什么是SQL Server中的数据库规范化?
In addition to specifically addressing database normalization in SQL Server, this article will also address the following questions:
除了专门解决SQL Server中的数据库规范化问题之外,本文还将解决以下问题:
- Why is a database normalized? 为什么要将数据库标准化?
- What are the types of normalization? 规范化的类型有哪些?
- Why is database normalization important? 为什么数据库规范化很重要?
- What is database denormalization? 什么是数据库非规范化?
- Why would we denormalize a database? 为什么我们要对数据库进行非规范化?
So, let’s get started with normalization concepts…
因此,让我们开始归一化概念吧……
According to Wikipedia …
根据维基百科 …
“Database normalization is the process of restructuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd as an integral part of his relational model.
“数据库规范化是根据一系列所谓的规范形式重组关系数据库的过程,目的是减少数据冗余并提高数据完整性。 它最初是由Edgar F. Codd提出的,作为他的关系模型的组成部分。
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).”
规范化要求组织数据库的列(属性)和表(关系),以确保数据库完整性约束正确地执行了它们的依赖关系。 它是通过综合(创建新的数据库设计)或分解(改进现有的数据库设计)过程应用一些正式规则来实现的。”
数据库规范化 (Database normalization)
Database Normalization is a process and it should be carried out for every database you design. The process of taking a database design, and apply a set of formal criteria and rules, is called Normal Forms.
数据库规范化是一个过程,应针对您设计的每个数据库执行该过程。 进行数据库设计并应用一组正式标准和规则的过程称为“正常形式”。
The database normalization process is further categorized into the following types:
数据库规范化过程进一步分为以下几种类型:
- First Normal Form (1 NF) 第一范式(1 NF)
- Second Normal Form (2 NF) 第二范式(2 NF)
- Third Normal Form (3 NF) 第三范式(3 NF)
- Boyce Codd Normal Form or Fourth Normal Form ( BCNF or 4 NF) Boyce Codd范式或第四范式(BCNF或4 NF)
- Fifth Normal Form (5 NF) 第五范式(5 NF)
- Sixth Normal Form (6 NF) 第六范式(6 NF)
One of the driving forces behind database normalization is to streamline data by reducing redundant data. Redundancy of data means there are multiple copies of the same information spread over multiple locations in the same database.
数据库标准化背后的驱动力之一是通过减少冗余数据来简化数据。 数据冗余意味着同一信息的多个副本分布在同一数据库的多个位置。
The drawbacks of data redundancy include:
数据冗余的缺点包括:
- Data maintenance becomes tedious – data deletion and data updates become problematic 数据维护变得乏味–数据删除和数据更新成为问题
- It creates data inconsistencies 造成数据不一致
- Insert, Update and Delete anomalies become frequent. An update anomaly, for example, means that the versions of the same record, duplicated in different places in the database, will all need to be updated to keep the record consistent 插入,更新和删除异常变得很常见。 例如,更新异常意味着同一记录的版本(在数据库的不同位置重复)将全部需要更新以保持记录的一致性
- Redundant data inflates the size of a database and takes up an inordinate amount of space on disk 冗余数据扩大了数据库的大小,并占用了磁盘上过多的空间
正规表格 (Normal Forms)
This article is an effort to provide fundamental details of database normalization. The concept of normalization is a vast subject and the scope of this article is to provide enough information to be able to understand the first three forms of database normalization.
本文旨在提供数据库规范化的基本细节。 规范化的概念是一个广泛的主题,本文的范围是提供足够的信息以能够理解数据库规范化的前三种形式。
- First Normal Form (1 NF) 第一范式(1 NF)
- Second Normal Form (2 NF) 第二范式(2 NF)
- Third Normal Form (3 NF) 第三范式(3 NF)
A database is considered third normal form if it meets the requirements of the first 3 normal forms.
如果数据库符合前三个范式的要求,则将其视为第三范式。
第一范式(1NF): (First Normal Form (1NF):)
The first normal form requires that a table satisfies the following conditions:
第一种范式要求表满足以下条件:
- Rows are not ordered 行未排序
- Columns are not ordered 列未排序
- There is duplicated data 数据重复
- Row-and-column intersections always have a unique value 行列相交始终具有唯一值
- All columns are “regular” with no hidden values 所有列均为“常规”,无隐藏值
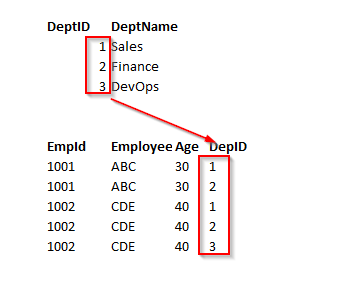
In the following example, the first table clearly violates the 1 NF. It contains more than one value for the Dept column. So, what we might do then is go back to the original way and instead start adding new columns, so, Dept1, Dept2, and so on. This is what’s called a repeating group, and there should be no repeating groups. In order to bring this First Normal Form, split the table into the two tables. Let’s take the department data out of the table and put it in the dept table. This has the one-to-many relationship to the employee table.
在下面的示例中,第一个表明显违反了1 NF。 它在“部门”列中包含多个值。 因此,我们可能要做的是回到原始方式,而是开始添加新列,例如Dept1,Dept2等。 这就是所谓的重复组,应该没有重复组。 为了带来此第一范式,将表拆分为两个表。 让我们从表中取出部门数据,并将其放入dept表中。 这与employee表具有一对多关系。
Let’s take a look at the employee table:
让我们看一下employee表:
Now, after normalization, the normalized tables Dept and Employee looks like below:
现在,在进行标准化之后,标准化表Dept和Employee如下所示:
Second Normal Form and Third Normal Form are all about the relationship between the columns that are the keys and the other columns that aren’t the key columns.
第二范式和第三范式都是关于作为关键字的列与不是关键字列的其他列之间的关系的。
第二范式(2NF): (Second Normal Form (2NF):)
An entity is in a second normal form if all of its attributes depend on the whole primary key. So this means that the values in the different columns have a dependency on the other columns.
如果实体的所有属性都依赖于整个主键,则它处于第二范式。 因此,这意味着不同列中的值对其他列具有依赖性。
- The table must be already in 1 NF and all non-key columns of the tables must depend on the PRIMARY KEY 该表必须已经在1 NF中,并且该表的所有非键列都必须取决于PRIMARY KEY
- The partial dependencies are removed and placed in a separate table 删除部分依赖项并将其放置在单独的表中
Note: Second Normal Form (2 NF) is only ever a problem when we’re using a composite primary key. That is, a primary key made of two or more columns.
注意:仅当我们使用复合主键时,第二范式(2 NF)才成为问题。 即,主键由两列或更多列组成。
The following example, the relationship is established between the Employee and Department tables.
在下面的示例中,在Employee表和Department表之间建立了关系。
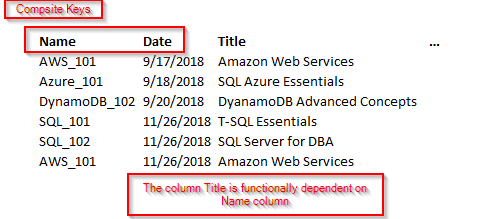
In this example, the Title column is functionally dependent on Name and Date columns. These two keys form a composite key. In this case, it only depends on Name and partially dependent on the Date column. Let’s remove the course details and form a separate table. Now, the course details are based on the entire key. We are not going to use a composite key.
在此示例中,“ 标题”列在功能上取决于“ 名称”和“日期”列。 这两个键构成一个复合键。 在这种情况下,它仅取决于“名称”,部分取决于“日期”列。 让我们删除课程详细信息并形成一个单独的表。 现在,课程详细信息基于整个关键。 我们将不使用复合键。
第三范式(3NF): (Third Normal Form (3NF):)
The third normal form states that you should eliminate fields in a table that do not depend on the key.
第三种普通形式指出,您应该消除表中不依赖键的字段。
- A Table is already in 2 NF 一个表已经在2 NF中
- Non-Primary key columns shouldn’t depend on the other non-Primary key columns 非主键列不应依赖于其他非主键列
- There is no transitive functional dependency 没有传递功能依赖
Consider the following example, in the table employee; empID determines the department ID of an employee, department ID determines the department name. Therefore, the department name column indirectly dependent on the empID column. So, it satisfies the transitive dependency. So this cannot be in third normal form.
考虑表employee中的以下示例; empID确定员工的部门ID,部门ID确定部门名称。 因此,部门名称列间接依赖于empID列。 因此,它满足传递依赖。 因此,这不能采用第三范式。
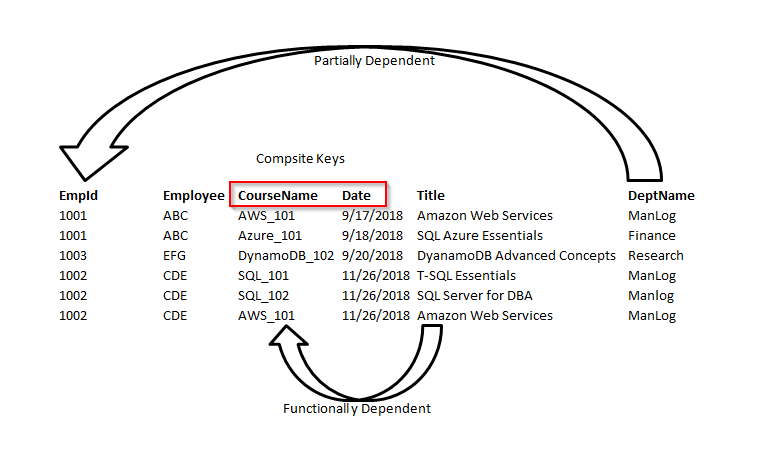
In order to bring the table to 3 NF, we split the employee table into two.
为了使表达到3 NF,我们将employee表拆分为两个。
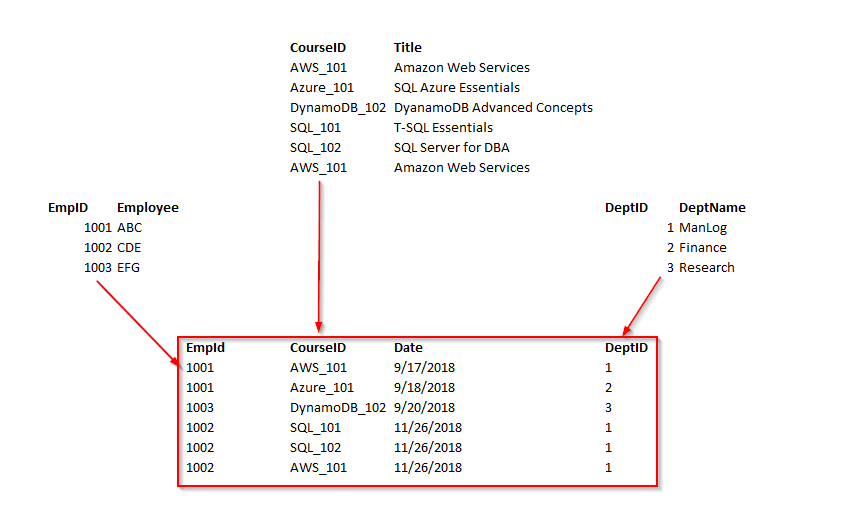
Now, we can see the all non-key columns are fully functionally dependent on the Primary key.
现在,我们可以看到所有非键列在功能上完全依赖于主键。
Although a fourth and fifth form does exist, most databases do not aspire to use those levels because they take extra work and they don’t truly impact the database functionality and improve performance.
尽管确实存在第四和第五种形式,但是大多数数据库并不希望使用这些级别,因为它们需要额外的工作,并且不会真正影响数据库功能并提高性能。
非规范化 (Denormalization)
According to Wikipedia…
根据维基百科 …
“Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data.[1][2] It is often motivated by performance or scalability in relational database software needing to carry out very large numbers of read operations. Denormalization should not be confused with Unnormalized form. Databases/tables must first be normalized to efficiently denormalize them.”
“非规格化是一种在以前规格化的数据库上用于提高性能的策略。 在计算中,非规范化是尝试通过添加冗余数据副本或对数据进行分组来提高数据库的读取性能,以牺牲一些写入性能为代价的过程。[1] [2] 它通常是由关系数据库软件的性能或可伸缩性驱动的,需要执行大量的读取操作。 非规范化不应与非规范化形式混淆。 首先必须对数据库/表进行规范化,以有效地对它们进行规范化。”
Database normalization is always a starting point for denormalization. Denormalization is a type of reverse engineering process that can apply to retrieve the data in the shortest time possible.
数据库规范化始终是非规范化的起点。 非规范化是一种逆向工程过程,可以应用于在尽可能短的时间内检索数据。
Let us consider an example; we’ve got an Employee table that in-house an email and a phone number columns. Well, what happens if we add another email address column, another phone number? We tend to break First Normal Form. It’s a repeating group. But in general, it is easy to have those columns created (Email_1, and Email_2 column), or having (home_phone and mobile_phone) columns, rather than having everything into multiple tables and having to follow relationships. The entire process is referred to as a denormalization.
让我们考虑一个例子。 我们有一个Employee表,内部有一封电子邮件和一个电话号码列。 好吧,如果我们添加另一个电子邮件地址列和另一个电话号码,会发生什么? 我们倾向于打破第一范式。 这是一个重复的小组。 但是总的来说,创建这些列(Email_1和Email_2列)或创建(home_phone和mobile_phone)列很容易,而不是将所有内容都放入多个表并遵循关系。 整个过程称为反规范化。
摘要 (Summary)
Thus far, we’ve discussed details of the Relational Database Management System (RDBMS) concepts such as Database Normalization (1NF, 2NF, and 3NF), and Database Denormalization
到目前为止,我们已经讨论了关系数据库管理系统(RDBMS)概念的详细信息,例如数据库规范化(1NF,2NF和3NF)和数据库非规范化
Again, the basic understandings of database normalization always help you to know the relational concepts, a need for multiple tables in the database design structures and how to query multiple tables in a relational world. It is a lot more common in data warehousing type of scenarios, where you’ll probably work on a process to de-normalize the data. Denormalized data is actually much more efficient to query than normalized data.
同样,对数据库规范化的基本理解总是可以帮助您了解关系概念,数据库设计结构中需要多个表以及如何在关系世界中查询多个表。 在数据仓库类型的场景中,这种情况更为常见,在这种情况下,您可能需要对流程进行非规范化处理。 实际上,非规范化数据比规范化数据更有效地进行查询。
Taking the database design through these three steps will vastly improve the quality of the data.
通过这三个步骤进行数据库设计将极大地提高数据质量。
翻译自: https://www.sqlshack.com/what-is-database-normalization-in-sql-server/
什么是SQL Server中的数据库规范化?相关推荐
- SQL Server中通用数据库角色权限的处理详解
SQL Server中通用数据库角色权限的处理详解 前言 安全性是所有数据库管理系统的一个重要特征.理解安全性问题是理解数据库管理系统安全性机制的前提. 最近和同事在做数据库权限清理的事情,主要是删除 ...
- sql server中创建数据库和表的语法
下面是sql server中创建数据库,创建数据表以及添加约束的sql语句: use master --创建数据库 if exists (select * from sysdatabases wher ...
- SQL Server中的数据库文件组和零碎还原
So far, we discussed many de-facto details about SQL Server database backup and restore. In this 15t ...
- 在SQL Server中的数据库之间复制表的六种不同方法
In this article, you'll learn the key skills that you need to copy tables between SQL Server instanc ...
- SQL Server 中创建数据库、更改主文件组示例
以下示例在 SQL Server 实例上创建了一个数据库.该数据库包括一个主数据文件.一个用户定义文件组和一个日志文件.主数据文件在主文件组中,而用户定义文件组包含两个次要数据文件.ALTER DAT ...
- SQL Server中的数据库表分区
什么是数据库表分区? (What is a database table partitioning?) Partitioning is the database process where very ...
- 数据库实验一 在SQL Server 中创建数据库
一.实验内容 1.创建数据库和查看数据库属性. 2.创建表.确定表的主码 3.查看和修改表结构. 4,具体内容 (1)使用SQL语句按教材中的内容建立学生数据库. (2)查看学生数据库的属性,并进行修 ...
- 用VB代码在SQL SERVER 中创建数据库,表,列.以及对数据库的操作
前面看了一编用VB代码创建ACCESS数据库的文章,写的很好. 根据思路,写下创建SQL 数据库的方法,供大家参考. 1:引用ADO2.5lib 2:在窗体上添加一个按钮COMMAND1 3:按钮代码 ...
- Sql Server中判断表或者数据库是否存在
SQL Server中判断数据库是否存在: 法(一): select * From master.dbo.sysdatabases where name='数据库名' 法(二): if db_id(' ...
最新文章
- C# using 语法说明
- 【 MATLAB 】序列的奇偶分解的 MATLAB 函数编写实践
- 【 Verilog HDL 】不同抽象级别的Verilog HDL模型之门级结构描述
- gcc 常用命令(逐渐完善)
- LeetCode:2. Add Two Numbers
- 各品牌交换机常用命令整理
- fastjson解析多层数据_JSON数据如何进行解析呢,方式有哪些?
- 教育机构如何提升在线教育技术能力? | 云+社区技术沙龙
- 论文浅尝 - ICML2020 | 对比图神经网络解释器
- python实现科赫雪花的绘制(最简单)
- 前端网页打印window.print()
- disparity和parallax的区别
- 用例图中的包含关系(include)与拓展关系(extend)的区别
- 钉钉作弊软件开发者,被判 5 年半,为什么提供「虚拟定位」会被判这么久?...
- Python 绘制数据图表
- OCR图文识别软件是怎么保存页面图像的
- php 查看文件锁定状态_Photoshop脚本 查看当前图层的锁定状态
- office2019安装在非系统盘
- 软件开发团队如何有效地沟通与协作?
- 计算机教室英语名言,计算机专业英语的一些名言警句