Stanford UFLDL教程 线性解码器
线性解码器
Contents[hide]
|
稀疏自编码重述
稀疏自编码器包含3层神经元,分别是输入层,隐含层以及输出层。从前面(神经网络)自编码器描述可知,位于神经网络中的神经元都采用相同的激励函数。在注解中,我们修改了自编码器定义,使得某些神经元采用不同的激励函数。这样得到的模型更容易应用,而且模型对参数的变化也更为鲁棒。
回想一下,输出层神经元计算公式如下:
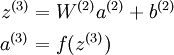
其中 a(3) 是输出. 在自编码器中, a(3) 近似重构了输入 x = a(1)。
S 型激励函数输出范围是 [0,1],当 f(z(3)) 采用该激励函数时,就要对输入限制或缩放,使其位于[0,1] 范围中。一些数据集,比如 MNIST,能方便将输出缩放到 [0,1] 中,但是很难满足对输入值的要求。比如, PCA 白化处理的输入并不满足[0,1] 范围要求,也不清楚是否有最好的办法可以将数据缩放到特定范围中。
线性解码器
设定 a(3) = z(3) 可以很简单的解决上述问题。从形式上来看,就是输出端使用恒等函数f(z) = z 作为激励函数,于是有 a(3) = f(z(3)) = z(3)。我们称该特殊的激励函数为线性激励函数 (称为恒等激励函数可能更好些)。
需要注意,神经网络中隐含层的神经元依然使用S型(或者tanh)激励函数。这样隐含单元的激励公式为 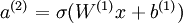 ,其中
,其中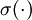 是 S 型函数, x 是输入,W(1) 和 b(1) 分别是隐单元的权重和偏差项。我们仅在输出层中使用线性激励函数。
是 S 型函数, x 是输入,W(1) 和 b(1) 分别是隐单元的权重和偏差项。我们仅在输出层中使用线性激励函数。
一个 S 型或 tanh 隐含层以及线性输出层构成的自编码器,我们称为线性解码器。
在这个线性解码器模型中,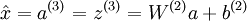 。因为输出
。因为输出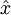 是隐单元激励输出的线性函数,改变W(2) ,可以使输出值 a(3) 大于 1 或者小于 0。这使得我们可以用实值输入来训练稀疏自编码器,避免预先缩放样本到给定范围。
是隐单元激励输出的线性函数,改变W(2) ,可以使输出值 a(3) 大于 1 或者小于 0。这使得我们可以用实值输入来训练稀疏自编码器,避免预先缩放样本到给定范围。
随着输出单元的激励函数的改变,这个输出单元梯度也相应变化。回顾之前每一个输出单元误差项定义为:
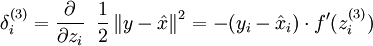
其中 y = x 是所期望的输出, 是自编码器的输出,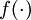 是激励函数.因为在输出层激励函数为f(z) = z, 这样 f'(z) = 1,所以上述公式可以简化为
是激励函数.因为在输出层激励函数为f(z) = z, 这样 f'(z) = 1,所以上述公式可以简化为
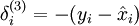
当然,若使用反向传播算法来计算隐含层的误差项时:
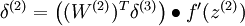
因为隐含层采用一个 S 型(或 tanh)的激励函数 f,在上述公式中,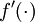 依然是 S 型(或 tanh)函数的导数。
依然是 S 型(或 tanh)函数的导数。
中英文对照
- 线性解码器 Linear Decoders
- 稀疏自编码 Sparse Autoencoder
- 输入层 input layer
- 隐含层 hidden layer
- 输出层 output layer
- 神经元 neuron
- 神经网络 neural network
- 自编码器 autoencoder
- 激励函数 activation function
- 鲁棒 robust
- S型激励函数 sigmoid activation function
- tanh激励函数 tanh function
- 线性激励函数 linear activation function
- 恒等激励函数 identity activation function
- 隐单元 hidden unit
- 权重 weight
- 偏差项 error term
- 反向传播算法 backpropagation
- from: http://ufldl.stanford.edu/wiki/index.php/%E7%BA%BF%E6%80%A7%E8%A7%A3%E7%A0%81%E5%99%A8
Stanford UFLDL教程 线性解码器相关推荐
- Stanford UFLDL教程 主成分分析(PCA)
Stanford UFLDL教程 主成分分析 Contents [hide] 1 引言 2 实例和数学背景 3 旋转数据 4 数据降维 5 还原近似数据 6 选择主成分个数 7 对图像数据应用PCA算 ...
- Stanford UFLDL教程 独立成分分析
独立成分分析 Contents [hide] 1概述 2标准正交ICA 3拓扑ICA 4中英文对照 5中文译者 概述 试着回想一下,在介绍 稀疏编码算法中我们想为样本数据学习得到一个超完备基(over ...
- Stanford UFLDL教程 稀疏编码
稀疏编码 Contents [hide] 1稀疏编码 2概率解释 [基于1996年Olshausen与Field的理论] 3学习算法 4中英文对照 5中文译者 稀疏编码 稀疏编码算法是一种无监督学习方 ...
- Stanford UFLDL教程 深度网络概览
深度网络概览 Contents [hide] 1概述 2深度网络的优势 3训练深度网络的困难 3.1数据获取问题 3.2局部极值问题 3.3梯度弥散问题 4逐层贪婪训练方法 4.1数据获取 4.2更好 ...
- Stanford UFLDL教程 自编码算法与稀疏性
自编码算法与稀疏性 目前为止,我们已经讨论了神经网络在有监督学习中的应用.在有监督学习中,训练样本是有类别标签的.现在假设我们只有一个没有带类别标签的训练样本集合 ,其中 .自编码神经网络是一种无监督 ...
- Stanford UFLDL教程 稀疏编码自编码表达
稀疏编码自编码表达 Contents [hide] 1稀疏编码 2拓扑稀疏编码 3稀疏编码实践 3.1将样本分批为"迷你块" 3.2良好的s初始值 3.3可运行算法 4中英文对照 ...
- Stanford UFLDL教程 数据预处理
数据预处理 Contents [hide] 1概要 2数据归一化 2.1简单缩放 2.2逐样本均值消减 2.3特征标准化 3PCA/ZCA白化 3.1基于重构的模型 3.2基于正交化ICA的模型 4大 ...
- Stanford UFLDL教程 卷积特征提取
卷积特征提取 Contents [hide] 1概述 2全联通网络 3部分联通网络 4卷积 5中英文对照 6中文译者 概述 前面的练习中,解决了一些有关低分辨率图像的问题,比如:小块图像,手写数字小幅 ...
- Stanford UFLDL教程 微调多层自编码算法
微调多层自编码算法 Contents [hide] 1介绍 2一般策略 3使用反向传播法进行微调 4中英文对照 5中文译者 介绍 微调是深度学习中的常用策略,可以大幅提升一个栈式自编码神经网络的性能表 ...
最新文章
- P1435 回文字串(DP)
- Redhat7.3、Oracle12C、4节点环境搭建
- C 为什么非要引入那几种类型转换?
- std::string中的反向迭代器rbegin()和rend()
- 图形化安装配置:安装oracle、新建数据库、用plsql连接oracle,套路明白了其实挺简单...
- 可以批量转modis投影_SNAP批量处理Sentinel2数据
- 字典推导式_Python基础-推导式
- Boost笔记--Thread--Ubuntu上初次使用时遇到的问题
- Python学习笔记之类(三)
- 以太坊—JSON RPC API
- GitHub上不错的Android开源项目(二)
- nodejs面试题笔记
- 十大验证码解决方案服务比较
- 可以免费下载任何文档(网页转换助手)
- ASP.NET Core 和 EF Core 系列教程——排序、筛选、分页和分组
- USACO 1.1.2 - Greedy Gift Givers(模拟)
- Mybatis(一)Mybatis的基本使用
- fastai 文本分类_使用Fastai v2和多标签文本分类器检查有毒评论
- HTML+CSS例子>太极
- 亿发软件:定制ERP管理系统在湖南建材行业的应用
热门文章
- 2014腾讯WE大会:开启未来的五大科技发展趋势
- php print_r this,PHP 打印函数之 print print_r
- 学习笔记Spark(四)—— Spark编程基础(创建RDD、RDD算子、文件读取与存储)
- python 稀疏数组搜索
- 小米6 android os,脱离安卓!小米6刷入全新系统:界面炫酷,可流畅日常使用!...
- python生成字母图片_Python 模拟动态产生字母验证码图片功能
- 破解IDEA2018的正确姿势
- 基础的VueJS面试题(附答案)
- 【Selenium 小知识】获取 token 和 cookies
- lazarus php,Lazarus 终于安装成功了