数据挖掘算法 1 ID3(python)
一 概念公式:
1信息熵:
若有n个消息,其给定各个方向概率分布为P=(p1,p2…pn),则由该分布传递的信息量称为P的熵,记为
2:信息增益:
信息增益度是两个信息熵之间的差值,记为Gain(P1)=entropy(p0,p1)-entropy(p0)
二 算法思想:
首先计算各个属性的所有取值的信息熵,然后根据当前属性的取值概率计算出当前属性的总的信息熵,接下来计算当前属性的信息增益度,最后通过所有属性的信息增益比较,增益大的先构造来构造决策树。希望随着决策树深度的增加,节点的熵迅速地降低,并且熵降低的速度越快越好,这样我们有望得到一棵高度最矮的决策树。
三 实例题目:
我们统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),并已知这些天气是否打球(play)。如果给出新一天的气象指标数据:sunny,cool,high,TRUE,判断一下会不会去打球。
| outlook | temperature | humidity | windy | play |
| sunny | hot | high | false | no |
| sunny | hot | high | true | no |
| overcast | hot | high | false | yes |
| rainy | mild | high | false | yes |
| rainy | cool | normal | false | yes |
| rainy | cool | normal | true | no |
| overcast | cool | normal | true | yes |
| sunny | mild | high | false | no |
| sunny | cool | normal | false | yes |
| rainy | mild | normal | false | yes |
| sunny | mild | normal | true | yes |
| overcast | mild | high | true | yes |
| overcast | hot | normal | false | yes |
| rainy | mild | high | true | no |
四实例解剖
1.目标:属性有4个:outlook,temperature,humidity,windy。我们首先要决定哪个属性作树的根节点。
2.计算:对每项指标分别统计:在不同的取值下打球和不打球的次数。设打球概率为P(Y),不打球概率为P(N)
outlook=sunny时,P(Y)=2/5,P(N)=3/5。此时entropy(sunny)=0.970
outlook=overcast时,P(Y)=1,P(N)=0,此时entropy(overcast)=0
outlook=rainy时,P(Y)=3/5,P(N)=2/5,entropy(rainy)=-3/5Log2(3/5)-2/5Log2(2/5)=0.442+0.528=0.970
而根据历史统计数据,outlook P(sunny)=5/14,P(overcast)=4/14, P(rainy)=5/14,
所以entropy(outlook)=P(sunny)*entropy(sunny)+P(overcast)*entropy(overcast)+ P(rainy)* entropy(rainy)
=5/14× 0.971 + 4/14 × 0 + 5/14 × 0.971 = 0.693
这样的话系统熵就从0.940下降到了0.693,信息增溢gain(outlook)为0.940-0.693=0.247
同样可以计算出gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048。
gain(outlook)最大(即outlook在第一步使系统的信息熵下降得最快),所以决策树的根节点就取outlook。
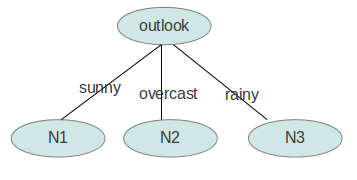
接下来要确定N1取temperature、humidity还是windy?在已知outlook=sunny的情况,根据历史数据,我们作出类似table 2的一张表,分别计算
gain(temperature)、gain(humidity)和gain(windy),选最大者为N1。
3.依此类推,构造决策树。当系统的信息熵降为0时,就没有必要再往下构造决策树了,此时叶子节点都是纯的--这是理想情况。最坏的情况下,决策树的高度为属性(决策变量)的个数,叶子节点不纯(这意味着我们要以一定的概率来作出决策)。
五实例实现:
略
数据挖掘算法 1 ID3(python)相关推荐
- python数据挖掘 百度云,常用数据挖掘算法总结及Python实现高清完整版PDF_python数据挖掘,python数据分析常用算法...
常用数据挖掘算法总结及Python实现 高清完整版PDF 第一部分数据挖掘与机器学习数学基础 第一章机器学习的统计基础 1.1概率论 l概率论基本概念 样本空间 我们将随机实验E的一切可能基本结果组成 ...
- 数据挖掘算法案例python_《常用数据挖掘算法总结及Python实现》[5.1MB]PDF影印版下载-码农之家...
<常用数据挖掘算法总结及Python实现>是一本数据挖掘相关的电子书资源,介绍了关于数据挖掘.算法总结.Python方面的内容,格式为PDF,资源大小5.1 MB,由debao9765 提 ...
- 【数据挖掘】数据挖掘算法 组件化思想 示例分析 ( 组件化思想 | Apriori 算法 | K-means 算法 | ID3 算法 )
文章目录 一. 数据挖掘算法组件化思想 二. Apriori 算法 ( 关联分析算法 ) 三. K-means 算法 ( 聚类分析算法 ) 四. ID3 算法 ( 决策树算法 ) 一. 数据挖掘算法组 ...
- 2021-03-15 数据挖掘算法—K-Means算法 Python版本
数据挖掘算法-K-Means算法 Python版本 简介 又叫K-均值算法,是非监督学习中的聚类算法. 基本思想 k-means算法比较简单.在k-means算法中,用cluster来表示簇:容易证明 ...
- ID3和C4.5分类决策树算法 - 数据挖掘算法(7)
(2017-05-18 银河统计) 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来判断其可行性的决策分析方法,是直观运用概率分析的一种图解法.由于这种决策分支画 ...
- python 数据挖掘 简书_python 数据挖掘算法简要
前言 数据挖掘是通过对大量数据的清理及处理以发现信息,并将这原理应用于分类,推荐系统,预测等方面的过程.本文基于<面向程序员数据挖掘指南>的理解,扩展学习后的总结.不足之处还请赐教,觉得有 ...
- 2021-03-20 数据挖掘算法—SVM算法 python
数据挖掘算法-SVM算法 简介 SVM(Support Vector Machine)名为支持向量机,是常见的一种判别方法.在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别.分类以及回归分 ...
- 数据挖掘算法_算法篇(01) 数据挖掘算法初探
前言 无论是传统行业,还是互联网行业.掌握数据,就是掌握规律.当你了解了市场数据,对它进行分析,就可以得到市场规律.当你掌握了产品自身的数据,对它进行分析,就可以了解产品的用户来源.用户画像等等.所以 ...
- C4.5决策树生成算法完整版(Python),连续属性的离散化, 缺失样本的添加权重处理, 算法缺陷的修正, 代码等
C4.5决策树生成算法完整版(Python) 转载请注明出处:©️ Sylvan Ding ID3算法实验 决策树从一组无次序.无规则的事例中推理出决策树表示的分类规则,采用自顶向下的递归方式,在决策 ...
最新文章
- Knowledge Graph |(1)图数据库Neo4j简介与入门
- vue获取dom元素注意问题
- 没有调查就没有发言权
- java分别使用for循环语句计算n!_实验三:分别用for、while和do-while循环语句以及递归方法计算n!,并输出算式...
- 有理有据!为什么String选择数字31作为hashCode方法乘子?
- pthread_cancel、pthread_equal函数
- 排序算法入门之简单选择排序
- python 导入包 作用域_Python 包、模块、函数、变量作用域
- LeetCode MySQL解题目录
- MySql中json类型的使用___mybatis存取mysql中的json
- php 取消命名空间,到PHP命名空间或不到PHP命名空间
- MTK功能机2503 GPIO配置
- 数字签名的原理及其应用
- 微信小程序实现退款,Java版。
- jacob更新word目录
- redis-trib.rb 使用详解
- matlab 混沌工具箱,matlab混沌工具箱
- 弘玑Cyclone完成1.5亿美元C轮融资,创行业单笔融资额最大记录
- PHP 垃圾回收机制
- siri中文语音助理_针对“语音助手”类产品,浅谈对话式交互设计