PINQ-验证数据集-多面搜索
In part 1, we briefly covered the installation and basic syntax of PINQ, a PHP LINQ port. In this article, we will see how to use PINQ to mimic a faceted search feature with MySQL.
在第1部分中 ,我们简要介绍了PINQ(PHP LINQ端口)的安装和基本语法。 在本文中,我们将看到如何使用PINQ模仿MySQL的多面搜索功能。
We are not going to cover the full aspect of faceted search in this series. Interested parties can refer to relevant articles published on Sitepoint and other Internet publications.
在本系列中,我们将不讨论分面搜索的所有方面。 有兴趣的人士可以参考在Sitepoint和其他Internet出版物上发表的相关文章。
A typical faceted search works like this in a website:
一个典型的多面搜索在网站中的工作方式如下:
- A user provides a keyword or a few keywords to search for. For example, “router” to search for products which contain “router” in the description, keyword, category, tags, etc. 用户提供一个关键词或几个关键词进行搜索。 例如,使用“路由器”搜索描述,关键字,类别,标签等中包含“路由器”的产品。
- The site will return the products matching the criteria.该站点将退回符合条件的产品。
- The site will provide some links to fine tune the search. For example, it may prompt that there are different brands for a router, and there may be different price ranges and different features. 该站点将提供一些链接以微调搜索。 例如,它可能提示路由器的品牌不同,价格范围和功能也可能不同。
- The user can further screen the results by clicking the different links provided and eventually gets a more customized result set. 用户可以通过单击提供的不同链接来进一步筛选结果,并最终获得更自定义的结果集。
Faceted search is so popular and powerful and you can experience it in almost every e-Commerce site.
分面搜索是如此流行且强大,您几乎可以在每个电子商务站点中都可以体验到它。
Unfortunately, faceted search is not a built-in feature provided by MySQL yet. What can we do if we are using MySQL but also want to provide our users with such a feature?
不幸的是,多面搜索还不是MySQL提供的内置功能。 如果我们使用MySQL但又想为用户提供这样的功能,该怎么办?
With PINQ, we’ll see there is an equally powerful and straightforward approach to achieving this as when we are using other DB engines – at least in a way.
使用PINQ,我们将看到有一种与使用其他数据库引擎时同样有效且直接的方法–至少以某种方式。
扩展第1部分演示 (Extending Part 1 Demo)
NOTE: All code in this part and the part 1 demo can be found in the repo.
注意:这部分和第1部分演示中的所有代码都可以在repo中找到。
In this article, we will extend the demo we have shown in Part 1 and add in some essential faceted search features.
在本文中,我们将扩展第1部分中显示的演示,并添加一些必不可少的多面搜索功能。
Let’s start with index.php by adding the following few lines:
让我们从index.php开始,添加以下几行:
$app->get('demo2', function () use ($app)
{
global $demo;
$test2 = new pinqDemo\Demo($app);
return $test2->test2($app, $demo->test1($app));
}
);
$app->get('demo2/facet/{key}/{value}', function ($key, $value) use ($app)
{
global $demo;
$test3 = new pinqDemo\Demo($app);
return $test3->test3($app, $demo->test1($app), $key, $value);
}
);We just created two more routes in our demo application (using Silex).
我们刚刚在演示应用程序中(使用Silex)创建了另外两条路线。
The first route is to bring us to the page showing all the records that match our first search behavior, i.e., search by providing a keyword. To keep the demo simple, we select all books from the sample book_book table. It will also display the result set and faceted links for further navigation.
第一种方法是将我们带到显示与我们的第一个搜索行为相匹配的所有记录的页面,即,通过提供关键字进行搜索。 为了使演示简单,我们从示例book_book表中选择所有书籍。 它还将显示结果集和多面链接,以进行进一步导航。
The second route brings us to another page showing the records matching further facet search criteria in the result set produced in the above step. It will display the faceted search links too.
第二条路线将我们带到另一个页面,该页面显示与在上述步骤中生成的结果集中的其他方面搜索条件匹配的记录。 它还将显示多面搜索链接。
In a real world implementation, after a faceted link is clicked, any faceted filtering in the result page will be adjusted to reflect the statistical information of the result data set. By doing this, the user can apply “add-on” screenings, adding “brand” first then “price range”, etc.
在实际的实现中,单击多面链接后,将调整结果页面中的任何多面过滤,以反映结果数据集的统计信息。 通过这样做,用户可以应用“附加”屏幕,先添加“品牌”,然后添加“价格范围”,等等。
But in this simple demo, we will skip this approach, all faceted search and the links will only reflect the information on the original data set. This is the first restriction and the first area for improvement in our demo.
但是在这个简单的演示中,我们将跳过这种方法,所有分面的搜索和链接将只反映原始数据集上的信息。 这是我们演示中的第一个限制和第一个需要改进的地方。
As we see from the code above, the real functions reside in another file called pinqDemo.php. Let’s see the relevant code that provides the faceted search feature.
从上面的代码中可以看到,实际函数位于另一个名为pinqDemo.php文件中。 让我们看一下提供多面搜索功能的相关代码。
方面类 (A facet class)
First, we create a class to represent a facet. Generally, a facet should have a few properties:
首先,我们创建一个代表构面的类。 通常,构面应具有一些属性:
The data it operates on (
$data)它操作的数据(
$data)The key it groups on (
$key)分组的键(
$key)The key type (
$type). It can be one of the below:密钥类型(
$type)。 可以是以下之一:- specify a full string to make an exact match指定完整的字符串以进行完全匹配
- specify partial (normally beginning) of a string to make a pattern match指定字符串的部分(通常是开头)以进行模式匹配
- specify a value range to group by a value range指定一个值范围以按值范围分组
The key type (
$type). It can be one of the below:密钥类型(
$type)。 可以是以下之一:If the key type is a range, there is a need to specify a value step to determine the upper/lower bound of the range; or if the key type is a partial string, we need to provide a number to specify how many first letters shall be used to group (
$range)如果键类型是一个范围,则需要指定一个值步来确定范围的上限/下限; 或如果键类型是部分字符串,我们需要提供一个数字来指定应使用多少个首字母进行分组(
$range)
The grouping is the most critical part in a facet. All the aggregating information that a facet could possibly return depends on the “grouping” criteria. Normally, “Full String”, “Partial String” and “Value Range” are the most commonly used ones.
分组是构面中最关键的部分。 构面可能返回的所有汇总信息取决于“分组”标准。 通常,“全字符串”,“部分字符串”和“值范围”是最常用的。
namespace classFacet
{
use Pinq\ITraversable,
Pinq\Traversable;
class Facet
{
public $data; // Original data
public $key; // the field to be grouped on
public $type; // F: full string; S: start of a string; R: range;
public $range; // Only valid if $type is not F
...
public function getFacet()
{
$filter = '';
if ($this->type == 'F') // Full string
{
...
}
elseif ($this->type == "S") //Start of string
{
...
}
elseif ($this->type == "R") // A value range
{
$filter = $this->data
->groupBy(function($row)
{
return floor($row[$this->key] / $this->range) * $this->range;
})
->select(function (ITraversable $data)
{
return ['key' => $data->last()[$this->key], 'count' => $data->count()];
});
}
return $filter;
}
}
}In this class, the key function is to return the faceted result set based on the data and the facet key properties. We noticed that for different types of keys, there are different ways to group the data. In the above, we have shown what the code will look like if we are grouping the data by a value range in a step specified by $range.
在此类中,键函数是根据数据和构面键属性返回构面结果集。 我们注意到,对于不同类型的键,有不同的方式对数据进行分组。 在上面的示例中,我们显示了如果在$range指定的步骤中按值范围对数据进行分组,代码将是什么样。
构面并显示原始数据 (Making facets and displaying the original data)
public function test2($app, $data)
{
$facet = $this->getFacet($data);
return $app['twig']->render('demo2.html.twig', array('facet' => $facet, 'data' => $data));
}
private function getFacet($originalData)
{
$facet = array();
$data = \Pinq\Traversable::from($originalData);
// 3 samples on constructing different Facet objects and return the facet
$filter1 = new \classFacet\Facet($data, 'author', 'F');
$filter2 = new \classFacet\Facet($data, 'title', 'S', 6);
$filter3 = new \classFacet\Facet($data, 'price', 'R', 10);
$facet[$filter1->key] = $filter1->getFacet();
$facet[$filter2->key] = $filter2->getFacet();
$facet[$filter3->key] = $filter3->getFacet();
return $facet;
}In the getFacet() function, we do the following steps:
在getFacet()函数中,我们执行以下步骤:
Convert the original data to a
Pinq\Traversableobject for further processing.将原始数据转换为
Pinq\Traversable对象以进行进一步处理。We create 3 facets. The ‘author’ facet will group on the field
authorand it is a full string grouping; ‘title’ facet on fieldtitleand a partial string grouping (the starting 6 letters count); ‘price’ facet on fieldpriceand a range grouping (by a step of 10).我们创建3个构面。 “作者”构面将按字段
author分组,这是一个完整的字符串分组; 字段title上的“标题”构面和部分字符串分组(以6个字母开头); 字段price和范围分组的“价格”方面(以10为步长)。Finally, we get the facets and return them back to
test2function so that the template can render the data and the facets.最后,我们获取构面并将其返回给
test2函数,以便模板可以呈现数据和构面。
显示构面和过滤数据 (Displaying the facets and the filtered data)
Most of the time, facets will be displayed as a link and bring us to a filtered data set.
大多数情况下,构面将显示为链接,并带我们进入经过过滤的数据集。
We have already created a route ('demo2/facet/{key}/{value}') to display the faceted search results and the facet links.
我们已经创建了一条路线( 'demo2/facet/{key}/{value}' )来显示多面搜索结果和多面链接。
The route takes two parameters, reflecting the key we facet on and the value of that key. The test3 function that eventually gets invoked from that route is excerpted below:
该路线有两个参数,分别反映了我们所面对的键和该键的值。 下面摘录了最终从该路由调用的test3函数:
public function test3($app, $originalData, $key, $value)
{
$data = \Pinq\Traversable::from($originalData);
$facet = $this->getFacet($data);
$filter = null;
if ($key == 'author')
{
$filter = $data
->where(function($row) use ($value)
{
return $row['author'] == $value;
})
->orderByAscending(function($row) use ($key)
{
return $row['price'];
})
;
}
elseif ($key == 'price')
{
...
}
else //$key==title
{
...
}
return $app['twig']->render('demo2.html.twig', array('facet' => $facet, 'data' => $filter));
}Basically, depending on the key, we apply filtering (the anonymous function in where clause) corresponding to the value passed in and get the further screened data. We can also specify the order of the faceted data.
基本上,根据键,我们应用与传入的值相对应的过滤( where子句中的匿名函数)并获取进一步的筛选数据。 我们还可以指定分面数据的顺序。
Finally, we display the data (along with the facets) in a template. This route renders the same template as that which is used by route 'demo2').
最后,我们在模板中显示数据(以及构面)。 该路由与路由'demo2'使用的模板相同)。
Next, let’s take a look at the template and see how the facet links are displayed. I am using Bootstrap so the CSS components used here should be quite familiar:
接下来,让我们看一下模板,并查看构面链接的显示方式。 我正在使用Bootstrap,因此此处使用CSS组件应该非常熟悉:
<div class="col col-md-4">
<h4>Search Bar</h4>
<ul>
{% for k, v in facet %}
<li><h5><strong>{{k|capitalize}}</strong></h5></li>
<ul class="list-group">
{% for vv in v %}
<li class="list-group-item"><span class="badge">{{vv.count}}</span><a href="/demo2/facet/{{k}}/{{vv.key}}">{{vv.key}}</a></li>
{%endfor%}
</ul>
{%endfor%}
</ul>
</div>We have to remember that the facet generated by our app is a nested array. In the first layer, it is an array of all the facets, and in our case, we have a total of 3 (for author, title, author, respectively).
我们必须记住,我们的应用程序生成的构面是一个嵌套数组。 在第一层中,它是所有构面的数组,在我们的例子中,共有3个面(分别针对author , title , author )。
For each facet, it is a “key-value” paired array so that we can iterate in a traditional way.
对于每个方面,它都是一个“键值”配对数组,因此我们可以以传统方式进行迭代。
Please note how we construct the URIs of the links. We used both the outer loop’s key (k) and inner loops key (vv.key) to be the parameters in the route ('demo2/facet/{key}/{value}'). The count of the key (vv.count) is used to touch up the display in the template (as a Bootstrap badge).
请注意我们如何构造链接的URI。 我们使用外循环键( k )和内循环键( vv.key )作为路由中的参数( 'demo2/facet/{key}/{value}' )。 键的计数( vv.count )用于vv.count模板中的显示(作为Bootstrap徽标)。
The template will be rendered as shown below:
模板将如下图所示:
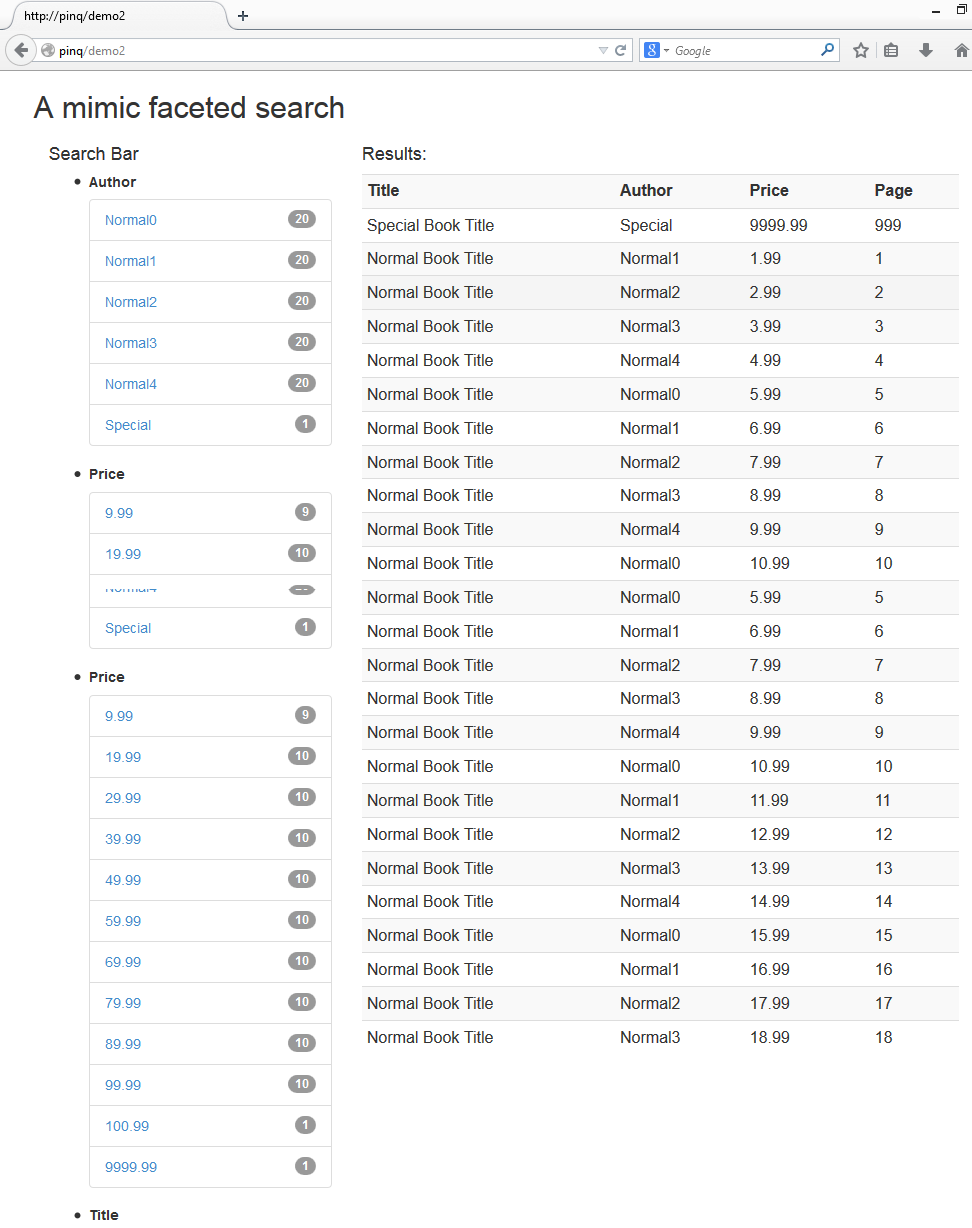
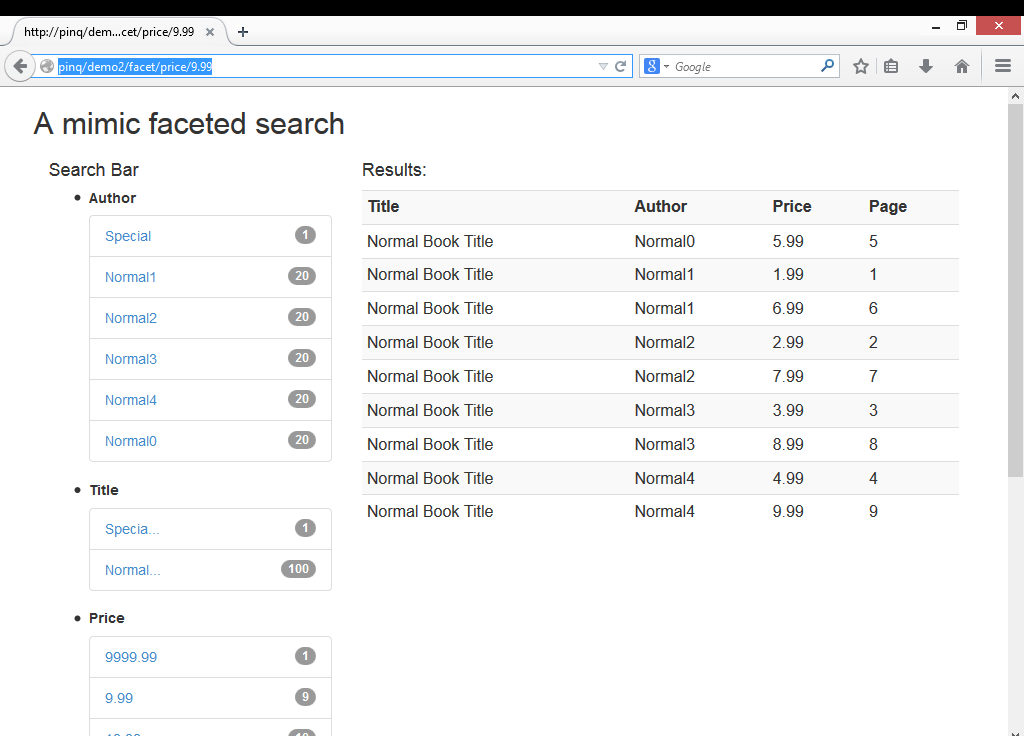
(The first shows the initial entry page and the second shows a faceted result with price between $0 to $10 and ordered by author)
(第一个显示初始输入页面,第二个显示分面结果,价格在$ 0到$ 10之间,由author订购)
All right, so far we have managed to mimic a faceted search feature in our web app!
好的,到目前为止,我们已经设法在我们的Web应用程序中模仿了多面搜索功能!
Before we conclude this series, we shall take a final look at this demo and see what can be done to improve it and what are the limitations.
在结束本系列文章之前,我们将最后看一下该演示,看看可以做些什么来改进它以及有哪些局限性。
有待改进 (Improvements to be made)
Overall, this is a quite rudimentary demo. We just ran through the basic syntax and concepts and forged them into a can-run example. As we saw earlier, a few areas can be improved on to make it more flexible.
总体而言,这是一个非常基本的演示。 我们只介绍了基本的语法和概念,并将其锻造为可以运行的示例。 正如我们前面所看到的,可以在一些方面进行改进以使其更加灵活。
We need to consider providing “add-on” criteria searching capability. Our current implementation limits the facet search to be applied on the original only, instead of the screened data. This is the most important improvement I can think of.
我们需要考虑提供“附加”条件搜索功能。 我们当前的实现方式限制了方面搜索仅应用于原始内容,而不是应用于筛选后的数据。 这是我能想到的最重要的改进。
局限性 (Limitations)
The faceted search implemented here has a deep-rooted limitation (and probably true for other faceted search implementations):
此处实现的多面搜索具有根深蒂固的局限性(对于其他多面搜索实现可能也是如此):
We are retrieving data from the MySQL server every time.
我们每次都从MySQL服务器检索数据。
This app uses Silex as the framework. For any single-entrance framework like Silex, Symfony, Laravel, its index.php (or app.php) gets called every time a route is to be analyzed and a controller’s function is to be invoked.
该应用程序使用Silex作为框架。 对于诸如Silex,Symfony,Laravel之类的任何单入口框架,每次要分析路线并调用控制器功能时,都会调用其index.php (或app.php )。
Looking at the code in our index.php, we will see that this also means the below line of code:
查看index.php中的代码,我们将看到这也意味着下面的代码行:
$demo = new pinqDemo\Demo($app);gets called every time a page in the app is displayed, which then means the following lines are executed every time:
每次在应用程序中显示页面时都会被调用,这意味着每次都会执行以下行:
class Demo
{
private $books = '';
public function __construct($app)
{
$sql = 'select * from book_book order by id';
$this->books = $app['db']->fetchAll($sql);
}Will it be better if we avoid using a framework? Well, besides the fact that it is not really a very good idea to develop an app without a framework, we are still facing the same issue: data (and status) are not persistent from one HTTP call to another. This is the fundamental characteristic of HTTP. This should be avoided with the use of a caching engine.
如果我们避免使用框架会更好吗? 嗯,除了在没有框架的情况下开发应用程序并不是一个好主意的事实之外,我们仍然面临着同样的问题:数据(和状态)在从一个HTTP调用到另一个HTTP调用之间并不持久。 这是HTTP的基本特征。 使用缓存引擎应避免这种情况。
We do save some SQL statements being executed at the server side when we are constructing the facets. Instead of passing 1 select query AND 3 different group by queries with the same where statement, we just issue one select query with the where statement and use PINQ to provide the aggregating information.
在构造构面时,我们确实保存了一些在服务器端执行SQL语句。 与其传递具有相同where语句的1个select查询和3个不同的group by查询,我们只不过是发出一个带where语句的select查询并使用PINQ提供汇总信息。
结论 (Conclusion)
In this part, we managed to mimic a facet search capability for our book collection site. As I said, it is merely a can-run demo and has plenty of room of improvement and some default limitations. Let us know if you build on this example and can show us some more advanced use cases!
在这一部分中,我们设法模仿了图书收藏网站的方面搜索功能。 正如我所说的,这只是一个可以运行的演示,并且有很大的改进空间和一些默认限制。 让我们知道您是否基于此示例,并且可以向我们展示一些更高级的用例!
The author of PINQ is now working on the next major version release (version 3). I do hope it can get more powerful.
PINQ的作者现在正在开发下一个主要版本(版本3)。 我确实希望它可以变得更强大。
Feel free to leave your comments and thoughts below!
随时在下面留下您的评论和想法!
翻译自: https://www.sitepoint.com/pinq-querify-datasets-faceted-search/
PINQ-验证数据集-多面搜索相关推荐
- 机器学习基础|K折交叉验证与超参数搜索
文章目录 交叉验证 交叉验证的概念 K的取值 为什么要用K折交叉验证 Sklearn交叉验证API 超参数搜索 超参数的概念 超参数搜索的概念 超参数搜索的原理 Sklearn超参数搜索API 实例 ...
- Python使用tpot获取最优模型、将最优模型应用于交叉验证数据集(5折)获取数据集下的最优表现,并将每一折(fold)的预测结果、概率、属于哪一折与测试集标签、结果、概率一并整合输出为结果文件
Python使用tpot获取最优模型.将最优模型应用于交叉验证数据集(5折)获取数据集下的最优表现,并将每一折(fold)的预测结果.概率.属于哪一折与测试集标签.结果.概率一并整合输出为结果文件 目 ...
- 【TensorFlow】TensorFlow从浅入深系列之七 -- 教你使用验证数据集判断模型效果
本文是<TensorFlow从浅入深>系列之第7篇 TensorFlow从浅入深系列之一 -- 教你如何设置学习率(指数衰减法) TensorFlow从浅入深系列之二 -- 教你通过思维导 ...
- 怎么用Q-Q图验证数据集的分布
样本数据集在构建机器学习模型的过程中具有重要的作用,样本数据集包括训练集.验证集.测试集,其中训练集和验证集的作用是对学习模型进行参数择优,测试集是测试该模型的泛化能力. 正负样本数据集符合独立同分布 ...
- python kfold交叉验证_Python sklearn KFold 生成交叉验证数据集的方法
源起: 1.我要做交叉验证,需要每个训练集和测试集都保持相同的样本分布比例,直接用sklearn提供的KFold并不能满足这个需求. 2.将生成的交叉验证数据集保存成CSV文件,而不是直接用sklea ...
- python kfold交叉验证_Python sklearn KFold 生成交叉验证数据集
源起: 1.我要做交叉验证,需要每个训练集和测试集都保持相同的样本分布比例,直接用sklearn提供的KFold并不能满足这个需求. 2.将生成的交叉验证数据集保存成CSV文件,而不是直接用sklea ...
- Python机器学习:多项式回归与模型泛化006验证数据集与交叉验证
交叉验证 引入数据集并且train_test_split #交叉验证 import numpy as np from sklearn import datasets digits = datasets ...
- 参数调优:K折交叉验证与GridSearch网格搜索
本文代码及数据集来自<Python大数据分析与机器学习商业案例实战> 一.K折交叉验证 在机器学习中,因为训练集和测试集的数据划分是随机的,所以有时会重复地使用数据,以便更好地评估模型的有 ...
- 10大类、142条数据源,中文NLP数据集线上搜索开放
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! 有了这个开源项目,再也不用担心找不到好用的中文 NLP 数据集,142 条数据集, ...
最新文章
- Android Dialog 弹框之外的区域 默认透明背景色修改
- c++ iou学习笔记
- Hibernate 中lazy的作用
- 关于 屏幕阅读器 和 sr-only
- python 线性回归与逻辑回归区别(有监督学习【分类、回归】、无监督学习【聚类、强化学习】、损失函数、梯度下降、学习率、过拟合、欠拟合、正则化)
- php+签到+二进制方式,PHP开发中如何实现二进制搜索?
- CASIO 5800P计算器游戏--猜数字游戏
- 69. (待补) (使用sqlite3)实现简单的管理系统 MVC 将链表作为内存数据模型,将sqlite3作为数据库,将终端作为交互界面。读数据库生成 链表,修改链表写入文件。...
- 今日头条下拉词框怎么做的呢?怎么优化推广呢?
- 用CSS制作细线表格
- Qt读取海康威视NVR服务器视频
- 话费充值哪里便宜?这样充帮我省了不少钱,推荐给您
- 2019上半年个人成长复盘
- 6000字用户成长分析体系。
- 小白学Pytorch 系列--Torch API(1)
- 教育邮箱怎么申请?教育邮箱怎么登录?
- 2019年中国软件业务收入100强
- RNGUZI疑是玩电竞竞猜的APPO(∩_∩)O哈哈~APP?QQ是什么让他输?qun是放水吗?还是身体不适91435456?
- 【利用Advanced Installer 进行Springboot 打jar包部署】
- 一个交换机可以放两个网段ip吗_网关和网段有什麼区别?