python 龙卷风_预测龙卷风强度
python 龙卷风
I will be using the Historical Tornado Tracks dataset from the National Oceanic and Atmospheric Administration (NOAA) and the National Weather Service (NWS) to predict a tornado’s F-scale rating. The data I am using can be found here.
我将使用美国国家海洋和大气管理局(NOAA)和美国国家气象局(NWS)的“历史龙卷风轨迹”数据集来预测龙卷风的F等级定级。 我正在使用的数据可以在这里找到。
First, lets discuss what the F-scale is. Also called the Fujita scale, the F-scale rating was introduced in 1971 by Ted Fujita and Allen Pearson. It was designed as a way to measure the impact a tornado had on man-made structures and vegetation. It is not a method of measuring a tornado’s width, path length, or wind speed.
首先,让我们讨论一下F标尺。 F等级也称为Fujita量表,由Ted Fujita和Allen Pearson于1971年推出。 它被设计用来衡量龙卷风对人造结构和植被的影响。 它不是测量龙卷风的宽度,路径长度或风速的方法。
While the original scale had 13 theoretical categories, Fujita intended for only six to be used. These range from F0-F5 on the scale. The categories and their descriptions can be seen below:
最初的量表具有13个理论类别,而藤田只打算使用6个。 范围从F0-F5。 类别及其描述如下所示:

Now that we’re all familiar with the rating system, I’ll dive into the data. While the dataset includes all US tornadoes from 1950–2018, tornadoes from 1950–1972 were retroactively rated by NOAA. Included are features describing starting and ending latitudes and longitudes, fatalities, injuries, loss and crop loss (in millions of dollars), path length, path width, and more.
现在我们都熟悉评分系统,我将深入研究数据。 虽然数据集包含1950-2018年的所有美国龙卷风,但NOAA追溯评估了1950-1972年的龙卷风。 其中包括描述起始和结束纬度和经度,死亡人数,伤害,损失和农作物损失(百万美元),路径长度,路径宽度等的功能。
First, let’s look at the distribution of F-ratings in the data:
首先,让我们看一下数据中F等级的分布:

As you can see in the image above, the data has very imbalanced classes. Over 46% of all tornadoes since 1950 are classified as F0's, while not even 0.1% of them were F5’s. This will introduce several challenges with classification which I will go over later.
如上图所示,数据具有非常不平衡的类。 自1950年以来,所有龙卷风中超过46%被归类为F0,而其中甚至没有0.1%是F5。 这将为分类带来一些挑战,我将在稍后进行介绍。
To start any classification problem, let’s determine our baseline. We’ll use the majority class as our baseline, which, as we can see in the distribution charts, is 46 percent. For those not familiar with classification, all this means is that if we guessed that every entry in the dataset was an F0 (the majority class), we would be correct almost half of the time. So how can we improve our guess rate?
要开始任何分类问题,让我们确定基线。 我们将以多数类作为基准,正如我们在分布图中看到的那样,该基准为46%。 对于那些不熟悉分类的人来说,这一切意味着,如果我们猜测数据集中的每个条目都是F0(多数类),那么几乎一半的时间我们都是正确的。 那么我们如何提高猜测率呢?
Let’s move on to a simple model: Random Forest classifier (RF). One thing to note is that at this point I have already done some feature selection to produce a better result out of the Random Forest model. More on that in a minute.
让我们继续一个简单的模型:随机森林分类器(RF)。 需要注意的一件事是,在这一点上,我已经进行了一些功能选择,以根据“随机森林”模型产生更好的结果。 一分钟内可以了解更多。

So running a RF model on the data, we get this confusion matrix. More info about confusion matrices can be found here. The accuracy we get from this model is 66 percent, a significant improvement over our baseline of 46 percent.
因此,对数据运行RF模型,我们得到了这个混淆矩阵。 有关混乱矩阵的 更多信息 ,请 参见此处。 我们从该模型获得的准确性为66%,比我们的基准46%有了显着提高。

As I said earlier, I have already done some feature selection to improve two factors: general accuracy, and the accuracy of the minority classes. This is a list of the current features and their importance in the model. Now let’s think back to our definition of the F-scale — it is simply a measurement of a tornado’s damage to man-made structures and crops. So how does the model perform when it is only fed those columns?
如前所述,我已经进行了一些特征选择以提高两个因素:总体准确性和少数类的准确性。 这是当前功能及其在模型中的重要性的列表。 现在让我们回想一下F刻度的定义-它只是龙卷风对人造结构和农作物造成的损害的一种度量。 那么,当模型仅填充这些列时,其性能如何?
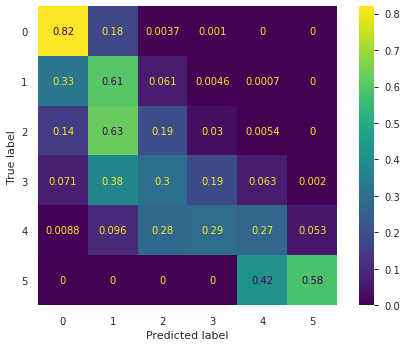
Here is the confusion matrix when the model is trained on only the Fatalities, Injuries, Loss, and Crop Loss columns. The model had a 62 percent accuracy on these four columns. While this may be a surprisingly small drop in accuracy, it is understandable considering these are the most important features to the Fujita Scale.
当仅在“死亡率”,“伤害”,“损失”和“作物损失”列上训练模型时,这是混淆矩阵。 该模型在这四个色谱柱上的准确度为62%。 尽管这可能是精度上出乎意料的小幅下降,但考虑到这些是Fujita秤最重要的功能,这是可以理解的。
So what else can be done to improve the accuracy of the predictions? As we can see in the distributions image, our classes are extremely imbalanced. To counter this natural disparity in the data, there are a couple possible solutions.
那么还有什么可以做来提高预测的准确性呢? 从分布图中可以看到,我们的类非常不平衡。 为了应对数据中的这种自然差异,有两种可能的解决方案。
The first option is to use the SMOTE algorithm to over-sample the minority classes. The algorithm does this by creating new entries that lie in between the existing entries. While this method doesn’t automatically guarantee that the new entries are realistic, the nearest neighbors methodology should produce realistic entries in my case.
第一种选择是使用SMOTE算法对少数类进行过度采样。 该算法通过创建位于现有条目之间的新条目来实现此目的。 尽管此方法不能自动保证新输入的内容是真实的,但在我的情况下,最近邻居方法应生成实际的输入。


Here is the confusion matrix and the classification report for the SMOTE algorithm. I have added back in all of the columns listed in the feature importance image.
这是SMOTE算法的混淆矩阵和分类报告。 我重新添加了功能重要性图像中列出的所有列。
While the 62 percent accuracy is identical to our previous model, the confusion matrix clearly shows an improvement in correct predictions.
尽管62%的准确度与我们之前的模型相同,但是混淆矩阵清楚地表明了正确预测的改进。


The second option would be utilizing the NearMiss algorithm. This method under-samples the dataset to include less counts of the majority classes.
第二种选择是利用NearMiss算法。 此方法对数据集进行欠采样以包含较少的多数类计数。
The confusion matrix plot looks nearly identical to the SMOTE plot, with slightly tighter spreads around correct predictions and a minor improvement predicting F5’s. As shown by the accuracy and recall scores, the NearMiss model is a small improvement over the SMOTE algorithm.
混淆矩阵图看起来几乎与SMOTE图相同,围绕正确预测的散布略紧,而预测F5的改进较小。 如准确性和召回力得分所示,NearMiss模型是对SMOTE算法的小改进。
I’ve learned two major things during the course of this project. The first thing being that tornadoes are difficult to classify. While 63 percent accuracy certainly isn’t terrible, I know that better scores are achievable (though outside of the scope of this project).
在这个项目的过程中,我学到了两件事。 首先是龙卷风很难分类。 虽然63%的准确度当然并不可怕,但我知道可以取得更好的成绩(尽管超出了该项目的范围)。
The second thing was the knowledge I gained from working with data that contained such divided classes. Before working on this project, I didn’t know about the different techniques used to deal with minority classes. The results I have achieved implementing these techniques should speak for themselves in proving their value.
第二件事是我从处理包含此类分类的数据中获得的知识。 在从事该项目之前,我不了解用于处理少数群体的不同技术。 我实现这些技术所取得的成果应该证明自己的价值。
翻译自: https://medium.com/@LukiePookie/predicting-tornado-intensity-547398578710
python 龙卷风
http://www.taodudu.cc/news/show-3619490.html
相关文章:
- 龙卷风路径_龙卷风路径图片壁纸 60 Tornado Alley - 猫猫壁纸酷 wallcoo.com
- java代码实现龙卷风_Java-使用二叉树实现快速排序-遁地龙卷风
- [概念] 敏感性分析(Sensitivity Analysis) 和龙卷风图(tornado diagram)
- 风险定量分析工具之龙卷风图
- Oracle中tnsping无响应
- Oracle,tnsping通的条件
- oracle监听延迟,求教,tnsping本机延迟非常大,求解决思路
- Tnsping 和TCP/IP 中的ping 的区別
- oracle ping 超时_急啊! tnsping oracle服务器时断时续,平均隔5-8秒超时一次(网络正常 ping一直都通)...
- oracle11g tnsping特别慢或者数据库连不上
- oracle ping 超时_tnsping无法ping通的问题,TNS12535 TNS操作超时 (服务器环境:window server 2008R2 数据库环境:oracle 11 g)...
- oracle ping 超时_tnsping无法ping通的问题,TNS-12535 TNS操作超时 (服务器环境:window server 2008R2 数据库环境:oracle 11 g)...
- oralce 客户端安装tnsping
- tnsping通oracle连不上,tnsping通但sqlplus连接不上的处理
- oracle ping 超时_对于tnsping的连接超时的功能补充
- oracle怎么ping别人,Oracle中tnsping命令解析
- oracle tnsping 怎么用,oracle 11.2.0 tnsping ORCL; 报错,该如何解决
- Oracle tnsping 03505,oracle客户端tnsping,提醒:TNS-03505: 无法解析名称
- Oracle tnsping 03505,tnsping 命令
- tnsping用法
- tnsping命令详解
- tnsping命令解析
- nextInt()
- random.nextInt()的用法
- java nextint后有空格,Java中nextInt()后接nextLine()读取不到数据
- random.nextint()详解
- nextInt
- NextInt()和NextLine()
- nextInt() 接收异常bug
- scanner中nextInt和nextLine的顺序问题
python 龙卷风_预测龙卷风强度相关推荐
- python二手车价格预测_天池_二手车交易价格预测数据分析
字典 FieldDescription SaleID 交易ID,唯一编码 name 汽车交易名称,已脱敏 regDate 汽车注册日期,例如20160101,2016年01月01日 model 车型编 ...
- Python 进阶_生成器 生成器表达式
目录 目录 相关知识点 生成器 生成器 fab 的执行过程 生成器和迭代器的区别 生成器的优势 加强的生成器特性 生成器表达式 生成器表达式样例 小结 相关知识点 Python 进阶_迭代器 & ...
- 有关糖尿病模型建立的论文_预测糖尿病结果的模型比较
有关糖尿病模型建立的论文 项目主题 (Subject of the Project) The dataset is primarily used for predicting the onset of ...
- arima 预测模型_预测未来:学习使用Arima模型进行预测
arima 预测模型 XTS对象 (XTS Objects) If you're not using XTS objects to perform your forecasting in R, the ...
- 用python做时间序列预测一:初识概念
用python做时间序列预测一:初识概念 利用时间序列预测方法,我们可以基于历史的情况来预测未来的情况.比如共享单车每日租车数,食堂每日就餐人数等等,都是基于各自历史的情况来预测的. 什么是时间序列? ...
- Python二手房价格预测(二)——数据处理及数据可视化
系列文章目录 数据获取部分:Python二手房价格预测(一)--数据获取 文章目录 系列文章目录 一.数据清洗 二.数据可视化 总结 一.数据清洗 1.先导入需要的库: import pandas a ...
- python股市_如何使用python和破折号创建仪表板来主导股市
python股市 始终关注大局 (Keep Your Eyes on the Big Picture) I've been fascinated with the stock market since ...
- Python二手车价格预测(二)—— 模型训练及可视化
系列文章目录 一.Python数据分析-二手车数据获取用于机器学习二手车价格预测 二.Python二手车价格预测(一)-- 数据处理 文章目录 系列文章目录 前言 一.明确任务 二.模型训练 1.引入 ...
- Python二手房价格预测(三)——二手房价格预测模型baseline
系列文章目录 一.Python二手房价格预测(一)--数据获取 二.Python二手房价格预测(二)--数据处理及数据可视化 文章目录 系列文章目录 前言 一.数据处理 二.模型训练 1.引入库 2. ...
最新文章
- hibernate.hbm2ddl.auto配置及意义
- 机器学习与差分隐私(认证鲁棒性和隐私保护)
- 特斯拉副总裁回应“质量不合格”报道:离谱 已准备起诉
- [Ext JS]5.11 轻量版的树- treelist
- Java中的Flyweight设计模式
- MySQL性能调优的10个方法
- 运用Excel实现描述性统计分析
- Python中的缩进(unindent)问题
- python实训报告怎么写_python实验报告
- Ardunio开发实例-TSL2591数字环境光传感器
- 银行利息计算公式推导(存款,贷款)
- 我唯一的愿望就是等你
- python turtle画太极的代码_python turtle 绘制太极图的实例
- 南方的X-Men看过来〜Cocos2d-x开发者沙龙(广州站)即将举办!
- 实现Taro 项目拆分到多个分包(Taro和原生混合开发)
- python两列时间间隔计算器_python时间差计算器时分秒_python 实现日期计算器
- poi读取excel多层表头模板写入数据并导出
- 如何度过8天长假?小灰推荐几部经典电影给大家!
- FatMouse' Trade--贪心
- 网络安全基础知识篇----nginx安装
热门文章
- Python计算两个日期之间天数
- TYPESDK手游聚合SDK服务端设计思路与架构之一:应用场景分析
- C语言nullptr错误,C/C++中的NULL与nullptr
- JAVA设置环境变量为什么要JAVA_HOME,可以去掉吗?可以去掉,直接添加Path即可
- 查找算法【二叉查找树】 - 二叉查找树的删除
- air 开发 android,简介开发运行于Android的AIR程序
- 数字 3D 可视化选矿工艺 | 智慧矿山
- 电脑显示系统无法自动配置网络连接服务器,win10系统本地连接IP配置出现故障无法连接网络如何解决-win10 网络...
- javaScript 对象添加属性和创建js对象的方式(以及理解:“无法给构造函数添加新的属性“)
- 电子书下载:iPhone and iPad Apps for Absolute Beginners iOS 5 Edition