Google是如何教会机器玩Atari游戏的
转自:http://blog.csdn.net/revolver/article/details/50177219
![]()
今年上半年(2015年2月),Google在Nature上发表了一篇论文:Human-level control through deep reinforcement learning。文章描述了如何让电脑自己学会打Atari 2600电子游戏。Atari 2600是80年代风靡美国的游戏机,总共包括49个独立的游戏,其中不乏我们熟悉的Breakout(打砖块),Galaxy Invaders(小蜜蜂)等经典游戏。Google算法的输入只有游戏屏幕的图像和游戏的得分,在没有人为干预的情况下,电脑自己学会了游戏的玩法,而且在29个游戏中打破了人类玩家的记录。
Google到底是如何做到的呢?答案当然是深度学习了。
先来看看Google给出的神经网络架构。
![]()
网络的最左边是输入,右边是输出。游戏屏幕的图像(实际上是4幅连续的图像,可以理解为4个通道的图像)经过2个卷积层(论文中写的是3个),然后经过2个全连接层,最后映射到游戏手柄所有可能的动作。各层之间使用ReLU激活函数。
这个网络怎么看着这么眼熟?这和我们识别MNIST数字时用的卷积神经网络是一样一样的。
可是转念又一想,还是不对。我们识别MNIST数字的时候,是Supervised Learning(监督学习)。每个图像对应的输出是事先知道的。可是在游戏中并不是这样,游戏环境给出的只是得分。算法需要根据得分的变化来推断之前做出的动作是不是有利的。
这就像训练宠物一样。当宠物做出了指定动作之后,我们给它一些食物作为奖励,使它更加坚信只要做出那个动作就会得到奖励。这种训练叫做Reinforcement Learning(强化学习)。
强化学习并没有指定的输出,环境只对算法做出的动作给出相应的奖励,由算法来主动发现什么时间做出什么动作是合适的。强化学习的难处在于,奖励往往是有延时的。比如在一个飞机游戏中,玩家指挥自己的飞机在合适的时机发射子弹,相应的奖励要等到子弹击中敌机才会给出。从发射子弹到击中敌机之间有一个时间延迟。那么算法如何跨越这个时间延迟,把击中敌机所得到的奖励映射到之前发射子弹的这个动作上呢?
要解释这个问题,我们需要首先来谈一下强化学习是怎么一回事。
Reinforcement Learning(强化学习)
先借用一下维基百科的描述:
| 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。 |
![]()
在强化学习的世界里,我们的算法(或者说人工智能)被称为Agent,它与环境发生交互。Agent从环境中获取状态(state),并决定自己要做出的动作(action)。环境会根据其自身的逻辑给Agent予以奖励(reward)。这个奖励有正向和反向之分。比如动物生活在大自然中,吃到食物即是一个正向的奖励,而挨饿甚至失去生命就是反向的奖励。动物们靠着自己的本能趋利避害,增大自己得到正向奖励的机会。如果反过来说,就是避免得到反向的奖励,而挨饿什么的最终会导致死亡。所以动物生存的唯一目的其实就是避免死亡。
在电子游戏世界(特指Atari 2600这一类的简单游戏。不包括推理解密类的游戏)中:
- 环境指的是游戏本身,包括其内部的各种逻辑;
- Agent指的是操作游戏的玩家,当然也可以是指操作游戏的AI算法;
- 状态就是指游戏在屏幕上展现的画面。游戏通过屏幕画面把状态信息传达给Agent。如果是棋类游戏,状态是离散的,状态的数量是有限的。但在动作类游戏(如打飞机)中,状态是画面中的每个物体(飞机,敌人,子弹等等)所处的位置和运动速度的组合。状态是连续的,而且数量几乎是无限的。
- 动作是指手柄的按键组合,包括方向键和按钮的组合,当然也包括什么都不按(不做任何动作)。
- 奖励是指游戏的得分,每击中一个敌人都可以得到一些得分的奖励。
- 策略是Agent脑子里从状态到动作的映射。也就是说,每当Agent看到一个游戏画面(状态),就应该知道该如何操纵手柄(动作)。Reinforcement Learning算法的任务就是找到最佳的策略。策略的表示方法可以有很多。比如:
- 当状态的个数是有限的情况下,我们可以给每个状态指定一个最佳动作,以后只要看到某种状态出现,就去查询这个状态对应的动作就可以了。这种表示方法类似于查询字典。用这种方法表示最佳策略是没问题的,但是却不利于我们找出最佳策略,因为这种表示法是不可微分的(non-differentiable)。
- 我们还可以给每个状态下所有可能的动作估一个价值(Q-value),当我们看到某个状态的时候,我们去比较这个状态下所有动作的价值,找出价值最大的那一个。这种表示方法实际上可以用一个二维的表格来表示(Tabular Representation)。
- 当状态的个数是无限多时,我们已经不可能用表格来表示策略了。这时我们只能用一些函数拟合(Function Approximation)的方法把状态,动作,价值这三者的关系表示出来。神经网络目前是最佳的选择。
插播:
为什么不包括推理解密类游戏呢?其实Google把游戏简单分为两类:Perfect Information和Imperfect Information。
Perfect Information类的游戏可以通过当前屏幕上的画面了解到所有的状态信息,如打砖块,小蜜蜂,各种棋类都属于这一类游戏。这类游戏又可以叫做Markov游戏。Google这篇论文就是主要针对这一类。
Imperfect Information类的游戏不但要看当前屏幕上的画面,还要记住所有的历史画面。如扑克牌等。要解决这类游戏也不是没有可能,只需要在神经网络里加入闭环反馈就可以了。这就是Recurrent Neural Network(RNN)递归神经网络。关于RNN,请参考我的另一篇笔记:深度学习笔记(五)用Torch实现RNN来制作一个神经网络计时器
Q-Value
上面说到策略可以用动作的价值Q-value(实际上是Quality-Value)来表示。但这个价值到底代表什么呢?我们学政治课的时候都知道,商品的价值是凝结在商品中的无差别的人类劳动 。那么这个动作的价值又凝结了什么东西呢?这个价值又是以什么单位来衡量的呢?
。那么这个动作的价值又凝结了什么东西呢?这个价值又是以什么单位来衡量的呢?
由于我们算法的目的只有一个,那就是尽量多的获得奖励(Reward)。所以动作的价值毫无疑问就是以Reward的多少来衡量的。一个动作的价值等于做了这个动作之后一段时间之内Agent所能获得的最大的奖励。
举个例子,假设你面临跳槽,如果跳到新公司,今后五年内的预期收入是500万。如果留在原来的公司,今后五年的预期收入为300万。那么你”跳槽“这个动作的Q-value就是500万,而“不跳槽”这个动作的Q-value为300万。
所谓价值,当然是要根据设定的时间段而定的。为了计算方便,我们一般不会设定为“5年”这样一个固定的时间段。而是给未来的Reward打一个折扣。比如明年的预期收入要打一个0.9折,后年的预期收入打0.9的二次方折,大后年的预期收入打0.9的三次方的折。这样,越遥远的收入就显得越不重要,其实也起到了限制时间段的作用。
Q-Value Tabular Representation(Q函数的表格形式)
前面说到,策略可以用一个记录着Q-value的二维表格来表示。我们来举一个实际的例子吧。
![]()
假设我们有一张地图,地图上有6个格子。游戏开始时你会出现在任意一个蓝色的格子里,你的任务是走到End终点。因为你的口袋上漏了一个洞,你每踏上一个蓝色的格子,你的口袋会掉出一块钱,而你走到终点的那一刻,你会得到10块钱,同时游戏结束。如果你试图走出边界,你会留在原来的那个格子里,并失去1块钱。
好了,游戏规则非常简单。为了要获取最大的利益,你需要找出一个最佳策略。在这么简单的游戏设定下,你可以用Q的表格形式来表示你的策略。我已经帮你把表格画好了,你只需要把合适的数字填进去。(为了计算方便,我们不对未来的奖励做打折处理)
![]()
假设你身处状态C,那么向下走会得到10块钱。所以C状态的向下的动作Q-value等于10。同样,E状态向右的动作也等于10。
![]()
如果你身处B状态,向下可以走到E,通过E可以走到终点并获得10块钱,但是在路过E的时候要损失1块钱,所以总的预期是9元。同样B状态向右也是9。
![]()
如果你身处D,最好的方法是向右走到E,再通过E走到终点。这样的预期同样是9元。
![]()
如果你身处A,那么你可以向下走到D,然后通过E走到终点,这样预期是8元。当然也可以向右走到B,然后选择通过C或E走到终点,预期同样是8元。所以A状态的向下和向右的动作都是8。
![]()
还有一些空格没有填。比如从E向左走,很明显这不是最佳的走法。不过如果你硬要这么走的话,你还可以从D走回E然后走到终点。但你走了一些冤枉路,你的收入将会是8。
![]()
按照这种逻辑,我们可以把其他的格子填满。
![]()
这样,我们就得到一个策略。按照这个策略,当你身处某个状态的时候,你可以选择四个动作中Q-value最高的那个来执行。
现在,策略我们是定出来了。可是这个策略是以我们人脑的智慧高屋建瓴的来完成的,对于电脑来讲该怎么办呢?先别着急,这一节的目的只是讲如何用二维的表格来表示一个策略。至于如何用算法找出最佳策略,我们后面再讲。
Q-Value Function Approximation(Q函数拟合形式)
在大多数Atari游戏中,状态的个数几乎可以说是无限多的。画面每变化一点点,就是一个新的状态。我们不可能为每个状态指定一个最佳的动作,而是需要把相近的状态归纳到一起。比如,我们可以这样描述某个策略:“当子弹从左边射向我的飞机时,我应该向右移动;当子弹从右边射向我的飞机时,我应该向左移动“。这个策略实际上把所有可能的屏幕状态分成了两类,分别把他们映射到手柄的向左和向右键。这种对局部图像进行描述从而进行分类的任务,用卷积神经网络来做是最合适不过的了。
具体来讲有两种方式:1. 将状态和动作做为输入,相应动作的Q-value做为输出;2. 将状态作为输入,一次性输出每个动作的Q-value。
![]()
在Google的论文里,就使用了类似第二种的网络形式把游戏画面映射到按键动作。网络的输入端是4帧连续的图像,经过3个卷积层和2个全连接层映射到18个输出节点,每个节点代表一个手柄按键动作的价值(Q-value)。
Temporal difference(时间差分)
直到现在,我们最大的一个疑问其实还未解决:我们上面提到的那个卷积神经网络到底是怎么在没有监督的情况下训练出来的呢?答案就是自己向自己学习,而且是向未来的自己学习。是不是很神奇?这就是Temporal Difference。其实就是根据Agent在连续时间点之间做出判断的差值来实现学习的目的。
扩展知识:
一般对于计算机算法而言,想要从环境中学习到经验并找出最佳策略,有三种不同的方法可以选择:
1. 动态规划(Dynamic Programming)方法。计算机专业的同学肯定不会陌生。在地图上找出两点之间的最短路径(也算是一种学习)用的就是这种方法。但这种方法的缺点在于,环境必须是已知的。如果要算出最短路径(最佳策略),最起码要把地图(环境)告诉Agent才可以。而Google并没有告诉算法任何关于Atari2600游戏的知识,所以动态规划并不能解决这类问题。
2. 蒙特卡罗(Monte-Carlo)方法。蒙特卡罗是摩纳哥的一个赌城,这种方法说白了就是随机瞎猜的方法。不断的改变策略,并在环境中不断尝试,直到找出回报最多的策略。实际上,生物在自然界的进化就是遵循这样一种方法。每种生物都把不计其数的后代散播到我们这个地球上,每个后代的个体都在基因上有微小的差别。基因优秀的生存下来,继续繁衍后代。听起来这种方法是不错的。但是每学习一次都要以物种个体的死亡为代价,这样学习的代价太大,学习的速度也太慢。另外,通过这种方法学习的经验是不具有推理性的。因为它无法判断到底是之前的具体是哪个动作导致了死亡的结果,只能把从出生到死亡之间的时间段里做出的所有动作当成一个整体策略来处理,这个策略由个体的基因决定。而算法选择整体保留或者整体销毁这个基因样本。
3. TD(Temporal difference)方法。Google就是用的这种方法。
我们先来举一个例子:
假设我们要根据从周一到周日的天气状况来预测周日的天气。我们从周一开始观察,周一晚上我们给出一个预测,这个预测会很不准确。周二晚上的时候,由于我们已经观察了两天,而且时间离周日又接近了一些,所以我们的预测会比周一准确一些。一直到周六晚上,我们的预测会越来越准确。直到时间到达周日,我们的预测变成100%准确,因为实际上我们已经知道答案了。
这就是Temporal Difference的基本假设:下一时刻对于结果的预测一定会比上一时刻的预测更准确。
所以我们的方法就是让周一的预测向周二靠近,周二的预测向周三靠近......周六的预测向周日靠近。周日就不用再靠近了,因为当天的天气就是标准答案。
具体到算法上,流程大概是这样的:
1. 首先我们需要有一个神经网络(或者是别的什么预测器),它的输入是当天的日期和当天观测到的一些数据,输出是对周日天气的预测。用数字来表示:1为晴天,0为雨天。这个神经网络的初始状态是随机的,处于一种混沌状态,它给出的预测值也可以看成是随机数。
2. 我们开始从周一开始收集观察数据,把收集到的数据放进神经网络,它吐出一个结果。当然这个结果没有任何意义,因为它是随机生成的。
3. 时间来到周二,我们又收集到了一些数据。把周二的数据放进神经网络,又吐出一个结果。这个结果仍然是随机的没有任何意义。但总算是和周一的结果有些差别。
4. 把周一的日期和观察数据和周二的预测结果组成一对样本,用来训练我们的神经网络。注意,这时候我们的训练转变成了监督学习。由于我们会选择一个很小的learning rate,我们的神经网络会改变一点点,使得下一次如果我们又在周一这天观察到和这个周一类似的数据时,我们的预测会更加接近这个周二的结果了。等等,刚才不是说周二的预测结果只是个随机数吗?那这样的学习还有什么意义呢?先不要着急......
5. 我们一天天的观察和学习,直到来到了周日。今天,我们要把周六的日期和观察数据和周日的预测结果(其实就是ground truth)组成一对样本来训练网络了。这次的训练才真正开始有意义了。当我们下一次遇到和周六类似的情况时,我们就能更加准确的预测周日的天气了。这样,一周的观察和学习生活就结束了。
6. 我们又开始了新的一周,重新从周一开始预测周日的天气。这次我们有了上一周的经验(所谓经验,就是上一周留下来的那个神经网络)。在这一周的学习中,前几天的学习仍然是很盲目的。但从周六开始,这种自我学习就开始有了一些方向性。因为周六给出的预测已经是有一些根据的。所以它有能力给周五的神经网络一些指导性意见。
7. 时间一周一周的过去了。周六的网络总是能够学习到Ground Truth。而周五的网络总是能向周六的网络学习......周一的网络总是向周二的网络学习。随着时间的推移,所有的网络都不同程度的学习到了Ground Truth。
是不是有一点感觉了?让我们再看一下之前的那个例子。
![]()
这次我们要遵循一个严格的算法来得到最佳策略。用这种方法叫做Q-learning。这是一个迭代的过程。首先,把所有动作的Q-value初始化为0。然后,遵循下面的规则进行迭代:
某个状态下某个动作的Q-value = 该动作导致的直接奖励 + 该动作导致的状态中最有价值动作的Q-value
这个公式其实有个名字叫做Bellman Equation。这个公式非常非常重要,是整个Reinforcement Learning的理论核心。用通俗的话讲就是:如果你要做出一个选择,你需要考虑两个方面,一是你做出选择后立即得到的回报是多少,二是你的选择导致的一系列变化在未来能给你多少回报。将这两者加起来,就是你某项选择的价值。
如果有人给你一亿让你吃屎,你吃吗?很明显,立即回报是一亿,吃完之后名誉受损可能影响别人对你的看法,吃不吃你自己考虑吧。
我们来实际操作一下。首先在我们的表格里把所有的Q-value初始化为0。
![]()
然后按照Bellman Equation进行迭代。
![]()
第一次迭代之后,所有没有踏上终点的动作都变成了-1,只有C的向下和E的向右变成了10。我们来看看为什么。
拿A状态的向右动作为例。这个动作导致的结果是B状态,并获得-1的奖励。而B状态的后续动作的价值都是0(初始化的值)。所以这次迭代的结果是-1加上0,等于-1。
再拿C状态的向下动作举例。这个动作导致的结果是游戏结束,并获得+10的奖励。游戏结束后也没有后续的奖励了。所以迭代的结果是+10。
继续往下迭代:
![]()
我们发现所有能导致E或C的动作都变成了9。
拿B状态举例,B状态后续到c的价值为-1,由c到end的价值为+10 ,b的状态值=b到c的价值(-1)+c到end的价值(+10)=9
然后是第三次迭代:
![]()
第四次迭代:
![]()
经过四次迭代,我们的表格已经收敛,继续迭代也不会发生变化了。这就说明,我们已经找到了最佳策略。这个策略和我们凭人脑制定的策略是一样的。
进入真正的Atari游戏
经过上面的讲解,我们了解到几条事实:
- 所谓玩游戏的策略,其实就是一张记录着Q-value的表格
- 这个表格可以用神经网络来替代
- 我们没有监督数据来训练这个网络,所有的训练数据都是由网络自身生成的,当然还有环境给出的Reward(英语有个词叫做Bootstrapping,意思是提着自己的鞋带把自己提起来)
- 其实我们可以什么都不做,算法自己会找出最佳策略
由于本文并不涉及如何编写代码,所以我只想用文字来描述一下,在训练的过程中到底发生了些什么。
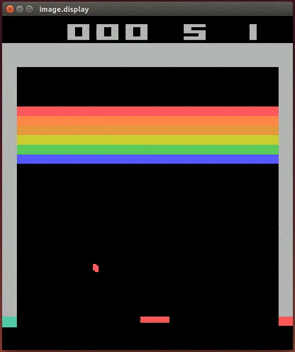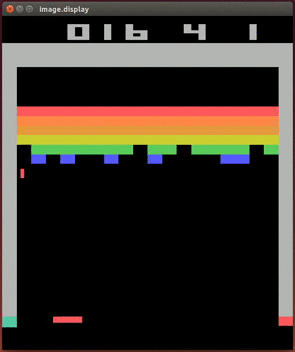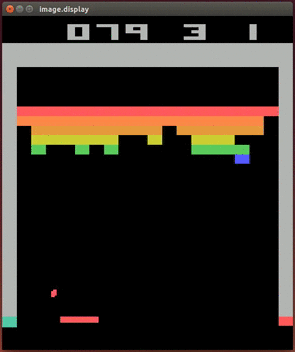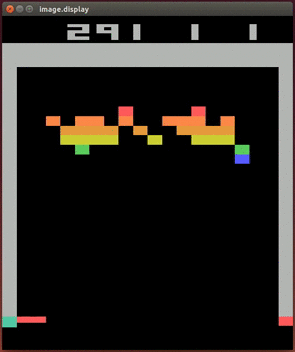
假设我们选择了Breakout(打砖块)游戏。
![]()
起初,我们建立了一个卷积神经网络,这就是AI的大脑。网络前端接受屏幕传来的图像,网络后端只有三个输出节点,分别代表向左移动,向右移动和不移动。网络的内部参数是随机初始化的,网络末端的Q-value也基本是随机的。这个大脑里面是一片混沌,它不会根据眼前的画面做出判断,只会随机的移动屏幕最下方的“球拍”。
我们打开开关,游戏开始运行。小球开始从上方掉下来。我们的“球拍”几乎不可能接到小球。每次小球掉落下去之后游戏就结束了。但马上又重新开始。
在这个过程中,屏幕图像源源不断的从神经网络的前端传进来,通过无数随机权重的神经脉络,连接到最后端的三个输出节点上。
"大脑“在做出随机动作的同时也在不停的学习。由于根本没有获得Reward,”大脑“只是单纯的拿n+1帧的图像对应的3个Q-value作为第n帧图像的学习目标。
这时的学习其实是盲目的。用随机初始化的网络随机的生成一些数据来训练,得到的结果也必然是一片混乱。所以,在这个阶段,神经网络跟没有学习到任何有意义的东西。
直到......
小球偶尔也会落在球拍上反弹回去。击中球拍并不会获得Reward,所以网络的训练仍然和之前一样无动于衷。
当小球向上击中一个砖块的时候,游戏给出1分作为Reward。从这时开始,“训练”才真正变得有意义了。在小球击中砖块的瞬间,砖块消失不见。由于神经网络接受的是4帧连续的图像,实际上是一个小动画,记录了砖块消失的过程。在这一帧发生的训练,其输入样本用的是上一帧的4幅图像(小球马上要击中砖块),而输出样本是击中砖块后的图像通过网络所生成的3个Q-value再加上刚才得到的1分。
这一帧的训练意义非同寻常,它告诉“大脑”:在小球马上要击中砖块这样一种状态下,不论你做出什么动作,都会得到比随机水平高出1分。
这一过程不断的重复,当“大脑”经历过多次击中砖块的瞬间,它脑中的卷积核就会试图找出这些画面中有哪些共同点。终于有一天,当击中过足够多次砖块之后,“大脑”终于明白,这些画面的共同点是:画面的某处都存在一个相同的pattern——小球和砖块非常接近而且小球正在向砖块飞去。“大脑”终于明白了它人生中的第一件事。
以后的每帧图像,它都会在图像中寻找这样的pattern,如果找到了,就会在输出端的3个动作节点给出3个比平时高一点的Q-value。
这时,“大脑”并没有将得分和动作联系在一起。这3个动作对它来说价值没有什么区别。它仍然是随机的给出一些动作。
“大脑”也会发现击中砖块前两帧的图像会“导致”前一帧的图像。在小球接近砖块的过程中,算法会不断的把下一帧的Q-value拿过来作为前一帧的图像的结果来训练。
渐渐地,“大脑”会认为所有小球飞向砖块的图像都应该对应较高的Q-value。也就是说,这些状态都是“有利”的。
下一步,“大脑”会继续领悟:是小球与球拍的碰撞“导致”了小球向上运动,并有很大可能是飞向砖块。所以小球与球拍的碰撞是“有利”的。
到目前为止,“大脑”还是没有搞清楚这3个动作到底有什么区别。
游戏继续,“大脑”继续随机的发出动作。
有时候,小球会贴着球拍的边缘掉下去。只有在这个时候,才能体现出动作带来的好处。比如,小球落到球拍左边缘时,如果这时碰巧发出了一个向左的动作,那么就会引发碰撞,否则小球就会跌落下去。在引发碰撞的情况下,“大脑”会把“碰撞”的Q-value(比较高)赋给向左这个动作。而向右和不移动这两个动作得到的却只是小球落下去的Q-value(比较低)。
久而久之,“大脑”就会明白当小球将要从左边略过球拍的时候,向左的动作比较有利;将要从右边略过的时候,向右的动作比较有利。
这样推广开来,“大脑”就会慢慢的找出合适的策略,越玩越好,逐渐达到完美的程度。
总结
说到这里,相信你已经能对强化学习有了一个大致的了解。接下来的事情,应该是如何把这项技术应用到我们的工作中,让它发挥出其巨大的潜能,创造出前人无法想象的价值。
自从Google发表了那篇惊世骇俗的论文以来,在我的内心里,人工智能的大门已经正式向人类打开,美好的未来也在向我们招手。从某种意义上讲,其巨大的影响力已经让我们手头的工作变得毫无价值,而我们应该抓紧时间去认真研究这新出现的技术,尽快的发挥它的巨大势能。正如KK的比喻那样:你正用一把铁铲在挖水渠,但你却突然听说明天会有人租一台挖掘机来过来,这时你还会继续挖下去吗?
转载于:https://www.cnblogs.com/laiqun/p/6755847.html
Google是如何教会机器玩Atari游戏的相关推荐
- 用深度强化学习玩atari游戏_被追捧为“圣杯”的深度强化学习已走进死胡同
作者 | 朱仲光 编译 | 夕颜出品 | AI科技大本营(ID:rgznai1100) [导读]近年来,深度强化学习成为一个被业界和学术界追捧的热门技术,社区甚至将它视为金光闪闪的通向 AGI 的圣杯 ...
- OpenCV图像识别初探-50行代码教机器玩2D游戏
最近在研究OpenCV,希望能通过机器视觉解决一些网络安全领域的问题.本文简要介绍如何通过OpenCV实现简单的图像识别,并让计算机通过"视觉"自动玩一个简单的2D小游戏,文末有视 ...
- 用深度强化学习玩atari游戏_(一)深度强化学习·入门从游戏开始
1.在开始正式进入学习之前,有几个概念需要澄清,这样有利于我们对后续的学习有一个大致的框架感 监督型学习与无监督型学习 深度强化学习的范畴 监督型学习是基于已有的带有分类标签的数据集合,来拟合神经网络 ...
- 教ai玩游戏_简单解释:DeepMind如何教AI玩视频游戏
教ai玩游戏 by Aman Agarwal 通过阿曼·阿加瓦尔(Aman Agarwal) 简单解释:DeepMind如何教AI玩视频游戏 (Explained Simply: How DeepMi ...
- 机器学习:让机器学会打游戏之陨石坠落
这是一个系列课程,我们将会用不同的机器学习算法,让机器学会玩不同的游戏. 今天要让机器玩的游戏是:陨石坠落(点击试玩). 课程概述 课程中,我们将围绕陨石坠落点预测问题,建立机器学习模型. 我们将会用 ...
- atari游戏模型_在Atari.com免费玩经典街机游戏
atari游戏模型 The late 70's and early 80's was a golden age for video games. Arcades were a thriving hot ...
- 离散世界模型,带你轻松玩转 Atari 游戏
文 / Google Research 学生研究员 Danijar Hafner 得益于深度强化学习 (RL),人工智能体能够随着时间的推移不断改进其决策.传统的无模型方法与环境交互,通过大量试错来学 ...
- 下载和玩经典游戏的最佳网站
For the holiday weekend, we wanted to provide you with some more ways to have fun. The following sit ...
- 不需要借助GPU的力量,用树莓派也能实时训练agent玩Atari
点击上方↑↑↑"视学算法"关注我 来源:公众号 机器之心 授权 还是熟悉的树莓派!训练 RL agent 打 Atari 不再需要 GPU 集群,这个项目让你在边缘设备上也能进行实 ...
- 云计算机玩大型游戏,云游戏实测点评:大部分都可以顺畅玩耍
大家好,这里是酷乐米小编龙牧,很多玩家都对玩游戏的热情居高不下,特别是当前较为热门的"云游戏"和手游.在2020年的现在,网络明显得到了改善,使用达龙云玩云游戏,小编亲测过,可以说 ...
最新文章
- 摄像头定位:ICCV2019论文解析
- 暑期集训5:并查集 线段树 练习题F: HDU - 1166
- malloc 初始化_在C语言中,请一定记得初始化局部变量!
- Golang 垃圾回收剖析
- UIKit封装的系统动画
- CentOS查看每个进程的网络流量
- hawq state 报错: the database is down, but Ambari shows all hawq services as being
- 网络协议文档阅读笔记-Introduction to DTLS(Datagram Transport Layer Security)
- 使用JavaScript弹出Confirm对话框
- 设计模式-单例模式扩展(程序员学习之路-架构之路)
- webpack+ES6+Sass搭建多页面应用
- - 动规讲解基础讲解五——最长公共子序列问题
- 15.软件架构设计:大型网站技术架构与业务架构融合之道 --- 技术架构与业务架构的融合
- 小米android截屏快捷键是什么原因,小米截屏快捷键是什么 如何快速截图快捷键...
- 利用excel做简单的曲线拟合并生成公式
- redis中内存碎片处理
- 511遇见易语言教程API模块制作cmd复制文件
- kuka机器人程序是c语言吗,KUKA机器人示教器编程问题讲解——KUKA机器人
- java 数据库容灾_mysql 容灾备份
- 如何查看台式机计算机网络密码,如何从计算机检查已知的WiFi密码
热门文章
- Photoshop-图层相关概念-LayerComp-Layers-移动旋转复制图层-复合图层
- 记忆中的巷子与老房子
- 苹果麦克风设置在哪里_这一份 iOS 14 安全和隐私设置指南,请收好
- 麦克风测试软件 ios,iOS开发麦克风权限判断
- 计算机专业的浪漫情话,计算机科学与技术表白情话
- 科研第二步:远程在服务器上跑程序jupyter使用
- 【2022-New】Flutter doctor 检测报错,Android toolchain - develop for Android devices
- 要怎样努力,才能成为很厉害的人?!
- Groundhog Chasing Death
- WSL2 更换硬盘位置