没有你看不懂的Kmeans聚类算法
1 引例
经过前面一些列的介绍,我们已经接触到了多种回归和分类算法。并且这些算法有一个共同的特点,那就是它们都是有监督的(supervised)学习任务。接下来,笔者就开始向大家介绍一种无监督的(unsupervised) 经典机器学习算法——聚类。同时,由于笔者仅仅只是对Kmeans框架下的聚类算法较为熟悉,因此在后续的几篇文章中笔者将只会介绍Kmeans框架下的聚类算法,包括:Kmeans、Kmeans++和WKmeans。
在正式介绍聚类之前我们先从感性上认识一下什么是聚类。聚类的核心思想就是将具有相似特征的事物给“聚”在一起,也就是说“聚”是一个动词。俗话说人以群分,物以类聚说得就是这个道理。
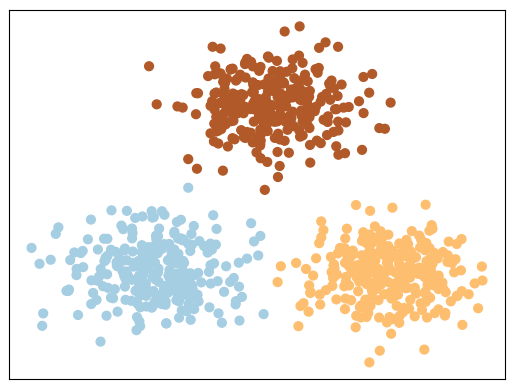
如图所示为三种类型的数据样本,其中每种颜色都表示一个类别。而聚类算法的目的就是就是将各个类别的样本点分开,也就是将同一种类别的样本点聚在一起。 此时可能有人会问:这不是和分类模型一样吗?刚刚接触聚类的同学难免都会面临这么一个疑问,即聚类和分类的区别在哪儿。一句话,分类能干的事儿,聚类也能干;而聚类能干的事,分类却干不了。什么意思呢?聚类的核心思想是将具有相似特征的事物给聚在一起,也就是说聚类算法最终只能告诉我们哪些样本属于同一个类别,而不能告诉我们每个样本具体属于什么类别。因此,聚类算法在训练过程中并不需要每个样本所对应的真实标签,而分类算法却不行。
假如我们有100个样本的病例数据(包含正样本和负样本),并且通过聚类算法后我们可以将原始数据划分成两个堆,其中一个堆里面有40个样本且均为一个类别,而剩下的一个堆里面有60个样本且也为同一个类别。但具体这两个堆哪一个代表正样例,哪一个代表负样例,这是聚类算法无法告诉我们的。同时,在聚类算法中这个堆就被称之为聚类后所得到的簇(cluster)。
到此,我相信大家已经明白了聚类算法的核心思想,那聚类算法是如何完成这么一个过程的呢?
2 Kmeans聚类
在上面我们说到聚类的思想是将具有同种特征的样本聚在一起,换句话说同一个簇中的样本之间都具有一定程度的相似性,而不同簇中的样本点具有较低的相似性。因此,对于聚类算法的本质又可以看成是不同样本间相似性的一个比较,聚类的目的就是将相似度较高的样本点放到一个簇中。
由于不同类型的聚类算法有着不同的聚类原理,以及相似性评判标准。下面我们就开始介绍聚类算法中最常用的KmeansKmeansKmeans聚类算法。
2.1 Kmeans算法原理
KmeansKmeansKmeans聚类算法也被称为KKK均值聚类,其主要原理为:
①首先随机选择KKK个样本点作为KKK个簇的初始簇中心;
②然后计算每个样本点与这个KKK个簇中心的相似度大小,并将该样本点划分到与之相似度最大的簇中心所对应的簇中;
③根据现有的簇中样本,重新计算每个簇的簇中心;
④循环迭代步骤②③,直到目标函数收敛,即簇中心不再发生变化。
![]()
如图所示为一个聚类过程中的示例,左上角为正确标签下的样本可视化结果(每种颜色表示一个类别),其中三个黑色圆点为随机初始化的三个簇中心;当iter=1时表算法第一次迭代后的结果,可以看到此时的算法将左边的两个簇都划分到了一个簇中,而右下角的一个簇被分成了两个簇;然后依次进行反复迭代,当第四次迭代完成后,可以发现三个簇中心基本上已经位于三个簇中了,被错分的样本也在逐渐减少;当进行完第五次迭代后,可以发现基本上已经完成了对整个样本的聚类处理,只需要再迭代几次即可收敛。
以上就是KmeansKmeansKmeans聚类算法在整个聚类过程中的变化情况,至于其具体的求解计算过程我们放到第二个阶段再进行介绍。
2.2 kkk值选取
经过上面的介绍,我们已经知道了KmeansKmeansKmeans聚类算法的基本原理。但现在有个问题就是,我们怎么来确定聚类的kkk值呢?也就是说我们需要将数据集聚成多少个簇?如果已经很明确数据集中存在多少个簇,那么就直接指定kkk值即可;如果并不知道数据集中有多少个簇,则需要结合另外一些办法来进行选取,例如看轮廓系数、结果的稳定性等等。下面,我们通过sklearn来完成对KmeansKmeansKmeans聚类算法的建模任务。
2.3 Sklearn建模
在sklearn中,我们可以通过语句from sklearn.cluster import KMeans来完成对KmeansKmeansKmeans模型的导入。然后我们仍旧可以通过前面介绍三步走策略完成整个聚类任务。
def train(x, y, K):model = KMeans(n_clusters=K)model.fit(x)y_pred = model.predict(x)nmi = normalized_mutual_info_score(y, y_pred)print("NMI: ", nmi)if __name__ == '__main__':x, y = load_data()train(x, y, K=3)# 结果:
NMI: 0.7581756800057784
以上便是用sklearn搭建一个聚类模型的全部代码,可以看到其实非常简单。其中NMI为一种聚类结果评估指标,其范围为0到1,越大表示结果越好。具体的评估指标我们会在后面的文章中进行介绍。
3 Kmeans求解
现在,我们已经对KmeansKmeansKmeans聚类算法的过程有了一个大致的了解,但是我们应该如何从数学的角度来对其进行描述呢?正如我们在介绍线性回归时一样,我们应该如何找到一个目标函数来对聚类结果的好坏进行刻画呢?
在上面我们说到,聚类的本质可以看成是不同样本间相似度比较的一个过程,把相似度较高的样本放到一个簇,而把相似度较低的样本点放到不同的簇中。那既然如此,我们应该怎么来衡量样本间的相似度呢?一种最常见的做法当然是计算两个样本间的欧式距离,当两个样本点离得越近就代表着两者间的相似度越高,并且这也是KmeansKmeansKmeans聚类算法中的衡量标准。
因此,根据这样的准则,我们就可以将KmeansKmeansKmeans聚类算法的目标函数定义为所有样本点到其对应簇中心距离的总和来刻画聚类结果的好坏程度。
3.1 Kmeans目标函数
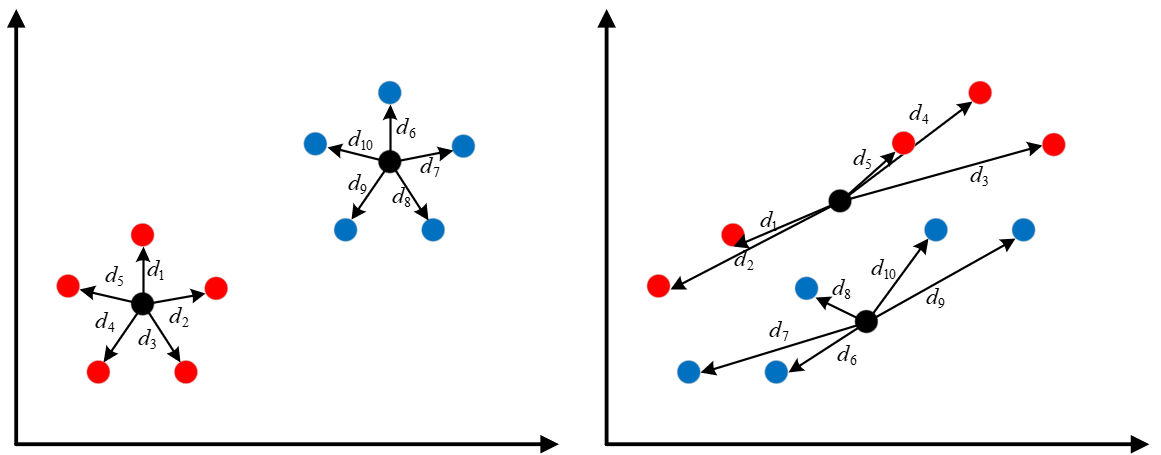
如图左右所示为同一数据集的两种不同聚类结果,其中同种颜色表示聚类后被划分到了同一个簇中,黑色圆点为聚类后的簇中心。从可视化结果来看,左图的聚类结果跟定好于右图的聚类结果。也就是说,我们可以通过最小化目标函数d=d1+d2,+⋯,+d10d=d_1+d_2,+\cdots,+d_{10}d=d1+d2,+⋯,+d10来得到最优解。
设X={X1,X2,.⋯,Xn}X=\{X_1,X_2,.\cdots,X_n\}X={X1,X2,.⋯,Xn}为一个含有nnn个样本的数据集,其中第iii个数据对象表示为Xi={xi1,xi2,⋯,xim}X_i=\{x_{i1},x_{i2},\cdots,x_{im}\}Xi={xi1,xi2,⋯,xim},mmm为数据对象特征的数目。数据对象分配矩阵UUU是一个n×kn\times kn×k的0-1矩阵(里面只有0和1),uipu_{ip}uip表示第iii个样本被分到第ppp个簇中。Z=Z1,Z2,⋯,ZkZ={Z_1,Z_2,\cdots,Z_k}Z=Z1,Z2,⋯,Zk为kkk个簇中心向量,其中Zp={zp1,zp2,⋯,zpm}Z_p=\{z_{p1},z_{p2},\cdots,z_{pm}\}Zp={zp1,zp2,⋯,zpm}为第ppp个簇中心。则KmeansKmeansKmeans聚类算法的目标函数可以写为:
P(U,Z)=∑p=1k∑i=1nuip∑j=1m(xij−zpj)2(1)P(U,Z)=\sum_{p=1}^k\sum_{i=1}^nu_{ip}\sum_{j=1}^m(x_{ij}-z_{pj})^2\tag{1} P(U,Z)=p=1∑ki=1∑nuipj=1∑m(xij−zpj)2(1)
并且服从于约束条件:
∑p=1kuip=1(2)\sum_{p=1}^ku_{ip}=1\tag{2} p=1∑kuip=1(2)
式子(1)(1)(1)看起来稍微有点复杂,但是其表示的意思就是累加各个样本点到其对应簇中心的距离和。由于一个数据集有多个簇,每个簇中有多个样本,每个样本又有多个维度,因此式子(1)(1)(1)中就存在了三个求和符号。其次,以上图为例再来简单说一下分配矩阵UUU。由上图(左)可知,数据集中一共有两个簇,且假设前5个样本为一个簇,后5个样本为一个簇,则分配矩阵为:
U[10,2]=[10101010100101010101]U_{[10,2]}=\begin{bmatrix} 1 & 0 \\1 & 0 \\1 & 0 \\1 & 0 \\1 & 0 \\0 & 1 \\0 & 1 \\0 & 1 \\0 & 1 \\0 & 1 \\ \end{bmatrix} U[10,2]=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡11111000000000011111⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
3.2 最小化目标函数
到目前为止,我们就得到了KmeansKmeansKmeans聚类算法的目标函数,接下来只需要对其进行最小化就能得到对应未知变量U,ZU,ZU,Z的更新公式。由于文章篇幅有限,具体的求解过程和编码实现将放在下一篇文章中进行介绍。
4 总结
在这篇文章中,笔者首先介绍了聚类算法的基本思想;然后以KmeansKmeansKmeans聚类算法为例,介绍了其聚类过程并进行了可视化;接着介绍了如何通过sklearn来完成对于KmeansKmeansKmeans聚类模型的搭建;最后介绍了KmeansKmeansKmeans聚类算法的目标函数。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1] 示例代码 : https://github.com/moon-hotel/MachineLearningWithMe
近期文章
[1]原来这就是支持向量机
[2]这就是决策树的思想
[3]朴素贝叶斯算法
[4]K最近邻算法

没有你看不懂的Kmeans聚类算法相关推荐
- Matlab实现K-Means聚类算法
原文地址为: Matlab实现K-Means聚类算法 人生如戏!!!! 一.理论准备 聚类算法,不是分类算法.分类算法是给一个数据,然后判断这个数据属于已分好的类中的具体哪一类.聚类算法是给一大堆原始 ...
- K-means聚类算法介绍
上次给大家介绍了分类和聚类的区别和聚类的进一步介绍,大家看懂了吗?今天给想给大家进一步地介绍K-means聚类算法. 下面的段落内容从3开始算起,1的内容来自分类和聚类的区别,2的内容来自聚类的进一步 ...
- K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比
原文:http://www.cnblogs.com/yixuan-xu/p/6272208.html K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means ...
- K-Means聚类算法进行压缩图片
K-Means聚类算法(二):算法实现及其优化 清雨影 2 年前 (最近在车间干活的时候把手砸伤了,所以打字还是有点不便,大家原谅我更新的慢,加上赞比较少,心情比较低落TAT) 首先介绍一下题图,这个 ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- 【白话机器学习】算法理论+实战之K-Means聚类算法
1. 写在前面 如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,常见的机器学习算法: 监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Ad ...
- 光谱分类算法 matlab,Matlab K-means聚类算法对多光谱遥感图像进行分类(一)
Matlab K-means聚类算法对多光谱遥感图像进行分类 作者: 白艺亭 测试了下matlab自带kmeans函数,作者编写函数,以及ENVI下的Kmeans方法,对比其效果,代码及结果图展示见下 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法 (白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类 ...
- kmeans算法_实战 | KMeans 聚类算法
1. 写在前面 如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,常见的机器学习算法: 监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Ad ...
最新文章
- 深入解读EOS源代码之——区块链内核
- GDCM:gdcm::StreamImageReader的测试程序
- 分治法:关于选择算法,找最大,找最小,同时找最大和最小,找第二大
- JavaScript event loop事件循环 macrotask与microtask
- Strut2的属性驱动,模型驱动的理解
- yum 出错,提示Segmentation Fault (core Dumped) 的解决办法
- ios raise_如何在iOS 10中关闭“ Raise to Wake”
- 自定义jQuery插件
- MyBatis中![CDATA[ ]]的使用
- 我的成长笔记20210325(一天写了247条用例)
- sqlite3 小记
- oracle数据库sqlloader,初见Oracle SqlLoader工具
- Zint生成多种条码及二维码
- ABC类IP地址划分_wuli大世界_新浪博客
- 渗透测试_缓冲区溢出
- 文本转思维导图(xmind)
- 【小米手环7】使用 Zeus + 表盘自定义工具 为小米手环7开发和安装小程序
- Appium报错Original error: Could not proxy command to the remote server. Original error: socket hang up
- Linux创建用户和删除用户
- 动态路由-----OSPF协议原理与单区域实验配置