Play中的关键字识别截然不同,相关性.竞争性.流量和搜索差异(人 ...
- 交通事故2018数据_现实世界数据科学项目:交通事故分析
交通事故2018数据 by Hari Santanam 通过Hari Santanam 现实世界数据科学项目:交通事故分析 (Real world data science project: traf ...
- 独家 | 为你的数据科学项目提供有力支撑——3个寻找数据集的最佳网站
作者:Angelia Toh,Self Learn Data Science联合创始人 翻译:李海明 校对:冯羽 本文约1000字,建议阅读5分钟 本文为你介绍3个寻找数据集的最佳网站. 标签:冠状病 ...
- api数据库管理_API管理平台如何增强您的数据科学项目
api数据库管理 Data scientists regularly use APIs (Application Programming Interfaces) to implement advanc ...
- 护理方面关于人工智能的构想_如何提出惊人的AI,ML或数据科学项目构想。
护理方面关于人工智能的构想 No Matter What People Tell You, Words And Ideas Can Change The World. - Robin Williams ...
- 数据科学生命周期_数据科学项目生命周期第1部分
数据科学生命周期 This is series of how to developed data science project. 这是如何开发数据科学项目的系列. This is part 1. 这 ...
- 数据科学项目_完整的数据科学组合项目
数据科学项目 In this article, I would like to showcase what might be my simplest data science project ever ...
最新文章
- MCSE2003学习之三
- linux下vi命令大全[转]
- 触发transition的几种方式--转
- ajax_post运用
- k8s Deployment
- Linux下配置jdk1.7
- 【阿里云镜像】配置阿里巴巴开源镜像站镜像——Epel镜像
- 直播回顾 | 菊风在智能硬件音视频领域的探索与实践
- Sqlite数据库锁死问题
- RCF—用于C++的进程间通讯(3)
- 微信手环1年多了,前主管终于出来聊了聊它是怎么诞生的
- 2023年湖北黄石初级工程师职称在哪里报名?评审条件是什么启程别
- 基于Android的上位软件,基于Android的电子套结机上位机软件设计
- 遇到问题--python-- pandas--常见问题积累
- Java:Java常考经典编程例题(二)
- #单调队列#洛谷 2698 [USACO12MAR]花盆Flowerpot
- 乌班图搭建sftp服务器
- C语言:爱因斯坦的数学题
- 传奇杀人魔戒的制作方法
- Git使用及安装教程