SQL Server中的数据库文件组和零碎还原
So far, we discussed many de-facto details about SQL Server database backup and restore. In this 15th article of the series, we are going to discuss, the file-group and piecemeal database backup and restore process.
到目前为止,我们讨论了有关SQL Server数据库备份和还原的许多实际细节。 在本系列的第 15篇文章中,我们将讨论文件组和零碎的数据库备份和还原过程。
Database “Backup and Restore” strategies are vital to every organization for smoother functioning of the business. Database design concepts are also important in defining the backup and restore strategy. A good database design structure and proper planning would give us an ample time to speed up the recovery process.
数据库“ 备份和还原 ”策略对于每个组织而言,对于企业的平稳运行至关重要。 数据库设计概念对于定义备份和还原策略也很重要。 良好的数据库设计结构和适当的计划将为我们提供充足的时间来加快恢复过程。
In this article, we will discuss the following topics:
在本文中,我们将讨论以下主题:
- Introduction 介绍
- Explain file-group(s) level database backup and restore operations 说明文件组级别的数据库备份和还原操作
- Discuss piecemeal database restore process 讨论零散的数据库还原过程
- Demo 演示版
- And more… 和更多…
In some cases, taking full database backup sis not a big deal, whereas, for VLDB databases or large OLTP databases, it may not be a feasible solution to initiate frequent full database backups in-and-out. In such scenarios, the file(s) and filegroup(s) backup and restore options play a vital role.
在某些情况下,进行完整的数据库备份没什么大不了的,而对于VLDB数据库或大型OLTP数据库,启动频繁的内部和外部数据库备份并不是可行的解决方案。 在这种情况下,文件和文件组的备份和还原选项起着至关重要的作用。
If you are operating VLDB database, in some cases, it becomes a daunting task to perform full database backup and restore as it may take several hours to complete the backup and restore operation.
如果您正在操作VLDB数据库,则在某些情况下,执行完整的数据库备份和还原将是一项艰巨的任务,因为完成备份和还原操作可能需要几个小时。
Piecemeal restore helps with databases that contain multiple filegroups to be restored and recovered at multiple stages. This would give an option to customize the backup and restore (or recovery) solution.
零散还原可帮助包含多个文件组的数据库在多个阶段还原和恢复。 这将提供自定义备份和还原(或恢复)解决方案的选项。
Based on recommended practices and database design principles; if the database is designed to leverage data and segments to different file groups and store them on a different drive this provides a great advantage when doing backups of the database, and restoring the database in case of any database corruption or failure. Let’s say that one of the non-primary data files may become corrupt or otherwise it can go offline due to some hardware failure then there is no need to perform the full database restores, instead, only restore the filegroup that are needed. This operation will suffice or speed-up the entire restoration process.
基于推荐的做法和数据库设计原则; 如果数据库旨在将数据和段利用到不同的文件组,并将它们存储在不同的驱动器上,则在进行数据库备份以及在发生数据库损坏或故障的情况下还原数据库时,这将具有很大的优势。 假设非主要数据文件之一可能由于某些硬件故障而损坏或可能脱机,则无需执行完整的数据库还原,而是仅还原所需的文件组。 此操作将满足或加速整个恢复过程。
入门 (Getting started)
Let us jump into the demo to see how to perform the backup and restore operation.
让我们跳到演示中,看看如何执行备份和还原操作。
In most of the cases, a single data file and log file works best for the database design requirement. If you’re planning to leverage data across multiple data files, create secondary file groups for the data and indexes, and make the secondary filegroup a default one for the storage. In this way, the primary-file will contain only the system objects. Then it’s possible that a single file group’s data file may become corrupted or otherwise go offline due to hardware failure or I/O subsystem failure. When this happens, there’s no need to perform a full database restore. After all, the rest of the file groups are all still safe and sound. By only restoring the file groups that need it, this way you can speed up the entire restoration process.
在大多数情况下,单个数据文件和日志文件最适合数据库设计要求。 如果您打算利用多个数据文件中的数据,请为数据和索引创建辅助文件组,并将辅助文件组作为存储的默认文件组。 这样,主文件将仅包含系统对象。 然后,由于硬件故障或I / O子系统故障,单个文件组的数据文件可能会损坏或脱机。 发生这种情况时,无需执行完整的数据库还原。 毕竟,其余所有文件组仍然安全无事。 通过仅还原需要它的文件组,可以加快整个还原过程。
Let’s go ahead and complete the prep work by executing the following the T-SQL:
让我们继续执行以下T-SQL,以完成准备工作:
The SQLShackFGDB database is created for the demo.
为该演示创建了 SQLShackFGDB数据库。
CREATE DATABASE SQLShackFGDB; GO USE SQLShackFGDB;Change the recovery model of the SQLShackFGDB database to FULL
将SQLShackFGDB数据库的恢复模型更改为FULL
ALTER DATABASE SQLShackFGDB SET RECOVERY FULL;- archiveData.ndf to the filegroup archiveData.ndf添加到文件组SecondarySQLShackFGDB to a SecondarySQLShackFGDB到SQLShackFGDB databaseSQLShackFGDB数据库
ALTER DATABASE SQLShackFGDB ADD FILEGROUP SecondarySQLShackFGDB; GOALTER DATABASE SQLShackFGDB ADD FILE (NAME = archiveData,FILENAME = 'f:\powerSQL\archiveData.ndf',SIZE = 5MB,MAXSIZE = 100MB,FILEGROWTH = 10MB ) TO FILEGROUP SecondarySQLShackFGDB; - Primary 主
- SecondarySQLShackFGDB 二级SQLShackFGDB
SELECT DB_NAME() databasename, sf.name FileName, size/128 SizeMB, fg.name FGName,sf.physical_name FROM sys.database_files sf INNER JOIN sys.filegroups fg ON sf.data_space_id=fg.data_space_id
Verify the location and it’s status of all the respective data and log files
验证所有各自的数据和日志文件的位置及其状态
SELECT name, physical_name, state_descFROM sys.master_filesWHERE database_id = DB_ID('SQLShackFGDB');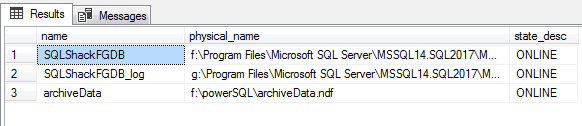
- ActiveSQLShackAuthor , and we’ll store it on the primary file group. Then, a second table called ActiveSQLShackAuthor ,我们将其存储在主文件组中。 然后,第二个表称为InactiveSQLShackAuthor, and this one on the InactiveSQLShackAuthor ,该表位于SecondarySQLShackFGDB file group. SecondarySQLShackFGDB文件组上。
CREATE TABLE ActiveSQLShackAuthor (ID int IDENTITY(1,1) PRIMARY KEY,AUthorName nvarchar(100) NOT NULL); GOCREATE TABLE InactiveSQLShackAuthor (ID int IDENTITY(1,1) PRIMARY KEY,AUthorName nvarchar(100) NOT NULL) ON SecondarySQLShackFGDB; GO Populate data into these tables
将数据填充到这些表中
INSERT INTO ActiveSQLShackAuthor (AUthorName) values('Active1'),('Active2'),('Active3'),('Active4'),('Active5')GO INSERT INTO InactiveSQLShackAuthor (AUthorName) values('Inactive1'),('Inactive2'),('Inactive3'),('Inactive4'),('Inactive5')Verify the existence of inserted data into the SQL table
验证是否存在插入到SQL表中的数据
SELECT * FROM ActiveSQLShackAuthor; SELECT * FROM InActiveSQLShackAuthor;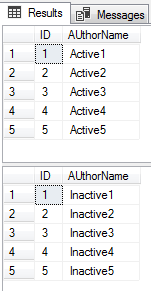
The following query list all the objects that are create on all the filegroups in the database
以下查询列出了在数据库中所有文件组上创建的所有对象
SELECT OBJECT_NAME(st.object_id) AS ObjectName, sds.name AS FileGroupFROM sys.data_spaces sdsJOIN sys.indexes si on si.data_space_id = sds.data_space_idJOIN sys.tables st on st.object_id = si.object_idWHERE si.index_id < 2AND st.type = 'U'; GO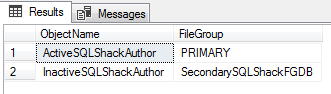
This section walkthrough the backup and restore step.
本节介绍了备份和还原步骤。
First, initiate a backup of the entire database using full database backup command. The WITH format option is used to override the already existing backups in the f:/PowerSQL/ folder.
首先,使用full database backup命令启动整个数据库的备份。 WITH格式选项用于覆盖f:/ PowerSQL /文件夹中已经存在的备份。
-- backup the database
BACKUP DATABASE SQLShackFGDBTO DISK = 'f:\PowerSQL\SQLShackFGDB.bak'WITH FORMAT;
Let’s insert few more records into the InactiveSQLShackAuthor table.
让我们再向InactiveSQLShackAuthor表中插入几条记录。
INSERT INTO InactiveSQLShackAuthor (AuthorName)
values('Inactive6'),
('Inactive7'),
('Inactive8'),
('Inactive9'),
('Inactive10')
I’ll execute the following statement to create the backup of the filegroup.
我将执行以下语句来创建文件组的备份。
-- backup the secondary filegroup by itself
BACKUP DATABASE SQLShackFGDBFILEGROUP = 'SecondarySQLShackFGDB'TO DISK = 'f:\PowerSQL\SecondarySQLShackFGDB.bak'
GO
Let’s simulate the hardware failure event by deleting the files. Now, the SQL Server won’t be able to access the secondary filegroup.
让我们通过删除文件来模拟硬件故障事件。 现在,SQL Server将无法访问辅助文件组。
Bring the database offline
使数据库脱机
USE MASTER; GO ALTER DATABASE SQLShackFGDB SET OFFLINE WITH ROLLBACK IMMEDIATE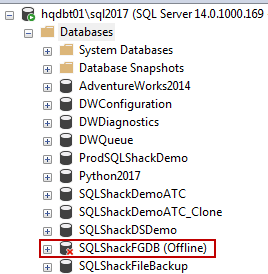
Locate the the secondary file and delete
找到辅助文件并删除

Now, try to bring the database online
现在,尝试使数据库联机
USE MASTER; GO ALTER DATABASE SQLShackFGDB SET ONLINE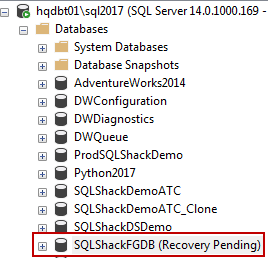
Check the error-log to isolate the issue. As we’ve deleted the file, the error-log report about the missing file.
检查错误日志以找出问题所在。 当我们删除文件时,有关丢失文件的错误日志报告。
Initiate a tail-log backup to recover the newly added data entries from the transaction log file.
启动尾日志备份,以从事务日志文件中恢复新添加的数据条目。
USE MASTER GO -- need a tail log backup first BACKUP LOG SQLShackFGDBTO DISK = 'f:\PowerSQL\SQLShackFGDBTaillog.bak'WITH NO_TRUNCATE; GONow, restore the secondary filegroup from the backup with NORECOVERY option.
现在,使用NORECOVERY选项从备份中还原辅助文件组。
RESTORE DATABASE SQLShackFGDBFILE = 'archiveData',FILEGROUP = 'SecondarySQLShackFGDB'FROM DISK = 'f:\PowerSQL\SecondarySQLShackFGDB.bak'WITH NORECOVERY GO
Apply the tail log to the database to bring it online
将尾日志应用于数据库以使其联机
RESTORE LOG SQLShackFGDBFROM DISK = 'f:\PowerSQL\SQLShackFGDBTaillog.bak'WITH RECOVERY GO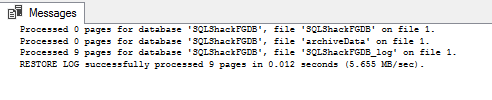
Let’s go ahead validate the recovery process by querying the SQL table.
让我们继续通过查询SQL表来验证恢复过程。
SELECT * FROM ActiveSQLShackAuthor; SELECT * FROM InActiveSQLShackAuthor;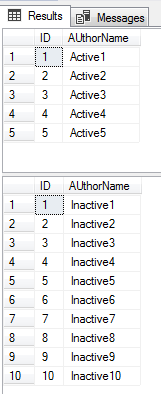
零碎还原 (Piecemeal restore)
Piecemeal restore process involves a series of restore step sequences, starting with the primary and, one or more secondary read-write filegroups followed by read-only filegroups.
零碎还原过程涉及一系列还原步骤序列,从主要和一个或多个辅助读写文件组开始,然后是只读文件组。
In some scenarios, we need to do a database restore from the backup. As we know, we do have the option to restore required file groups but not all of the file groups are requirered to make the database online at a specific instance. It is always required to restore the primary file group but any secondary user defined file groups are optional, at that point, while doing the restore. After the restore, one could get partial data and it’s available online and for the rest of the data, the users can wait, for a period of time,to recover other filegroups.
在某些情况下,我们需要从备份中还原数据库。 众所周知,我们确实可以选择还原所需的文件组,但并非所有文件组都需要还原才能在特定实例上使数据库联机。 始终需要还原主文件组,但是此时,在进行还原时,任何辅助用户定义的文件组都是可选的。 还原后,可以获取部分数据,并且该数据可以在线使用,而对于其余数据,用户可以等待一段时间,以恢复其他文件组。
The RESTORE DATABASE command with PARTIAL clause starts a new piecemeal restore operation. The keyword PARTIAL indicates that the restore process involves a partial restore. The partial keyword defines and initiates the partial-restore sequence. This will be validated during the recovery stages. The state of the database restores remains to be recovery pending because their database recovery has been postponed.
带有PARTIAL子句的RESTORE DATABASE命令将启动新的逐段还原操作。 关键字PARTIAL表示还原过程涉及部分还原。 部分关键字定义并启动部分恢复序列。 这将在恢复阶段得到验证。 数据库还原的状态仍处于恢复挂起状态,因为其数据库恢复已被推迟。
Let us follow the below steps to prove the concept of the piecemeal process
让我们按照以下步骤来证明零碎过程的概念
First, add another filegroup to store the static data
首先,添加另一个文件组来存储静态数据
ALTER DATABASE SQLShackFGDB ADD FILEGROUP ReadOnlySQLShackFGDB; GOALTER DATABASE SQLShackFGDB ADD FILE (NAME = readonlyData,FILENAME = 'f:\powerSQL\readonlydata.ndf',SIZE = 5MB,MAXSIZE = 100MB,FILEGROWTH = 10MB ) TO FILEGROUP ReadOnlySQLShackFGDB; GOAdd a table to the filegroup ReadOnlySQLShackFGDB and insert few records to the table
将表添加到文件组ReadOnlySQLShackFGDB并将少量记录插入表中
CREATE TABLE ReportSQLShackAuthor (ID int IDENTITY(1,1) PRIMARY KEY,AUthorName nvarchar(100) NOT NULL) ON ReadOnlySQLShackFGDB; GOINSERT INTO ReportSQLShackAuthor (AUthorName) values('Report1'), ('Report2'), ('Report3'), ('Report4'), ('Report5')Query the table to validate the data
查询表以验证数据
select * from ReportSQLShackAuthor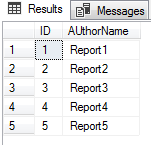
To change the filegroup state to read_only use the following alter database command
要将文件组状态更改为read_only,请使用以下alter database命令
use master GO ALTER DATABASE SQLShackFGDB MODIFY FILEGROUP ReadOnlySQLShackFGDB READ_ONLY;
Backup the SQLShackFGDB database
备份SQLShackFGDB数据库
BACKUP DATABASE SQLShackFGDBTO DISK = 'f:\PowerSQL\SQLShackFGDB.bak'WITH FORMAT; GOThe database has three filegroup, One is read-only and other two are in read-write mode. Verify the filegroup status by executing the following T-SQL
该数据库具有三个文件组,一个是只读文件,另外两个处于读写模式。 通过执行以下T-SQL验证文件组状态
SELECT DB_NAME() databasename, sf.name FileName, size/128 SizeMB, fg.name FGName,sf.physical_name, sf.state_desc, sf.is_read_only FROM sys.database_files sf INNER JOIN sys.filegroups fg ON sf.data_space_id=fg.data_space_id
Backup the read-only database
备份只读数据库
BACKUP DATABASE SQLShackFGDBFILEGROUP = 'ReadOnlySQLShackFGDB'TO DISK = 'f:\PowerSQL\ReadOnlySQLShackFGDB.bak' WITH FORMAT GO
Now, drop the database to simulate the piecemeal recovery process of the database
现在,删除数据库以模拟数据库的逐步恢复过程
USE MASTER; GO DROP DATABASE SQLShackFGDBLet’s perform the database restore operation. Before you start, change the session context to master database. Now, we’re going to do the read-write filegroups restore using READ_WRITE_FILEGROUPS clause.
让我们执行数据库还原操作。 在开始之前,请将会话上下文更改为master数据库。 现在,我们将使用READ_WRITE_FILEGROUPS子句进行读写文件组还原。
USE MASTER GO RESTORE DATABASE SQLShackFGDB READ_WRITE_FILEGROUPS FROM DISK = 'f:\PowerSQL\SQLShackFGDB.bak' WITH PARTIAL, RECOVERY GO SELECT TOP (1000) [ID],[AUthorName]FROM [SQLShackFGDB].[dbo].[InactiveSQLShackAuthor]GOSELECT TOP (1000) [ID],[AUthorName]FROM [SQLShackFGDB].[dbo].ReportSQLShackAuthor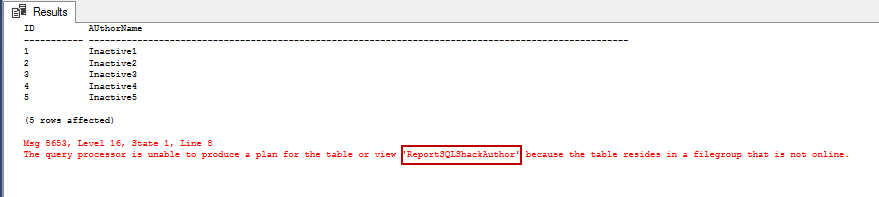
Next, restore the read-only filegroups
接下来,还原只读文件组
RESTORE DATABASE SQLShackFGDBFILE = 'readonlyData',FILEGROUP = 'ReadOnlySQLShackFGDB'FROM DISK = 'f:\PowerSQL\ReadOnlySQLShackFGDB.bak'WITH RECOVERY
Verify the output by querying the read-only table data
通过查询只读表数据验证输出
SELECT TOP (1000) [ID],[AUthorName]FROM [SQLShackFGDB].[dbo].[InactiveSQLShackAuthor]GOSELECT TOP (1000) [ID],[AUthorName]FROM [SQLShackFGDB].[dbo].ReportSQLShackAuthor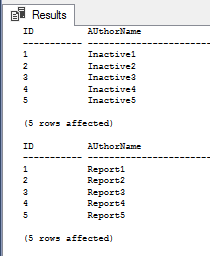
结语 (Wrapping up)
This article walkthrough the database backup and restore (or recovery) of a SQL Server that contain multiple files or filegroups.
本文介绍了包含多个文件或文件组SQL Server的数据库备份和还原(或恢复)。
We also talked about file and filegroup level backup and the available options to restore partial databases with the concept of a piecemeal restore. We saw how to perform the database recovery process by enabling filegroup backups. There is an option available, that we reviewed, to speed up the recovery process without having to restore the entire database.
我们还讨论了文件和文件组级别的备份,以及使用零碎还原的概念还原部分数据库的可用选项。 我们看到了如何通过启用文件组备份来执行数据库恢复过程。 我们审查了一个可用的选项,可以加快恢复过程,而不必还原整个数据库。
目录 (Table of contents)
| Database Backup and Restore process in SQL Server – series intro |
| An overview of the process of SQL Server backup-and-restore |
| Understanding the SQL Server Data Management Life Cycle |
| Understanding SQL Server database recovery models |
| Understanding SQL Server Backup Types |
| Backup and Restore (or Recovery) strategies for SQL Server database |
| Discussing Backup and Restore Automation using SQLCMD and SQL Server agent |
| Understanding Database snapshots vs Database backups in SQL Server |
| SqlPackage.exe – Automate SQL Server Database Restoration using bacpac with PowerShell or Batch techniques |
| Smart database backup in SQL Server 2017 |
| How to perform a Page Level Restore in SQL Server |
| Backup Linux SQL Server databases using PowerShell and Windows task scheduler |
| SQL Server Database backup and restore operations using the Cloud |
| Tail-Log Backup and Restore in SQL Server |
| SQL Server Database Backup and Restore reports |
| Database Filegroup(s) and Piecemeal restores in SQL Server |
| In-Memory Optimized database backup and restore in SQL Server |
| Understanding Backup and Restore operations in SQL Server Docker Containers |
| Backup and Restore operations with SQL Server 2017 on Docker containers using Azure Data Studio |
| Interview questions on SQL Server database backups, restores and recovery – Part I |
| Interview questions on SQL Server database backups, restores and recovery – Part II |
| Interview questions on SQL Server database backups, restores and recovery – Part III |
| Interview questions on SQL Server database backups, restores and recovery – Part IV |
| SQL Server中的数据库备份和还原过程–系列简介 |
| SQL Server备份和还原过程概述 |
| 了解SQL Server数据管理生命周期 |
| 了解SQL Server数据库恢复模型 |
| 了解SQL Server备份类型 |
| SQL Server数据库的备份和还原(或恢复)策略 |
| 讨论使用SQLCMD和SQL Server代理进行备份和还原自动化 |
| 了解SQL Server中的数据库快照与数据库备份 |
| SqlPackage.exe –使用bacpac和PowerShell或Batch技术自动执行SQL Server数据库还原 |
| SQL Server 2017中的智能数据库备份 |
| 如何在SQL Server中执行页面级还原 |
| 使用PowerShell和Windows任务计划程序备份Linux SQL Server数据库 |
| 使用CloudSQL Server数据库备份和还原操作 |
| SQL Server中的尾日志备份和还原 |
| SQL Server数据库备份和还原报告 |
| SQL Server中的数据库文件组和零碎还原 |
| 在SQL Server中进行内存优化的数据库备份和还原 |
| 了解SQL Server Docker容器中的备份和还原操作 |
| 使用Azure Data Studio在Docker容器上使用SQL Server 2017进行备份和还原操作 |
| 有关SQL Server数据库备份,还原和恢复的面试问题–第一部分 |
| 有关SQL Server数据库备份,还原和恢复的面试问题–第二部分 |
| 有关SQL Server数据库备份,还原和恢复的面试问题–第三部分 |
| 有关SQL Server数据库备份,还原和恢复的面试问题–第IV部分 |
参考资料 (References)
- BACKUP (Transact-SQL)备份(Transact-SQL)
- Example: Piecemeal Restore of Only Some Filegroups (Full Recovery Model)示例:仅部分文件组的逐个还原(完整恢复模型)
- Example: Piecemeal Restore of Only Some Filegroups (Simple Recovery Model)示例:仅部分文件组的逐个还原(简单恢复模型)
翻译自: https://www.sqlshack.com/database-filegroups-and-piecemeal-restores-in-sql-server/
SQL Server中的数据库文件组和零碎还原相关推荐
- SQL Server FILESTREAM查询和文件组
In this series of the SQL Server FILESTREAM (see TOC at bottom), We have gone through various aspect ...
- SQL Server中的即时文件初始化概述
This article gives an overview of Instant File Initialization and its benefits for SQL Server databa ...
- 什么是SQL Server中的数据库规范化?
In addition to specifically addressing database normalization in SQL Server, this article will also ...
- SQL Server中读取XML文件的简单做法
SQL Server 2000使得以XML导出数据变得更加简单,但在SQL Server 2000中导入XML数据并对其进行处理则有些麻烦.本文介绍在SQL Server中读取XML文件的简单做法. ...
- SQL Server中通用数据库角色权限的处理详解
SQL Server中通用数据库角色权限的处理详解 前言 安全性是所有数据库管理系统的一个重要特征.理解安全性问题是理解数据库管理系统安全性机制的前提. 最近和同事在做数据库权限清理的事情,主要是删除 ...
- sql server中创建数据库和表的语法
下面是sql server中创建数据库,创建数据表以及添加约束的sql语句: use master --创建数据库 if exists (select * from sysdatabases wher ...
- 在SQL Server中的数据库之间复制表的六种不同方法
In this article, you'll learn the key skills that you need to copy tables between SQL Server instanc ...
- SQL Server 中创建数据库、更改主文件组示例
以下示例在 SQL Server 实例上创建了一个数据库.该数据库包括一个主数据文件.一个用户定义文件组和一个日志文件.主数据文件在主文件组中,而用户定义文件组包含两个次要数据文件.ALTER DAT ...
- (转)如何压缩SQL Server 2005指定数据库文件和日志的大小?
下面有两个SQL语句可以达到在SQL Server 2005/2008压缩指定数据库文件和日志的大小的效果: 1.DBCC SHRINKDATABASE (Transact-SQL) 收缩指定数据库中 ...
最新文章
- shell的各种运行模式?
- SAP QM 采样方案的c1 d1 c2 d2 --多重采样
- 老旧的金融机构,是时候赶赶云计算的时髦了
- python对象编程例子-python编程进阶之类和对象用法实例分析
- rhce linux下如何配置lvs高可用集群
- php+nginx导入太大文件报http error错误的原因
- [0716] Jsoi B Isbn
- jquery 逗号分割截取字符串_JS/JQUERY字符串截取分割匹配等处理汇总
- 【SpringMVC】SpringMVC和Spring集成
- Linux 命名空间
- java某个参数值设置为空_@PathVariable为空时指定默认值的操作
- MATLAB常用三角函数
- jave double相加结果误差+尾巴
- c语言清屏函数怎么用_怎么用好 Golang 的 init 函数
- zmap扫描mysql_互联网扫描器 ZMap 完全手册
- 2021年茶艺师(初级)报名考试及茶艺师(初级)模拟考试题库
- C# WinForm GUI之控件
- 读心术:从零知识证明中提取「知识」——探索零知识证明系列(三)
- [AI开发]深度学习如何选择GPU?
- 搜索中常见数据结构与算法探究(二)