R语言︱决策树族——随机森林算法
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~![]()
———————————————————————————
笔者寄语:有一篇《有监督学习选择深度学习还是随机森林或支持向量机?》(作者Bio:SebastianRaschka)中提到,在日常机器学习工作或学习中,当我们遇到有监督学习相关问题时,不妨考虑下先用简单的假设空间(简单模型集合),例如线性模型逻辑回归。若效果不好,也即并没达到你的预期或评判效果基准时,再进行下换其他更复杂模型来实验。
——————————————————————————————————————————————
一、随机森林理论介绍
1.1 优缺点
优点。
(1)不必担心过度拟合;
(2)适用于数据集中存在大量未知特征;
(3)能够估计哪个特征在分类中更重要;
(4)具有很好的抗噪声能力;
(5)算法容易理解;
(6)可以并行处理。
缺点。
(1)对小量数据集和低维数据集的分类不一定可以得到很好的效果。
(2)执行速度虽然比Boosting等快,但是比单个的决策树慢很多。
(3)可能会出现一些差异度非常小的树,淹没了一些正确的决策。
1.2 生成步骤介绍
1、从原始训练数据集中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,每次未被抽到的样本组成了K个袋外数据(out-of-bag,BBB)。
2、设有n 个特征,则在每一棵树的每个节点处随机抽取mtry 个特征,通过计算每个特征蕴含的信息量,特征中选择一个最具有分类能力的特征进行节点分裂。
3、每棵树最大限度地生长, 不做任何剪裁
4、将生成的多棵树组成随机森林, 用随机森林对新的数据进行分类, 分类结果按树分类器投票多少而定。
1.3 随机森林与SVM的比较
(1)不需要调节过多的参数,因为随机森林只需要调节树的数量,而且树的数量一般是越多越好,而其他机器学习算法,比如SVM,有非常多超参数需要调整,如选择最合适的核函数,正则惩罚等。
(2)分类较为简单、直接。随机深林和支持向量机都是非参数模型(复杂度随着训练模型样本的增加而增大)。相较于一般线性模型,就计算消耗来看,训练非参数模型因此更为耗时耗力。分类树越多,需要更耗时来构建随机森林模型。同样,我们训练出来的支持向量机有很多支持向量,最坏情况为,我们训练集有多少实例,就有多少支持向量。虽然,我们可以使用多类支持向量机,但传统多类分类问题的执行一般是one-vs-all(所谓one-vs-all 就是将binary分类的方法应用到多类分类中。比如我想分成K类,那么就将其中一类作为positive),因此我们还是需要为每个类训练一个支持向量机。相反,决策树与随机深林则可以毫无压力解决多类问题。
(3)比较容易入手实践。随机森林在训练模型上要更为简单。你很容易可以得到一个又好且具鲁棒性的模型。随机森林模型的复杂度与训练样本和树成正比。支持向量机则需要我们在调参方面做些工作,除此之外,计算成本会随着类增加呈线性增长。
(4)小数据上,SVM优异,而随机森林对数据需求较大。就经验来说,我更愿意认为支持向量机在存在较少极值的小数据集上具有优势。随机森林则需要更多数据但一般可以得到非常好的且具有鲁棒性的模型。
1.5 随机森林与深度学习的比较
深度学习需要比随机森林更大的模型来拟合模型,往往,深度学习算法需要耗时更大,相比于诸如随机森林和支持向量机那样的现成分类器,安装配置好一个神经网络模型来使用深度学习算法的过程则更为乏味。
但不可否认,深度学习在更为复杂问题上,如图片分类,自然语言处理,语音识别方面更具优势。
另外一个优势为你不需要太关注特征工程相关工作。实际上,至于如何选择分类器取决于你的数据量和问题的一般复杂性(和你要求的效果)。这也是你作为机器学习从业者逐步会获得的经验。
可参考论文《An Empirical Comparison of Supervised Learning Algorithms》。
1.6 随机森林与决策树之间的区别
模型克服了单棵决策树易过拟合的缺点,模型效果在准确性和稳定性方面都有显著提升。
决策树+bagging=随机森林
1.7 随机森林不会发生过拟合的原因
在建立每一棵决策树的过程中,有两点需要注意-采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。
假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。
然后进行列采样,从M个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤-剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。 按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。
可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
1.8 随机森林与梯度提升树(GBDT)区别
随机森林:决策树+bagging=随机森林
梯度提升树:决策树Boosting=GBDT
两者区别在于bagging boosting之间的区别,可见:
|
bagging |
boosting |
|
|
取样方式 |
bagging采用均匀取样 |
boosting根据错误率来采样 |
|
精度、准确性 |
相比之,较低 |
高 |
|
训练集选择 |
随机的,各轮训练集之前互相独立 |
各轮训练集的选择与前面各轮的学习结果相关 |
|
预测函数权重 |
各个预测函数没有权重 |
boost有权重 |
|
函数生成顺序 |
并行生成 |
顺序生成 |
|
应用 |
象神经网络这样极为消耗时间的算法,bagging可通过并行节省大量的时间开销 baging和boosting都可以有效地提高分类的准确性 |
baging和boosting都可以有效地提高分类的准确性 一些模型中会造成模型的退化(过拟合) boosting思想的一种改进型adaboost方法在邮件过滤,文本分类中有很好的性能 |
|
随机森林 |
梯度提升树 |
本部分参考:随机森林简易教程
特征选择目前比较流行的方法是信息增益、增益率、基尼系数和卡方检验。这里主要介绍基于基尼系数(GINI)的特征选择,因为随机森林采用的CART决策树就是基于基尼系数选择特征的。
基尼系数的选择的标准就是每个子节点达到最高的纯度,即落在子节点中的所有观察都属于同一个分类,此时基尼系数最小,纯度最高,不确定度最小。
决策树中最常用的四种算法:
基尼系数(Gini Index)
基尼系数指出:我们从总体中随机挑选两个样本,如果总体是纯的,那么这两个样本是同类别的概率为1。
- 用于处理分类型目标变量“Success”或者“Failure”。
- 它只作用于二进制分裂。
- 基尼系数越大,纯度越高。
- CART(分类和回归树)使用Gini方法创建二进制分裂。
卡方(Chi-Square)
它可以用来衡量子节点和父节点之间是否存在显著性差异。我们用目标变量的观测频率和期望频率之间的标准离差的平方和来计算卡方值。
- 它用于处理分类型目标变量“Success”或“Failure”。
- 它可以计算两个或多个分裂。
- 卡方越高,子节点与父节点之间的差异越显著。
- Chi-square = ((Actual – Expected)^2 / Expected)^1/2
- 它生成的树称为:CHAID (Chi-square Automatic Interaction Detector)
如何计算一个分裂的卡方:
- 通过计算Success和Failure的偏差来计算单个节点的卡方。
- 通过计算每个节点的Success和Failure的所有卡方总和计算一个分裂的卡方。
信息增益(Information Gain)
观察下面的图像,想一下哪个节点描述起来更加容易。答案一定是C,因为C图中的所有的值都是相似的,需要较少的信息去解释。相比较,B和A需要更多的信息去描述。用纯度描述,就是:Pure(C) > Pure(B) > Pure(A)。
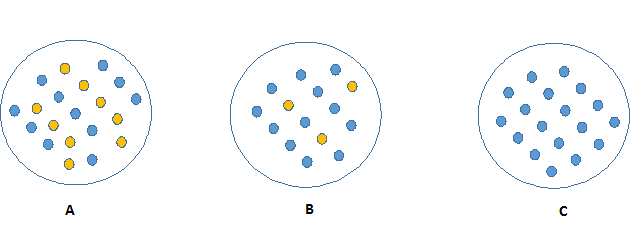
纯度越高的节点,就会需要更少的信息去描述它;相反,不纯度越高,就会需要更多的信息。信息论用熵来定义系统的混乱程度。如果样本中的个体是完全相同类别的,那么系统的熵为0;如果样本是等划分的(50%-50%),那么系统的熵为1。
方差削减(Reduction in Variance)
至此,我们已经讨论了很多关于分类型目标变量的算法。方差削减是用于连续型目标变量的算法(回归问题)。它使用方差公式去挑选最优分裂。方差最小的分裂将会作为分割总体的准则。

如何计算方差?
- 计算每一个节点的方差。
- 计算每一个节点方差的加权平均,作为一个分裂的方差。
——————————————————————————————————————————————
二、随机森林重要性度量指标——重要性评分、Gini指数
(1)重要性评分
定义为袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量。
(1):对于每棵决策树,利用袋外数据进行预测,将袋外数据的预测误差将记录下来。其每棵树的误差是:vote1,vote2····,voteb;
(2):随机变换每个预测变量,从而形成新的袋外数据,再利用袋外数据进行验证,其每个变量的误差是:vote11,vote12,···,vote1b。
(3):对于某预测变量来说,计算其重要性是变换后的预测误差与原来相比的差的均值。
r语言中代码:
rf <- randomForest(Species ~ ., data=a, ntree=100, proximity=TRUE,importance=TRUE)(2)gini指数
gini指数表示节点的纯度,gini指数越大纯度越低。gini值平均降低量表示所有树的变量分割节点平均减小的不纯度。对于变量重要度衡量,步骤如同前面介绍,将变量数据打乱,gini指数变化的均值作为变量的重要程度度量。
gini(T)=1−∑j=1np2j
(3)重要性绘图函数——varImpPlot(rf)函数
![]()
——————————————————————————————————————————————
三、随机森林模型R语言实践
3.1 随机森林模型几点注意
模型中关于分类任务以及回归预测任务的区别:
随机森林模型,分类和回归预测的操作不同之处在于判断因变量的类型,如果因变量是因子则执行分类任务,如果因变量是连续性变量,则执行回归预测任务。
模型中关于数据结构的要求:
`randomForest`函数要求为数据框或者矩阵,需要原来的数据框调整为以每个词作为列名称(变量)的数据框。在文本挖掘的过程中,需要把词频(横向,long型数据)转化为变量(wide型纵向数据),可以用reshape2、data.table包来中dcast来实现。具体实战见博客:R语言︱监督算法式的情感分析笔记的4.1节。
K越大,单棵树的效果会提升,但树之间相关性也会增强
决策树数量M
M越大,模型效果会有提升,但计算量会变大
单棵决策树:rpart/tree/C50
随机森林:randomforest/ranger
梯度提升树:gbm/xgboost
树的可视化:rpart.plot
3.2 模型拟合
本文以R语言中自带的数据集iris为例,以setosa为因变量,其他作为自变量进行模型拟合,由于setosa本身就是因子型,所以不用转换形式。
> data <- iris
> library(randomForest)
> system.time(Randommodel <- randomForest(Species ~ ., data=data,importance = TRUE, proximity = FALSE, ntree = 100))
用户 系统 流逝 0 0 0
> print(Randommodel)Call:randomForest(formula = Species ~ ., data = data, importance = TRUE, proximity = FALSE, ntree = 100) Type of random forest: classificationNumber of trees: 100
No. of variables tried at each split: 2OOB estimate of error rate: 3.33%
Confusion matrix:setosa versicolor virginica class.error
setosa 50 0 0 0.00
versicolor 0 47 3 0.06
virginica 0 2 48 0.04代码解读:randomForset,执行建模,x参数设定自变量数据集,y参数设定因变量数据列,importance设定是否输出因变量在模型中的重要性,如果移除某个变量,模型方差增加的比例是它判断变量重要性的标准之一,proximity参数用于设定是否计算模型的临近矩阵,ntree用于设定随机森林的树数(后面单独讨论),最后一句输出模型在训练集上的效果。
prInt输出模型在训练集上的效果,可以看出错误率为3.33%,维持在比较低的水平。
3.3 随机森林模型重要性检测
> importance(Randommodel,type=1) #重要性评分MeanDecreaseAccuracy
Sepal.Length 4.720094
Sepal.Width 1.405924
Petal.Length 16.222059
Petal.Width 13.895115
> importance(Randommodel,type=2) #Gini指数MeanDecreaseGini
Sepal.Length 9.484106
Sepal.Width 1.930289
Petal.Length 45.873386
Petal.Width 41.894352
> varImpPlot(Randommodel) #可视化利用iris数据,可以看到这四个变量的重要性排序是一样的。
3.4 模型的预测功能
predict中有多种参数,比如Nodes,Proximity,predict.all。
predict(object, newdata, type="response",norm.votes=TRUE, predict.all=FALSE, proximity=FALSE, nodes=FALSE,cutoff, ...)
#Nodes判断是否是终点。Proximity判断是否需要进行近邻测量。predict.all判断是否保留所有的预测器。举例,以前面的随机森林模型进行建模。
predict.all会输出一个150*150的字符矩阵,代表每一颗树的150个预测值(前面预设了ntree=100);
Nodes输出100颗树的节点情况。
prediction <- predict(Randommodel, data[,1:5],type="class") #还有response回归类型table(observed =data$Species,predicted=prediction) table输出混淆矩阵,注意table并不是需要把预测值以及实际值放在一个表格之中,只要顺序对上,用observed以及predicted直接调用也可以。
3.5 补充——随机森林包(party包)
与randomForest包不同之处在于,party可以处理缺失值,而这个包可以。
library(party)#与randomForest包不同之处在于,party可以处理缺失值,而这个包可以
set.seed(42)
crf<-cforest(y~.,control = cforest_unbiased(mtry = 2, ntree = 50), data=step2_1)
varimpt<-data.frame(varimp(crf))party包中的随机森林建模函数为cforest函数,
mtry代表在每一棵树的每个节点处随机抽取mtry 个特征,通过计算每个特征蕴含的信息量,特征中选择一个最具有分类能力的特征进行节点分裂。
varimp代表重要性函数。跟对着看:笔记+R︱风控模型中变量粗筛(随机森林party包)+细筛(woe包)
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~![]()
———————————————————————————
R语言︱决策树族——随机森林算法相关推荐
- R语言----决策树与随机森林详解
决策树 首先区分树模型和线性模型的区别: 线性模型: 对所有特征给予权重相加得到一个新的值 (例:逻辑回归通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类) 逻辑回归只能找到线性的分割 ( ...
- 随机森林回归预测r语言_使用随机森林(R语言)做回归
引言 随机森林( random forest) 是一种基于分类树( classification tree) 的算法,它可以用于分类和回归,本文在这里以广西地区1990-2014共25年的GDP数据作 ...
- 十五、机器学习中的决策树和随机森林算法
@Author:Runsen 决策树是解决分类和回归问题的一种常见的算法.决策树算法采用树形结构,每一次选择最优特征,来实现最终的分类,因此决策树是一种递归的算法.但是,决策树很容易产生过拟合现象,最 ...
- R语言机器学习篇——随机森林
参考书籍:陈强.机器学习及R应用.北京:高等教育出版社,2020 随机森林属于集成学习的方法,也称为组台学习,本章介绍随机森林与它的特例方法,装袋法,并分别以例子的形式讨论回归问题与分类问题的随机森林 ...
- R语言中实现随机森林建模的包randomForest
文章目录 介绍 randomForest()的用法 参数介绍 输出参数 实例 varImpPlot()的用法 参数介绍 实例 介绍 randomForest 使用 Breiman 的随机森林算法(ba ...
- R语言机器学习系列-随机森林回归代码解读
回归问题指的是因变量或者被预测变量是连续性变量的情形,比如预测身高体重的具体数值是多少的情形.整个代码大致可以分为包.数据.模型.预测评估4个部分,接下来逐一解读. 1.包部分,也就是加载各类包,包括 ...
- R语言ggplot2 | 绘制随机森林重要性+相关性热图
- R语言CART决策树、随机森林、chaid树预测母婴电商平台用户寿命、流失可视化
全文链接:http://tecdat.cn/?p=31644 借着二胎政策的开放与家庭消费升级的东风,母婴市场迎来了生机盎然的春天,尤其是母婴电商行业,近年来发展迅猛(点击文末"阅读原文&q ...
- 数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化...
全文链接:http://tecdat.cn/?p=22262 在讨论分类时,我们经常分析二维数据(一个自变量,一个因变量)(点击文末"阅读原文"获取完整代码数据). 但在实际生活中 ...
最新文章
- STM32处理器存储空间布局解析
- Python 学习日记 第八天
- linux 命令 grep -A -B -C 显示行选项
- 最长公共子序列Python解法
- codeforce Gym 101102A Coins (01背包变形)
- prometheus-operator架构部署( prometheus-server, pushgateway, grafana, alertmanater,servicemonitor...)
- headerutf php_php header设置编码的方法
- 32bit程序在64bit操作系统下处理重定向细节
- 【从线性回归到BP神经网络】第一部分:协方差与相关系数
- Jinja2 入门教程、基本概念、简单使用及使用 Jinja2 生成 H3C 交换机配置举例
- 获取小游戏SWF文件中的素材
- stm32中的“hello world”
- java设计模式-设配器模式
- 学习笔记——深蓝学院点云系列公开课05:3D物体检测的发展与未来
- apmserv php7,apmserv
- 心电图心电轴怎么计算_心电轴度数计算表
- fiddler--通过Fiddler模拟弱网进行测试
- 基于PHP+MySQL音乐网站的设计与开发
- LIS2MDL磁力计驱动
- 中国膜产业需求规模与投资潜力分析报告2022版