利用Python进行市场购物篮分析——入门篇
我们从日常生活中获取数据,大量的商业活动以及社交活动为我们提供了丰富的数据。如何从这些看似无用的数据中提取价值,这对于我们程序猿来说应该是我们的职责所在。今天就让我们用Python来进行市场购物篮的分析。
文中需要用到MLxtend,MLxtend是一个基于Python的开源项目,主要为日常处理数据科学相关的任务提供了一些工具和扩展。项目的Github地址:http://github.com/rasbt/mlxtend。
python分析师可以使用许多数据分析工具,但知道在那些情况下使用那些数据分析工具可能很困难。一种有用的(但却被忽视)的技术称为关联分析,它尝试在大型数据集中查找相关商品之间的关联。一个具体的应用通常称为市场篮子分析。最经典引用的市场篮子分析的例子是所谓的“啤酒和尿布”案例。基本的故事是,大型零售商能够挖掘他们的交易数据,并找到一个意想不到的购买啤酒和婴儿尿布的购买模式。
不幸的是,这个故事很可能是一个数据城市传奇。然而,它是挖掘事务数据可以获得的商业价值的示例。
如果你对Python数据科学有一些基本的了解,可能你的第一个倾向就是考虑scikit学习一个现成的算法。然而,scikit-learn不支持这种算法。幸运的是,Sebastian Raschka 提供了非常有用的具有Apriori算法的MLxtend库的,以方便我们进一步分析我们所掌握的数据。
接下来我将演示一个使用此库来分析相对较大的在线零售数据集的示例,并尝试查找有趣的购买组合。在本文结尾处,我希望你能掌握将其应用于你自己的数据集的基本方法。
为什么是关联分析?
在当今的世界,有许多复杂的数据分析方法(聚类,回归,神经网络,随机森林,SVM等)。这些方法中的很多种所面临的挑战在于它们可能难以调整,并需要相当多的数据准备和特征工程才能获得好的结果。换句话说,它们都非常强大,但需要掌握很多知识才能正确实现。
关联分析对数学知识的掌握要求非常低,而且结果易于向非技术人员解释。此外,它是一种无监督的学习工具,可以查找隐藏的模式,因此对数据准备和特征工程的需求有限。对于某些数据探索案例来说,这是一个很好的开始,并且可以发现使用其他方法深入了解数据的方式。
另外一个额外的好处,MLxtend库中的python实现对于非常熟悉scikit-learn 和pandas应该是非常简单的。由于所有这些原因,我认为这是一个有用的工具来帮助你解决数据分析实际问题。
关联分析101
理解关联分析中常用使用的几个术语很重要。在介绍数据挖掘是为那些有兴趣了解这些定义和算法实现的人,让他们对关联分析的数学方法有一个基本的概念。
关联规则通常如下:{Diapers} - > {Beer},这意味着在同一交易中购买尿布的客户之间和购买啤酒之间存在很强的关系。
在上面的例子中,{Diaper}是前提,{Beer}是后果。前提和后果可以包含很多内容,换句话说,就是类似{Diaper,Gum} - > {Beer,Chips}也是一个有效的关联规则。
信心是对关联规则可靠性的度量。上述例子中有0.5的信心意味着在购买了Diaper和Gum的情况下,有50%的可能去购买Beer和Chips。对于产品推荐,50%的置信度可能是完全可以接受的,但在医疗情况下,此级别可能不够高。
如果两个规则是独立的,Lift是观察到的支持与预期的支持的比率(lift解释详见维基百科)。基本的经验法则是Lift接近1表示规则完全独立。Lift> 1通常更“有趣”,可以表示这是有用的规则模式。
最后一个注意事项,与数据有关。此分析要求将交易的所有数据包含在1行中,并且编码方式应为one-hot编码(了解one-Hot编码)。了解MLxtend 的文档对了解如何运用是非常有用:
本文的具体数据来自UCI机器学习存储库,数据代表了2010-2011年英国零售商的交易数据。这主要代表的是批发商的销售数据,所以它与消费者购买模式略有不同,但仍然是一个有用的案例研究。
代码讲解
可以使用pip安装MLxtend,只有安装了MLxtend下面的代码才能真正运行。一旦安装完毕,下面的代码将会开始工作。我已经将源代码上传至Github,以方便你的下载。
获取我们的Pandas和MLxtend代码导入并读取数据:
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
df=pd.read_excel('http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx')
df.head()
我们需要做一点数据处理。首先,一些数据描述中具有需要删除的空格。我们还会删除没有发票编号的行,并删除信用交易(发票编号包含C)。
df['Description'] = df['Description'].str.strip()
df.dropna(axis=0, subset=['InvoiceNo'], inplace=True)
df['InvoiceNo'] = df['InvoiceNo'].astype('str')
df = df[~df['InvoiceNo'].str.contains('C')]
数据清理完成后,我们需要将每个产品进行one-hot编码。为了保持数据集小,我选择只是看法国的销售记录。然而,在下面的其他代码中,我将这些结果与德国的销售进行比较。进一步的国家比较将会是有趣的调查。
basket = (df[df['Country'] =="France"].groupby(['InvoiceNo', 'Description'])['Quantity'].sum().unstack().reset_index().fillna(0).set_index('InvoiceNo'))
以下是前几列的样子(注意,我在列中添加了一些数字来说明这个概念,这个例子中的实际数据全是0).
数据中有很多零,但是我们还需要确保将任何正则转换为1,而将0设置为0。此步骤将完成数据的one-hot编码,并删除邮资列:
def encode_units(x):if x <= 0:return 0if x >= 1:return 1
basket_sets = basket.applymap(encode_units)
basket_sets.drop('POSTAGE', inplace=True, axis=1)
既然数据的结构是正确,我们可以生成支持至少7%的频繁项目集(选择这个数字,可以帮助我得到更多有用的例子。)
frequent_itemsets = apriori(basket_sets, min_support=0.07, use_colnames=True)最后一步是产生相应的信心和提升的规则:
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
rules.head()
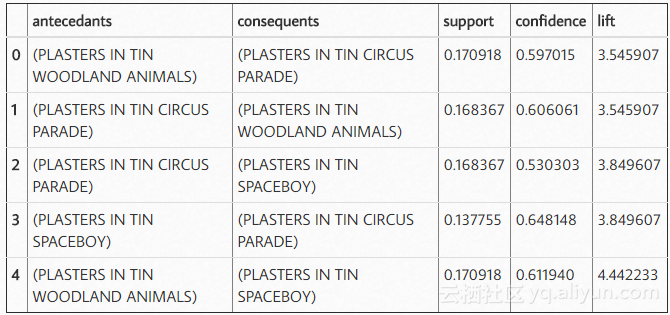
这就是这个项目的一切!
现在,最棘手的部分是弄清楚我们得到的这些结论告诉我们什么了。可能绝大多数程序猿不太关注。例如,我们可以发现很多关联规则具有很高的提升价值,这意味着它的发生频率可能会高于交易和产品组合数量的预期值。这部分分析是行业知识将派上用场的地方。由于我没有,所以我只是想找几个说明性的例子。
我们可以使用标准的pandas code来过滤数据帧。在这种情况下,寻找一个lift(6)和高信度(.8):
rules[ (rules['lift'] >= 6) &(rules['confidence'] >= 0.8) ]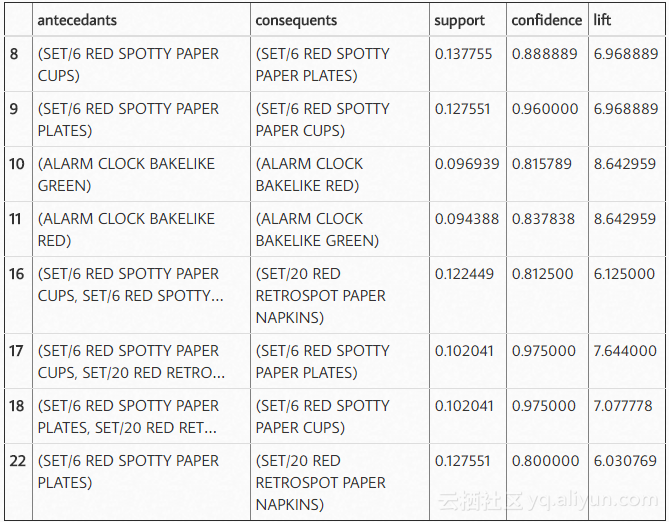
在查看规则时,可以发现似乎绿色和红色闹钟是一起购买的,红纸杯,餐巾纸和纸板是以总体概率提高的方式一起购买的。
您可能想要看看有多大的机会可以使用一种产品的受欢迎程度来推动另一种产品的销售。例如,我们可以看到,我们销售340个绿色闹钟,但只有316个红色闹钟,所以也许我们可以通过科学的方法来推动更多的红色闹钟销售。
basket['ALARM CLOCK BAKELIKE GREEN'].sum()
340.0
basket['ALARM CLOCK BAKELIKE RED'].sum()
316.0我们来看看德国有什么流行的组合呢?
basket2 = (df[df['Country'] =="Germany"].groupby(['InvoiceNo', 'Description'])['Quantity'].sum().unstack().reset_index().fillna(0).set_index('InvoiceNo'))
basket_sets2 = basket2.applymap(encode_units)
basket_sets2.drop('POSTAGE', inplace=True, axis=1)
frequent_itemsets2=apriori(basket_sets2,min_support=0.05, use_colnames=True)
rules2= association_rules(frequent_itemsets2, metric="lift", min_threshold=1)
rules2[ (rules2['lift'] >= 4) &(rules2['confidence'] >= 0.5)]
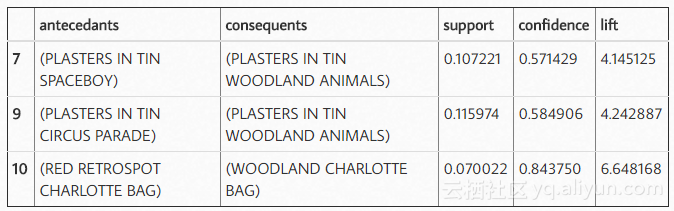
似乎除了大卫·哈塞尔夫以外,德国人喜欢锡太太雄和林地动物的Plaster。
在非常认真的情况下,熟悉数据的分析师可能会有十几个不同的问题,即这种类型的分析可以发挥商业价值。我没有将此分析复制到额外的国家或客户组合,但是由于上述基本的pandas代码,整个过程将相对简单。
结论
关联分析有一个非常好的方面是它很容易运行,相对容易解释。如果您没有使用MLxtend和关联分析,则使用基本Excel分析找到这些模式将是非常困难。使用python和MLxtend,分析过程相对简单,如果你了解Python,你可以访问python生态系统中的所有其他可视化技术和数据分析工具。
最后,我建议您查看MLxtend库的其余部分。如果您在使用scikit-learn做工作,可以了解并熟悉MLxtend,以及如何增加数据科学工具包中的一些现有工具。
本文由北邮@爱可可-爱生活老师推荐,@阿里云云栖社区组织翻译。
利用Python进行市场购物篮分析——入门篇相关推荐
- 数据分析之市场购物篮分析流程
数据分析是企业了解市场.挖掘信息潜能的最佳方式,不同的企业在数据分析方面有着不同的做法,能带来不同的效果,因而很多企业都万分重视.今天本文要为大家讲解的是市场购物篮分析流程,希望企业能够从中受益. 市 ...
- 市场购物篮分析 Market Basket Analysis
购物篮分析最主要的目的在于找出什么样的东西应该放在一起?商业上的应用在藉由顾客的购买行为来了解是什么样的顾客以及这些顾客为什么买这些产品,找出相关的联想(association)规则,企业藉由这些规则 ...
- python 关联分析算法的包_Python 极简关联分析(购物篮分析)
关联分析,也称购物篮分析,本文目的: 基于订单表,用最少的python代码完成数据整合及关联分析 文中所用数据下载地址: 使用Python Anaconda集成数据分析环境,下载mlxtend机器学习 ...
- python数据分析与挖掘实战(商品零售购物篮分析)
一.引言 购物篮分析是商业领域最前沿.最具挑战性的问题之一,也是许多企业重点研究的问题.购物篮分析是通过发现顾客在一次购买行为中放入购物篮中不同商品之间的关联,研究顾客的购买行为,从而辅助零售企业制定 ...
- 啤酒和尿不湿?购物篮分析、商品关联分析和关联规则算法都给你搞清楚(上—理论篇)
不管是不是搞数据分析的,相信应该都听过啤酒尿不湿的故事,说的是美国的沃尔玛超市管理人员分析销售数据时发现了一个令人难以理解的现象:"啤酒"与"尿布湿"这两件看上 ...
- tableau linux无网络安装_举个栗子!Tableau 技巧(127):购物篮分析之关联购买
购物篮分析(Market Basket Analysis)是通过顾客的购物篮信息研究其购买行为.主要目的在于找出什么样的东西应该放在一起.通过分析顾客的购买行为来探知顾客的属性及购买某些商品的可能原因 ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)(购物篮分析)
在各种数据挖掘算法中,关联规则挖掘算是比较重要的一种,尤其是受购物篮分析的影响,关联规则被应用到很多实际业务中,本文对关联规则挖掘做一个小的总结. 首先,和聚类算法一样,关联规则挖掘属于无监督学习方法 ...
- 108_Power Pivot购物篮分析分组GENERATE之笛卡尔积、排列、组合
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 1.背景 昨天在看论坛帖子时候(帖子),看到一个关于SKU组合的问题,有很多M大佬都给出了处理方案,于是想用dax也写一个 ...
- 数据挖掘实战—商品零售购物篮分析
文章目录 引言 一.数据探索性分析 1.数据质量分析 1.1 缺失值分析 1.2 异常值分析 1.3 重复数据分析 2.数据特征分析 2.1 描述性统计分析 2.2 分布分析 2.2.1 商品热销情况 ...
最新文章
- 卷积神经网络原理_怎样设计最优的卷积神经网络架构?| NAS原理剖析
- Android TouchEvent 分发流程
- java 中pc寄存器的作用_既然有PC寄存器,栈帧里的返回地址的作用是什么?
- IOS15 的UITableViewController 如何初始化
- python 解方程 sympy_用Python和Sympy求解方程并得到数值答案
- dbm和mysql使用场景_mysql基本用法总结
- msdb 数据库_如何检索有关存储在MSDB数据库中的SSIS包的信息
- 深度解析艾瑞咨询《2017年度中国商业智能行业研究报告》
- 打印出来只有a4纸一半 预览是正常的_还需要去打印店?能随身使用的便携打印机:汉印MT800评测...
- php smarty配置文件,Smarty配置文件
- jmc线程转储_Java线程转储– VisualVM,jstack,kill -3,jcmd
- Shadow DOM系列1-简介
- 解决摹客iDoc插件在Sketch中无法正常使用,切图和标注尺寸不一致的问题
- java怎么反编译_java如何进行反编译
- eclipse编译Duet固件的完整过程
- Android架构学习之路三-MVX
- 中兴路由器,交换机DHCP原理,dhcp配置,实例
- android中使用hbuilder混合开发中提示未添加plugintest模块 请参考283
- Rust + GO 大战 C/CPP + JAVA
- 牛客小白月赛21 I I love you(dp的优化)
热门文章
- go ip过滤_智慧识别“GOIP”呼转 罪犯无所遁形
- 汇编SHR、SHL、SAR、SAL、ROL、ROR、RCL、RCR指令
- matlab dcc,重金感谢(dcc-mvgarch)!
- 印度紧盯中国,计划在东海岸建新海军基地
- YOLO-V5 算法和代码解析系列 —— 学习路线规划综述
- 5.随机输入一个整数,判断输入的数是正数、负数还是0,如果是正数那么我们输出,”刚刚输入的一个正数”,如果是负数,那么我们输出,”刚刚输入的那个数是负数”,如果我们输入的0的话,那么我们出输,”刚刚输
- 英语会话必须掌握的五种基本结构[转]
- 动态规划 HDU 1493 QQpet
- MDIEMDIE双心封装版0.3.0.0RC6V2
- 报告:我国网民规模达9.4亿,本科以上不足1成,2成网民月收入1000元以下