python实现数据恢复_使用sklearn进行对数据标准化、归一化以及将数据还原的方法...
在对模型训练时,为了让模型尽快收敛,一件常做的事情就是对数据进行预处理。
这里通过使用sklearn.preprocess模块进行处理。
一、标准化和归一化的区别
归一化其实就是标准化的一种方式,只不过归一化是将数据映射到了[0,1]这个区间中。
标准化则是将数据按照比例缩放,使之放到一个特定区间中。标准化后的数据的均值=0,标准差=1,因而标准化的数据可正可负。
二、使用sklearn进行标准化和标准化还原
原理:
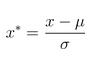
即先求出全部数据的均值和方差,再进行计算。
最后的结果均值为0,方差是1,从公式就可以看出。
但是当原始数据并不符合高斯分布的话,标准化后的数据效果并不好。
导入模块
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from matplotlib import gridspec
import numpy as np
import matplotlib.pyplot as plt
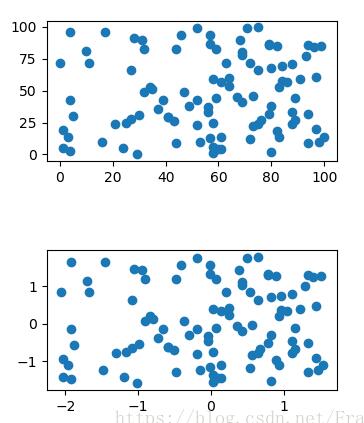
通过生成随机点可以对比出标准化前后的数据分布形状并没有发生变化,只是尺度上缩小了。
cps = np.random.random_integers(0, 100, (100, 2))
ss = StandardScaler()
std_cps = ss.fit_transform(cps)
gs = gridspec.GridSpec(5,5)
fig = plt.figure()
ax1 = fig.add_subplot(gs[0:2, 1:4])
ax2 = fig.add_subplot(gs[3:5, 1:4])
ax1.scatter(cps[:, 0], cps[:, 1])
ax2.scatter(std_cps[:, 0], std_cps[:, 1])
plt.show()
sklearn.preprocess.StandardScaler的使用:
先是创建对象,然后调用fit_transform()方法,需要传入一个如下格式的参数作为训练集。
X : numpy array of shape [n_samples,n_features]Training set.
data = np.random.uniform(0, 100, 10)[:, np.newaxis]
ss = StandardScaler()
std_data = ss.fit_transform(data)
origin_data = ss.inverse_transform(std_data)
print('data is ',data)
print('after standard ',std_data)
print('after inverse ',origin_data)
print('after standard mean and std is ',np.mean(std_data), np.std(std_data))
通过invers_tainsform()方法就可以得到原来的数据。
打印结果如下:
可以看到生成的数据的标准差是1,均值接近0。
data is [[15.72836992]
[62.0709697 ]
[94.85738359]
[98.37108557]
[ 0.16131774]
[23.85445883]
[26.40359246]
[95.68204855]
[77.69245742]
[62.4002485 ]]
after standard [[-1.15085842]
[ 0.18269178]
[ 1.12615048]
[ 1.22726043]
[-1.59881442]
[-0.91702287]
[-0.84366924]
[ 1.14988096]
[ 0.63221421]
[ 0.19216708]]
after inverse [[15.72836992]
[62.0709697 ]
[94.85738359]
[98.37108557]
[ 0.16131774]
[23.85445883]
[26.40359246]
[95.68204855]
[77.69245742]
[62.4002485 ]]
after standard mean and std is -1.8041124150158794e-16 1.0
三、使用sklearn进行数据的归一化和归一化还原
原理:
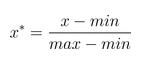
从上式可以看出归一化的结果跟数据的最大值最小值有关。
使用时类似上面的标准化
data = np.random.uniform(0, 100, 10)[:, np.newaxis]
mm = MinMaxScaler()
mm_data = mm.fit_transform(data)
origin_data = mm.inverse_transform(mm_data)
print('data is ',data)
print('after Min Max ',mm_data)
print('origin data is ',origin_data)
结果:
G:\Anaconda\python.exe G:/python/DRL/DRL_test/DRL_ALL/Grammar.py
data is [[12.19502214]
[86.49880021]
[53.10501326]
[82.30089405]
[44.46306969]
[14.51448347]
[54.59806596]
[87.87501465]
[64.35007178]
[ 4.96199642]]
after Min Max [[0.08723631]
[0.98340171]
[0.58064485]
[0.93277147]
[0.47641582]
[0.11521094]
[0.59865231]
[1. ]
[0.71626961]
[0. ]]
origin data is [[12.19502214]
[86.49880021]
[53.10501326]
[82.30089405]
[44.46306969]
[14.51448347]
[54.59806596]
[87.87501465]
[64.35007178]
[ 4.96199642]]
Process finished with exit code 0
其他标准化的方法:
上面的标准化和归一化都有一个缺点就是每当来一个新的数据的时候就要重新计算所有的点。
因而当数据是动态的时候可以使用下面的几种计算方法:
1、arctan反正切函数标准化:
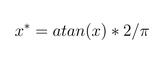
2、ln函数标准化
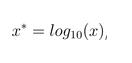
以上这篇使用sklearn进行对数据标准化、归一化以及将数据还原的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
python实现数据恢复_使用sklearn进行对数据标准化、归一化以及将数据还原的方法...相关推荐
- python svr回归_使用sklearn库中的SVR做回归分析
sklearn中的回归有多种方法,广义线性回归集中在linear_model库下,例如普通线性回归.Lasso.岭回归等:另外还有其他非线性回归方法,例如核svm.集成方法.贝叶斯回归.K近邻回归.决 ...
- python聚类分析散点图_使用sklearn对iris数据集进行聚类分析
导入库 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns fro ...
- python一年收入_你的年收入过5万了吗?数据科学家的Python模块和包
全文共2327字,预计学习时长15分钟 图源:unsplash 笔者刚开始学习给数据科学编程时,发现要找到创建模块和包的简单解释以及教程非常困难,尤其是数据科学项目方面. 数据科学代码通常是非常线性的 ...
- Python遥感图像处理应用篇(十六):GDAL 将归一化处理csv数据转化为遥感影像
1.使用数据 将上一篇文章中得到的计算结果作为转换数据.链接如下: Python遥感图像处理应用篇(十五):GDAL 读取多光谱数据做归一化处理_空中旋转篮球的博客-CSDN博客 2.实现代码 基本思 ...
- python实现数据恢复_数据恢复/电子取证 非常有用的python库——Construct | 学步园...
和硬盘打交道,不免会用到字节.大\小端对齐.结构等.C语言定义了很多类型,我们定义一个结构,配合mem***函数.大小端转换宏等几乎可以应付了.Python就没那么好用了,因为它本身也不是为这种低级操 ...
- python 召回率_使用sklearn获取精确性和召回率
这有点不同,因为对于非二进制分类,交叉值分数不能计算精度/召回率,所以需要使用recision-score.recall-score和手工进行交叉验证.参数average='micro'计算全局精度/ ...
- python数据分析实况_机器学习竞赛分享:通用的团队竞技类的数据分析挖掘方法...
前言 该篇分享来源于NFL竞赛官方的R语言版本,我做的主要是翻译为Python版本: 分享中用到的技巧.构建的特征.展示数据的方式都可以应用到其他领域,比如篮球.足球.LOL.双人羽毛球等等,只要是团 ...
- python过拟合_梯度下降、过拟合和归一化
好的课程应该分享给更多人:,点开任意一个之后会发现他们会提供系列课程整合到一起的百度网盘下载地址,包括视频+代码+资料,免费的优质资源.当然,现在共享非常多,各种mooc.博客.论坛等,很容易就可以找 ...
- python数据标准化代码_可能是最全的数据标准化教程(附python代码)
什么是数据标准化(归一化) 数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标 ...
最新文章
- can差分线阻抗_CAN总线冷知识—边沿台阶是怎么来的?
- FastJson、Jackson、Gson进行Java对象转换Json的细节处理
- 【数学与算法】奇异矩阵、奇异值、奇异值分解、奇异性
- hdu 3172(并查集+hash)
- Linux df -h查看磁盘使用情况
- 【struts2】预定义拦截器
- ClickHouse表引擎之Integration系列
- hyperv虚拟机网络速度慢问题的解决办法
- 关于Vue.js的v-for,key的顺序改变,影响过渡动画表现
- simotion基本功能手册_深入浅出西门子运动控制器:SIMOTION实用手册
- copy的过去式_copy什么意思_copy是什么意思中文翻译
- 无法加载JIT编译器问题解决
- android多边形图片,android – 按多边形区域裁剪图像
- AWVS安装(未来即将到来)
- WiFi、WiMAX、WBMA与3G的比较(图)
- Python8.2(3)传递实参
- 大众文艺杂志大众文艺杂志社大众文艺编辑部2022年第9期目录
- 吉多·范罗苏姆 --python创始人
- 【2021年1月】RT-Thread社区简报
- 安卓开发学习日记第三天_新手怪button_莫韵乐的欢乐笔记