Stanford UFLDL教程 独立成分分析
独立成分分析
Contents[hide]
|
概述
试着回想一下,在介绍 稀疏编码算法中我们想为样本数据学习得到一个超完备基(over-complete basis)。具体来说,这意味着用稀疏编码学习得到的基向量之间不一定线性独立。尽管在某些情况下这已经满足需要,但有时我们仍然希望得到的是一组线性独立基。独立成分分析算法(ICA)正实现了这一点。而且,在 ICA 中,我们希望学习到的基不仅要线性独立,而且还是一组标准正交基。(一组标准正交基  需要满足条件:
需要满足条件: (如果
(如果 )或者
)或者 (如果i = j))
(如果i = j))
与稀疏编码算法类似,独立成分分析也有一个简单的数学形式。给定数据 x,我们希望学习得到一组基向量――以列向量形式构成的矩阵 W,其满足以下特点:首先,与稀疏编码一样,特征是稀疏的;其次,基是标准正交的(注意,在稀疏编码中,矩阵 A 用于将特征 s 映射到原始数据,而在独立成分分析中,矩阵W 工作的方向相反,是将原始数据 x 映射到特征)。这样我们得到以下目标函数:
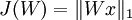
由于 Wx 实际上是描述样本数据的特征,这个目标函数等价于在稀疏编码中特征 s 的稀疏惩罚项。加入标准正交性约束后,独立成分分析相当于求解如下优化问题:
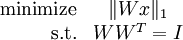
与深度学习中的通常情况一样,这个问题没有简单的解析解,而且更糟糕的是,由于标准正交性约束,使得用梯度下降方法来求解该问题变得更加困难――每次梯度下降迭代之后,必须将新的基映射回正交基空间中(以此保证正交性约束)。
实践中,在最优化目标函数的同时施加正交性约束(如下一节 正交ICA中讲到的)是可行的,但是速度慢。在标准正交基是不可或缺的情况下,标准正交ICA的使用会受到一些限制。(哪些情况见:TODO )
标准正交ICA
标准正交ICA的目标函数是:
通过观察可知,约束WWT = I隐含着另外两个约束:
第一,因为要学习到一组标准正交基,所以基向量的个数必须小于输入数据的维度。具体来说,这意味着不能像通常在 稀疏编码中所做的那样来学习得到超完备基(over-complete bases)。
第二,数据必须经过无正则 ZCA白化(也即,ε设为0)。(为什么必须这样做?见TODO)
因此,在优化标准正交ICA目标函数之前,必须确保数据被白化过,并且学习的是一组不完备基(under-complete basis)。
然后,为了优化目标函数,我们可以使用梯度下降法,在梯度下降的每一步中增加投影步骤,以满足标准正交约束。过程如下:
重复以下步骤直到完成:

 , 其中U是满足WWT = I的矩阵空间
, 其中U是满足WWT = I的矩阵空间
在实际中,学习速率α是可变的,使用一个线搜索算法来加速梯度.投影步骤通过设置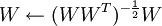 来完成,这实际上可以看成就是ZCA白化(TODO:解释为什么这就象ZCA白化).
来完成,这实际上可以看成就是ZCA白化(TODO:解释为什么这就象ZCA白化).
拓扑ICA
与 稀疏编码算法类似,加上一个拓扑代价项,独立成分分析法可以修改成具有拓扑性质的算法。
中英文对照
- 独立成分分析 Independent Component Analysis
- 稀疏编码算法 Sparse coding
- 超完备基 Over-complete basis
- 标准正交基 Orthonormal basis
- 稀疏惩罚项 Sparsity penalty
- 梯度下降法 Gradient descent
- 白化 Whitened
- 不完备基 Under-complete basis
- 线搜索算法 Line-search algorithm
-
拓扑代价项 Topographic cost term
- from: http://ufldl.stanford.edu/wiki/index.php/%E7%8B%AC%E7%AB%8B%E6%88%90%E5%88%86%E5%88%86%E6%9E%90
Stanford UFLDL教程 独立成分分析相关推荐
- 机器学习教程 之 独立成分分析:PCA的高阶版
有好些天没写博客了,最近一直忙着在看论文,解模型,着实有点头痛.今天趁着又到周末了更一帖(其实是模型解不下去了-),这次来说一下一个在信号分析与数据挖掘领域颇为使实用的算法,独立成分分析(ICA),这 ...
- Stanford UFLDL教程 主成分分析(PCA)
Stanford UFLDL教程 主成分分析 Contents [hide] 1 引言 2 实例和数学背景 3 旋转数据 4 数据降维 5 还原近似数据 6 选择主成分个数 7 对图像数据应用PCA算 ...
- Python专栏 | 独立成分分析(ICA)的实例应用:消除伪影信号
关注微信公众号:脑机接口研习社 了解脑机接口最近进展 系列文章目录 Python专栏 | 脑电图和脑磁图(EEG/MEG)的数据分析方法之载入数据 Python专栏 | MNE脑电数据(EEG/MEG ...
- 独立成分分析及Demo
1. 独立成分分析建模 独立成分分析目标是实现在海量数据中学习完备的单位正交基,所以,所以,可以建立如下的最优化问题: 其中,第一项为稀疏约束,第二项为完备单位正交基约束,熟悉稀疏表示的可能会注意到, ...
- R语言使用caret包的preProcess函数进行数据预处理:对所有的数据列进行独立成分分析ICA(Independent components analysis)、设置method参数为ica
R语言使用caret包的preProcess函数进行数据预处理:对所有的数据列进行独立成分分析ICA(Independent components analysis).设置method参数为ica 目 ...
- 独立成分分析ICA、因子分析、LDA降维、NMF非负矩阵分解
独立成分分析ICA.因子分析.LDA降维.NMF非负矩阵分解 目录 独立成分分析ICA.因子分析.LDA降维.NMF非负矩阵分解 独立成分分析ICA
- Stanford UFLDL教程 用反向传导思想求导
用反向传导思想求导 Contents [hide] 1简介 2示例 2.1示例1:稀疏编码中权重矩阵的目标函数 2.2示例2:稀疏编码中的平滑地形L1稀疏罚函数 2.3示例3:ICA重建代价 3中英文 ...
- 主成分分析(PCA)和独立成分分析(ICA)相关资料
来源:知乎:独立成分分析(ICA)与主成分分析(PCA)的区别在哪里(https://www.zhihu.com/question/28845451) - 一楼:魏天闻 首先回答题主的问题:不管是PC ...
- 独立成分分析ICA系列3:直观解释与理解
服从均匀分布的独立成分sl和s2的联合分布.其中横坐标表示s1,纵坐标表示s2 为了进一步解释ICA的统计模型,考虑服从下列均匀密度分布的两个互相独立的随机变量: 这个联合分布是在一个方形上均匀分布的 ...
最新文章
- 在CentOS 6.3 64bit上安装MySQL for python模块
- 【教程】新手如何制作简单MAD和AMV,学不会那都是时辰
- pom.xml错误:org.codehaus.plexus.archiver.jar.Manifest.write(java.io.PrintWriter)的解决方法
- linux2.6内核链表
- mysql druid 多数据源_SpringBoot使用阿里数据库连接池Druid以及多数据源配置
- “最粉嫩”的JVM垃圾回收器及算法,王者笔记!
- ZedGraph在Asp.net中的应用
- python扩展库简介_python非官方扩展库
- 软件项目验收的准备工作
- RAID卡的安装配置
- Asp.Net 之 枚举类型的下拉列表绑定
- 手机弹出键盘 窗口改变事件
- 怎么删除计算机多余的启动项,怎么删除Win7多余的开机启动项
- lzg_ad:如何自定义Shell组件
- Android之传感器(三)方向传感器
- Android Apk瘦身方案1——R.java文件常量内联
- 51nod 1113 矩阵快速幂【裸题】【内含黑科技】
- 分析PostLateUpdate.FinishFrameRendering()。每帧渲染时间截然不同
- 音视频开发(十四):OpenGL 与 OpenGL ES2区别
- 欧国联 法国 vs 德国