如何实现降维处理(R语言)
转载自:http://f.dataguru.cn/thread-303589-1-1.html
现实世界中数据一般都是复杂和高维的,比如描述一个人,有姓名、年龄、性别、受教育程度、收入、地址、电话等等几十种属性,如此多的属性对于数据分析是一个严重的挑战,除了极大增加建模的成本和模型的复杂度,往往也会导致过拟合问题,因此在实际处理过程中,一些降维的方法是必不可少,其中用的比较多的有主成分分析(PCA)、奇异值分解(SVD)、特征选择(Feature Select),本文将对PCA和SVD作简单的介绍,并力图通过案例加深对这两种降维方法的理解。
1 主成分分析PCA
1.1 R语言案例
在R语言中PCA对应函数是princomp,来自stats包。以美国的各州犯罪数据为对象进行分析,数据集USArrests在graphics包中。
- > library(stats) ##princomp
- > head(USArrests)
- Murder Assault UrbanPop Rape
- Alabama 13.2 236 58 21.2
- Alaska 10.0 263 48 44.5
- Arizona 8.1 294 80 31.0
- > summary(pc.cr <- princomp(USArrests, cor = TRUE))
- ##每个主成分对方差的贡献比例,显然Comp.1 + Comp2所占比例超过85%,因此能够用前两个主成分来表示整个数据集,也将数据从4维降到两维
- Importance of components:
- Comp.1 Comp.2 Comp.3 Comp.4
- Standard deviation 1.5748783 0.9948694 0.5971291 0.41644938
- Proportion of Variance 0.6200604 0.2474413 0.0891408 0.04335752
- Cumulative Proportion 0.6200604 0.8675017 0.9566425 1.00000000
- 接下来查看每个特征在主成分中所在的比例
- > loadings(pc.cr)
- Loadings:
- Comp.1 Comp.2 Comp.3 Comp.4
- Murder -0.536 0.418 -0.341 0.649
- Assault -0.583 0.188 -0.268 -0.743
- UrbanPop -0.278 -0.873 -0.378 0.134
- Rape -0.543 -0.167 0.818
- Comp.1 Comp.2 Comp.3 Comp.4
- SS loadings 1.00 1.00 1.00 1.00
- Proportion Var 0.25 0.25 0.25 0.25
- Cumulative Var 0.25 0.50 0.75 1.00
- 根据以上数据可很容易转换为几个数学等式:
- Comp1 = -0.536 * Murder + (-0.583) * Assault + (-0.278)*UrbanPop + (-0.543)* Rape
- Comp2 = 0.418 * Murder + 0.188 * Assault + (-0.873)*UrbanPop + (-0.167)* Rape
- 可以用Comp1、Comp2两个维度的数据来表示各州,在二维图上展现各州个聚类关系。
- > head(pc.cr$scores) ##scores包含有各州在四个主成分的得分
- Comp.1 Comp.2 Comp.3 Comp.4
- Alabama -0.98556588 1.13339238 -0.44426879 0.156267145
- Alaska -1.95013775 1.07321326 2.04000333 -0.438583440
- Arizona -1.76316354 -0.74595678 0.05478082 -0.834652924
- Arkansas 0.14142029 1.11979678 0.11457369 -0.182810896
- California -2.52398013 -1.54293399 0.59855680 -0.341996478
- ##将前两个Comp提取出来,转换为data.frame方便会面绘图
- > stats.arrests <- data.frame(pc.cr$scores[, -c(3:4)])
- > head(stats.arrests)
- Comp.1 Comp.2
- Alabama -0.9855659 1.1333924
- Alaska -1.9501378 1.0732133
- Arizona -1.7631635 -0.7459568
- > library(ggplot2)
- ##展现各州的分布情况,观察哪些州比较异常,哪些能够进行聚类
- > ggplot(stats.arrests, aes(x = Comp.1, y = Comp.2)) +
- + xlab("First Component") + ylab("Second Component") +
- + geom_text(alpha = 0.75, label = rownames(stats.arrests), size = 4)
复制代码
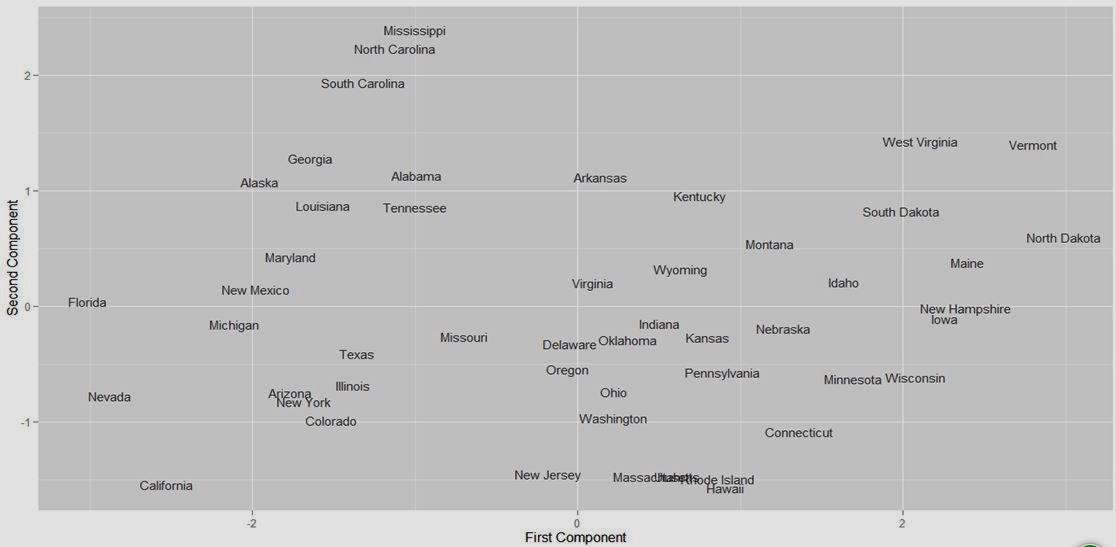
有兴趣的同学还可以,分析南北各州在犯罪数据上的迥异。
1.2 PCA理论基础
经过上一小节对PCA的简单应用,应该可以体会到PCA在降维处理上的魅力,下面简单介绍PCA的理论基础,对于更好的理解和应用PCA会非常有帮助。
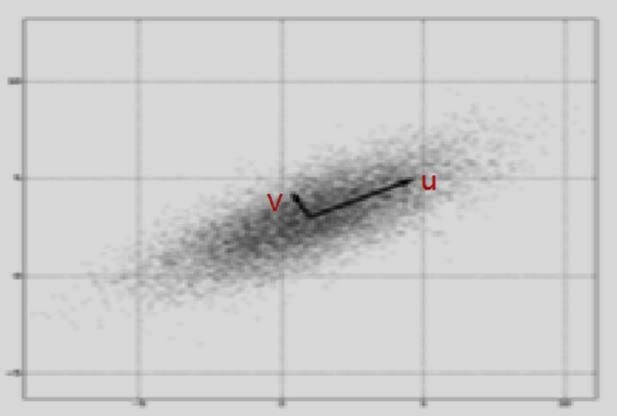
PCA本质就是将数据投影在众多正交向量上,根据投影后数据的方差大小,说明向量解释数据的程度,方差越大,解释的程度越大。以下图为例,数据投影在向量u的方差明显最大,因此u向量作为第一主成分,与u向量正交的v向量,作为第二主成分。
Nd = dim(data) 代表数据的维数, Sc = num(Comp)代表主成分的个数(Nd = Sc ),在实际情况中,往往取前k << Nd个主成分便能解释数据的方差程度超过90%,因此能够在只丢失少量消息的情况,达到大规模减少数据维度的效果,无论对于建立模型、提升性能、减少成本都有很大的意义。
从某种意义上讲,PCA只是将很多相互间存在线性关系的特征,转换成新的、相互独立的特征,从而减少特征数量。对此,它需要借助特征值来找到方差最大的主成分,每一个特征值对应一个特征向量,特征值越大,特征向量解释数据矩阵的方差的程度越高。因此,只需要将特征值从大到小排列,取出前k个特征向量,便能确定k个最重要的主成分。
PCA算法通常包括如下5个步骤:
A 平均值归一化,减去每个特征的平均值,保证归一化后的数据平均值为0
B 计算协方差矩阵,每两个特征之间的协方差
C 计算协方差矩阵的特征向量和特征值
D 将特征向量根据对应的特征值大小降序排列,特征向量按列组成FeatureVector = (eig_1, eig_2, …,eig_n)
E RowFeatureVector = t(FeatureVector) (转置),eig_1变为第一行,RowDataAdjusted = t(DataAdjusted), 特征行变为列,得到最终的数据。
FinalData = RowFeatureVector X RowDataAdjusted
从维度变化的角度出发
协方差矩阵:n x n , FeatureVector: n x n,RowFeatureVector:n x n, n为特征数量
DataAdjusted:m x n, RowDataAdjusted: n x m
取前k个特征向量, RowFeatureVector:k x n
那么FinalData: k x m, 这样便实现维度的降低。
2 奇异值分解(SVD)
2.1 案例研究
我们通过一张图片的处理来展示奇异值分解的魅力所在,对于图片的处理会用到R语言中raster和jpeg两个包。
- ##载入图片,并且显示出来
- > library(raster)
- Loading required package: sp
- > library(jpeg)
- > raster.photo <- raster("Rlogo.jpg")
- > photo.flip <- flip(raster.photo, direction = "y")
- ##将数据转换为矩阵形式
- > photo.raster <- t(as.matrix(photo.flip))
- > dim(photo.raster)
- [1] 288 196
- > image(photo.raster, col = grey(seq(0, 1, length = 256))) ##灰化处理
复制代码

- ##奇异值进行分解
- > photo.svd <- svd(photo.raster)
- > d <- diag(photo.svd$d)
- > v <- as.matrix(photo.svd$v)
- > u <- photo.svd$u
- 取第一个奇异值进行估计,如下左图
- > u1 <- as.matrix(u[, 1])
- > d1 <- as.matrix(d[1, 1])
- > v <- as.matrix(v[, 1])
- > photo1 <- u1 %*% d1 %*% t(v)
- > image(photo1, col = grey(seq(0, 1, length = 256)))
复制代码

取前五十个奇异值进行模拟,基本能还原成最初的模样,如上右图
- > u2 <- as.matrix(u[, 1:50])
- > d2 <- as.matrix(d[1:50, 1:50])
- > v2 <- as.matrix(v[, 1:50])
- > photo2 <- u2 %*% d2 %*% t(v2)
- > image(photo2, col = grey(seq(0, 1, length = 256)))
复制代码
当我们尝试用更多的奇异值模拟时,会发现效果越来来越好,这就是SVD的魅力,对于降低数据规模、提高运算效率、节省存储空间有着非常棒的效果。原本一张图片需要288 X 196的存储空间,经过SVD处理后,在保证图片质量的前提下,只需288 X 50 + 50 X 50 + 196 X 50的存储空间仅为原来的一半。
2.1 SVD理论基础
SVD算法通过发现重要维度的特征,帮助更好的理解数据,从而在数据处理过程中减少不必要的属性和特征,PCA(主成分分析)只是SVD的一个特例。PCA针对的正方矩阵(协方差矩阵),而SVD可用于任何矩阵的分解。
对于任意m x n矩阵A,都有这样一个等式
Am x n = Um x r Sr x r VTn x r
U的列称为左奇异向量,V的列称为右奇异向量,S是一个对角线矩阵,对角线上的值称为奇异值, r = min(n, m)。U的列对应AAT的特征向量,V的列则是ATA的特征向量,奇异值是AAT和ATA共有特征值的开方。由于A可能不是正方矩阵,因此无法利用得到特征值和特征向量,因此需要进行变换,即AAT(m x m)和ATA(n x n),这样就可以计算特征向量和特征值了。
A = USVT AT = VSUT
AAT = USVT VSUT = US2UT
AAT U = U S2
同样可以推导出: ATA V = V S2
总结下来,SVD算法主要有六步:
A 、计算出AAT
B 、计算出AAT的特征向量和特征值
C、计算出ATA
D 、计算出ATA的特征向量和特征值
E、计算ATA和ATA共有特征值的开方
F、计算出U、 S、 V
3 参考资料
[1] http://www.di.fc.ul.pt/~jpn/r/svd/svd.html
[2] http://www.puffinwarellc.com/index.php/news-and-articles/articles/30-singular-value-decomposition-tutorial.html
[3] http://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Dimensionality_Reduction
[4] http://en.wikipedia.org/wiki/Principal_component_analysis
转自:http://futureindata.blogspot.com/2014/02/r.html
如何实现降维处理(R语言)相关推荐
- R语言分析蛋白质组学数据:飞行时间质谱(MALDI-TOF)法、峰值检测、多光谱比较...
全文链接:http://tecdat.cn/?p=30051 •研究生物体产生的全部蛋白质. • Foci:鉴定.结构测定.生物标志物.通路.表达(点击文末"阅读原文"获取完整代码 ...
- R语言plotly可视化:使用PCA算法进行数据降维、使用plotly可视化随着主成分的增加解释的方差的量(plotting explained variance)
R语言plotly可视化:使用PCA算法进行数据降维.使用plotly可视化随着主成分的增加解释的方差的量(plotting explained variance) 目录
- R语言plotly可视化:使用PCA算法进行数据降维、使用plotly可视化PCA所有的主成分绘制散点图矩阵、降维后的两个(三个)核心主成分的二维、三维可视化图形、方差解释的量、载荷图等
R语言plotly可视化:使用PCA算法进行数据降维.使用plotly可视化PCA所有的主成分绘制散点图矩阵.降维后的两个(三个)核心主成分的二维.三维可视化图形.方差解释的量.载荷图等 目录
- R语言使用Rtsne包进行TSNE分析:提取TSNE分析结果合并到原dataframe中、可视化tsne降维的结果、并圈定降维后不匹配的数据簇(tSNE identifying mismatch)
R语言使用Rtsne包进行TSNE分析:提取TSNE分析结果合并到原dataframe中.可视化tsne降维的结果.并使用两个分类变量从颜色.形状两个角度来可视化tsne降维的效果.并圈定降维后不匹配 ...
- 【视频】主成分分析PCA降维方法和R语言分析葡萄酒可视化实例|数据分享
最近我们被客户要求撰写关于主成分分析PCA的研究报告,包括一些图形和统计输出.降维技术之一是主成分分析 (PCA) 算法,该算法将可能相关变量的一组观察值转换为一组线性不相关变量.在本文中,我们将讨论 ...
- R语言主成分回归(PCR)、 多元线性回归特征降维分析光谱数据和汽车油耗、性能数据...
原文链接:http://tecdat.cn/?p=24152 什么是PCR?(PCR = PCA + MLR)(点击文末"阅读原文"获取完整代码数据). • PCR是处理许多 x ...
- R语言主成分分析PCA谱分解、奇异值分解预测分析运动员表现数据和降维可视化
最近我们被客户要求撰写关于主成分分析PCA的研究报告,包括一些图形和统计输出. 本文描述了如何 使用R执行主成分分析 ( PCA ).您将学习如何 使用 PCA预测 新的个体和变量坐标.我们还将提供 ...
- R语言辅导高维数据的主成分pca、 t-SNE算法降维与可视化分析案例报告
降低维度有两个主要用例:数据探索和机器学习.它对于数据探索很有用,因为维数减少到几个维度(例如2或3维)允许可视化样本.然后可以使用这种可视化来从数据获得见解(例如,检测聚类并识别异常值).对于机器学 ...
- R语言学习_数据降维
纬度灾难 变量过多(没用的变量) 变量相关(相关的变量) 解决办法 剔除无用变量 逐步回归 向前引入法 向后剔除法 逐步筛选法 Step函数 AIC越小越好 AIC = n ln(SSE) + 2p ...
最新文章
- CSS3 里添加自定义字体
- python magic文档
- 2016谷歌官方最新eclipse工程导入studio,以前方式全部废弃。不能再使用。
- 分区变为RAW的解决办法
- Pytorch —— 权值初始化
- 2小时c++与ros教学
- delphi的 PosEx 函数功能介绍
- elm预测matlab,机器学习——极限学习(ELM)matlab代码分析
- C++ Struct和Union区别
- 我是如何2小时弄出房产网站小程序的?
- 不要着急改代码,先想想--centos 6.8下编译安装tmux
- 怎么批量修改文件夹名称?
- 彻底禁用UAC,解决“Windows 8/10 Administrator须以管理员身份运行才有权限”的问题
- 创意 博客思听 偶有所得
- C语言中“=,^=,|=”分别表示什么意
- xbox sdk_因此,您只是获得了Xbox Xbox。 怎么办?
- 建筑行业为什么要数字化转型?
- 原生HTML+CSS+JS制作自己的导航主页(前端大作业,源码+步骤详解)
- mysql创建学生信息表学号_mysql创建学生信息表
- 泛谈移动互联时代的交互设计师