(详细)强化学习--贝尔曼方程
原文链接:https://zhuanlan.zhihu.com/p/86525700
我有一个疑问,就是在推导过程中,状态s不是变量,st 是t阶段的状态相当于是一个常数,那么为什么st=s,常数在等号的左边,变量在等号的右边?
这里的st表示的是t时刻对应的状态,状态可能有多种,但是这里设t时刻的状态为s,所以st=s。比如说放学回家,你一共有三种状态,写作业、看电视、打游戏,在某一时刻(这里可以对应t)你的状态是什么,即st得状态。st得状态可以是写作业(状态s1)、看电视(状态s2)、打游戏(状态s3)。st=s1表示t时刻你的状态是你正在写作业
Bellman方程
Bellman方程是强化学习的基础和核心,在介绍强化学习的概念及应用时我们必须对贝尔曼方程有个全面的了解,不然后面的只是将很难理解和掌握,所以在这里我们首先介绍Bellman方程的基础知识。
首先我们需要弄清楚贝尔曼方程的三个主要概念,策略函数、状态价值函数、状态-动作价值函数(简称为动作价值函数)[1]。
策略函数(Policy Function):策略函数是一个输入为s输出为a的函数表示为 ,其中s表示状态,a表示动作,策略函数的含义就是在状态s下应该选择的动作a。强化学习的核心问题就是最优化策略函数从而最大化后面介绍的价值函数。
状态价值函数(State Value Function):前面说过强化学习的核心问题是最优化策略函数,那么如何评价策略函数是最优的呢?状态价值函数是评价策略函数 优劣的标准之一,在每个状态s下(
,
为所有状态的集合),可以有多个动作a选择(
,
为所有动作的集合),每执行一次动作,系统就会转移到另一个状态(状态有时有多个可能,每种状态都有一个概率转移到就是下文的
),如何保证所有的动作能使系统全局最优则要定义价值函数,系统的状态价值函数的含义是从当前状态开始到最终状态时系统所获得的累加回报的期望,下一状态的选取依据策略函数(不同的动作a将导致系统转移到不同的状态)。所以系统的状态价值函数和两个因素有关,一个是当前的状态s,另一个是策略
。从不同的状态出发,得到的值可能不一样,从同一状态出发使用不同的策略,最后的值也可能不一样。所以建立的状态价值函数一定是建立在不同的策略和起始状态条件下的。状态价值函数的具体形式如下:
其中 ,其中
表示从
转移到
时获得的回报,
是折损因子,取值为
。可以将上面的状态价值函数的形式表示为递归的形式:
其中 表示在选择动作a时,状态由s转移到
的概率,这里要注意,选定了动作之后不代表后面的状态就确定了,根据概率可能有好几种状态可以转移到,如后面的赌徒问题。但是也存在动作确定后,后面只有一种转移可能,这个时候
。下面用赌徒问题和方格世界的例子来说明这个概念。
例1:赌徒问题[2]
一个赌徒利用硬币投掷的反正面结果来赌博。假如投掷结果是硬币的正面朝上,那么他就赢得他所压的赌注,如果是反面朝上,那么他输掉他的赌注。当这个赌徒赢满100美元或者他输掉他所有的钱时,赌博结束。每一轮投掷,赌徒必须取出他资金的一部分作为赌注,赌注金额必须是整数。这个问题可以表述为一个无折扣的、情节式的有穷马尔可夫决策过程。状态就是赌徒所拥有的资金, ,动作就是下赌注,
。
这里的每个动作a就对应2各状态,如当前状态 ,
,设赌徒每局输赢的概率都为0.5,则下一状态为
的概率为0.5,下一状态为
的概率也为0.5。
例2:方格世界
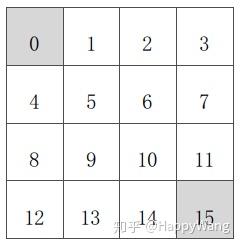
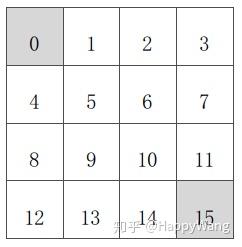
如图有个 的方格,每个方格都对应一个状态,共有16个状态,每个状态下对应4个动作
A={上,下,左,右 },当当前状态确定,动作确定之后对应的下一个状态也就确定了。
状态动作价值函数(State-action Value Function):动作价值函数也称为Q函数,相比于Value Function是对状态的评估,Q Function是对(状态-动作对)的评估,Q值的定义是,给定一个状态 ,采取动作
后,按照某一策略
与环境继续进行交互,得到的累计汇报的期望值。其数学表达形式是:
对于状态价值函数和动作价值函数的区别,可以简单的认为,状态函数中,当前状态下选取哪个动作是未知数,需要求出一系列的动作集合(各不同状态下),形成一个完整的策略,然后使状态方程的值最大化,而动作价值函数是当前状态下的动作已知,求余下状态下的动作集合使动作方程的值最大化,具体数学形式如下:
动作和状态价值函数的关系
前面我们简单的将状态价值函数和状态-动作价值函数的关系描述为状态价值函数在当前状态的动作是不确定的, 所以它必须考虑到所用动作的情况然后取其期望,而状态-动作价值函数只是考虑特定的动作下的价值。最大化状态价值函数就是求当前状态的最大期望值,而最大化状态-动作价值函数就是求当前状态下一动作能带来的最大回报值,用数学的形式表示如下:
将公式(1-2)进一步化简可得:
从上式可以看出状态方程比动作方程考虑了所有动作的情况。
注意:
这里需要注意几个表示价值的符号的意义, 。
表示的是在状态s下,执行动作a的情况下状态转移到s'时得到的即时奖励。
下面举个例子说明状态价值函数和状态动作价值函数的含义[3]:
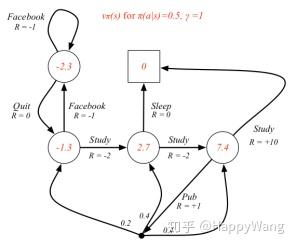
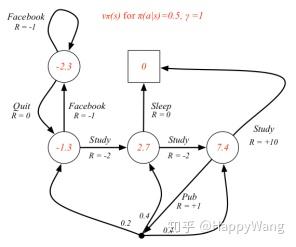
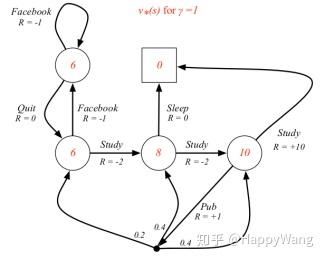
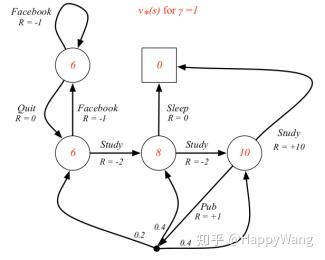
如图2所示,是计算各状态价值的过程,其中设每一个状态下执行某个动作的概率都为0.5,即 ,折损因子
,根据公式
进行迭代求解,这里箭头从一个圆直接连接到另一个圆表示执行某动作之后,其能到达的状态只有一种, ,而箭头连接点的分出去三个箭头,表示执行该动作,将有可能到达三种状态,且概率分别为0.2,0.4,0.4。图中,
表示的是
,以图中7.4值计算为例:
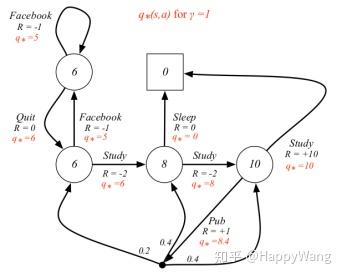
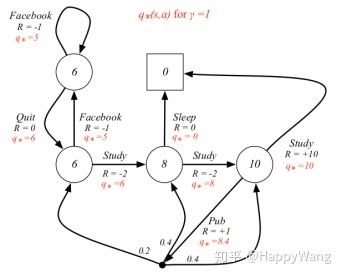
对应的状态-动作价值是指在某个状态选取某个特定动作时所获得的价值,如在上述取7.4的状态下,取动作为 的动作,此时a确定,
,根据公式:
求得, 。
当要求最大状态价值函数和最大状态价值函数时,就是取获得最大价值的动作进行选取,如下图所示:
参考
- ^贝尔曼方程推导 https://blog.csdn.net/hhy_csdn/article/details/89105908
- ^赌徒问题实验报告 https://wenku.baidu.com/view/d0253055312b3169a451a4f8.html
- ^马尔可夫决策过程 https://zhuanlan.zhihu.com/p/28084942
(详细)强化学习--贝尔曼方程相关推荐
- 强化学习-贝尔曼方程的推导
一.贝尔曼方程的推导 以下是贝尔曼方程的推导1,大家可能对14.18的推导很困惑.以下为大家解疑. 式14.15->14.16是最关键的. Vπ(s)V^{\pi}(s)Vπ(s)的含义是:最初 ...
- 【强化学习系列】超详细整理实用资料——1 强化学习概述(包含马尔科夫、贝尔曼方程、蒙特卡洛、时间差分法)
文章目录 前言 强化学习通用工作方式(敲重点!!) 几个重要概念 工作流程 模型通用设计要点(每个模型都需要注重的点) 强化学习适用场景 马尔科夫 马尔可夫链 马尔可夫随机过程 马尔可夫决策过程(敲重 ...
- 一文读懂AlphaGo背后的强化学习:它的背景知识与贝尔曼方程的原理
作者 | Joshua Greaves 译者 | 刘畅,林椿眄 本文是强化学习名作--"Reinforcement Learning: an Introduction"一书中最为重 ...
- 强化学习之贝尔曼方程
强化学习 强化学习注重智能体(agent)与环境之间的交互式学习: 强化学习的数据集不是训练初始阶段就有的,而是来自智能体与环境交互才能获得: 强化学习不追求单步决策的最优策略,而是追求与环境交互 ...
- 什么是强化学习?(贝尔曼方程)
文章目录 什么是强化学习?(贝尔曼方程) 3.贝尔曼方程(Bellman equation) 3.1贝尔曼期望方程(Bellman expectation equation) 3.2 贝尔曼最优方程( ...
- 贝尔曼方程怎么解_强化学习系列(下):贝尔曼方程
在本文中,我们将学习贝尔曼方程和价值函数. 回报和返还(return) 正如前面所讨论的,强化学习agent如何最大化累积未来的回报.用于描述累积未来回报的词是返还,通常用R表示.我们还使用一个下标t ...
- 强化学习: 贝尔曼方程与马尔可夫决策过程
强化学习: 贝尔曼方程与马尔可夫决策过程 一.简介 贝尔曼方程和马尔可夫决策过程是强化学习非常重要的两个概念,大部分强化学习算法都是围绕这两个概念进行操作.尤其是贝尔曼方程,对以后理解蒙特卡洛搜索.时 ...
- 强化学习 - 详细解读DQN(更新完成)
详细解读DQN 一. 强化学习 1. 什么是强化学习问题? 2. 强化学习的理论体系 (1) MDP i) Markov Property ii) Markov Process iii) Markov ...
- 强化学习介绍和马尔可夫决策过程详细推导
强化学习系列学习笔记,结合<UCL强化学习公开课>.<白话强化学习与PyTorch>.网络内容,如有错误请指正,一起学习! 强化学习基本介绍 强化学习的中心思想是让智能体在环境 ...
最新文章
- Python OOP知识积累
- webView 点击连接如何不让跳转到系统的 浏览器
- release8_如何在Windows 8 Release Preview中将Chrome用作Metro浏览器
- 浅谈javascript函数劫持
- bootstrap1
- 算法学习之路|最小生成树——prime算法
- 20172325 2018-2019-1 蓝墨云班课实验--哈夫曼树的编码
- mysql 查询若干小时之内的数据
- 手模手教你装 文能黑苹果,武可3A游戏大作的2400块主机
- Word VBA:MathType公式与Latex公式切换
- 如何在手机浏览器中实现条形码/QR码扫描
- cmd操作 以及几个常用快捷键
- php文字如何排版,文字排版,二十个文字排版技巧教程
- 新浪微博开放平台开发步骤简介(适合新手看)
- 地震数据剖面图-matlab
- 苹果6标准模式和放大模式具体有什么差别?
- android修改文件名,android 修改文件名称
- 冰雪之冠上的明珠与东方明珠 辉映在黄浦江两岸
- CAN总线控制器配置说明
- 【MybatisPlus】MP来实现一些特殊的查询