python 插补数据_python 2020中缺少数据插补技术的快速指南
python 插补数据
Most machine learning algorithms expect complete and clean noise-free datasets, unfortunately, real-world datasets are messy and have multiples missing cells, in such cases handling missing data becomes quite complex.
大多数机器学习算法期望完整且干净的无噪声数据集,但不幸的是,现实世界的数据集比较杂乱,缺少多个单元格,在这种情况下,处理丢失的数据变得相当复杂。
Therefore in today’s article, we are going to discuss some of the most effective and indeed easy-to-use data imputation techniques which can be used to deal with missing data.
因此,在今天的文章中,我们将讨论一些最有效且确实易于使用的数据插补技术,这些技术可用于处理丢失的数据。
So without any further delay, let’s get started.
因此,没有任何进一步的延迟,让我们开始吧。

什么是数据归因? (What is Data Imputation?)
Data Imputation is a method in which the missing values in any variable or data frame(in Machine learning) is filled with some numeric values for performing the task. Using this method the sample size remains the same, only the blanks which were missing are now filled with some values. This method is easy to use but the variance of the dataset is reduced.
数据插补是一种方法,其中(在机器学习中)任何变量或数据框中的缺失值都填充有一些数字值,以执行任务。 使用此方法,样本大小保持不变,现在仅将缺少的空白 填充一些值 。 这种方法易于使用,但数据集的方差减小了。
为什么要进行数据插补? (Why Data Imputation?)
There can be various reasons for imputing data, many real-world datasets(not talking about CIFAR or MNIST) containing missing values which can be in any form such as blanks, NaN, 0s, any integers or any categorical symbol. Instead of just dropping the Rows or Columns containing the missing values which come at the price of losing data which may be valuable, a better strategy is to impute the missing values.
插补数据可能有多种原因,许多现实世界的数据集(不涉及CIFAR或MNIST)包含缺失值,这些缺失值可以采用任何形式,例如空格,NaN,0,任何整数或任何分类符号 。 更好的策略是估算缺失值 ,而不是仅仅删除包含缺失值的行或列,而这些缺失值会以丢失可能有价值的数据为代价 。
Having a good theoretical knowledge is amazing but implementing them in code in a real-time machine learning project is a completely different thing. You might get different and unexpected results based on different problems and datasets. So as a Bonus,I am also adding the links to the various courses which has helped me a lot in my journey to learn Data science and ML, experiment and compare different data imputations strategies which led me to write this article on comparisons between different data imputations methods.
拥有良好的理论知识是惊人的,但是在实时机器学习项目中以代码实现它们是完全不同的。 根据不同的问题和数据集,您可能会得到不同且出乎意料的结果。 因此,作为奖励,我还添加了到各种课程的链接,这些链接对我学习数据科学和ML,实验和比较不同的数据归因策略有很大帮助,这使我撰写了有关不同数据之间的比较的本文。归因方法。
I am personally a fan of DataCamp, I started from it and I am still learning through DataCamp and keep doing new courses. They seriously have some exciting courses. Do check them out.
我个人是 DataCamp 的粉丝 ,我从此开始,但仍在学习 DataCamp 并继续 学习 新课程。 他们认真地开设了一些令人兴奋的课程。 请检查一下。
1.处理缺少输入的数据 (1. handling-missing-data-with-imputations-in-r)
2.在Python中处理丢失的数据 (2. dealing-with-missing-data-in-python)
3.处理R中的缺失数据 (3. dealing-with-missing-data-in-r)
4.在Python中构建数据工程管道 (4. building-data-engineering-pipelines-in-python)
5.数据工程概论 (5. introduction-to-data-engineering)
6.用Python进行数据处理 (6. data-manipulation-with-python)
7.熊猫数据处理 (7. data-manipulation-with-pandas)
8.使用R进行数据处理 (8. data-manipulation-with-r)
P.S: I am still using DataCamp and keep doing courses in my free time. I actually insist the readers to try out any of the above courses as per their interest, to get started and build a good foundation in Machine learning and Data Science. The best thing about these courses by DataCamp is that they explain it in a very elegant and different manner with a balanced focus on practical and well as conceptual knowledge and at the end, there is always a Case study. This is what I love the most about them. These courses are truly worth your time and money. These courses would surely help you also understand and implement Deep learning, machine learning in a better way and also implement it in Python or R. I am damn sure you will love it and I am claiming this from my personal opinion and experience.
PS:我仍在使用 DataCamp, 并在 业余时间 继续 上课 。 我实际上是坚持要求读者根据自己的兴趣尝试上述任何课程,以开始并为机器学习和数据科学打下良好的基础。 DataCamp 开设的这些课程的最好之 处 在于,他们以非常优雅且与众不同的方式 对课程进行了 解释,同时重点关注实践和概念知识,最后始终进行案例研究。 这就是我最喜欢他们的地方。 这些课程确实值得您花费时间和金钱。 这些课程肯定会帮助您更好地理解和实施深度学习,机器学习,并且还可以在Python或R中实现它。我该死的,您一定会喜欢它的,我是从我个人的观点和经验中主张这一点的。
Also, I have noticed that DataCamp is giving unlimited access to all the courses for free for one week starting from 1st of September through 8th September 2020, 12 PM EST. So this would literally be the best time to grab some yearly subscriptions(which I have) which basically has unlimited access to all the courses and other things on DataCamp and make fruitful use of your time sitting at home during this Pandemic. So go for it folks and Happy learning
此外,我注意到, DataCamp 自2020年9月1日至美国东部时间12 PM,为期一周免费无限制地访问所有课程。 因此,从字面上看,这将是获取一些年度订阅(我拥有)的最佳时间,该订阅基本上可以无限制地访问 DataCamp 上的所有课程和其他内容, 并可以在这次大流行期间充分利用您在家里的时间。 因此,请亲朋好友学习愉快
Coming back to the topic -
回到主题-
Sklearn.impute package provides 2 types of imputations algorithms to fill in missing values:
Sklearn.impute包提供了两种插补算法来填充缺失值:
1. SimpleImputer (1. SimpleImputer)
SimpleImputer is used for imputations on univariate datasets, univariate datasets are datasets that have only a single variable. SimpleImputer allows us to impute values in any feature column using only missing values in that feature space.
SimpleImputer用于单变量数据集的插补, 单变量数据集是仅具有单个变量的数据集。 SimpleImputer允许我们仅使用该要素空间中的缺失值来插补任何要素列中的值 。
There are different strategies provided to impute data such as imputing with a constant value or using the statistical methods such as mean, median or mode to impute data for each column of missing values.
提供了不同的策略来估算数据,例如以恒定值进行估算,或使用统计方法(例如均值,中位数或众数)为缺失值的每一列估算数据。
For categorical data representations, it has support for ‘most-frequent’ strategy which is like the mode of numerical values.
对于分类数据表示,它支持“最频繁”策略,就像数值模式一样。





2.迭代计算机 (2. IterativeImputer)
IterativeImputer is used for imputations on multivariate datasets, multivariate datasets are datasets that have more than two variables or feature columns per observation. IterativeImputer allows us to make use of the entire dataset of available features columns to impute the missing values.
IterativeImputer用于对多元数据集进行插补, 多元数据集是每个观察值具有两个以上变量或特征列的数据集。 IterativeImputer允许我们利用可用要素列的整个数据集来估算缺失值。
In IterativeImpute each feature with a missing value is used as a function of other features with known output and models the function for imputations. The same process is then iterated in a loop for some iterations and at each step, a feature column is selected as output y and other feature columns are treated as inputs X, then a regressor is fit on (X, y) for known y and is used to predict the missing values of y.
在IterativeImpute与缺失值的每个特征被用作与已知的输出和模式插补函数其它特征的函数 。 然后,在循环中重复相同的过程进行一些迭代,并在每个步骤中,选择一个特征列作为 输出y ,将其他特征列视为 输入X ,然后将 回归器拟合到(X,y)上 以获取已知 y 和用于 预测y的缺失值 。
The same process is repeated for each feature column in a loop and the average of all the multiple regression values are taken to impute the missing values for the data points.
对循环中的每个要素列重复相同的过程,并采用所有多个回归值的平均值来估算数据点的缺失值。

失踪图书馆 (Missingpy library)
Missingpy is a library in python used for imputations of missing values. Currently, it supports K-Nearest Neighbours based imputation technique and MissForest i.e Random Forest-based imputation technique.
Missingpy是python中的一个库,用于估算缺失值。 当前,它支持基于K最近邻的插补技术和MissForest即基于随机森林的插补技术。
To install missingpy library, you can type the following in command line:
要安装missingpy库,可以在命令行中键入以下内容:
pip install missingpy
pip install missingpy
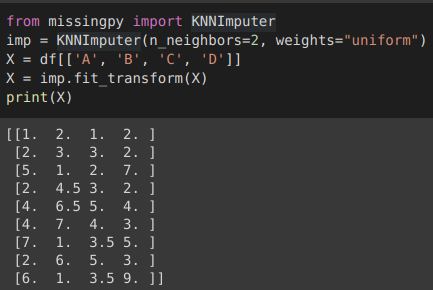
3. KNNImputer (3. KNNImputer)
KNNImputer is a multivariate data imputation technique used for filling in the missing values using the K-Nearest Neighbours approach. Each missing value is filled by the mean value form the n nearest neighbours found in the training set, either weighted or unweighted.
KNNImputer是一种多变量数据插补技术,用于使用K最近邻方法填充缺失值。 每个缺失值都由在训练集中找到的n个最近邻居 (加权或未加权)的平均值填充。
If a sample has more than one feature missing then the neighbour for that sample can be different and if the number of neighbours is lesser than n_neighbour specified then there is no defined distance in the training set, the average of that training set is used during imputation.
如果样本缺少一个以上的特征,则该样本的邻居可能会有所不同 ;如果邻居的数量小于指定的n_neighbour,则训练集中没有定义的距离,则在插补过程中将使用该训练集的平均值。
Nearest neighbours are selected on the basis of distance metrics, by default it is set to euclidean distance and n_neighbour are specified to consider for each step.
根据距离量度 选择最近的邻居 ,默认情况下将其设置为欧式距离,并为每个步骤指定要考虑的n_neighbour 。
4.小姐森林 (4. MissForest)
It is another technique used to fill in the missing values using Random Forest in an iterated fashion. The candidate column is selected from the set of all the columns having the least number of missing values.
这是另一种使用“ 随机森林 ”以迭代方式填充缺失值的技术。 从缺少值最少的所有列的集合中选择候选列 。
In the first step, all the other columns i.e non-candidate columns having missing values are filled with the mean for the numerical columns and mode for the categorical columns and after that imputer fits a random forest model with the candidate columns as the outcome variable(target variable) and remaining columns as independent variables and then filling the missing values in candidate column using the predictions from the fitted Random Forest model.
第一步,将所有其他列(即缺少值的非候选列)填充为数值列的平均值和分类列的众数,然后,imputer将候选列作为结果变量拟合随机森林模型 (目标变量)和其余列作为自变量 ,然后使用拟合随机森林模型的预测填充候选列中的缺失值。
Then the imputer moves on and the next candidate column is selected with the second least number of missing values and the process repeats itself for each column with the missing values.
然后,推动者继续前进,并选择缺失值次之的下一个候选列,并且该过程针对具有缺失值的每一列重复其自身。

进一步阅读 (Further Readings)
FancyImpute:
FancyImpute:
IterativeImputer was originally a part of the fancy impute but later on was merged into sklearn. Apart from IterativeImputer, fancy impute has many different algorithms that can be helpful in imputing missing values. Few of them are not much common in the industry but have proved their existence in some particular projects, that is why I am not including them in today's article. You can study them here.
IterativeImputer最初是幻想式估算的一部分,但后来合并为sklearn。 除了IterativeImputer之外,花式插补还具有许多不同的算法,可用于插补缺失值。 它们很少在行业中并不常见,但是已经证明它们在某些特定项目中的存在,这就是为什么我不在今天的文章中包括它们。 你可以在这里学习。
AutoImpute:
自动提示:
It is yet another python package for analysis and imputation of missing values in datasets. It supports various utility functions to examine patterns in missing values and provides some imputations methods for continuous, categorical or time-series data. It also supports multiple and single imputation frameworks for imputations. You can study them here.
它是另一个python软件包,用于分析和估算数据集中的缺失值。 它支持各种实用程序功能以检查缺失值中的模式,并为连续,分类或时间序列数据提供一些插补方法。 它还支持用于插补的多个和单个插补框架。 你可以在这里学习。
If you enjoyed reading this article, I am sure that we share similar interests and are/will be in similar industries. So let’s connect via LinkedIn and Github. Please do not hesitate to send a contact request!
如果您喜欢阅读本文,那么我相信我们有相同的兴趣并且会/将会从事相似的行业。 因此,让我们通过LinkedIn和Github进行连接。 请不要犹豫,发送联系请求!
翻译自: https://medium.com/analytics-vidhya/a-quick-guide-on-missing-data-imputation-techniques-in-python-2020-5410f3df1c1e
python 插补数据
http://www.taodudu.cc/news/show-995314.html
相关文章:
- ab 模拟_Ab测试第二部分的直观模拟
- 亚洲国家互联网渗透率_发展中亚洲国家如何回应covid 19
- 墨刀原型制作 位置选择_原型制作不再是可选的
- 使用协同过滤推荐电影
- 数据暑假实习面试_面试数据科学实习如何准备
- 谷歌 colab_如何在Google Colab上使用熊猫分析
- 边际概率条件概率_数据科学家解释的边际联合和条件概率
- 袋装决策树_袋装树是每个数据科学家需要的机器学习算法
- opencv实现对象跟踪_如何使用opencv跟踪对象的距离和角度
- 熊猫数据集_大熊猫数据框的5个基本操作
- 帮助学生改善学习方法_学生应该如何花费时间改善自己的幸福
- 熊猫数据集_对熊猫数据框使用逻辑比较
- 决策树之前要不要处理缺失值_不要使用这样的决策树
- gl3520 gl3510_带有gl gl本机的跨平台地理空间可视化
- 数据库逻辑删除的sql语句_通过数据库的眼睛查询sql的逻辑流程
- 数据挖掘流程_数据流挖掘
- 域嵌套太深_pyspark如何修改嵌套结构域
- spark的流失计算模型_使用spark对sparkify的流失预测
- Jupyter Notebook的15个技巧和窍门,可简化您的编码体验
- bi数据分析师_BI工程师和数据分析师的5个格式塔原则
- 因果推论第六章
- 熊猫数据集_处理熊猫数据框中的列表值
- 数据预处理 泰坦尼克号_了解泰坦尼克号数据集的数据预处理
- vc6.0 绘制散点图_vc有关散点图的一切
- 事件映射 消息映射_映射幻影收费站
- 匿名内部类和匿名类_匿名schanonymous
- ab实验置信度_为什么您的Ab测试需要置信区间
- 支撑阻力指标_使用k表示聚类以创建支撑和阻力
- 均线交易策略的回测 r_使用r创建交易策略并进行回测
- 初创公司怎么做销售数据分析_初创公司与Faang公司的数据科学
python 插补数据_python 2020中缺少数据插补技术的快速指南相关推荐
- python处理金融数据_Python 数据分析中金融数据的来源库和简单操作
金融数据 数据分析离不开数据的获取,这里介绍几种常用的获取金融方面数据的方法. pandas-datareader pandas-datareader 库包含了全球最著名的几家公司所整理的金融数据,这 ...
- Python之pandas:对pandas中dataframe数据中的索引输出、修改、重命名等详细攻略
Python之pandas:对pandas中dataframe数据中的索引输出.修改.重命名等详细攻略 目录 对pandas中dataframe数据中的索引输出.修改.重命名等详细攻略 知识点学习 输 ...
- python文本筛选_使用python对多个txt文件中的数据进行筛选的方法
使用python对多个txt文件中的数据进行筛选的方法 一.问题描述 筛选出多个txt文件中需要的数据 二.数据准备 这是我自己建立的要处理的文件,里面是随意写的一些数字和字母 三.程序编写 impo ...
- 通过Python的pdfplumber库提取pdf中表格数据
文章目录 前言 一.pdfplumber库是什么? 二.安装pdfplumber库 三.查看pdfplumber库版本 四.提取pdf中表格数据 1.引入库 2.定义pdf文件路径 3.打开pdf文件 ...
- 系统的认识大数据人工智能数据分析中的数据
今天,大量数据.信息充斥我的日常生活和工作中,仿佛生活在数据和信息的海洋中,各类信息严重影响了我们的生活,碎片.垃圾.过时信息耗费了我们宝贵时间,最后可留在我们大脑中的数据.信息和知识少之又少,如何提 ...
- java代码转置sql数据_SQL Server中的数据科学:数据分析和转换–使用SQL透视和转置
java代码转置sql数据 In data science, understanding and preparing data is critical, such as the use of the ...
- hive通过外表把数据存到mysql中_hive数据去重
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能 hive的元数据存储:通常是存储在关系数据库如 mysql(推荐) , derby(内嵌 ...
- mssql查询括号前的数据及括号中的数据
mssql查询括号前的数据及括号中的数据 select CASE WHEN CHARINDEX('-',Name)=0 THEN REVERSE(stuff(reverse(Name), 1, cha ...
- python查看dataframe数据类型_python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数 ...
最新文章
- 清橙 A1120 拦截导弹 -- 动态规划(最长上升子序列)
- 更新Svn客户端后,右键菜单中没有TortoiseSVN了
- QML与Qt C++ 交互机制详解
- java将xml中的标签名称转为小写_深入学习Java Web(七): JSTL标签库
- ssl2661-廉价最短路径【SPFA】
- 重装谷歌浏览器chrome:未知错误导致安装失败
- linux之Ansible快速入门
- 零基础搭建Hadoop大数据处理-初识
- 程序员必知:平凡而又神奇的贝叶斯方法
- emc re 整改 超标_资深EMC工程师总结:EMC整改流程及常见问题
- 八数码问题matlab实现,A* 算法解决八数码问题 matlab
- dotnet OpenXML PPT 动画框架入门
- 理解和应用共线平面束
- VB中的二维数组输出的定位
- 九寨沟地震类毕业论文文献都有哪些?
- UVa10158 War
- 项目干系人管理-知识领域
- MANTIS新手操作教程
- 日语在线翻译网站大集合- -
- File-Upload