从贪心选择到探索决策:基于强化学习的多样性排序
本文主要介绍发表在SIGIR'2018上的论文
这篇论文利用强化学习来解决多样性排序问题,整体思路和AlphaGo类似。
- Motivation
在信息检索领域一个重要的目标是提供可以覆盖很多topic的检索结果,也就是检索结果的多样性。简单来说就是选择候选文档的一个最小子集,这个子集能够尽可能多的包含subtopic。因为文档是否新颖取决于已经选择的文档,因此这是个NP-hard的问题。一些传统的方法都是把检索多样性看成是基于相关性和新颖性的一个排序问题,这些方法的核心是利用贪心来选择文档,每一次从候选集合中选择一个文档。贪心方法虽然可以加速在线排序,但是可想而知这种方法不可避免的会陷入次优解,因为它每次选择只考虑局部信息,而文档的“贡献"(utility)并不是独立的,是与其他文档相关联的,每次选择一个文档后都会改变候选集合中的剩余文档的utility,理想的解决方法是探索所有文档的排序,但在实际应用中这显然无法实现。得益于AlphaGo的成功,作者提出利用蒙特卡洛树搜索(Monte Carlo tree search-MCTS)来改善MDP模型。新的模型 (MCTS enhanced MDP for Diverse ranking)利用一个MDP来对序列文档的选择进行建模,在每次进行选择时,将query和已有文档送给RNN来产生policy和value,policy用来进行文档的选择而value用来估计整体文档排序的质量,比如
。为了防止次优解,作者使用MCTS来探索每个位置的可能的文档排序,由此产生一个对于当前选择的更好的policy。因为MCTS探索了更多未来可能的文档,它给出的policy有更大的概率产生全局最优解。当有了更好的policy后,模型通过最小化loss function来进行调整。
2. MDP和MCTS
马尔可夫决策过程(MDP)是建模序列决策的一个框架,关键部分为States,Action, Policy, Transition和Value。具体的,States 是状态的集合,在文章中作者定义状态为query、已有文档排序和候选文档的三元组;Action
是agent可以执行的离散动作集合,可选的动作会依赖于状态s,记为
; Policy
描述agent的行为,它是所有可能动作的一个概率分布,通过最大化长期回报进行优化;Transition
是状态转移函数
,也就是根据动作
将状态
映射为
;Value 是状态值函数
,用来预测当前基于policy p下状态s的长期回报。MDP模型中agent和环境在每个时刻
进行交互,在每个时间步
agent接收环境的状态
,然后选择一个动作
,之后 agent进入一个新的状态
,强化学习的目标是最大化长期回报,也就是最大化Value
。
通过MDP做的决策(根据policy选择置信度最大的动作)可能会陷入次优解,理论上我们应该探索所有的决策空间来得到全局最优解,但是这是不现实的。MCTS就是在决策空间中进行启发式的搜索,这样更容易产生比贪心更好的决策序列。给定时刻 ,policy
以及值函数
,MCTS的目标是找到一个“加强版”的策略来进行更好的决策。MCTS包含四个过程,分别是Selection,Expansion,Simulation/Evaluation 和 Back-propagation。Selection是从根节点开始,递归的选择一个最优子节点直到到达叶子节点;Expansion 指如果
不是一个终止节点,那么为
创建子节点并且根据policy选择一个子节点
;Simulation/Evaluation 是从
进行一次模拟直到结束。在AlphaGo Zero中使用值函数代替模拟来加速树的搜索。Back-propagation来更新当前序列中的每个节点里的数值。MCTS最终输出一个policy
,这个策略用来在
时刻选择动作。MCTS会持续的进行,直到完整的episode生成为止。
3. Algorithm
这一部分介绍 模型,模型整体如图
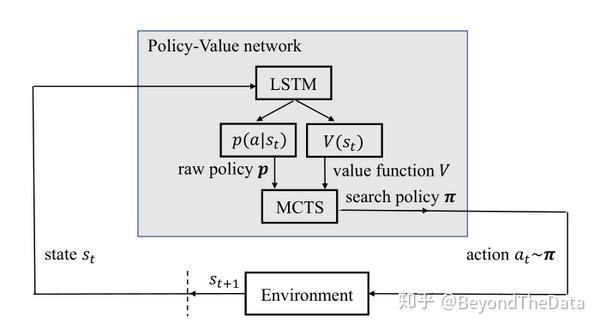
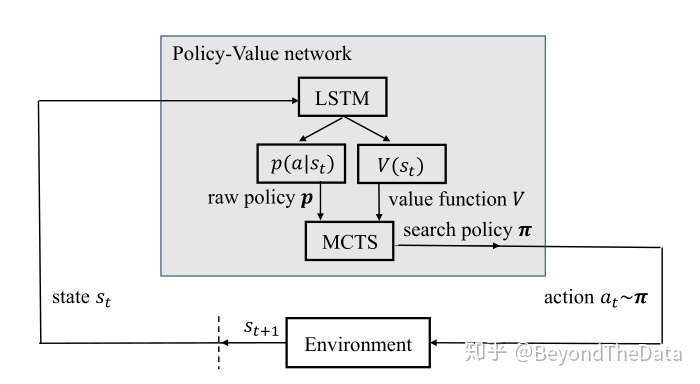
可以看出在每个时间步模型选择一个文档,首先模型通过LSTM来产生 和
,然后进行搜索,产生加强版的策略,之后根据策略选择动作并进入下一个状态。
3.1定义文档排序的MDP
定义候选文档全集为 ,每个文档通过doc2vec模型转化为向量,在时刻
,状态为
,其中
为query,
是已选择的文档,
是候选文档,在初始状态(
),
,
为空集;动作
是可以选择的动作集合,也就是对应每一个候选文档;状态转移
为
其中
为将
添加到
中,
为将
从
去除。每次选择新的文档query是保持不变的,新文档添加到
的末尾;值函数
用来估计整体排序的质量,通过学习
来近似评价指标,比如
。具体的,值函数
的计算如下
的输入为query和已有文档的向量表示,输出为cell state向量与output vector的concatenate,也就是
;有了值函数,可以计算policy
,计算方法如下
其中
为参数,最终的策略函数
为
。
3.2 MCTS
有了值函数和策略函数后,作者提出使用MCTS来进行改进,也就是在每个时刻 ,根据值函数
和策略函数
进行MCTS搜索得到更好的策略
。因为MCTS探索整体的排序空间,所以
比上式得到的
会选择更好的动作。具体算法为


在Selection阶段( line 3 - line 7),每次搜索都从根节点 开始选择最大化upper confidence bound的文档。注意这个根节点并不是树的根节点,而是
时刻的状态。最大化upper confidence bound的标准为
由 的定义可以看出,
是动作值函数,可以看做选择某个动作的回报,考虑的是“利用”,而
更倾向于“探索”,也就是更喜欢访问次数少的节点,
,是平衡因子,
定义为
是策略函数
的预测概率,
是节点的被访问次数。上式是PUCT算法的一个变体。
在Evaluation and expansion阶段( line8 - line 19),当到达一个叶节点 时,如果是episode的结尾,那么可以用已有的评价指标进行评估,比如
,否则可以用值函数来评估
。如果
可以展开,那么对每个动作构建新的节点并且初始化,也就是 line 11- line 16。
在Back-propagation and update( line 20 - line 28)中,我们更新 和
本质上 是每次从状态
选择动作
的对应的值函数的相加再求平均,也就是
,文中的公式是增量更新的形式。在Algorithm 1的 line 29 - line 32,根据已有的
来计算
3.3 利用强化学习训练网络
有了更好的策略 后,在每个时刻
都使用
进行文档选择。当候选集合为空或者已经满足挑选文档个数时不再进行文档的排序,此时利用已有的文档排序,可以和真实的文档计算评价指标,用
表示。所有时刻的状态和MCTS的策略组成
,我们要优化的目标为
第一项为平方误差,希望值函数在每个状态的值都和
接近;而第二项是为了让LSTM输出的策略与MCTS得到的策略更接近。loss function形象化表示如下图
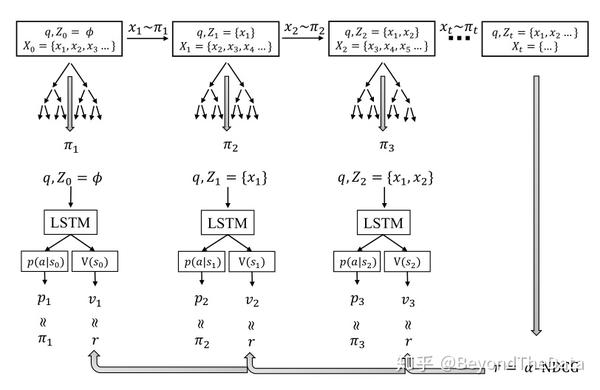
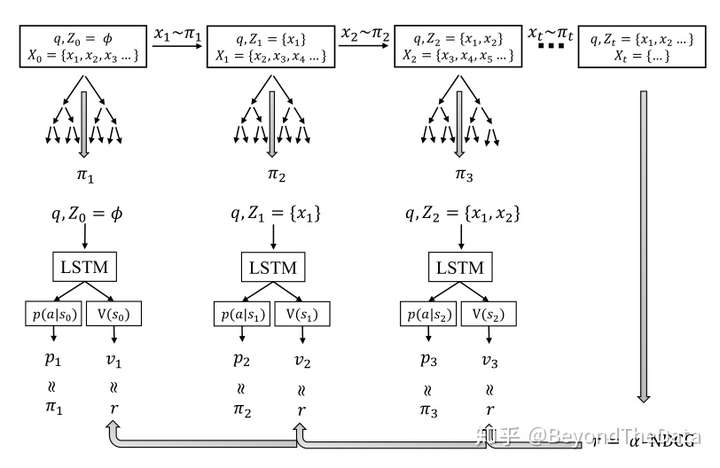
整体算法如下


可以看出针对每个query,在每个时刻选择文档时,利用MCTS来进行选择。当结束排序后,根据排序结果以及每个时刻的策略 和
进行模型的更新,最终得到一个训练好的LSTM模型。
3.4 Online ranking
MCTS是比较耗时的,在线上进行排序的时候可能会对服务有不小的压力。作者提出了Online ranking的方法,就是在排序时不再进行MCTS,直接用LSTM输出的策略。作者用实验验证了不使用MCTS的时候模型仍然会高于baseline。这得益于训练时MCTS的贡献,MCTS使模型能够输出更精确的策略。
3.4 与AlphaGo Zero的不同
虽然受到了AlphaGo Zeor的启发,但 与之还是有不同的。作者总结了三点,第一使任务的形式化不同。围棋是两人进行博弈,状态是棋盘以及落子位置,而多样性排序只需要每次挑选一个文档。第二是监督信息不同,在围棋中监督信息是最后的输赢,而在多样性排序中监督信息是各种多样性的评价指标。第三是网络模型不同,AlphaGo Zero使用了残差网络而排序使用了LSTM,这也是由于任务不同而有不同的选择。
4. Experiment
作者与其他算法进行了对比,实验结果如下
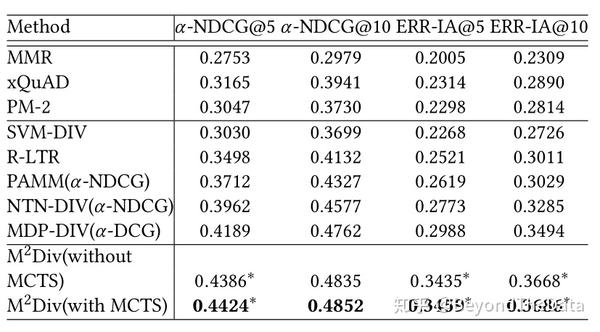
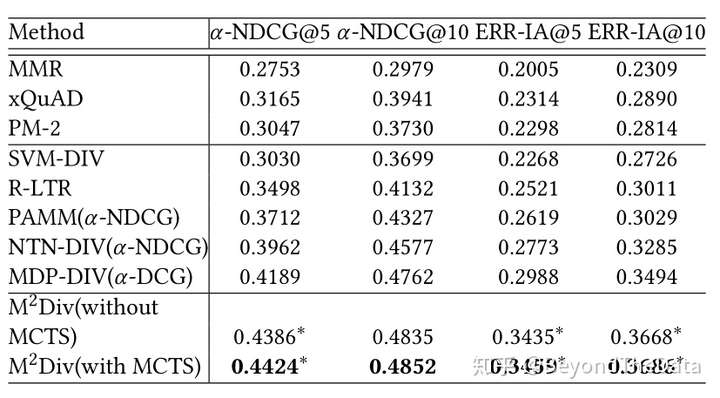
可以看出在测试阶段使用MCTS的效果最好。除此之外,作者还对比了在没有MCTS的排序中使用策略还是使用值函数,随着训练迭代的增多,使用策略效果会更好
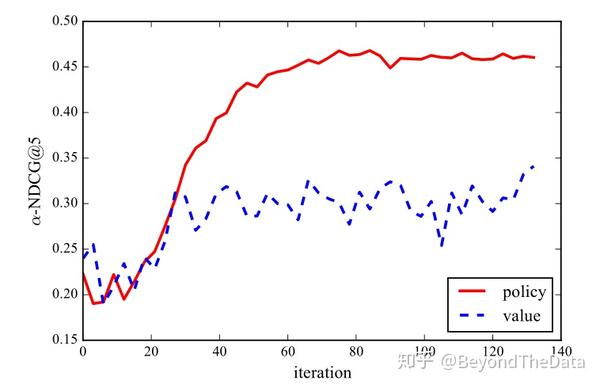
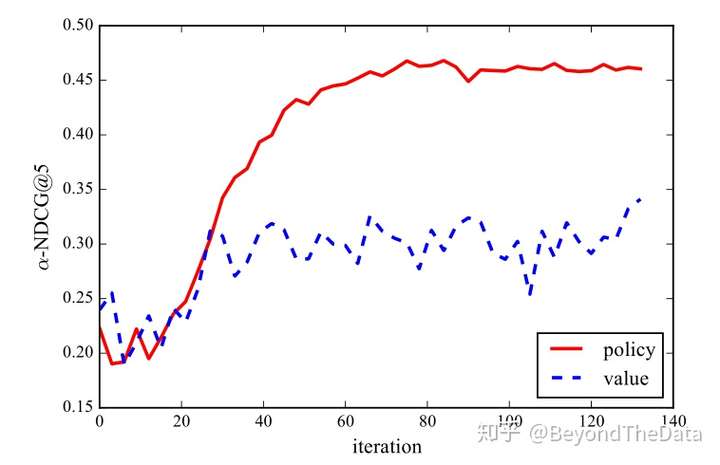
一个可能的原因是 的优化相对困难,尤其是在训练的初期。
5. 结束语
这篇文章利用强化学习来进行多样性排序,与已有方法相比效果由明显的提升。用AlphaGo算法的整体框架来解决序列排序问题确实也比较自然,尤其是文档之间还会互相的影响。这种方法也可以应用到其他序列生成的任务中,最直接的比如导航时路线生成,理想状况下是可以根据路况来选择道路的。强化学习应用很广,期待能在更多的场景下发挥作用。
原文:https://zhuanlan.zhihu.com/p/56053546
从贪心选择到探索决策:基于强化学习的多样性排序相关推荐
- 基于强化学习的多战机同SEAD联合作战空战辅助决策(改进版)
基于强化学习的多战机同SEAD联合作战空战辅助决策(改进版) 1.基础知识 这部分的基础知识可以参考以前的博文:基于强化学习的多战机同SEAD联合作战空战辅助决策 2.之前的工作 之前运用强化学习的知 ...
- 【实践】基于强化学习的 Contextual Bandits 算法在推荐场景中的应用
文章作者:杨梦月.张露露 内容来源:滴滴科技合作 出品平台:DataFunTalk 导读:本文是对滴滴 AI Labs 和中科院大学联合提出的 WWW 2020 Research Track 的 Or ...
- [论文]基于强化学习的无模型水下机器人深度控制
基于强化学习的无模型水下机器人深度控制 摘要 介绍 问题公式 A.水下机器人的坐标框架 B.深度控制问题 马尔科夫模型 A.马尔科夫决策 B.恒定深度控制MDP C.弯曲深度控制MDP D.海底追踪的 ...
- 论文浅尝-综述 | 基于强化学习的知识图谱综述
转载公众号 | 人工智能前沿讲习 论文来源:https://crad.ict.ac.cn/CN/10.7544/issn1000-1239.20211264 摘要:知识图谱是一种用图结构建模事物及事物 ...
- 让机器帮你做决策!强化学习在智能交互搜索的应用分享...
小叽导读:在时间就是金钱的时代,降低搜索时间成本,迅速找到目标产品具有重要意义.如今的电商平台已不仅仅是一个摆放商品的货架,"智能推荐"成为电商的一个重要功能.今天,我们来看看强化 ...
- 让机器帮你做决策!强化学习在智能交互搜索的应用分享
小叽导读:在时间就是金钱的时代,降低搜索时间成本,迅速找到目标产品具有重要意义.如今的电商平台已不仅仅是一个摆放商品的货架,"智能推荐"成为电商的一个重要功能.今天,我们来看看强化 ...
- 读书笔记 - 基于强化学习的城市交通信号控制方法研究 - 西电MaxPlus
<基于强化学习的城市交通信号控制方法研究> 针对TC-GAC交通信号控制方法中只考虑局部拥堵因子的缺陷,引入车辆目的车道的全局拥堵因子,实现了多交叉口控制器Agent之间的简单协作. 由于 ...
- 华为诺亚ICLR 2020满分论文:基于强化学习的因果发现算法
2019-12-30 13:04:12 人工智能顶会 ICLR 2020 将于明年 4 月 26 日于埃塞俄比亚首都亚的斯亚贝巴举行,不久之前,大会官方公布论文接收结果:在最终提交的 2594 篇论文 ...
- 王亚楠:基于强化学习的自动码率调节
本文来自 爱奇艺 技术产品中心 资深工程师 王亚楠在LiveVideoStackCon 2018热身分享,并由LiveVideoStack整理而成.在分享中,王亚楠分别介绍了自动码率调节的实现过程.现 ...
最新文章
- R语言系统自带及附属包开元可用数据集汇总
- C# 简单软件有效期注册的实现【原】
- 计算机科学与技术python方向是什么意思-2020年西京学院计算机科学与技术专业专业介绍...
- 闲话WPF之二六(WPF性能优化点)
- CCIE-LAB-第十五篇-IPV6-BGP+VPN6+RT
- OpenGL ES 加载3D模型
- 初识 Vue(10)---(计算属性的 setter 和 getter)
- 分解原理_葛兰维均线的数学拟合原理--傅立叶函数的分解的应用
- E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
- go 变量大写_golang学习笔记(一):包,变量,函数
- IDEA设置背景颜色(护眼色)
- Convert excel format exception.You can try specifying the ‘excelType‘ yourself
- 如何解决苹果Mac大写键CapsLock不能锁定大小写?
- 新浪股权分散是把双刃剑
- Oblog 2.52导出日志最新漏洞
- n维空间被m个n-1维的“刀”最多切出多少块
- php面包屑源码,推荐两款好用的WordPress面包屑插件
- android高德地图多个mark点击,Android ---------高德卫星地图绘制多个点和点的点击事件自定义弹窗...
- 【Latex 表格】换行+行高
- IBM Cloud Computing Practitioners 2019 (IBM云计算从业者2019)Exam答案
热门文章
- 《In Search of an Understandable Consensus Algorithm》翻译
- 实力剖析一个经典笔试题
- Android ADB 源码分析(三)
- 包与模块管理及面向对象初步
- JavaScript高级之ECMASript 7、8 、9 、10 新特性
- LeetCode 2207. 字符串中最多数目的子字符串(前缀和)
- LeetCode 2178. 拆分成最多数目的偶整数之和(等差数列求和)
- LeetCode 1752. 检查数组是否经排序和轮转得到
- LeetCode 1504. 统计全 1 子矩形(记录左侧的连续1的个数)
- 数据结构--单链表single linked list数据结构C++实现