时序数据库InfluxDB 2.0 alpha 发布:主推新的Flux查询语言,TICK栈将成为整体
InfluxDB 2.0的第一个alpha版本正式发布。2.0版本的愿景是将TICK整合成一个整体,将时序数据库、UI、仪表盘工具以及后台处理和监控代理置于一组API后面。从1.x到2.0产品线代表了自2013年以来InfluxDB产品的最大一次转变。这篇文章将介绍InfluxDB和Flux的2.x版本系列将要实现的目标、它们的构建方式,以及2.0版本alpha、beta和最终版的开发过程。
Flux,一门新语言
Flux是InfluxDB 2.0的一个重要组成部分,也就是我们的新数据脚本和查询语言。在总结了多年以来的用户功能请求、社区问题、当前的查询语言InfluxQL和TICKscript之后,我们决定构建一门新语言。Flux的设计目标是:
支持驱动图形用户体验的语言服务,让用户无需学习新语言即可完成更多任务。Flux应该比使用其他语言更容易做到这一点。
集成不同的数据源。这些数据源可能是其他数据库、第三方API、文件系统或任何存在数据的地方。与其他系统集成是这门语言的核心功能。
交叉编译。现在我们可以在时序数据库中使用多种语言,如InfluxQL、PromQL、Flux,等等。我们希望可以使用单个优化器,能够针对多个不同数据源制定计划。
除了支持多种查询语法外,Flux还必须能够与其他分析工具和环境无缝集成,包括Jupyter,以及使用Apache Arrow作为底层数据交换格式,以便与其他大数据分析系统集成。
Flux是第四代编程语言,专为数据脚本、ETL、监控和警报而设计。它的作用超越了一门查询语言和编程语言。它提供了一个规划器和优化器,无缝地结合了查询和编程,形成了一个统一的整体。

实现这些设计目标最终将得到图灵完备的Flux,不仅可以用于查询和处理时间序列数据,还可以用于处理一般的数据。在接下来的几个月,我们将详细介绍如何创建这些连接器,并将它们与查询规划器和优化器结合在一起,从而让Flux查询可以使用各个数据存储系统的独特功能。
在这个版本中,我们把重点放在InfluxDB 2.0嵌入式数据存储的查询能力上。像跨度量数学操作、top N、time shift、group by和按值排序这样的请求功能都有可能在这个初始alpha版本中实现。创建一门新的语言和一个新的查询引擎是一项艰巨而又重要的任务,不过我们的努力已经开始为我们带来回报。例如,可以看一下count是如何实现的。Flux代码库的一个主要设计目标是让外部贡献者能够很容易地添加新函数,就像Telegraf中的输入函数那样。
我们将Flux作为一个独立于InfluxDB的代码库,因为它将拥有自己的开源生命周期,无论你是否使用InfluxDB,它都是有用的。为此,我们采用了MIT许可,并接受将Flux与第三方系统进行集成的拉取请求,即使这些系统可能是InfluxDB的竞争对手。这也反映了我们在Telegraf上的一贯理念。Telegraf不仅被InfluxDB用户广泛使用,还被微软、DataDog、SignalFX、Wavefront等很多其他公司的客户广泛使用。
我们接受可能引来竞争的连接器的原因非常简单:我们意识到,Telegraf的价值源于那些输入插件,如果用户可以将这些插件作为他们的数据收集器,那么将吸引更大的社区来贡献插件,这对于InfluxDB用户来说也是有利的。在过去的三年半,Telegraf的200多个插件主要由社区(包括竞争对手)提供,而且社区的贡献和使用量超过了InfluxDB本身。
TICK成为一个整体
TICK就是我们所说的构成InfluxData平台的组件集,代表了我们用于解决时序数据库问题的四个组件:Telegraf(我们的数据收集器)、InfluxDB(我们的时序数据库)、Chronograf(我们的可视化UI)和Kapacitor(我们的处理和监控服务)。这些组件的当前版本是公司随时间推移而逐步推出的工件。
2014年,我们萌生了构建TICK组件的想法,当时正在为Influx进行A轮融资。我们的想法非常简单:时序是一种基础级的抽象概念,可用于解决很多问题,而我们正在构建一个处理时序数据的平台。换句话说:很多数据问题实际上是时序数据问题,我们将帮助人们解决这些问题。我们有一个原型数据库,需要聘请开发人员和设计人员来完成这项工作并构建其他三个组件。在2015年和2016年期间,我们开始组建团队开发这些组件,包括2015年6月的Telegraf初始版本、2015年11月的Kapacitor、2016年9月的InfluxDB 1.0,以及2016年11月重新启动的Chronograf。
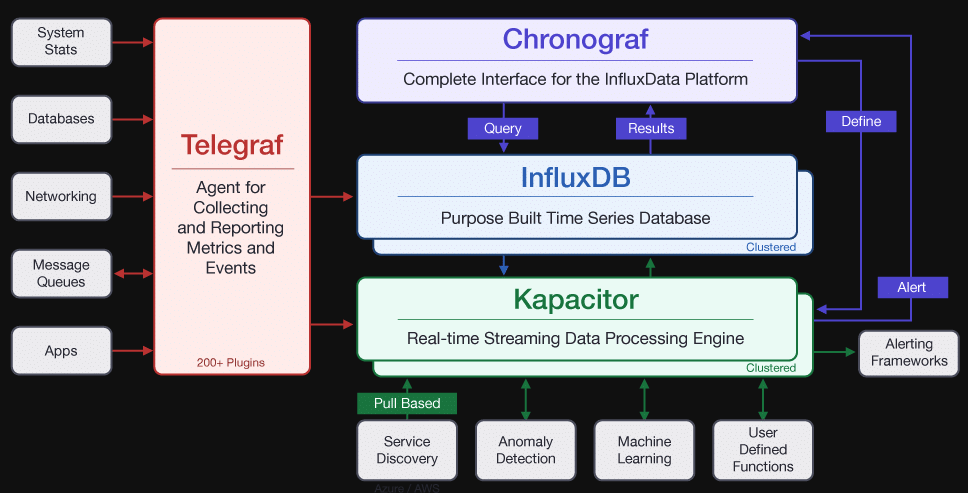
在那段时间里,我们了解到更多有关人们如何使用这个平台的信息以及他们经常遇到的问题类型。有大量关于InfluxQL的功能请求,但我们却没办法找到一种优雅的方式来添加这门新语言。
目前,大约有13%的InfluxDB用户在使用Kapacitor。我们经常听到用户抱怨TICKscript难学,也很难调试,但对于那些经历了这段旅程的用户来说,他们认为它是一个杀手级的应用程序。在InfluxDB的早期阶段,我们将UI作为数据库的一部分。将所有UI放入Chronograf的做法在当时是有争议的,现在我们意识到,如果我们只是将UI作为数据库的一部分,那么用户体验可能会更好。
以上这些因素导致了Flux的诞生。Flux是一门新语言,解决了我们无法在InfluxQL中解决的功能性问题。作为一门语言,Flux看起来比TICKscript更熟悉。将Flux作为交互式查询和后台处理语言将使开发工具变得更加容易,能够帮助用户进行调试,并查看监控、警报和ETL任务中都发生了什么。
另一个重要的推动因素是我们希望创建一个统一的平台API,旨在让InfluxDB成为一个多租户的时序数据服务。因为有了这些组件,InfluxDB实际上不仅仅是一个数据库,它是一个监控系统、一个仪表盘引擎、一个分析服务,还是一个事件和指标处理器。随着Flux的功能不断扩展,InfluxDB的功能和应用范围也将进一步扩展。
Telegraf继续在InfluxDB之外拥有自己的生命周期,同时我们将在InfluxDB 2.0中添加API,用于集成Telegraf。alpha版本提供了一个示例,可以通过用户界面创建Telegraf配置,直接从InfluxDB中获取数据。
集中的推送和拉取
InfluxDB 2.0的另一个重要部分是支持Prometheus格式。InfluxDB 2.0可以充当指标刮板,在初始入门体验中,可以选择设置本地InfluxDB服务器指标。InfluxDB 2.0提供了开箱即用的推送和拉取模型,最后我们还将支持开箱即用的PromQL查询。
未来的工作
我们希望为社区用户提供早期版本,用于收集用户反馈。在我们准备进入beta阶段之前,仍然缺少一些需要完成的核心功能。我们仍然需要提升兼容性(通过InfluxQL和1.x API查询InfluxDB 2.0),并且能够写入InfluxDB 2.0,就好像它是1.x服务器一样。我们还需要添加备份和还原、批量数据导入和导出以及数据删除功能。
这些特性大多是较低级别的API工作。在我们完成这些工作之后,UI团队将能够基于用户反馈进行快速迭代,并能够添加更多以2.0 API为基础的面向用户的特性。
我们计划从2月的第一周开始减少每周的alpha版本构建。在得到最小的特性集后,我们将进入beta阶段。在beta测试期间,我们将进行额外的bug修复、性能测试和其他准备活动。alpha构建的目的不是测试性能,而是收集有关UI和API的反馈。
整个InfluxDB 2.0 API都是基于这个Swagger文件记录和实现的。在项目进入beta阶段后,API应该是稳定的,只会有一些附加的变化。我们仍然需要将TICKscript的所有功能添加到Flux中,可以在监控和警告工作负载中使用Tasks。我们还必须创建一个TICKscript到Flux的转换器,帮助Kapacitor用户迁移到InfluxDB 2.0。
这只是一个早期版本,我们计划在InfluxDB 2.x系列版本中做更多的工作。我们还将构建我们的新InfluxData云产品——InfluxDB 2.x API的全托管版本。
InfuxDB 2.0上手指南:https://v2.docs.influxdata.com/v2.0/get-started/
英文原文:https://www.influxdata.com/blog/influxdb-2-0-alpha-release-and-the-road-ahead/
时序数据库InfluxDB 2.0 alpha 发布:主推新的Flux查询语言,TICK栈将成为整体相关推荐
- InfluxDB 2.0 Alpha展开测试!将会加入查询语言Flux
InfluxData释出其开源时序数据库InfluxDB 2.0 Alpha测试版,这个版本最大的更新,便是增加了新的数据脚本和查询语言Flux,不只能提供跨平台时序数据操作,还能将TICK组件堆栈整 ...
- 时序数据库InfluxDB介绍
时序数据库InfluxDB介绍 InfluxDB可以用来监控数据统计,每毫秒记录电脑内存使用情况,根据统计的数据结合图形化界面工具制作内存使用情况折线图,比如Grafana.InfluxDB适用于De ...
- 时序数据库InfluxDB
在系统服务部署过后,线上运行服务的稳定性是系统好坏的重要体现,监控系统状态至关重要,经过调研了解,时序数据库influxDB在此方面表现优异. influxDB介绍 时间序列数据是以时间字段为每行数据 ...
- 物联网IOT时序数据库influxdb(2.x)
物联网IOT时序数据库influxdb 物联网IOT时序数据库influxdb(2.x) 1.简介 2.InfluxDB相关概念 3.InfluxDB安装 3.1 本地安装 3.2 docker容器方 ...
- Spring Boot中使用时序数据库InfluxDB
除了最常用的关系数据库和缓存之外,之前我们已经介绍了在Spring Boot中如何配置和使用MongoDB.LDAP这些存储的案例.接下来,我们继续介绍另一种特殊的数据库:时序数据库InfluxDB在 ...
- 京东:618 期间遭「黑公关」恶意抹黑;Adobe 回应“杀死Flash”;Bootstrap 5.0 Alpha 发布 |...
整理 | 屠敏 头图 | CSDN 下载自东方 IC 快来收听极客头条音频版吧,智能播报由出门问问「魔音工坊」提供技术支持. 「极客头条」-- 技术人员的新闻圈! CSDN 的读者朋友们早上好哇,「极 ...
- 时序数据库:基于Chronograf对时序数据库InfluxDB(限流监控Sentinel的监控数据存储) 进行监控大屏展示
文章目录 前言 一.架构 二.工具 三.安装 四.大屏 总访问量 最近一小时访问量 最近一小时限流数 最近一小时异常数 最近一小时的访问趋势图(秒级别) 最近12小时资源访问排名 五.预警 六.小结 ...
- python 时序数据库_时序数据库InfluxDB
一.什么是InfluxDB? InfluxDB是一款用Go语言编写的开源分布式时序.事件和指标数据库,无需外部依赖.该数据库现在主要用于存储涉及大量的时间戳数据,如DevOps监控数据,APP met ...
- 时序数据库 InfluxDB
目录 一.介绍 二.安装 三.inflxudb保留字 四.基本语法 1.客户端操作 1. 数据库操作 2. 数据表和数据操作 3. series 操作 4.Shard 5. 用户操作 2.API操作 ...
最新文章
- 吴军:既能得诺贝尔奖,又能生产高科技产品,美国的科研机制是如何运行的?...
- Jfinal 2.1版本,JFinalConfig里自动配置路由的代码实现,直接晒代码
- MySQL 存储过程初研究
- leetcode 326. 3的幂(Power of Three)
- JavaScript操作表格进行拖拽排序
- 嵌入式linux写文件内存增加,嵌入式Linux对内存的直接读写
- omnigraffle 画曲线_Omnigraffle画线框图的新手操作指南
- 斜齿轮传动几何尺寸计算例2:斜齿角度变位-齿轮手册第2版表2.2-9
- ci php redis,一次基于CI的Redis性能问题定位
- 批处理之for /f
- mysql join 从库_Mysql实现跨库join查询
- 清华大学计算机2021研究生录取分数线,清华大学2021年研究生录取分数线多少分...
- 如何建立个人网站?先分享一下
- MacBook Pro 2018款充电口不能用解决办法
- VUE基础用法(四)
- curl ip.sb查询公网ip
- Android开发之使用createFromStream加载图片发现图片变小
- 知识分享-博客公众号推荐
- 微软任命 CEO 萨提亚·纳德拉为董事会主席
- 大数据基础之Hive(四)—— 常用函数和压缩存储