一文贯通python文件读取

不论是数据分析还是机器学习,乃至于高大上的AI,数据源的获取是所有过程的入口。 数据源的存在形式多为数据库或者文件,如果把数据看做一种特殊格式的文件的话,即所有数据源都是文件。获得数据,就是读取文件的操作,文件有各种各样的格式即数据的组织形式,如何方便快捷地获取文件中的内容呢?
还是那句名言,life is short, just use python。
操作基础
在python 中,文件的操作分为面向目录和面向文件的,本质都是一样的。
面向目录的常见操作见下表:
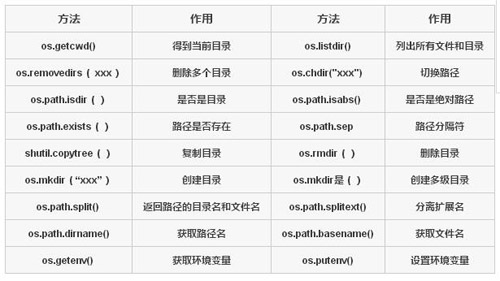
面向文件的常见操作见下表:
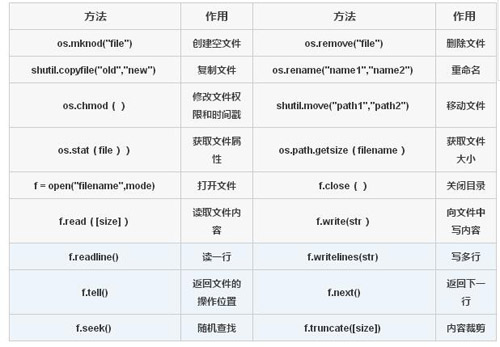
在这些基本操作中,遍历目录并列出所有文件或者所需的目标文件是一种常见的操作。另外,需要注意的是打开文件时的模式,a,w,r,组合时的a+,w+,r+, 还有针对这六种模式在读取二进制文件时都要加上b。 在操作结束时,一定要显式关闭文件, 当然 通过with 语句的隐式关闭也是可以的。
对于作为数据内容源的文件而言, 可以简单的分为文本和非文本两类,就是内容本身是文字的和非文字的,对混合形式的文件一般可以采用分而治之的方式。对于数据分析而言,这里侧重于文件读取及数据的采集上。
文本文件读取
数据分析乃至文本分析都有涉及到文本文件的读取。文本文件也可以粗略的分为两类:纯内容文本和带格式约定的文本。纯内容文本就是相对纯粹的文本数据,例如新闻,博客文字内容,readme等等。带格式约定的文本是为了增强内容的功能性或者实现特定的语义,例如xml,html,json文件等。
纯内容文本文件
在读取纯内容文本的时候,就是一般的读文件基础操作,需要注意的是文本内容的字符集编码。判断文本文件属于哪个字符集,老码农还在用chardet,不知道现在有没有更先进的手段了。示例代码如下:
- import chardet
- f = open('/target_path/abel.txt',r)
- my_data = f.read()
- print chardet.detect(my_data)
chardet.detect 返回的是一个字典,包括编码类型和一个概率值。然后,就可以根据自己的需要进行编码转换了。
键值对相关的配置文件
在应用中经常有.ini文件来用于配置信息,在python 中可以利用ConfigParser来处理。ConfigParser 模块有RawConfigParser,ConfigParser 和SafeConfigParser 三种对象,一般采用ConfigParser即可。 一个应用的配置文件"myweb_config.ini"如下:
- [myweb]
- url = http://%(host)s:%(port)s/myweb
- host = 192.168.1.100
- port = 8888
那么,使用ConfigParser的示例代码如下:
- import ConfigParser
- mysql_config = ConfigParser.ConfigParser()
- cf.read("myweb_config.ini")
- print cf.get("portal", "url")
读取配置文件的一个常见使用情形是获取数据库的访问信息,以便从数据库中获取数据。
Json,XML和HTML文件
JSON是一种轻量级的数据交换格式。Json 文件采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言,是当前应用中主流的数据文件之一。 通过Python的json模块,可以将字符串形式的json数据转化为字典,也可以将Python中的字典数据转化为字符串形式的json数据。读取Json文件的示例代码如下:
- import json
- f = open("test.json", encoding='utf-8')
- my_json = json.load(f)
然后就可以对my_json 以字典方式进行读取了,需要主要的是设置Json文件解码模式。
XML是一套定义语义标记的规则,将文档分成许多部分并对这些部分加以标识。同时,也是定义了用于定义其他与特定领域有关的、语义的、结构化的标记语言的句法语言。在python 中解析 XML 文件有三种方法:SAX,DOM,和ElementTree。ElementTree就像一个轻量级的DOM,示例代码如下:
- import xml.etree.ElementTree as ET
- my_xml_tree = ET.parse('/home/abel/face.xml')
- print my_xml_tree.getroot()
HTML 更是我们最常接触文件,基于web的数据爬虫,数据分析,数据挖掘等都会涉及到HTML文件的读写。在python中,用BS4 来对html 进行操作是非常方便的,同样也可以对xml 文件进行类似的操作,尤其是从网络中读取html,示例代码如下:
- import requests
- from bs4 import BeautifulSoup
- res = requests.get("http://a.b.c/c?d=e")
- soup = BeautifulSoup(res.text)
- print soup.find_all('a')
CSV文件
CSV文件就是一种由逗号隔开的文本文件,使用非常广泛,尤其是excel 文件可以另存为CSV文件,使分析CSV文件中的数据更加方便。 在Python中可以之间使用csv模块进行操作即可,示例代码如下:
- import csv
- csv_reader = csv.reader(open('mydata.csv', encoding='utf-8'))
- for each_line in csv_reader:
- print each_line
常见的文本文件除了纯文本,键值对文件,json,xml,html,csv以外,就是大量的日志文件了,也可以选择的相关库或者自行分析读取, 进一步就可能进入到NLP的领域了。
媒体文件读取
媒体文件中的数据内容一般不是文本,是经过编码是数据,例如图片,音频,以及视频文件,为了简化可以暂不考虑其中的字幕情况。
图片文件
图片由各种各样的格式即数据内容的编解码方式,在python 中一般使用PIL 库对图片文件进行读取或者进一步的处理,示例代码如下:
- from PIL import Image
- im = Image.open('/home/abel/abc.jpg')
- w, h = im.size
- im.thumbnail((w/2, h/2))
- im.save('/home/abel/abc_thumbnail.jpg', 'jpeg')
这个一个获取一个图片文件缩略图的小例子。 PIL是很强大的,提供了几乎所有的图像基本操作,例如改变图像大小,旋转图像,图像格式转换,色场空间转换,图像增强,直方图处理,插值和滤波等等。当然,其他的一些科学计算库也提供了很多图像处理的功能,例如大名鼎鼎的OpenCV, 具体可以参见《7行python代码的人脸识别》一文。
音频MP3
和图片文件一样, 音频文件的编解码格式同样很多。以MP3为例,只要了解了MP3文件的编码格式,就可以通过Python直接对MP3中的文件信息进行读取了。如果不重复造轮子的话,python 对音频的支持库也有很多。就MP3而言,可以使用python 中的eye3D(http://http://eyed3.nicfit.net) 库来读取MP3 中的相关信息, 示例代码如下:
- import eyed3
- f_mp3 = eyed3.load("/users/hecom/xiangwang.mp3")
- print f_mp3.tag.title
- print f_mp3.info.time_secs
技术演进日新月异,老码农曾经使用过的PyMedia 好像很久没人维护了,至于mp3 文件的播放,可以使用的库同样很多,例如mp3play,pyaudio以及pygame等。对于音频文件的进一步处理一般就要涉及的语音识别和语音合成了。
视频MP4
视频可以粗略地看成音频、图片乃至文字的混合体了。在Python 中读取并处理视频文件,一般可以使用MoviePy库(https://github.com/Zulko/moviepy)。MoviePy是可用于视频编辑的基本操作(像剪切,合并,插入标题),视频合成(又名非线性编辑),视频处理,或者创建高级的效果。它可以读取和写入的最普通的视频格式,包括GIF。 示例代码如下:
- from moviepy.editor import *
- video = VideoFileClip("mybaby.mp4").subclip(50,60)
- txt_clip = ( TextClip("My Son 2002",fontsize=70,color='white')
- .set_position('center')
- .set_duration(10) )
- result = CompositeVideoClip([video, txt_clip])
- result.write_videofile("mybaby_edited.mp4",fps=25)
这个小例子是将一个MP4提取其中50秒至60秒之间的数据并增加上一点文本信息生成一个新的MP4文件。MoviePy中提供了很多视频处理的方法和示例,并且能与PIL,OpenCV,scikit Image,matplotlib等混合使用。另外,关于视频的摄取,python中也是有vediocapture库的。
带格式编码的文档读取
我们常见的另一类文档如PDF,word,excel等也是一种混合文档,里面一般以文本为主,主要在显示方式上作了规则限定,文档中包含了关于显示格式的大量信息。当然,这些文档还可以嵌入媒体文件。粗浅地解释一下,为了理解的方便,可以把这些带格式编码的文档看作浏览器和html文本的结合体,这样文件中的某些逻辑处理就可以想象成JavaScript的相关操作了。
PDF文件
PDF是一种非常好用的格式,它能够解析并显示与图片结合在一起的文本,并且具备一般性的不可编辑。在Python 中一般可以通过pdfminer(http://www.unixuser.org/~euske/python/pdfminer/) 或者pypdf 来读取pdf文件中的内容, 官网给出的示例代码如下:
- from pdfminer.pdfparser import PDFParser
- from pdfminer.pdfdocument import PDFDocument
- from pdfminer.pdfpage import PDFPage
- from pdfminer.pdfpage import PDFTextExtractionNotAllowed
- from pdfminer.pdfinterp import PDFResourceManager
- from pdfminer.pdfinterp import PDFPageInterpreter
- from pdfminer.pdfdevice import PDFDevice
- # Open a PDF file.
- fp = open('mypdf.pdf', 'rb')
- # Create a PDF parser object associated with the file object.
- parser = PDFParser(fp)
- # Create a PDF document object that stores the document structure.
- # Supply the password for initialization.
- document = PDFDocument(parser, password)
- # Check if the document allows text extraction. If not, abort.
- if not document.is_extractable:
- raise PDFTextExtractionNotAllowed
- # Create a PDF resource manager object that stores shared resources.
- rsrcmgr = PDFResourceManager()
- # Create a PDF device object.
- device = PDFDevice(rsrcmgr)
- # Create a PDF interpreter object.
- interpreter = PDFPageInterpreter(rsrcmgr, device)
- # Process each page contained in the document.
- for page in PDFPage.create_pages(document):
- interpreter.process_page(page)
除此之外,还可以采用命令行———— pdf2txt 直接调用pdf文件进行文本转换。
word 文件
word文档几乎是最常见的办公文件了,但是.docx文件的结构比较复杂,一般分为三层:
- Docment对象表示整个文档;
- Docment包含了Paragraph对象的列表,Paragraph对象用来表示文档中的段落;
- 一个Paragraph对象包含Run对象的列表。
在python中 一般可以采用python-docx 库对word文件进行读写,简化起见,如果只关心word文件中的文本信息的话,示例代码如下:
- import docx
- doc = docx.Document('/home/abel/test.docx')
- paras = doc.paragraphs
- text_in_doc =[]
- for each_p in paras:
- text_in_doc.append(each_p.text)
Python DocX目前是Python OpenXML的一部分,可以用它打开Word 2007及以后的文档,而用它保存的文档可以在Microsoft Office 2007/2010, Microsoft Mac Office 2008, Google Docs, OpenOffice以及Apple iWork 08中打开。
Excel 文件
python处理excel文件主要的第三方库有xlrd、xlwt、xluntils和pyExcelerator等,还有人在这之上封装了很多更方便实用的库。这里使用朴实的xlrd(https://github.com/python-excel/xlrd/)来读取excel文件,示例代码如下:
- import xlrd
- myworkbook = xlrd.open_workbook('test.xls') # 打开xls文件
- table = myworkbook.sheet_by_name(u'Sheet1')
- nrows = table.nrows
- for i in range(nrows):
- print table.row_values(i)[:10]
这个小例子读取了test.xls 文件,打印出来Sheet1中各行的前十列。xlrd 是有局限的,无法读取excel中的一些对象,如:
- 图表,图片,宏以及其他的嵌入对象
- VBA,超链接,数据验证
- 公式(结果除外),条件的格式化,注释等等
好在,我们关注的是excel中的数据内容,以便进行数据分析,这些局限无伤大雅。
一句话小结
文件数据源的读取是数据分析的入口,使用Python可以方便快捷地读取各种文件格式中的内容,为进一步的数据分析或者数据清洗提供了简洁方式。
作者:老曹
来源:51CTO
一文贯通python文件读取相关推荐
- 一文贯通python文件读取 1
版权声明:本文为半吊子子全栈工匠(wireless_com,同公众号)原创文章,未经允许不得转载. https://blog.csdn.net/wireless_com/article/details ...
- python读取文件读不出来-python文件读取失败怎么处理
在读取文件时候比如读取 xxx.csv 时候 可能报编码错误 类似于 'xxx' codec can't decode byte 0xac in position 211: illegal multi ...
- python 文件读取错误之FileNotFoundError: [Errno 2] No such file or directory:,顺便学习斜杠/和反斜杠\的用法
python 文件读取错误之FileNotFoundError: [Errno 2] No such file or directory:,顺便学习斜杠/和反斜杠\的用法: 最近学习文件读取和中文分词 ...
- python文件读取操作练习题(统计单词)
python文件读取操作练习题(统计单词) 学习路线:python的文件读取基础入门(read(),readlines(),with.open()) ->python文件读取操作练习题(统计单词 ...
- python文件读取方法read(size)的含义是_Python file read()方法
在计算机中,文件包括了文档.图片.视频.程序组件等,每个类型的文件都有不同的作用或功用.例如一个程序通常由主程序.动态库.配置文件等组成,这些也是文件,起到支持程序运行的作用.想要使用文件,第一个操作 ...
- python文件读取下一个字符_python文件的读写总结
读写文件是最常见的IO操作.Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘, ...
- python文件读取数据-Python从文件中读取数据
一.读取整个文件内容 在读取文件之前,我们先创建一个文本文件resource.txt作为源文件. resource.txt my name isjoker, I am18years old, How ...
- python文件读取模式_day-2 python 文件读写模式r,r+,w,w+,a,a+的区别
r+和w+都是可读可写,区别在于r+读文件时,不会覆盖之前的内容,之前的内容能够读出来:w+读时,会覆盖之前的内容:所以读文件时,用r或者r+ #读操作 r 1 filepath = 'aa.log' ...
- 【python文件读取】加密数据的读取
问题引出 当我们程序中要用到账号,密码等一些敏感信息时,别人一眼就能看得到这些信息的时候,该怎么操作才能避免敏感信息被泄露呢?对了,我们不妨把信息写到文件里,通过获取文件中设定好的数据来起到数据保密的 ...
最新文章
- 基于Keras的CNN/Densenet实现分类
- 【坐在马桶上看算法】排序总结:小哼买书
- ubuntu 安装RPM软件包
- 单片微机原理P4:80C51串口与串行总线拓展
- 第3章 StringBuilder类
- 脚本重启nginx进程
- boost::contract模块实现sqrt的测试程序
- 《认清C++语言》のrandom_shuffle()和transform()算法
- pig连接oracle数据库,Pig安装讲解
- 详解Spring中的CharacterEncodingFilter--forceEncoding为true在java代码中设置失效--html设置编码无效...
- SAP手记之六:GUI安装后初始配置(中文语言包安装)
- 09月28日 pytorch与resnet(五) 转移学习
- windows10搭建DVWA靶场(新手向)
- VMware 中Fedora系统连接网络问题!
- 数据库基础(面试常见题)
- mysql容灾方案_mysql 架构 ~异地容灾
- Python-CSP 201903-1 小中大
- Photoshop如何修改图片的颜色
- linux系统分辨率文件,Linux下显示分辨率低解决方法
- 计算机学院寝室文明风景线活动,豫青网:宿舍风景线 你我来创建