案例▍Python实战 爬取万条票房数据分析2019春节档电影状况
![]()
题图|《流浪地球》海报 作者|量化小白上分记 36大数据获授权转载
今年春节档全国共有8部影片上映,对于影片的对比分析已经非常多,孰优孰劣,每个人心里都有一杆秤,不再赘述。本文着重分析影片票房的地域差别,爬取了年后两周各地万余家影院的票房数据,一起来看看各地影院今年春节档表现如何,非官方统计,数据一定不准确,看看就好。
1.数据说明
分影院的票房数据来自中国票房网: ** http://www.cbooo.cn/cinemaday **
网站提供日票房排行榜的前100名和周票房的前一万余名,本文爬取包含更多样本的周票房数据,取年后两周的数据。
![]()
最终爬到的数据样式如下,数据从左往右依次为 ** 影院名称 ** , ** 当周票房 ** 、 ** 单荧幕票房 ** 、 ** 场均人次
** 、 单日单厅票房 、 单日单厅场次 6个变量。
![]()
2.数据获取
使用python获取数据,对于爬取过程不感兴趣的可以直接看下部分,需要数据/代码的请在后台回复“ ** 票房 ** ”。
在数据页面按 ** F12 ** 打开开发者工具,选择 ** NetWork ** , ** XHR **
,刷新页面后,依次点1,2,3,4页,接收到了一堆文件。
![]()
右键任意打开一个,显示如下(如果不是这种格式,说明你选错了)
![]()
是我们需要的数据,对比前后的变量关系,得到每个变量的含义。
![]()
再分析网址,从前面的截图能看出来, pindex后面跟的是页码 ,对页码进行循环就可以爬到所有的数据。dt =
1042看不出来什么意思,但改变日期范围重复上面的操作时,看到此时dt变成了1041,说明 dt后面的值对应不同的日期范围 。
![]()
我们的目标是爬取0204-0210,0211-0217两周的数据,获取对应的dt分别是1040和1041,最终代码如下
# -*- coding: utf-8 -*- """ Created on Fri Oct 19 18:50:03 2018 """ import urllib import requests from fake_useragent import UserAgent import json import pandas as pd import time import datetime # 发送get请求 comment_api = 'http://www.cbooo.cn/BoxOffice/getCBW?pIndex={}&dt={}' """ cinemaName:影院名称 amount:当周票房 avgPS:场均人次 avgScreen:单荧幕票房 screen_yield:单日单厅票房 scenes_time:单日单厅场次 """ headers = { "User-Agent": UserAgent(verify_ssl=False).random} #response_comment = requests.get(comment_api.format(1,1040),headers = headers) #json_comment = response_comment.text #json_comment = json.loads(json_comment) col = ['cinemaName','amount','avgPS','avgScreen','scenes_time','screen_yield'] dataall = pd.DataFrame() num = 1035 for i in range(1,num+1): response_comment = requests.get(comment_api.format(i,1041),headers = headers) json_comment = response_comment.text json_comment = json.loads(json_comment) n = len(json_comment['data1']) datas = pd.DataFrame(index = range(n),columns = col) for j in range(n): datas.loc[j,'cinemaName'] = json_comment['data1'][j]['cinemaName'] datas.loc[j,'amount'] = json_comment['data1'][j]['amount'] datas.loc[j,'avgPS'] = json_comment['data1'][j]['avgPS'] datas.loc[j,'avgScreen'] = json_comment['data1'][j]['avgScreen'] datas.loc[j,'scenes_time'] = json_comment['data1'][j]['scenes_time'] datas.loc[j,'screen_yield'] = json_comment['data1'][j]['screen_yield'] dataall = pd.concat([dataall,datas],axis = 0) print('已完成 {}% !'.format(round(i/num*100,2))) time.sleep(0.5) dataall = dataall.reset_index()
[/code]得到的两周数据里,第一周包含11295个样本,第二周包含11375个样本,将两周数据按影院合并后,最终得到10193个样本。```codedata1 = data1.drop_duplicates() data2 = data2.drop_duplicates() datas = pd.merge(data1,data2,left_on ='cinemaName',right_on = 'cinemaName').dropna() datas = datas.reset_index(drop = True) dataall = datas[['cinemaName']] dataall['amount'] = datas['amount_x'] + datas['amount_y'] dataall['avgPS'] = (datas['avgPS_x'] + datas['avgPS_y'])/2 dataall['avgScreen'] = datas['avgScreen_x'] + datas['avgScreen_y'] dataall['screen_yield'] = (datas['screen_yield_x'] + datas['screen_yield_y'])/2 dataall['scenes_time'] = (datas['scenes_time_x'] + datas['scenes_time_y'])/2 dataall['avgprice'] = dataall.screen_yield/dataall.scenes_time/dataall.avgPS dataall = dataall.dropna().reset_index(drop = True)
[/code]3.数据总览 先从各方面简单看看取到的数据。** 票房TOP10影院 **北京耀莱以860万的票房,远超第二名金逸北京的590万占据首位。并且票房前10名中,有5家都是北京的影院。** 单变量分布 **用单日单厅票房/单日单厅场次/场均人数估计平均票价,各个变量分布进如下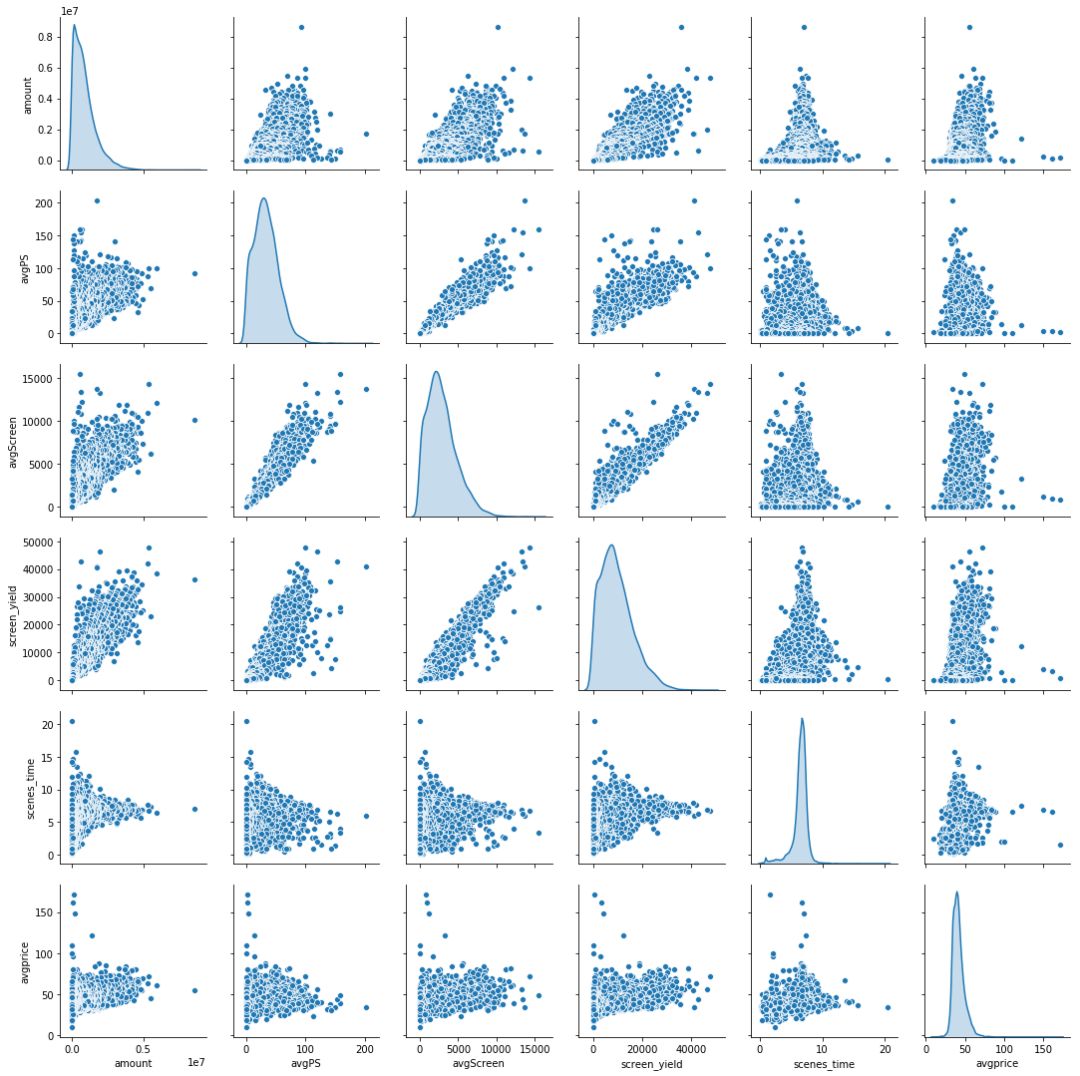可以看出,所有变量都呈现 ** 尖峰右拖尾 **
的特征,大部分值低于中位数,但也不乏高于均值的点,考虑到各个影院数据存在规模、地域等因素差异,这一结果就很正常了。** 票房影响因素 **1. 从上图看出,场均人次与单荧幕票房正相关,观影人数增多票房收入增加,符合常理。 2. 单日单厅场次与票房之间有先升后降的关系,换句话说, ** 排片少时,增加每日排片能增加票房收入,但排片过于密集,反而不利于票房增加 ** 。 3. 票价,场均人次与票房之间关系如图,颜色越深,表明票房越高。票价影响场均人次,过高和过低都会使票房收入减少,平均票价 ** 40-70 ** 区间内,影院票房收入更高,符合实际情况。 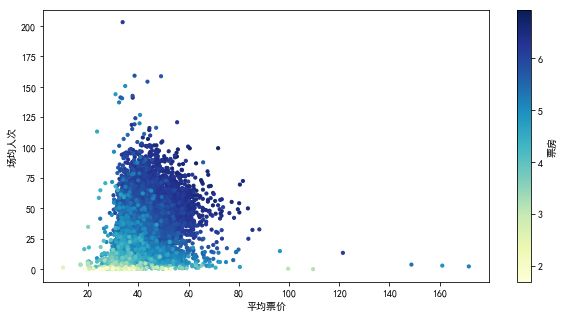4.票房地域特征粗略看过数据之后,我们分析地域因素对于票房的影响,虽然爬取的数据中没有直接给出影院的地域特征,但可以用影院名称提取地域位置,python里有一个基于jieba分词的地域查询包
**cpca** ,可以直接返回中文地址对应的省市县。 ```coderesult = cpca.transform(dataall.cinemaName.tolist(),cut = False) dataall['province'] = result['省'] dataall['city'] = result['市']
[/code]用cpca查询各个影院所在的省市,但这个包也不是非常完善,加上有的影院名称地址非常模糊,最终有7581个影院查询到了省市。未查询到的部分影院如下,一部分是没有地域信息,只有影院名称,一部分有地域信息,可能过于生僻,未能匹配到,之后的分析中删掉没匹配到的这部分影院。匹配到影院所在省份后,按省份汇总数据,分析各省票房。** 各省票房 **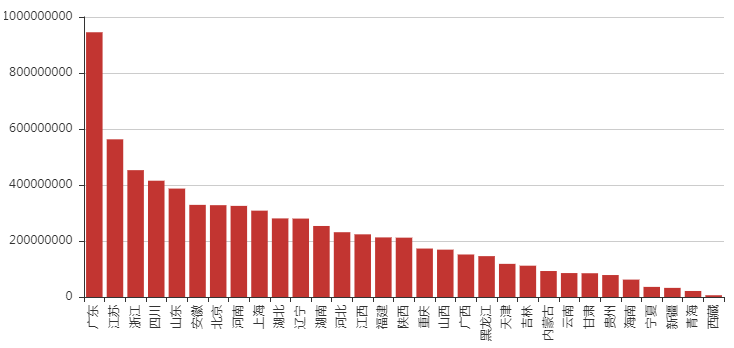各地区票房存在明显差异,广东省票房收入最高,远超其他省份去,西藏票房最少。接下来从各省影院数、场均人次、平均票价三方面来看各省差异。 ** 影院数 **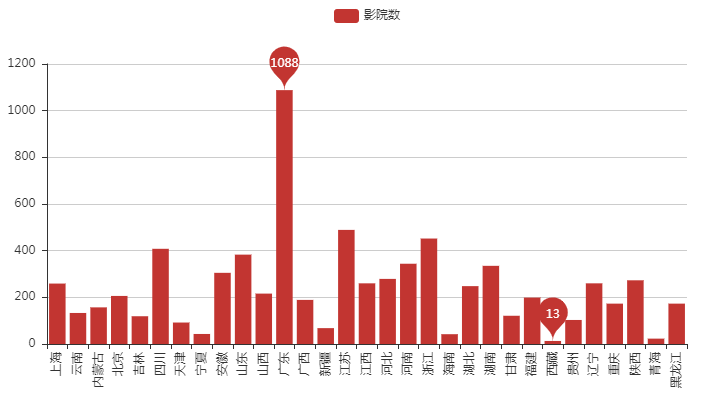最终获取的有地域信息的影院中,广东省有1088个影院,远远超出平均水平,这也可以解释为何广东省票房总数能排到第一,而西藏地区仅有13个影院,绝大部分地区影院在200上下浮动。**场均人次-平均票价**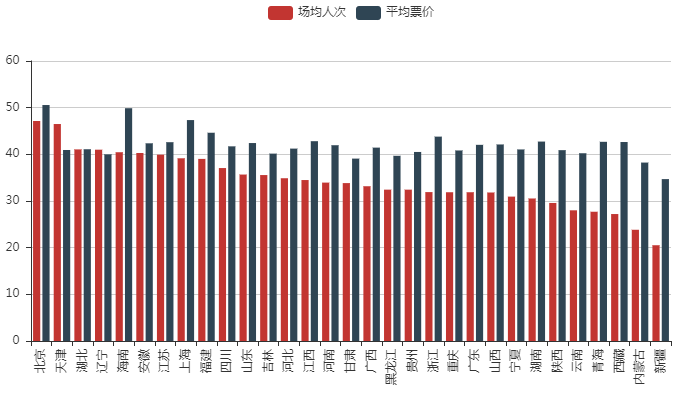平均票价整体差异不大,40元左右波动,场均人次来看,北京天津最多,但最高最低值差异不超过30人,因此这两项因素对于票房的影响远不如影院数大。** 各市票房分布 **最后将票房按市进行统计,得到全国各市票房分布如下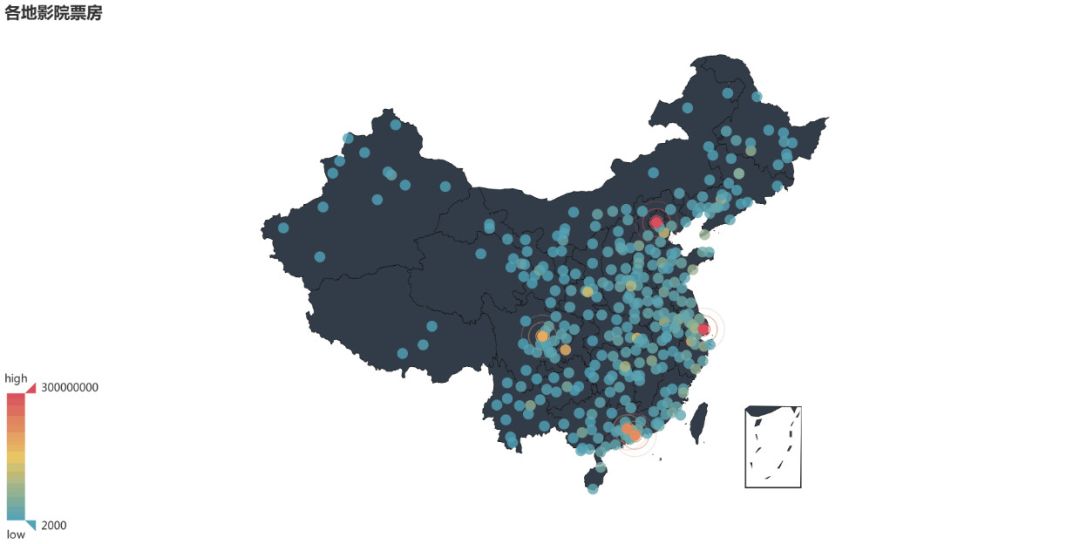图中标出了票房收入最高的5个市,分别是 ** 北京 ** ( 3279万)、 **上海** (3083万)、 **广州** (2258万)、
**深圳** (2205万)、 ** 成都 ** (1856万)。END“新年新气象,36大数据社群(大数据交流、AI技术学习群、机器人研究、AI+行业、企业合作群)火热招募中,对大数据和AI感兴趣的小伙伴们。增加AI小秘书微信号:
a769996688 , 说明身份即可加入 。欢迎投稿,投稿/合作:dashuju36@qq.com如果您觉得文章不错,那就分享到朋友圈~
案例▍Python实战 爬取万条票房数据分析2019春节档电影状况相关推荐
- 使用urllib 爬取万条伤感网易云热评
使用urllib 爬取万条伤感网易云热评 import urllib.request import re import ssl import json #抓取一页 def 网易云热评(url):#创建 ...
- 【Python】爬取中国历史票房榜,可视化分析
[Python]爬取中国历史票房榜,可视化分析 最近电影<哪吒之魔童转世>票房已经超过<流浪地球>,<复联4>.升到中国内地票房第二位.就好有哪些电影排进了历史票房 ...
- 实战▍Python爬取3w条游戏评分数据,看看哪款最热门?
图| 战争前线游戏原画 本文作者| 量化小白H 本文为投稿,36大数据已获发布授权 36大数据推荐 实战项目 本文爬取了豆瓣游戏网站上所有可见的游戏评分数据进行分析,全文包括以下几个部分: 数据获 ...
- python实战| 爬取虎牙高质量小姐姐私房照!
今天给大家介绍python如何爬取虎牙小姐姐并制作心形照片墙, 有兴趣的小伙伴们一起来看看吧! 点击进去,这颜值..... i了i了 需求分析 我们的目标有5个,分别是小姐姐的 房间名称.封面照片.昵 ...
- python实战|爬取1000位小姐姐私房照制作照片墙,刷新你三观的颜值!
今天给大家介绍python如何爬取虎牙小姐姐并制作心形照片墙, 有兴趣的小伙伴们一起来看看吧! 点击进去 卧槽,这颜值..... i了i了 需求分析 我们的目标有5个,分别是小姐姐的 房间名称.封面照 ...
- Python+BI爬取3000条车厘子数据,发现了这些秘密
听说最近车厘子的价格突然猛跌,之前很多人梦寐以求的"车厘子自由",现在都能实现了.其实车厘子的价格下降,主要原因是进口货运成本的大大降低,为了找到车厘子最佳的购买方式,我决定用py ...
- Python实战 | 爬取并闪存微信群里的百度云资源
需求背景: 需求: 涉及: 本篇文章目录: 爬取微信群聊信息里的网盘资源 爬取微信群聊信息可以用微信网页版的api,这里推荐一个高度封装,使用简单的工具:wxpy: 用 Python 玩微信 这是个不 ...
- python豆瓣历史评分_Python实战-爬取豆瓣top250评分高于指定值的电影信息
思路 1. 要获得怎么样的数据 2. 找到数据来源 3. 模拟浏览器发送请求获得数据 4. 处理数据,保存数据 第一步: 在这里数据是豆瓣top250中高于指定分数的电影信息 信息有:名称,评分,格言 ...
- python爬取微信聊天记录数据_[使用案例]python如何爬取微信好友信息?(上)
Python3如何爬取微信好友基本信息,并且进行数据清洗?下面跟着IP海带来的教程,我们一起看看具体的操作要怎么实现. 1.登录获取好友基础信息: 好友的获取方法为get_friends,将会返回完整 ...
- Python实战 | 爬取当当网 TOP500 畅销书
目标网页:当当网书籍畅销榜 http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1 爬取结果: 代码: ...
最新文章
- java changelistener_ListChangeListener.Change
- 神经网络参数量的计算:以UNet为例
- 第一次,人类在人工神经网络中发现了“真”神经元
- 欧拉函数的一道练习题(附加容斥做法)
- mysql5.7重置密码windows_MySql 5.7 for Windows 重置root密码
- windows xp 下的putty不能使用小键盘的问题
- 解释如何优化css选择器_购物车解释了CSS选择器
- 堆栈 cookie 检测代码检测到基于堆栈的缓冲区溢出_漏洞公告 | 华硕(ASUS)家庭无线路由器远程代码执行0day...
- base64 linux_渗透测试常用Linux命令总结
- BZOJ1202 [HNOI2005] 狡猾的商人
- 【名单回顾】CSP-J2 2019年第二轮入门级获奖名单(仅列北京地区小学生)
- Learun框架的入门问题
- c语言绪论课题背景及意义,选题背景及课题研究的目的和意义范例.doc
- [Wondgirl]从零开始学React Native之Text(五)
- 学习笔记——STM32摄像头OV7725(二)
- android中point pt1,Android dip,px,pt,sp 的区别详解
- MSF-02-木马捆绑
- 积分换元法中换元单调性问题的讨论
- 苹果开发者账号(公司级)和邓白氏编码(D-U-N-S)申请记录(2015.06)
- 视频播放器的html代码(二)