如何确定抽样统计的最小样本量(附:随机抽样统计的抽样误差Excel计算表格)...
在电视节目中经常看到关于选举的报道中经常会后有支持率的数字,例如:调查结果为
- a方支持率为45.3%;
- b方支持率为30.2%;
- c方支持率为8.5%;
- ...
最后都会说明一下,此次电话调查的数量2300,置信度为95%﹐最大容许误差为±2.5%,这就是抽样调查的典型情景:一个大的集合(比如:数千万选民)做一次调查的成本较高,抽样调查可以低成本的用近似的(可接受的)数据反映实际情况;在用户调研中,也经常通过通过抽样调查的方式并对比打分的方法做评估。
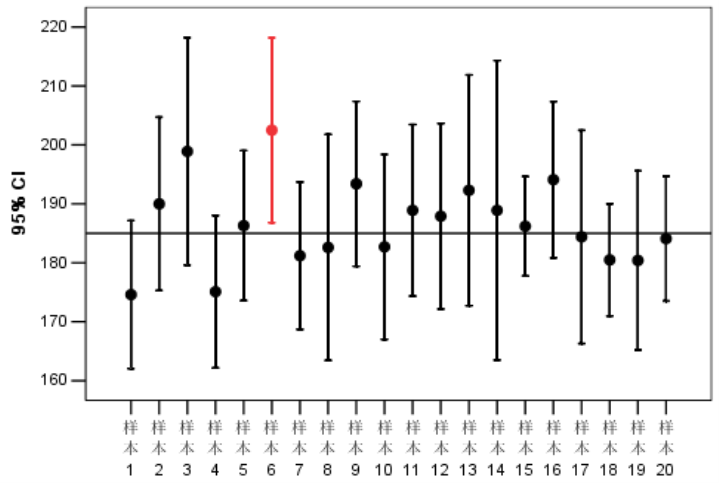
抽样误差: 假如相同规模的抽样调查进行多次, 抽样均值在真实均值的上下波动,相对于整体均值的偏移波动就是抽样误差,而这个误差的分布是符合正态分布的,例如下图: 横轴为整体的均值,圆点是每次抽样的均值,而红色那次抽样就是加上误差后都未覆盖到均值线);
最小抽样量的计算公式: 抽样量需要 > 30个才算足够多,可以用以下近似的误差/样本量估算公式;
n: 为样本量;
:总体方差,抽样个体值和整体均值之间的偏离程度,抽样数值分布越分散方差越大,;
E: 为抽样误差(可以根据均值的百分比设定),由于是倒数平方关系,抽样误差减小为1/2,抽样量需要增加为4倍;
: 为可靠性系数,即置信度,置信度为95%时,
=1.96,置信度为90%时,
=1.645
为了体现相对差距: 假设抽样均值为y
相对抽样误差 h = E / y
C= σ / y
以下是基于抽样得分的抽样误差估算表格:
| 置信度 | 相对抽样误差(假设:C=0.4) | ||||
| 1% | 2% | 3% | 4% | 5% | |
| 95% | 6147 | 1537 | 683 | 384 | 246 |
| 90% | 4330 | 1082 | 481 | 271 | 173 |
如果是基于胜出率,支持率等: 分值为0/1状态分布,公式拟合为
π为按照经验得出的最后比例,在未知时π可取50%,待算出结果后再重新拟合,比例越悬殊需要的样本量越少;
<!--td {color:#000000; font-size:12.0pt; font-family:宋体; font-weight:400; font-style:normal; text-decoration:none; text-align:general; vertical-align:middle; mso-number-format:General; mso-protection:locked visible; }.et9 {color:#000000; font-size:10.5pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:center; vertical-align:top; white-space:normal; border-left:.5pt solid #000000; border-right: .5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:'0%'; mso-protection:locked visible; }.et10 {color:#000000; font-size:10.5pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:center; vertical-align:top; border-right: .5pt solid #000000; border-top:.5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:General; mso-protection:locked visible; }.et11 {color:#000000; font-size:10.5pt; font-family:宋体; font-weight:400; font-style:normal; text-decoration:none; text-align:justify; vertical-align:top; white-space:normal; border-right: .5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:General; mso-protection:locked visible; }.et12 {color:#000000; font-size:10.5pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:general; vertical-align:top; white-space:normal; border-right: .5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:'0%'; mso-protection:locked visible; }.et13 {color:#000000; font-size:10.5pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:general; vertical-align:top; white-space:normal; border-right: .5pt solid #000000; border-top:.5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:'0%'; mso-protection:locked visible; }.et14 {color:#000000; font-size:10.5pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:center; vertical-align:top; border-right: .5pt solid #000000; border-top:.5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:General; mso-protection:locked visible; }.et15 {color:#000000; font-size:9.0pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:center; vertical-align:middle; border-left:.5pt solid #000000; border-right: .5pt solid #000000; border-top:.5pt solid #000000; mso-number-format:General; mso-protection:locked visible; }.et16 {color:#000000; font-size:9.0pt; font-family:宋体; font-weight:700; font-style:normal; text-decoration:none; text-align:center; vertical-align:middle; border-left:.5pt solid #000000; border-right: .5pt solid #000000; border-bottom:.5pt solid #000000; mso-number-format:General; mso-protection:locked visible; }-->
| 置信度 | 相对抽样误差 | ||||
| 1% | 2% | 3% | 4% | 5% | |
| 95% | 9604 | 2401 | 1067 | 600 | 384 |
| 90% | 6765 | 1691 | 752 | 423 | 270 |
大部分的电话抽样调查:取样量一般在2000-5000;
如何确定抽样统计的最小样本量(附:随机抽样统计的抽样误差Excel计算表格)...相关推荐
- 如何确定抽样统计的最小样本量(附:随机抽样统计的抽样误差Excel计算表格)
在电视节目中经常看到关于选举的报道中经常会后有支持率的数字,例如:调查结果为 a方支持率为45.3%: b方支持率为30.2%: c方支持率为8.5%: ... 最后都会说明一下,此次电话调查的数量2 ...
- python 假设检验 样本量太大_【Python】统计科学系列之最小样本量计算
首页 专栏 python 文章详情 0 统计科学系列之最小样本量计算 张俊红发布于 35 分钟前 这一篇我们讲讲统计中的最小样本量计算.大家先想想为什么叫最小样本量,而不是最大或者直接叫样本量计算呢? ...
- 假设检验中两类错误及最小样本量计算
脚注: 以下内容均为个人总结,便于日后查阅.如有不对地方,还请及时指正. 案例: 在互联网等行业中,大家会对产品.排序模型.机制策略等模块不断迭代/创新,来提升整个App的用户体验.那么,怎样 ...
- 运营策略实验最小样本量的确定
1.问题 传统运营业务是人力驱动的.人力的有限性,必然导致运营覆盖的用户往往是有限的,比如头部用户或者高潜用户.因此,运营业务线的数据分析师往往遇到小样本量的策略实验. 样本过小通常有如下问题:1)效 ...
- UA MATH567 高维统计 专题0 为什么需要高维统计理论?——协方差估计的高维效应与Marcenko-Pastur规则
UA MATH567 高维统计 专题0 为什么需要高维统计理论?--协方差估计的高维效应与Marcenko-Pastur规则 上一讲我们介绍了在实验中,线性判别分析的判别误差会随着维度的上升而上升,而 ...
- oracle 数据统计收集,Oracle 10g收集数据库统计信息
1.需求概述 某数据库由于整体统计信息不准确,多次出现部分业务SQL选错执行计划,从而导致性能下降影响到最终用户体验,目前通过SQL_PROFILE绑定执行计划临时解决,但此方法不够灵活,后续维护工作 ...
- elasticsearch 条件去重_elasticsearch 笔记四 之聚合查询之去重计数、基础统计、百分位、字符串统计...
这一节笔记还是聚合查询,以下是本节目录:去重统计 cardinality 基础统计 stats 百分位 percentiles 字符串统计 string_stats 1.去重统计 cardinalit ...
- 试验设计系列(一)| 样本量与功效(power)的计算
在「临床医师看过来」系列的前18篇文章中,我们介绍了基础的统计分析及JMP入门操作.从本文开始,我们将通过三篇系列文章来陆续介绍临床试验的一些内容,分别从样本量.随机分组.等效性检验三个方面介绍临床试 ...
- GB/T25915.1法规基本标准-附 录 B(资料性)等级划分计算
附 录 B(资料性)等级划分计算实例 B.1 示例1 B.1.1 某个洁净室占地面积18m2,规定洁净度级别为动态ISO5级.使用采样流量为28.3L/min的 离散粒子计数器进行分级测试.2个关注粒 ...
最新文章
- 编程将 .Net Assembly 里的类注册成 COM 类
- 把列表变成列向量_线性代数的本质11 抽象向量空间
- spring—事务控制
- PL/SQL配置文件解析
- php在线答题怎么评分,在线答题系统怎样进行阅卷?
- [深度学习-实践]GAN入门例子-利用Tensorflow Keras与数据集CIFAR10生成新图片
- 我的世界服务器按键显示mode,【服务器相关】【求助!】关于服务器中使用gamemode等命令错误。...
- python爬虫 去哪网数据分析
- Leetcode: One Edit Distance
- Echarts官网无法打开的问题
- ODL之VTN详解-Mac Map
- CDH 6系列(CDH 6.0.0、CHD 6.1.0等)安装和使用
- 关于C语言两个小游戏的提示和源码(猜词游戏与控制移动游戏)
- 智能驾驶+多元化长尾应用场景,什么样的公司最终胜出?
- uni-app app平台微信支付
- 简单而有韵味,让你get最浪漫的表白编程代码大全
- 微信小程序获取输入框(input)内容
- 做SEO优化第六步:设置Title、keywords和Description
- 自学java,学多久可以找到工作?
- win98系统常见问题解决方法(转)