利用卷积自编码器对图片进行降噪
前言
这周工作太忙,本来想更把 Attention tranlsation 写出来,但一直抽不出时间,等后面有时间再来写。我们这周来看一个简单的自编码器实战代码,关于自编码器的理论介绍我就不详细介绍了,网上一搜一大把。最简单的自编码器就是通过一个 encoder 和 decoder 来对输入进行复现,例如我们将一个图片输入到一个网络中,自编码器的 encoder 对图片进行压缩,得到压缩后的信息,进而 decoder 再将这个信息进行解码从而复现原图。
自编码器实际上是通过去最小化 target 和 input 的差别来进行优化,即让输出层尽可能地去复现原来的信息。由于自编码器的基础形式比较简单,对于它的一些变体也非常之多,包括 DAE,SDAE,VAE 等等,如果感兴趣的小伙伴可以去网上搜一下其他相关信息。
本篇文章将实现两个 Demo,第一部分即实现一个简单的 input-hidden-output 结的自编码器,第二部分将在第一部分的基础上实现卷积自编码器来对图片进行降噪。
工具说明
TensorFlow1.0
jupyter notebook
数据:MNIST 手写数据集
完整代码地址:NELSONZHAO/zhihu
第一部分
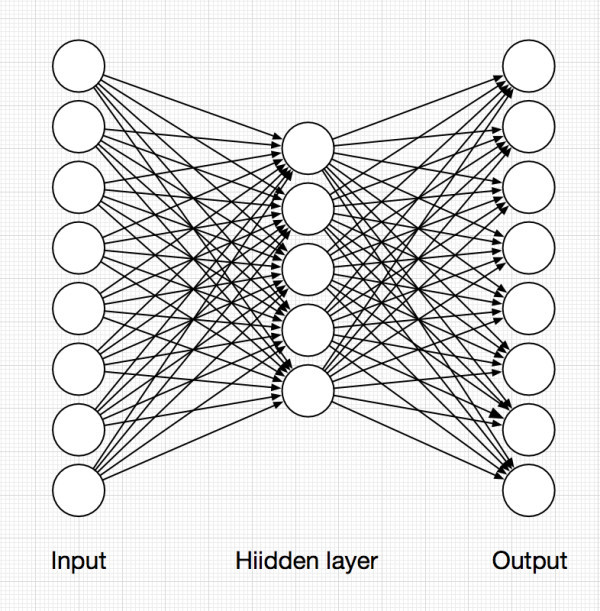
首先我们将实现一个如上图结构的最简单的 AutoEncoder。
加载数据
在这里,我们使用 MNIST 手写数据集来进行实验。首先我们需要导入数据,TensorFlow 已经封装了这个实验数据集,所以我们使用起来也非常简单。

如果想让数据显示灰度图像,使用代码 plt.imshow(img.reshape((28,28)), cmap='Greys_r') 即可。
通过 input_data 就可以加载我们的数据集。如果小伙伴本地已经有了 MNIST 数据集(四个压缩包),可以把这四个压缩包放在目录 MNIST_data 下,这样 TensorFlow 就会直接 Extract 数据,而不用再重新下载。我们可以通过 imshow 来随便查看一个图像。由于我们加载进来的数据已经被处理成一个 784 维度的向量,因此重新显示的时候需要 reshape 一下。
构建模型
我们把数据加载进来以后就可以进行最简单的建模。在这之前,我们首先来获取一下 input 数据的大小,我们加载进来的图片是 28x28 的像素块,TensorFlow 已经帮我们处理成了 784 维度的向量。同时我们还需要指定一下 hidden layer 的大小。

在这里我指定了 64,hidden_units 越小,意味着信息损失的越多,小伙伴们也可以尝试一下其他的大小来看看结果。
AutoEncoder 中包含了 input,hidden 和 output 三层。

在隐层,我们采用了 ReLU 作为激活函数。
至此,一个简单的 AutoEncoder 就构造完成,接下来我们可以启动 TensorFlow 的 graph 来进行训练。

训练结果可视化
经过上面的步骤,我们构造了一个简单的 AutoEncoder,下面我们将对结果进行可视化看一下它的表现。

这里,我挑选了测试数据集中的 5 个样本来进行可视化,同样的,如果想观察灰度图像,指定 cmap 参数为'Greys_r'即可。上面一行为 test 数据集中原始图片,第二行是经过 AutoEncoder 复现以后的图片,可以很明显的看到像素信息的损失。
同样,我们也可以把隐层压缩的数据拿出来可视化,结果如下:

这五张图分别对应了 test 中五张图片的隐层压缩后的图像。
通过上面一个简单的例子,我们了解了 AutoEncoder 的基本工作原理,下面我们将更进一步改进我们的模型,将隐层转换为卷积层来进行图像降噪。
上面过程中省略了一部分代码,完整代码请去我的 GitHub 上查看。
第二部分
在了解了上面 AutoEncoder 工作原理的基础上,我们在这一部分将对 AutoEncoder 加入多个卷积层来进行图片的降噪处理。
同样的我们还是使用 MNIST 数据集来进行实验,关于数据导入的步骤不再赘述,请下载代码查看。在开始之前,我们先通过一张图片来看一下我们的整个模型结构:

我们通过向模型输入一个带有噪声的图片,在输出端给模型没有噪声的图片,让模型通过卷积自编码器去学习降噪的过程。
输入层

这里的输入层和我们上一部分的输入层已经不同,因为这里我们要使用卷积操作,因此,输入层应该是一个 height x width x depth 的一个图像,一般的图像 depth 是 RGB 格式三层,这里我们的 MNIST 数据集的 depth 只有 1。
Encoder 卷积层
Encoder 卷积层设置了三层卷积加池化层,对图像进行处理。

第一层卷积中,我们使用了 64 个大小为 3 x 3 的滤波器(filter),strides 默认为 1,padding 设置为 same 后我们的 height 和 width 不会被改变,因此经过第一层卷积以后,我们得到的数据从最初的 28 x 28 x 1 变为 28 x 28 x 64。
紧接着对卷积结果进行最大池化操作(max pooling),这里我设置了 size 和 stride 都是 2 x 2,池化操作不改变卷积结果的深度,因此池化以后的大小为 14 x 14 x 64。
对于其他卷积层不再赘述。所有卷积层的激活函数都是用了 ReLU。
经过三层的卷积和池化操作以后,我们得到的 conv3 实际上就相当于上一部分中 AutoEncoder 的隐层,这一层的数据已经被压缩为 4 x 4 x 32 的大小。
至此,我们就完成了 Encoder 端的卷积操作,数据维度从开始的 28 x 28 x 1 变成了 4 x 4 x 32。
Decoder 卷积层
接下来我们就要开始进行 Decoder 端的卷积。在这之前,可能有小伙伴要问了,既然 Encoder 中都已经把图片卷成了 4 x 4 x 32,我们如果继续在 Decoder 进行卷积的话,那岂不是得到的数据 size 越来越小?所以,在 Decoder 端,我们并不是单纯进行卷积操作,而是使用了 Upsample(中文翻译可以为上采样)+ 卷积的组合。
我们知道卷积操作是通过一个滤波器对图片中的每个 patch 进行扫描,进而对 patch 中的像素块加权求和后再进行非线性处理。举个例子,原图中我们的 patch 的大小假如是 3 x 3(说的通俗点就是一张图片中我们取其中一个 3 x 3 大小的像素块出来),接着我们使用 3 x 3 的滤波器对这个 patch 进行处理,那么这个 patch 经过卷积以后就变成了 1 个像素块。在 Deconvolution 中(或者叫 transposed convolution)这一过程是反过来的,1 个像素块会被扩展成 3 x 3 的像素块。
但是 Deconvolution 有一些弊端,它会导致图片中出现 checkerboard patterns,这是因为在 Deconvolution 的过程中,滤波器中会出现很多重叠。为了解决这个问题,有人提出了使用 Upsample 加卷积层来进行解决。
关于 Upsample 有两种常见的方式,一种是 nearest neighbor interpolation,另一种是 bilinear interpolation。
本文也会使用 Upsample 加卷积的方式来进行 Decoder 端的处理。

在 TensorFlow 中也封装了对 Upsample 的操作,我们使用 resize_nearest_neighbor 对 Encoder 卷积的结果 resize,进而再进行卷积处理。经过三次 Upsample 的操作,我们得到了 28 x 28 x 64 的数据大小。最后,我们要将这个结果再进行一次卷积,处理成我们原始图像的大小。

最后一步定义 loss 和 optimizer。

loss 函数我们使用了交叉熵进行计算,优化函数学习率为 0.001。
构造噪声数据
通过上面的步骤我们就构造完了整个卷积自编码器模型。由于我们想通过这个模型对图片进行降噪,因此在训练之前我们还需要在原始数据的基础上构造一下我们的噪声数据。

我们通过上面一个简单的例子来看一下如何加入噪声,我们获取一张图片的数据 img(大小为 784),在它的基础上加入噪声因子乘以随机数的结果,就会改变图片上的像素。接着,由于 MNIST 数据的每个像素数据都被处理成了 0-1 之间的数,所以我们通过 numpy.clip 对加入噪声的图片进行 clip 操作,保证每个像素数据还是在 0-1 之间。
np.random.randn(*img.shape) 的操作等于 np.random.randn(img.shape[0], img.shape[1])
我们下来来看一下加入噪声前后的图像对比。

训练模型
介绍完模型构建和噪声处理,我们接下来就可以训练我们的模型了。

在训练模型时,我们的输入已经变成了加入噪声后的数据,而输出是我们的原始没有噪声的数据,主要要对原始数据进行 reshape 操作,变成与 inputs_相同的格式。由于卷积操作的深度,所以模型训练时候有些慢,建议使用 GPU 跑。
记得最后关闭 sess。
结果可视化
经过上面漫长的训练,我们的模型终于训练好了,接下来我们就通过可视化来看一看模型的效果如何。

可以看到通过卷积自编码器,我们的降噪效果还是非常好的,最终生成的图片看起来非常顺滑,噪声也几乎看不到了。
有些小伙伴可能就会想,我们也可以用基础版的 input-hidden-output 结构的 AutoEncoder 来实现降噪。因此我也实现了一版用最简单的 input-hidden-output 结构进行降噪训练的模型(代码在我的 GitHub)。我们来看看它的结果:

可以看出,跟卷积自编码器相比,它的降噪效果更差一些,在重塑的图像中还可以看到一些噪声的影子。
结尾
至此,我们完成了基础版本的 AutoEncoder 模型,还在此基础上加入卷积层来进行图片降噪。相信小伙伴对 AntoEncoder 也有了一个初步的认识。
完整的代码已经放在我的 GitHub(NELSONZHAO/zhihu) 上,其中包含了六个文件:
BasicAE,基础版本的 AutoEncoder(包含 jupyter notebook 和 html 两个文件)
EasyDAE,基础版本的降噪 AutoEncoder(包含 jupyter notebook 和 html 两个文件)
ConvDAE,卷积降噪 AutoEncoder(包含 jupyter notebook 和 html 两个文件)
如果觉得不错,可以给我的 GitHub 点个 star 就更好啦!
作者:天雨粟
来源:51CTO
利用卷积自编码器对图片进行降噪相关推荐
- 干货|利用卷积自编码器对图片进行降噪
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 前言: 这周工作太忙,本来想更把Attention tranlsa ...
- 视觉进阶 | 用于图像降噪的卷积自编码器
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 本文转自:磐创AI 作者|Dataman 编译|Arno 来源|A ...
- 用于图像降噪的卷积自编码器
这篇文章的目的是介绍关于利用自动编码器实现图像降噪的内容. 在神经网络世界中,对图像数据进行建模需要特殊的方法.其中最著名的是卷积神经网络(CNN或ConvNet)或称为卷积自编码器.并非所有的读者都 ...
- 卷积自编码器(Convolutional Autoencoder)的一个实验
1.卷积自编码器(CAE)的简单介绍 卷积自编码器是自编码器方法的一种延伸,自编码器包括编码和解码,通过将输入的图像进行编码,特征映射到隐层空间,然后解码器对隐层空间的特征进行解码(重建的过程)获得输 ...
- [自编码器:理论+代码]:自编码器、栈式自编码器、欠完备自编码器、稀疏自编码器、去噪自编码器、卷积自编码器
写在前面 因为时间原因本文有些图片自己没有画,来自网络的图片我尽量注出原链接,但是有的链接已经记不得了,如果有使用到您的图片,请联系我,必注释. 自编码器及其变形很多,本篇博客目前主要基于普通自编码器 ...
- 【GNN】VGAE:利用变分自编码器完成图重构
今天学习的是 Thomas N. Kipf 的 2016 年的工作<Variational Graph Auto-Encoders>,目前引用量为 260 多. VGAE 属于图自编码器, ...
- 利用卷积神经网络对脑电图解码及可视化
目录 Part 1 导读 Part 2 网络结构 Part 3 实验结果 本分享为脑机学习者Rose整理发表于公众号:脑机接口社区 .QQ交流群:941473018 Part 1 导读 研究人员应用卷 ...
- DL之AlexNet:利用卷积神经网络类AlexNet实现猫狗分类识别(图片数据增强→保存h5模型)
DL之AlexNet:利用卷积神经网络类AlexNet实现猫狗分类识别(图片数据增强→保存h5模型) 目录 利用卷积神经网络类AlexNet实现猫狗分类识别(图片数据增强→保存h5模型) 设计思路 处 ...
- DL之CNN:利用卷积神经网络算法(2→2,基于Keras的API-Functional)利用MNIST(手写数字图片识别)数据集实现多分类预测
DL之CNN:利用卷积神经网络算法(2→2,基于Keras的API-Functional)利用MNIST(手写数字图片识别)数据集实现多分类预测 目录 输出结果 设计思路 核心代码 输出结果 下边两张 ...
- DL之CNN:利用卷积神经网络算法(2→2,基于Keras的API-Sequential)利用MNIST(手写数字图片识别)数据集实现多分类预测
DL之CNN:利用卷积神经网络算法(2→2,基于Keras的API-Sequential)利用MNIST(手写数字图片识别)数据集实现多分类预测 目录 输出结果 设计思路 核心代码 输出结果 1.10 ...
最新文章
- Linux下计划任务和标准化工作流程
- Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AV
- NumericUpDown 控件输入限制小数位
- 嵌入式工程师必读100本专业书籍
- mysql 引起服务器死机_MSSQL数据库占用内存过大造成服务器死机问题的解决方法...
- python os模块详细_Python文件系统功能--os模块详解
- [詹兴致矩阵论习题参考解答]习题3.6
- css3 渐变色 3种,css3实现渐变色文字的三种方法
- EOJ_1015_查字典
- 前端 JS 如何在一个页面中局部加载其它页面的数据
- C++从0到1的入门级教学(十二)——运算符重载
- vue 相关技术文章集锦
- python解密_Python解密
- QML笔记-对QML中信号与槽的基本认识
- c语言随机读写信息fetch,北京大学信息科学技术学院考试试卷-计算机系统导论-期中-2015(16页)-原创力文档...
- linux mpc8313启动流程,基于MPC8313E和FPGA的双口RAM驱动开发
- 联合主键使用in和not in
- java getreturntype_java.lang.reflect.Method.getGenericReturnType()方法示例
- 10 种最流行的 Web 挖掘工具
- Mellanox网卡不能分配VF解决方法