python读取pdf表格_[转]Python 解析 PDF 文本和表格的四大方法介绍
Python 解析 PDF 文本和表格的四大方法介绍
== code for paper and NSFC Proj. parsing==: https://gitee.com/sonica/pdf_parsing
看到一个不错的知识文章,和大家分享一下:
很多文件为了安全都会存成 PDF 格式,比如有的论文、技术文档、书籍等等,程序读取这些文档内容带来了很多麻烦。Python 目前解析 PDF 的扩展包有很多,这里将对比介绍 PyPDF2、pdfplumber、pdfminer3k 以及 Camelot,告诉你哪个是好用的 PDF 解析工具。
本文使用的案例 PDF 文档下载链接:
链接:
另外,获取 PDF 文档之后,会发现 PDF 文档中的换行符是以行的位置相同的,而不是跟段落相同。
1. PyPDF2 解析 PDF 文档
这里主要参考了 2019-03-07,Usman Malik 写的一篇文章:
Python for NLP: Working with Text and PDF Files
使用 Python 安装 PyPDF2 扩展包:
pip install PyPDF2
#---------OR
conda install -c conda-forge pypdf2
读取 PDF 文件
import PyPDF2
path = r"****.pdf"
#使用open的‘rb’方法打开pdf文件(这里必须得使用二进制rb的读取方式)
mypdf = open(path,mode='rb')
#调用PdfFileReader函数
pdf_document = PyPDF2.PdfFileReader(mypdf)
#使用pdf_document变量,获取各个信息
#或者PDF文档的页数
pdf_document.numPages
#输出PDF文档的第一页内容
first_page = pdf_document.getPage(0)
print(first_page.extractText())
输出文档第一页内容之后会发现,PyPDF2 方法对中文的支持不好,而对英文的支持会很好,所以如果处理中文文档的话,可以使用下面这个方法。
2. pdfplumber 解析 PDF 文档
安装的话直接使用下面语句即可:
pip install pdfplumber
(1)解析文本内容
pdfplumber 中的 extract_text 函数是可以直接识别 PDF 中的文本内容。
首先读取整个 PDF 文档文本内容
import pdfplumber
import pandas as pd
with pdfplumber.open(path) as pdf:
content = ''
#len(pdf.pages)为PDF文档页数
for i in range(len(pdf.pages)):
#pdf.pages[i] 是读取PDF文档第i+1页
page = pdf.pages[i]
#page.extract_text()函数即读取文本内容,下面这步是去掉文档最下面的页码
page_content = '\n'.join(page.extract_text().split('\n')[:-1])
content = content + page_content
print(content)
解析文本内容,取出 PDF 的售后解决方案中的故障代码内容,可以看到故障代码内容,如下图所示,故障代码在两页里面。

根据这类文档的规律可以知道,故障代码内容都是在文本故障代码列举如下:和 2. 之间,因此解析 PDF 之后取出这部分内容还是比较容易的:
print(content.split('故障代码列举如下:')[1].split('2.')[0])
运行结果如下,可以看出来很好的取出来这部分内容了。

(2)解析表格内容
上面介绍了 pdfplumber 解析文本内容的方法,这里介绍一下解析表格内容的方法,和上面十分类似,pdfplumber 中的 extract_tables 函数是可以直接识别 PDF 中的表格的。
这里展示解析 PDF 文档中第一页表格的方法,可以看出案例 PDF 中第一页的开头就是一个表格:

由于使用 extract_tables 函数得到的是 Table 一个嵌套的 List 类型,转化成 DataFrame 会更方便查看和分析。
import pdfplumber
import pandas as pd
with pdfplumber.open(path) as pdf:
first_page = pdf.pages[0]
for table in first_page.extract_tables():
df = pd.DataFrame(table)
df
可以看出这个函数非常容易的将 PDF 文档中的表格提取出来了。

看完上面的可以知道 pdfplumber 扩展包可以非常好的解析 PDF 的文本内容和表格内容,并且对中文有很好的支持,十分推荐使用该方法。
3. pdfminer3k 解析 PDF 文档
pdfminer3k 是 pdfminer 的 python3 版本,主要用于读取 pdf 中的文本。如果直接搜索 pdfminer3k 的话会发现网上有非常多的教程,但是看了之后,你可能就想吐槽这些教程太繁琐了,看着头疼。
下面这个是 pdfminer 解析 PDF 文档的流向图。
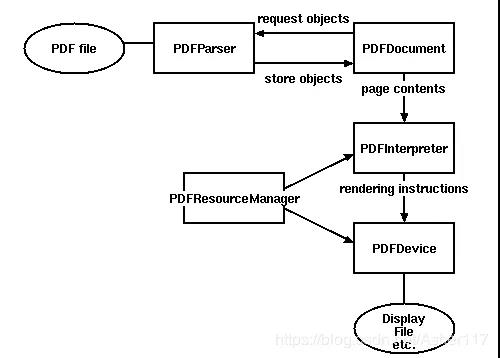
pdfminer 方法解析 PDF 可以很好的提取文本内容,但是对于表格数据,能提取出文字,但是没有格式,会很不友好。因此你如果只需要提取文本内容的话,可以使用 pdfminer 扩展包,这个包也能很好的支持中文。中文需要考虑编码和全角半角问题。
4. Camelot 解析 PDF 文档
安装
Camelot 先使用 pip install camelot-py 语句安装,如果报错,参考安装 Camelot 教程。
另外,使用 camelot 需要安装 cv2 包,上面这个安装教程中也有。
import camelot
import pandas as pd
tables = camelot.read_pdf(filepath=path,pages='1',flavor='stream')
df = pd.DataFrame(tables[0].data)
Camelot 读取 PDF 文件中的表格数据很好用,并且能够很好的支持中文,但是 Camelot 有很多局限性。
首先,使用 stream 时,表格无法被自动侦测到,stream 把整个页面当成一个 table。
其次,camelot 只用使用基于文本的 PDF 文件而不能使用扫描文档。
综上所述,建议使用 pdfplumber 扩展包来解析 PDF 文档的文本和表格,如果只解析文本内容,也可以使用 pdfminer ,而解析英文文档内容,可以使用 PyPDF2 。
read more:
python读取pdf表格_[转]Python 解析 PDF 文本和表格的四大方法介绍相关推荐
- python读取第二行_使用Python操作Excel(二):读取数据表
上一节我们提到,使用openpyxl可以方便的对数据表进行操作,例如:抽象Excel数据并存入数据库 将数据库数据导出到Excel 给一个已存在的数据表追加信息 我们还介绍了一些Excel的基本术语, ...
- python读取xls文件_从python中的xls读取unicode
我正在尝试使用 Python读取.xls文件.该文件包含多个非ascii字符(即äöü).我已经尝试过使用openpyxls和xlrd(我对xlrd寄予厚望,因为它无论如何都会读取unicode中的所 ...
- python读取sas数据集_利用Python获取SAS和R自带数据集
图:北京-奥森公园-2018年4月 无论是SAS.R还是Python,本身都自带一些数据集,对于初学者来说,可以通过这些自带的小数据集进行编程练习,无疑是非常方便的.SAS.R作为统计分析软件,本身自 ...
- python读取svg文件_使用python创建SVG
我正在构建一组SVG文件,其中包含大量的硬编码值(它们必须打印一些大小为m m的元素,而其他元素必须按百分比缩放,并且大多数值都是相对定义的).我不想用手来管理这些数字(但愿我不想改变一些事情),我想 ...
- python读取usb数据显示_在python中从各种usb设备读取和存储各种数据
您似乎认为该传感器通信协议的行尾字符是4个不同的字符:表示,在许多编程语言中,它只是用\r表示(尽管它看起来像2个字符,但它只表示一个字符).在 由于协议是结构化的,通过逐行读取传感器的数据,可以大大 ...
- python读取bmp图片_用Python读取bmp文件
我意识到这是一个老问题,但我自己解决这个问题时发现了这个问题,我想这可能会在将来帮助别人. 实际上很容易将BMP文件读取为二进制数据.当然,这取决于你需要支持的范围有多广,需要支持的角落案例有多少. ...
- 怎么用python读取大文件_使用Python读取大文件的方法
背景准备试一试:f =开放(\u201C\/道路\/ \/文件\u201D,\u201Cr\u201D)打印()最后:如果f:()调用读()将读取所有文件的内容,如果文件有10 g,记忆会破灭,所以, ...
- python 读取邮件内容_利用Python imaplib和email模块 读取邮件文本内容及附件内容...
python使用imap接收邮件的过程探索 https://www.cnblogs.com/yhlx/archive/2013/03/22/2975817.html #! encoding:utf8 ...
- python读取sav文件_在Python中读取SPSS(.sav)文件时,获取“title already used as a name or title”错误...
我正在读一个SPSS文件(.sav).我下面的代码可以读取.sav文件.但是,我遇到了一个非常奇怪的错误.当我试图读取另一个.sav文件时,它会给出以下错误Traceback (most recent ...
- python读取网络摄像头_使用Python/Linux读取网络摄像头的选项
我正在寻找一种方法,将网络摄像头集成到我的python程序中. 我运行的是Raspberry Pi型号,频率为900mHz,因此解决方案需要与ARM兼容,并且(希望)轻量级. 我看到的大多数帖子都推荐 ...
最新文章
- LeetCode: 150:逆波兰表示法求值。
- Swift_类型选择
- 支持向量机SVM原理(一)
- 内存监控及报警shell脚本
- Impala-shell 启动异常 - Python版本为3.x 启动脚本为2.x
- 计算机注册表管理,如何打开计算机注册表编辑器
- Django 2.0 学习(12):Django 模板语法
- Python : Arrow、Pyarrow库、以及与Julia互读
- Windows11 安装 WSA 简单上手一试
- 基于STM32cubemx的STM32F107vct6的代码生成,实验四串口与DMA
- lisp绘制直齿圆柱齿轮_直齿圆柱齿轮的画法
- uniapp获取经纬度
- H5通过数据流方式播放视频
- 百家讲坛-《老子智慧与现代爱情婚姻》
- 赛轮转债上市价格预测
- 【LeetCode】跳跃游戏Ⅰ~Ⅵ(我真的跳晕了@_@)
- Python处理中文文本
- 网络安全--红队资源大合集
- 过滤软件“绿坝”分析报告
- 一个“追跌卖涨”的股票筛选程序