万亿级调用下的优雅——微信序列号生成器架构设计及演变(上)
版权声明:本文由曾钦松原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/200
来源:腾云阁 https://www.qcloud.com/community
微信在立项之初,就已确立了利用数据版本号实现终端与后台的数据增量同步机制,确保发消息时消息可靠送达对方手机,避免了大量潜在的家庭纠纷。时至今日,微信已经走过第五个年头,这套同步机制仍然在消息收发、朋友圈通知、好友数据更新等需要数据同步的地方发挥着核心的作用。
而在这同步机制的背后,需要一个高可用、高可靠的序列号生成器来产生同步数据用的版本号。这个序列号生成器我们称之为seqsvr,目前已经发展为一个每天万亿级调用的重量级系统,其中每次申请序列号平时调用耗时1ms,99.9%的调用耗时小于3ms,服务部署于数百台4核CPU服务器上。本文会重点介绍seqsvr的架构核心思想,以及seqsvr随着业务量快速上涨所做的架构演变。
背景
微信服务器端为每一份需要与客户端同步的数据(例如消息)都会赋予一个唯一的、递增的序列号(后文称为sequence),作为这份数据的版本号。在客户端与服务器端同步的时候,客户端会带上已经同步下去数据的最大版本号,后台会根据客户端最大版本号与服务器端的最大版本号,计算出需要同步的增量数据,返回给客户端。这样不仅保证了客户端与服务器端的数据同步的可靠性,同时也大幅减少了同步时的冗余数据。
这里不用乐观锁机制来生成版本号,而是使用了一个独立的seqsvr来处理序列号操作,一方面因为业务有大量的sequence查询需求——查询已经分配出去的最后一个sequence,而基于seqsvr的查询操作可以做到非常轻量级,避免对存储层的大量IO查询操作;另一方面微信用户的不同种类的数据存在不同的Key-Value系统中,使用统一的序列号有助于避免重复开发,同时业务逻辑可以很方便地判断一个用户的各类数据是否有更新。
从seqsvr申请的、用作数据版本号的sequence,具有两种基本的性质:
递增的64位整型变量
每个用户都有自己独立的64位sequence空间
举个例子,小明当前申请的sequence为100,那么他下一次申请的sequence,可能为101,也可能是110,总之一定大于之前申请的100。而小红呢,她的sequence与小明的sequence是独立开的,假如她当前申请到的sequence为50,然后期间不管小明申请多少次sequence怎么折腾,都不会影响到她下一次申请到的值(很可能是51)。
这里用了每个用户独立的64位sequence的体系,而不是用一个全局的64位(或更高位)sequence,很大原因是全局唯一的sequence会有非常严重的申请互斥问题,不容易去实现一个高性能高可靠的架构。对微信业务来说,每个用户独立的64位sequence空间已经满足业务要求。
目前sequence用在终端与后台的数据同步外,同时也广泛用于微信后台逻辑层的基础数据一致性cache中,大幅减少逻辑层对存储层的访问。虽然一个用于终端——后台数据同步,一个用于后台cache的一致性保证,场景大不相同。
但我们仔细分析就会发现,两个场景都是利用sequence可靠递增的性质来实现数据的一致性保证,这就要求我们的seqsvr保证分配出去的sequence是稳定递增的,一旦出现回退必然导致各种数据错乱、消息消失;另外,这两个场景都非常普遍,我们在使用微信的时候会不知不觉地对应到这两个场景:小明给小红发消息、小红拉黑小明、小明发一条失恋状态的朋友圈,一次简单的分手背后可能申请了无数次sequence。
微信目前拥有数亿的活跃用户,每时每刻都会有海量sequence申请,这对seqsvr的设计也是个极大的挑战。那么,既要sequence可靠递增,又要能顶住海量的访问,要如何设计seqsvr的架构?我们先从seqsvr的架构原型说起。
架构原型
不考虑seqsvr的具体架构的话,它应该是一个巨大的64位数组,而我们每一个微信用户,都在这个大数组里独占一格8bytes的空间,这个格子就放着用户已经分配出去的最后一个sequence:cur_seq。每个用户来申请sequence的时候,只需要将用户的cur_seq+=1,保存回数组,并返回给用户。

图1. 小明申请了一个sequence,返回101
预分配中间层
任何一件看起来很简单的事,在海量的访问量下都会变得不简单。前文提到,seqsvr需要保证分配出去的sequence递增(数据可靠),还需要满足海量的访问量(每天接近万亿级别的访问)。满足数据可靠的话,我们很容易想到把数据持久化到硬盘,但是按照目前每秒千万级的访问量(~10^7 QPS),基本没有任何硬盘系统能扛住。
后台架构设计很多时候是一门关于权衡的哲学,针对不同的场景去考虑能不能降低某方面的要求,以换取其它方面的提升。仔细考虑我们的需求,我们只要求递增,并没有要求连续,也就是说出现一大段跳跃是允许的(例如分配出的sequence序列:1,2,3,10,100,101)。于是我们实现了一个简单优雅的策略:
内存中储存最近一个分配出去的sequence:cur_seq,以及分配上限:max_seq
分配sequence时,将cur_seq++,同时与分配上限max_seq比较:如果cur_seq > max_seq,将分配上限提升一个步长max_seq += step,并持久化max_seq
重启时,读出持久化的max_seq,赋值给cur_seq
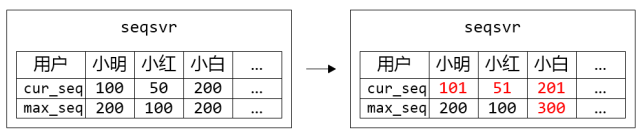
图2. 小明、小红、小白都各自申请了一个sequence,但只有小白的max_seq增加了步长100
这样通过增加一个预分配sequence的中间层,在保证sequence不回退的前提下,大幅地提升了分配sequence的性能。实际应用中每次提升的步长为10000,那么持久化的硬盘IO次数从之前~10^7 QPS降低到~10^3 QPS,处于可接受范围。在正常运作时分配出去的sequence是顺序递增的,只有在机器重启后,第一次分配的sequence会产生一个比较大的跳跃,跳跃大小取决于步长大小。
分号段共享存储
请求带来的硬盘IO问题解决了,可以支持服务平稳运行,但该模型还是存在一个问题:重启时要读取大量的max_seq数据加载到内存中。
我们可以简单计算下,以目前uid(用户唯一ID)上限2^32个、一个max_seq 8bytes的空间,数据大小一共为32GB,从硬盘加载需要不少时间。另一方面,出于数据可靠性的考虑,必然需要一个可靠存储系统来保存max_seq数据,重启时通过网络从该可靠存储系统加载数据。如果max_seq数据过大的话,会导致重启时在数据传输花费大量时间,造成一段时间不可服务。
为了解决这个问题,我们引入号段Section的概念,uid相邻的一段用户属于一个号段,而同个号段内的用户共享一个max_seq,这样大幅减少了max_seq数据的大小,同时也降低了IO次数。
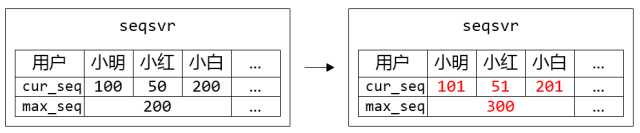
图3. 小明、小红、小白属于同个Section,他们共用一个max_seq。在每个人都申请一个sequence的时候,只有小白突破了max_seq上限,需要更新max_seq并持久化
目前seqsvr一个Section包含10万个uid,max_seq数据只有300+KB,为我们实现从可靠存储系统读取max_seq数据重启打下基础。
工程实现
工程实现在上面两个策略上做了一些调整,主要是出于数据可靠性及灾难隔离考虑
把存储层和缓存中间层分成两个模块StoreSvr及AllocSvr。StoreSvr为存储层,利用了多机NRW策略来保证数据持久化后不丢失;AllocSvr则是缓存中间层,部署于多台机器,每台AllocSvr负责若干号段的sequence分配,分摊海量的sequence申请请求。
整个系统又按uid范围进行分Set,每个Set都是一个完整的、独立的StoreSvr+AllocSvr子系统。分Set设计目的是为了做灾难隔离,一个Set出现故障只会影响该Set内的用户,而不会影响到其它用户。

图4. 原型架构图
小结
写到这里把seqsvr基本原型讲完了,正是如此简单优雅的模型,可靠、稳定地支撑着微信五年来的高速发展。五年里访问量一倍又一倍地上涨,seqsvr本身也做过大大小小的重构,但seqsvr的分层架构一直没有改变过,并且在可预见的未来里也会一直保持不变。
原型跟生产环境的版本存在一定差距,最主要的差距在于容灾上。像微信的IM类应用,对系统可用性非常敏感,而seqsvr又处于收发消息、朋友圈等功能的关键路径上,对可用性要求非常高,出现长时间不可服务是分分钟写故障报告的节奏。下一篇文章会讲讲seqsvr的容灾方案演变。
万亿级调用下的优雅——微信序列号生成器架构设计及演变(上)相关推荐
- 万亿级调用系统:微信序列号生成器架构设计及演变
"每天万亿级调用的重量级系统,每次申请序列号平时调用耗时1ms,99.9%的调用耗时小于3ms,服务部署于数百台4核CPU服务器上!" 老司机介绍: 曾钦松,微信高级工程师,目前负 ...
- 微信序列号生成器架构设计及演变
一.摘要 微信在立项之初,就已确立了利用数据版本号实现终端与后台的数据增量同步机制,确保发消息时消息可靠送达对方手机,避免了大量潜在的家庭纠纷.时至今日,微信已经走过第五个年头,这套同步机制仍然在消息 ...
- 【技术干货】40页PPT分享万亿级交易量下的支付平台设计
本文主要是根据作者在2018QCon演讲内容整理而成: 苏宁金融交易量3年内从1000亿增长到万亿+,服务用户3亿+,服务场景从服务于苏宁易购内部生态,扩展到服务全渠道,全场景,多业态的线上线下智慧零 ...
- 千亿级数量下日志分析系统的技术架构选型
 随着数据已经逐步成为一个公司宝贵的财富,大数据团队在公司往往会承担更加重要的角色.大数据团队往往要承担数据平台维护.数据产品开发.从数据产品中挖掘业务价值等重要的职责.所以对于很多大数据工程师 ...
- 2021北京智源大会圆满闭幕,现场8千人,参会7万人,发布「悟道2.0」全球最大万亿级模型...
句点,是下一行诗篇的开始. 6月3日晚上10点整,2021北京智源大会正式闭幕,为北京乃至中国人工智能发展画上浓重一点. 定位于"内行的AI盛会",北京智源大会以国际性.权威性.专 ...
- 个推CTO叶新江谈数据智能:基于万亿级图助力大数据精准防疫和健康码赋码引擎开发
近日,每日互动(个推)CTO叶新江受邀出席WAIC世界人工智能大会,并于"大数据关联下的图数据库技术与应用"主题论坛上发表演讲,同与会专家.观众共同探讨"万亿级图下的 ...
- 万亿级日访问量下,Redis在微博的9年优化历程
来自:DBAplus社群 讲师介绍 兰将州,新浪微博核心feed流.广告数据库业务线负责人,主要负责MySQL.NoSQL.TiDB相关的自动化开发和运维,参与Redis.counteservice_ ...
- 第四十五期:万亿级日访问量下,Redis在微博的9年优化历程
Redis在微博内部分布在各个应用场景,比如像现在春晚必争的"红包飞"活动,还有像粉丝数.用户数.阅读数.转评赞.评论盖楼.广告推荐.负反馈.音乐榜单等等都有用到Redis. 作者 ...
- 区块链游戏是一个万亿级市场,真正爆发还需7年| 专访陈昊芝(下)
今天我们面临的问题,不是什么游戏适合用区块链改造的问题,而是什么游戏在目前阶段场景比较合适的问题.理论上所有的游戏都可以应用区块链技术去改造,或者说重新设计.其中有丰富道具玩法的游戏可能更适合这样操作 ...
最新文章
- 寻找数组中第二大或第二小的数值
- 爬虫 python 爬取php的网页,带有post参数的网页如何爬取
- 【总结】那些只要发送口令就能获取的有三AI大包视频和图文资料,你都存下来了吗...
- ORA-04091: table is mutating, trigger/function may not see it
- LeetCode 110平衡二叉树-简单
- LeetCode 276. 栅栏涂色(DP)
- java c 基本类型_java 基本数据类型
- vue 转换信息为二进制 并实现下载
- Factory Pattern工厂模式
- react网页适配不同分辨率_PC端页面适应不同的分辨率的方法 (转载)
- 数据整理—dplyr包(filter系列)
- forms Build中的触发器
- 台式计算机m9870t,新闻中心 ——驱动之家:您身边的电脑专家
- [渝粤教育] 西南科技大学 高等数学2 在线考试复习资料
- bzoj4568-幸运数字
- 三栏式布局详解(代码+图解)
- 英雄无敌6服务器在哪个文件夹,英雄无敌6无法进入游戏解决方法_单机攻略_快吧单机游戏...
- Add-Migration
- [codeforces 1359A] Berland Poker 抽屉原理
- spire.doc操作word文档工具类(自用)