直击Titan图数据库:如何提升25%+的反欺诈检测效率?
传统的关系型数据库通过实体和关系来建模,在过去的很长一段时间内都占据着绝对的统治地位。但是随着大数据的兴起,它的一些缺陷也变得越来越明显,特别是在需要处理非常复杂的实体关系时,关系型数据库变得越来越力不从心。
当我们要表示实体间的多对多关系时,一般会建立关系表。当要看实体间的关系时,我们需要把这种关系再关联起来。这通常是一项非常消耗性能的工作,特别是在关系非常复杂或者关系层次很多的情况下,需要关联非常多的表,甚至产生非常巨大的中间结果,导致查询非常缓慢甚至跑不出来。
图数据库以图论为基础,数据本身以图的方式存储(比如邻接表),在处理与图相关的任务时占有先天的优势。所以目前在知识图谱,社交网络分析等领域开始有越来越多的应用。
常见的图形数据库
以下是三个比较流行的图数据库及各自的特性对比。

经过我们对比及试用的结果,OrientDB 和 Neo4j 使用比 Titan 都要简单,社区也更活跃。但是 Neo4j 最大的缺陷在于并非是真正的分布式,当数据量超过单机的承载能力以后很难处理;而且 Neo4j 和OrientDB 的底层存储都是自主研发,Titan 支持HBase/Cassandra 作为底层存储,跟我们目前主要的数据平台 Hadoop 能很好集成在一起;此外,Titan 除了支持 OLTP 操作以外,还可以跟 Spark 结合进行 OLAP 相关的分析。所以我们最终决定采用 Titan 。
Titan技术架构
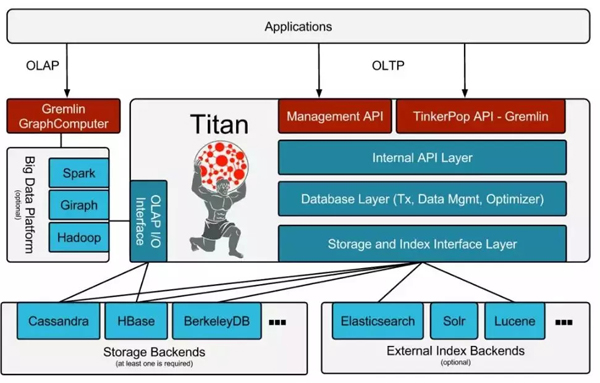
Titan 的总体技术架构如上所示,存储、索引、OLAP 的计算引擎都是开源的可选组件:
- 底层存储支持 HBase/Cassandra,所以存储是可以平行扩展的,几乎没有容量限制;
- 支持 Elasticsearch/Solr/Lucene 作为外部的索引插件,实现在进行非等值查询时也能利用到索引;
- Management API 负责 Schema 的创建,修改,删除及实例管理等操作;
- 通过 Tinkerpop API提供图上的操作接口;
- Internal API、Database Layer、Storage and Index Interface Layer负责将 Tinkerpop 和Management API 的图操作转换成底层存储 Cassandra 和 HBase 上的操作(比如HBase 中的put、get、scan)。
- GraphComputer 提供以 Spark/MR 的方式进行图上的 OLAP 操作,做子图或者全图上的分析(比如计算 Pagerank )。
Titan图的表示
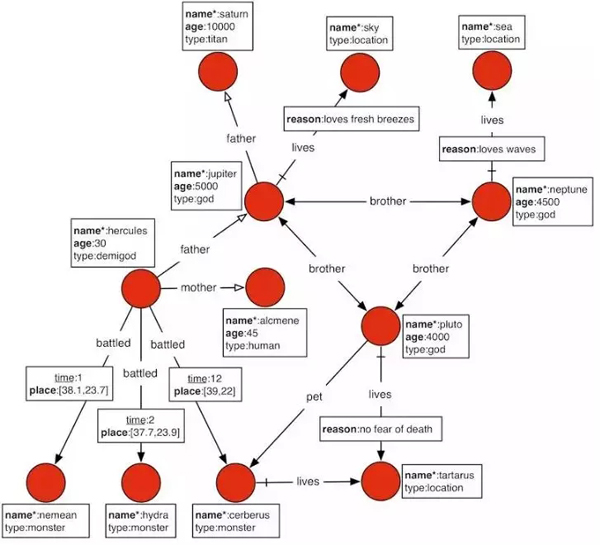
Titan用结点、边和属性三类信息来描述一个图,如上图所示。
结点(Vertex):用于表示一个实体,结点通过指定不同的标签(LABEL)来区别具体的实体类型,如Titan、Location;结点由唯一的 Vertex ID 标识,该ID由 Titan 自动生成并管理。
边(Edge):用于描述实体之前的关系,有出结点和入结点;边同样有标签(LABEL),用于区分边的类型,如上图所示的 father、lives;边带有方向;边可以指定是否只允许单向查询;边可以指定 MULTILICITY,表示该 LABEL 的边能存在几条;边也有唯一的 Edge ID,该ID由 Titan 自动生成及管理。
属性(property):既可以在结点上,也可以在边上,用于描述结点和边的附加信息;属性通过 PROPERTY KEY来表示该属性是什么属性,如上图所示 name、age、place;属性也可以指定 CARDILITY,用于表示该属性可以存在多个该属性;属性也有唯一的 Property ID,该 ID由 Titan自动生成及管理;对于结点和边上的属性都可以添加索引,这时通过属性来查询特定结点或者边的时候,可以直接通过索引定位到对应的结点或者边的 ID,减少扫描的数据量,提升性能。
Titan的图查询
Titan通过 Tinkerpop 的 Gremlin 语言提供图的查询、修改等操作。一个 Titan 实例对应的就是 Tinkerpop 的一个 Gremlin Server。多个对应相同存储后台的 Gremlin Server 组成了 Titan 的分布集式集群。用户可以通过 Gremlin Client 或者Restful API提交查询请求。
查询的例子如下:
- #创建一个集群
- gremlin> graph = TitanFactory.open('conf/titan-hbase.properties')
- ==>standardtitangraph[hbase:[titan003, titan004, titan005]]
- gremlin> g = graph.traversal()
- ==>graphtraversalsource[standardtitangraph[hbase:[titan003, titan004, titan005]], standard]
- #查询name为'saturn'的结点
- gremlin> saturn = g.V().has('name', 'saturn').next()
- ==>v[256]
- #查看saturn结点有哪些属性
- gremlin> g.V(saturn).valueMap()
- ==>[name:[saturn], age:[10000]]
- #saturn的祖父的姓名
- gremlin> g.V(saturn).in('father').in('father').values('name')
- ==>hercules
- #查询hercules的父母的信息
- gremlin> g.V(hercules).out('father', 'mother')
- ==>v[1024]
- ==>v[1792]
- gremlin> g.V(hercules).out('father', 'mother').values('name')
- ==>jupiter
- ==>alcmene
- gremlin> g.V(hercules).out('father', 'mother').label()
- ==>god
- ==>human
- gremlin> hercules.label()
- ==>demigod
Titan底层存储格式
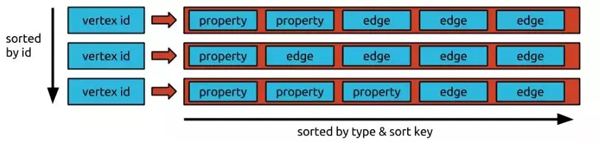
Titan 中的结点和边按照邻接表的方式组织,每个结点的邻接表包含该结点的所有相邻边和该结点的属性,存储上遵循Big Table Data Model。
也就是说,表由多行组成,每一行由很多的Cell组成,每个 Cell 由一个Column和Value组成。行由唯一的 Key 标识,每个 Cell 由 Key+column 标识。
Titan Layout:
Edge & Property Layout:
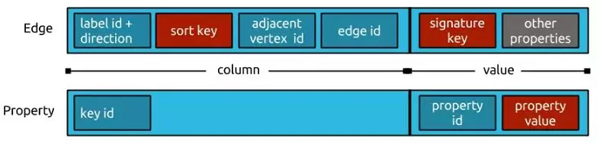
如上图所示,对于 Titan 的实现来说。每一行的 Key 就是结点的 Vertex ID,该 ID 是由 Titan自动维护的一个64bit长整型数。每个 Cell 就是结点的属性或者该结点相连的边。
边 Cell 的 Column 包含边的方向,边上指定的排序属性的信息,邻接点的ID, 边的ID; 边的 Value 包含边上的所有属性( Signature 属性在前)。
属性 Cell 的 Column 包含属性的类型 ID ; Value 包含属性的 ID 和属性的值。
拍拍贷图数据库应用
我们目前将用户信息、设备信息及社交关系构建了一个异构网络,并将该异构网络图应用在用户关联分析及反欺诈检测场景。
传统的方式上,我们的数据都是存储在RDMS上,要查询用户的关联关系时,都是通过关联多张表来实现。但这种方式存在很多的问题:
- 这些表相应都较大,在做表关联的时候效率非常低下;
- 对于关系的层次支持非常有限,出入度很大的结点,产生的中间结果会非常大;
- 对于图上的查询不够灵活。
这些都极大地限制了我们分析能力和分析效率。出于以上这些痛点,我们引入了 Titan 图形数据库。每天会通过改写的 Titan Bulkload 将10亿+结点信息和500亿+左右的关系数据导入Titan 后台 HBase 生成一张包含13类节点和15类边的复杂异构网络。
通过该网络,可以方便快速地回答以下类似问题:
- 和用户A关联的用户有哪些;
- 和用户A关联的用户有什么特征;
- 用户A和用户B怎么关联在一起的。
下图是我们将图数据库应用于反欺诈中的示例图:
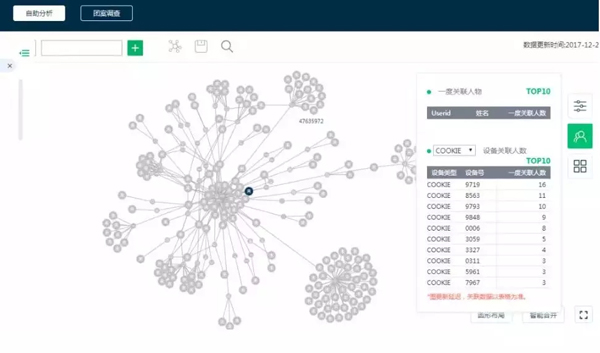
根据原始的数据图我们可以对用户做以下调查分析,来确定特定的用户是不是欺诈用户或者是不是与欺诈用户有关联:
- 通过特定规则筛选可疑用户
- 查看与可疑用户有特定关联的用户
- 查看与可疑用户有特定关联的所有用户组成的子网的网络特征及用户特征
- 分析特定用户可以通过什么样的关联关系关联在一起
- 最多可分析6层关联关系的数据
通过该方式,我们大大减少了调查过程中的工作量,整体效率提升了25%+。
作者介绍
冯锦明,拍拍贷高级数据工程专家。
http://database.51cto.com/art/201804/570147.htm
直击Titan图数据库:如何提升25%+的反欺诈检测效率?相关推荐
- 人人都在讨论图数据库,它到底好在哪——创邻科技
[摘要]图数据库不是存储图片的数据库,而是存储顶点与他们之间关系的数据库.与传统关系型数据库相比,图数据库的优势体现在直观性.灵活性.高性能等方面.图数据库支持多种图算法,可以应用于社交网络.金融欺诈 ...
- 图数据库应用:金融反欺诈实践
1 背景介绍 1.1 传统反欺诈技术面临挑战 数字技术与金融业的融合发展,也伴随着金融欺诈风险不断扩大,反欺诈形势严峻.数字金融欺诈逐渐表现出专业化.产业化.隐蔽化.场景化的特征,同传统的诈骗相比,数 ...
- neo4j(一).初识图数据库neo4j
neo4j是图数据库 初识neo4j,首先我们要知道neo4j是图数据库.我们平常用的数据库一般是RDBMS(关系型数据库),那么什么是图数据库呢?既然有了关系型数据库,那么为什么要有图数据库呢? 1 ...
- 常用的图数据库对比(Neo4j、FlockDB、AllegroGrap、GraphDB、InfiniteGraph、TITAN、OrientDb)
1.数据库分类: 传统的关系数据库和NoSQL数据库 传统的关系数据库:mySQL.oracle NoSQL数据库分为Graph,Document,Column Family.Key-Value St ...
- 图数据库的类别有哪些?解读:图数据库分类与原理
图数据库作为新兴NoSQL数据库的代表,可以分为四种类型.图数据库应用广泛,无论是互联网行业还是传统的金融.地产.医疗等行业,都可以通过图数据库的应用进一步提升企业效率.数易轩致力于图数据库技术服务, ...
- 中秋邀请共赏图数据库-蚂蚁集团图数据TuGraph 正式开源
目录 前言 1.五道口+蚂蚁集团的系统长什么样 2.性能拉满,能抗能打 优点: 缺点: 一.TuGraph,比关系数据库更懂关系 1.更懂关系的图数据TuGraph 2.图数据发展的三个阶段 2.1第 ...
- neo4j 图数据库初步调研 三元组、属性图、图模型、超图、RDF-f
相关文章 neo4j 图数据库初步调研 图数据库与关系型数据库差异 demo项目(python+vue) 本文目录 相关文章 一.技术关键字 二.前言 1.什么是图 2.反规范化 三.RDF(资源描述 ...
- 图模型在反欺诈中的应用
最近在研究图模型在反欺诈中的应用,综合整理相关资料.在目前的工作中,线上用的是fast unfoloding社区发现算法. 1.阿里团队公开了用无监督模型,防范信用卡欺诈(autoencoder)(非 ...
- 图数据库Titan安装与部署
Titan简介 Titan是一个分布式的图数据库,支持横向扩展,可容纳数千亿个节点和边. Titan支持事务,并且可以支撑上千用户并发进行复杂图遍历操作. Titan包含下面这些特性: 弹性与线性扩展 ...
最新文章
- Python itertools 操作迭代对象
- file_get_contents遍历api数据
- [Python图像处理] 三十八.OpenCV图像增强和图像去雾万字详解(直方图均衡化、局部直方图均衡化、自动色彩均衡化)
- An Openfire plugin for Webspell sites.
- 恕我直言,IDEA的Debug,你可能只用了10%
- linux 下设置定时任务
- 第三次学JAVA再学不好就吃翔(part10)--基础语法之if语句
- EL调用java方法
- 《Asp.Net 2.0 揭秘》读书笔记(九)
- python 两阶段聚类_Python,如何对多元时间序列进行聚类?
- vue表单实现输入框控制输入小数点后两位
- 乘坐飞机时,有什么事情是机长和机上工作人员不想让乘客知道的?
- 欺骗的艺术——你被社工了吗?
- c 语言基础笔试题1
- 电脑XP系统开机速度变慢12种解决办法
- 通过注册表禁用系统服务
- HanLP《自然语言处理入门》笔记--2.词典分词
- torch.load()出现ModuleNotFoundError错误
- 抖音很火的公众号表白,每天定时发送给自己的女朋友
- Biotion-PEG-Mal,Maleimide-PEG-Biotin,生物素聚乙二醇马来酰亚胺分子量
热门文章
- CSS3: border-radius边框圆角详解
- python小白-day4递归和算法基础
- Reporting Service 钻取
- CUDA学习----sp, sm, thread, block, grid, warp概念
- Linux/Unix下的任务管理器-top命令
- [云炬创业管理笔记]第6章制定创业行动测试3
- 小微商户申请php,微信小微商户申请入驻 - osc_r8q2esik的个人空间 - OSCHINA - 中文开源技术交流社区...
- 以太网口差分电平_以太网物理层信号测试与分析
- Gateway配合sentinel自定义限流_你知道如何使用阿里Sentinel实现接口限流吗?
- VTK修炼之道15:图像处理_显示(vtkImageViewer2 vtkImageActor)