采矿协议_采矿电信产品推荐
采矿协议
重点 (Top highlight)
抽象 (Abstract)
In the current age of information overload, it is becoming increasingly hard for people to find relevant content. Recommender systems have been introduced to help people in retrieving potentially useful information from a huge set of choices. It is a system that suggests products, services, information to users based on the analysis of data and has become increasingly significant in solving the information explosion problem.
在当前信息过载的时代,人们越来越难以找到相关内容。 引入了推荐系统,以帮助人们从众多选择中检索潜在有用的信息。 它是一种基于数据分析向用户提供产品,服务,信息的系统,在解决信息爆炸问题方面变得越来越重要。
In recent years, significant steps have been taken in the direction of providing personalized recommendation services for a wide variety of web-based applications in e-commerce, e-learning, and e-governance. However, this system is surprisingly not present in the telecom sector as of today, though it is a necessity. Hence, this blog explores the need for recommender systems in telcos to assist its customers in selecting the most appropriate telecom plans/products online. The blog ends with the development and implementation of a personalized recommendation system for telecom products/services by mining association rules from data to find the right telcos packages/plans/products for a new customer.
近年来,在为电子商务,电子学习和电子政务中的各种基于Web的应用程序提供个性化推荐服务的方向上已采取了重要步骤。 但是,尽管有必要,但是迄今为止,该系统在当今的电信领域中并不令人惊讶。 因此,该博客探讨了电信公司对推荐系统的需求,以帮助其客户在线选择最合适的电信计划/产品。 通过从数据中挖掘关联规则,为新客户找到合适的电信套餐/计划/产品,该博客以电信产品/服务的个性化推荐系统的开发和实施为结尾。
介绍 (Introduction)
While artificial intelligence (AI) has unquestionable power to transform the telecom industry, it is still very much a nascent field. Yet I believe telcos are uniquely well-positioned to take advantage of AI technology, largely because they are already used to dealing with huge volumes of data on which AI and machine learning (ML) rely. Since this isn’t a passing fad, it’s important for telcos to play the long game with AI and consider less-explored domains that could unlock new revenue streams.
人工智能(AI)无疑具有改变电信行业的能力,但它仍然是一个新兴领域。 但是我相信电信公司在利用AI技术方面处于独特的位置,主要是因为它们已经习惯于处理AI和机器学习(ML)所依赖的大量数据。 由于这不是一时的风尚,因此对于电信公司而言,使用AI进行漫长的竞争并考虑未开发的领域可能会释放新的收入来源非常重要。
AI and ML require vast quantities of data to function correctly, but the data must be of sufficient quality, too. If the right amount of good-quality data is not available, decisions recommended by an AI or ML model are unlikely to be accurate or successful.
AI和ML需要大量数据才能正常运行,但是数据也必须具有足够的质量。 如果没有正确数量的高质量数据,则AI或ML模型建议的决策不太可能是准确或成功的。
On a positive note, telcos do have access to large quantities of data, perhaps more than companies in most other industries. However, the struggle lies in capturing the right dataset and storing them with the degree of granularity needed for ML.
积极的一面是,电信公司确实可以访问大量数据,这可能比大多数其他行业的公司要多。 但是,努力在于捕获正确的数据集并以ML所需的粒度程度存储它们。
It is one thing to have high-quality data collected in a traditional way, but it is another to get this data into a specific way which you might need to solve a use case. Most telcos operator’s web page today, consists of a vast number of choices, which in turn becomes increasingly hard for a customer to find his/her desired choice of product.
以传统方式收集高质量数据是一回事,而将数据转化为解决用例可能需要的特定方式则是另一回事。 如今,大多数电信运营商的网页都包含众多选择,这反过来又使客户越来越难找到所需的产品选择。
Don’t you think it would be substantial if the same web page could automatically give you recommendations on various add-on products/bundles based on choices made by existing customers in the past?
您是否认为,如果同一网页可以根据现有客户过去的选择自动为您提供有关各种附加产品/套装的建议,那将是很重要的吗?
需要电信公司推荐系统 (Need for Telcos Recommendation System)
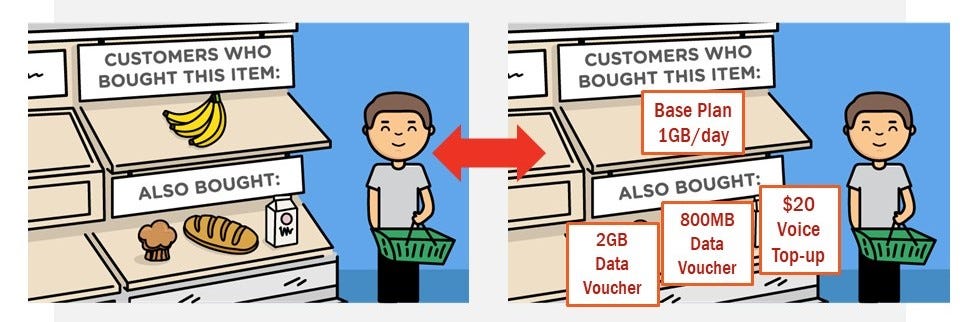
Recommendation systems can be fine-tuned to cater to user profiles/preferences based on the choices of other users. The advantage of this system is to suggest the right items (base plans or add-on products) to particular users, based on their explicit and implicit preferences by applying an information filtering algorithm. The algorithm that I have used for implementation is called Apriori.
可以对推荐系统进行微调,以根据其他用户的选择迎合用户个人资料/偏好。 该系统的优点是通过应用信息过滤算法,根据特定用户的显式和隐式偏好向他们建议正确的项目(基本计划或附加产品)。 我用于实现的算法称为Apriori。
算法说明 (Algorithm description)
Apriori Algorithm — It is simply the study of customer transaction database to determine dependencies between purchases of different plans/products.
Apriori算法-它只是研究客户交易数据库以确定不同计划/产品的购买之间的依存关系。
In other words, it is the study of “what goes with what”.
换句话说,它是 对“ 随什么而变” 。
The availability of detailed information on customer transactions has led to the development of techniques that automatically look for associations between items that are stored in the database. Example — data collected about customer transactions regarding each plan/base package along with the add-on products are captured by the network operator in their database. Such databases consist of a large number of transaction records where each record lists either the base plan or the add-on product purchased by the customer.
有关客户交易的详细信息的可用性导致了自动寻找存储在数据库中的项目之间的关联的技术的发展。 示例-网络运营商会在其数据库中收集有关每个计划/基本套餐的客户交易的数据以及附加产品。 这样的数据库由大量的交易记录组成,其中每个记录都列出了客户购买的基本计划或附加产品。
实施步骤 (Implementation Steps)
第1步 (Step 1)
By performing basic EDA on customer transaction data using Python, it is very likely to observe that there are certain base packages/plans that appear more often than the rest. Hence it would be a good idea to display a popular list of base packages as a first step. Given all the data is stored in a pandas dataframe ‘df’, we can get the list of popular base-packages/plans using the code below.
通过使用Python对客户交易数据执行基本的EDA,很可能会发现某些基本程序包/计划比其他程序/计划更频繁地出现。 因此,第一步是显示一个流行的基本软件包列表是一个好主意。 假设所有数据都存储在熊猫数据框“ df”中,我们可以使用下面的代码获取流行的基本包装/计划的列表。
df["BASE_PACKAGE_NAME"].value_counts()第2步 (Step 2)
Getting this data into a form where each record lists all the items bought by the user wouldn’t be much of a challenge using Python.
使用Python将这些数据转换成每个记录都列出用户购买的所有商品的形式并不是什么难事。

At this stage, we would be interested to know if certain groups of items are consistently purchased together, which can be found with the help of the Apriori algorithm.
在此阶段,我们很想知道某些物品组是否始终如一地一起购买,可以在Apriori算法的帮助下找到它们。
#Convert the dataframe to a listrecords = df.values.tolist()#Generate association rules with required #minimum support, confidence and liftfrom apyori import aprioriassociation_rules = apriori(records, min_support=0.3346, min_confidence=0.20, min_lift=3, min_length=3)association_results = list(association_rules)There are four performance metrics within the Apriori algorithm. These parameters are used to exclude association rules in the result that have support and confidence lower than the minimum support, confidence, lift, or length, respectively.
Apriori算法中有四个性能指标。 这些参数用于排除结果中支持和置信度分别低于最小支持,置信度,提升或长度的关联规则。
min_support — A float value between 0 and 1; used to select the items with support value greater than the value specified in the parameter.
min_support —介于0和1之间的浮点值; 用于选择支撑值大于参数中指定值的项目。

2. min_confidence — A float value between 0 and 1; used to filter those rules that have confidence greater than the confidence threshold specified in the parameter.
2. min_confidence —介于0和1之间的浮点值; 用于过滤那些置信度大于参数中指定的置信度阈值的规则。
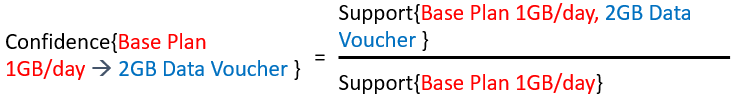
3. min_lift — This specifies the minimum lift value for the shortlisted rules.
3. min_lift —指定候选规则的最小提升值。

4. min_length — This specifies the minimum number of items that you want to see in your association rules itemsets.
4. min_length-这指定您要在关联规则项目集中看到的最小项目数。
The optimum values for min_support, min_confidence, and min_lift arguments can be set by trying out different values and checking whether they are producing valid association between the itemsets or not.
可以通过尝试不同的值并检查它们是否在项目集之间产生有效的关联来设置min_support,min_confidence和min_lift参数的最佳值。
第三步 (Step 3)
Obtaining association rules in a comprehensible format could be a challenge; here’s how I overcame that. Note that ‘Predecessor’ is an item found within the data, whereas ‘Successor’ is an item found in combination with the Predecessor.
以一种易于理解的格式获得关联规则可能是一个挑战。 这就是我克服的方法。 请注意,“前身”是数据中发现了一个项目,而“接班人”是一个项目结合发现的前身。
#Create a dataframe with all the necessary informationdf = pd.DataFrame(columns=('Items','Predecessor','Successor','Support','Confidence','Lift'))Support =[]Confidence = []Lift = []Items = []Predecessor= []Successor=[]for RelationRecord in association_results: for ordered_stat in RelationRecord.ordered_statistics: Support.append(RelationRecord.support) Items.append(RelationRecord.items) Predecessor.append(ordered_stat.items_base) Successor.append(ordered_stat.items_add) Confidence.append(ordered_stat.confidence) Lift.append(ordered_stat.lift)df['Items'] = list(map(set, Items)) df['Predecessor'] = list(map(set, Predecessor))df['Successor'] = list(map(set, Successor))df['Support'] = Supportdf['Confidence'] = Confidencedf['Lift']= Lift#Sort the dataframe based on confidence df.sort_values(by ='Confidence', ascending = False, inplace = True)第4步 (Step 4)
Providing the right recommendations would be by picking the items in the ‘Successor’ column given that the ‘Predecessor’ column value is equal to the base-package name selected by the customer from the popular package list.
提供正确的建议是通过在“继任者”列中选择项目,前提是“先行者”列值等于客户从受欢迎的包裹列表中选择的基本包裹名称。
#Picking the records for a particular plan/base_package that has been selected by the customer on the GUIpackage_name = "1GB/Day(24 day Validity)"index=[]for key, value in df["Predecessor"].iteritems(): if len(value) == 1 and package_name in value: print(key,value) index.append(key)
recommendations = df[df.index.isin(index)]And voila!
瞧!
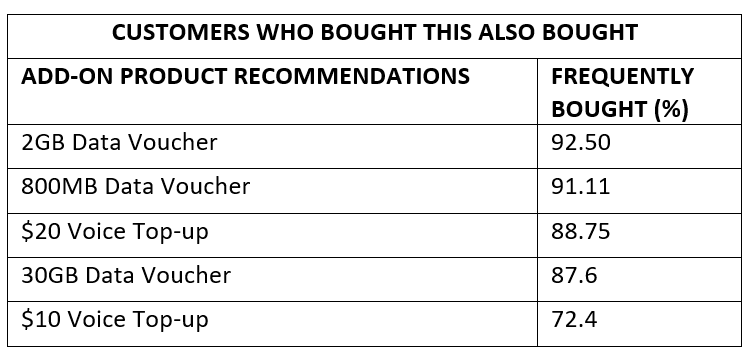
Note that the frequently bought percentage is the measure of confidence parameter, which is computed by the Apriori algorithm as stated earlier.
请注意,经常购买的百分比是置信度参数的度量,它是由Apriori算法计算的,如前所述。

结论与未来工作 (Conclusion and Future Work)
Being a part of the telecom industry for almost 5 years, I have seen that any AI initiative can have various technical and organizational questions; which is not very surprising as AI is such a pie-in-the-sky thing that you need to give the organization something tangible. Hence, making the leap from concept to live project or, making the move from piloting AI proof-of-concept projects to deploying live is a further challenge. The association-rule mining approach described in this blog proves the benefits of automated affinity analysis and is a fundamental business use-case for telcos in my opinion. It is critically important to have a clear understanding of what would constitute success from such an investment.
作为电信行业的一份子,已经有近5年的历史了,我已经看到,任何AI计划都可能会遇到各种技术和组织问题。 这并不令人感到意外,因为AI是天上掉下来的东西,您需要为组织提供切实的东西。 因此,实现从概念到实际项目的飞跃,或者从试点AI概念验证项目过渡到实际部署是进一步的挑战。 我认为,此博客中描述的关联规则挖掘方法证明了自动亲和力分析的好处,并且是电信公司的基本业务用例。 至关重要的是,清楚地了解通过这种投资将构成什么成功。
Taking a step further, the above implementation is limited to provide recommendations for new customers subscribing to the network via web-GUI/kiosk. The model can be improved by providing recommendations to existing/new customers by adding a clustering algorithm in the initial stage; which would segment customers based on age, salary, geographical data, etc. Additionally, some shortcomings of the Apriori algorithm are the profusion of rules that are generated and the fact that rare combinations of itemsets tend to be ignored, as they do not meet the minimum support requirements. Using a more robust algorithm would help to resolve this issue.
更进一步,上述实现方式仅限于为通过web-GUI / kiosk订阅网络的新客户提供建议。 可以通过在初始阶段添加聚类算法为现有/新客户提供建议来改进模型; 这会根据年龄,薪水,地理数据等对客户进行细分。此外,Apriori算法的一些缺点是生成的规则过多,而且由于无法满足商品集的罕见组合而往往会忽略它们的事实。最低支持要求。 使用更强大的算法将有助于解决此问题。
Thank you for reading!
感谢您的阅读!
翻译自: https://towardsdatascience.com/mining-telecom-product-recommendations-cfe455f3e563
采矿协议
http://www.taodudu.cc/news/show-1874007.html
相关文章:
- 机器人控制学习机器编程代码_机器学习正在征服显式编程
- 强化学习在游戏中的作用_游戏中的强化学习
- 你在想什么?
- 如何识别媒体偏见_面部识别,种族偏见和非洲执法
- openai-gpt_GPT-3 101:简介
- YOLOv5与Faster RCNN相比。 谁赢?
- 句子匹配 无监督_在无监督的情况下创建可解释的句子表示形式
- 科技创新 可持续发展 论坛_可持续发展时间
- Pareidolia — AI的艺术教学
- 个性化推荐系统_推荐系统,个性化预测和优点
- 自己对行业未来发展的认知_我们正在建立的认知未来
- 汤国安mooc实验数据_用漂亮的汤建立自己的数据集
- python开发助理s_如何使用Python构建自己的AI个人助理
- 学习遗忘曲线_级联相关,被遗忘的学习架构
- 她玩游戏好都不准我玩游戏了_我们可以玩游戏吗?
- ai人工智能有哪些_进入AI有多么简单
- 深度学习分类pytorch_立即学习AI:02 —使用PyTorch进行分类问题简介
- 机器学习和ai哪个好_AI可以使您成为更好的运动员吗? 使用机器学习分析网球发球和罚球...
- ocr tesseract_OCR引擎之战— Tesseract与Google Vision
- 游戏行业数据类丛书_理论丛书:高维数据101
- tesseract box_使用Qt Box Editor在自定义数据集上训练Tesseract
- 人脸检测用什么模型_人脸检测模型:使用哪个以及为什么使用?
- 不洗袜子的高文博_那个孩子在夏天中旬用高袜子大笑?
- word2vec字向量_Anything2Vec:将Reddit映射到向量空间
- ai人工智能伪原创_AI伪科学与科学种族主义
- ai人工智能操控什么意思_为什么要建立AI分散式自治组织(AI DAO)
- 机器学习cnn如何改变权值_五个机器学习悖论将改变您对数据的思考方式
- DeepStyle(第2部分):时尚GAN
- 肉体之爱的解释圣经_可解释的AI的解释
- 机器学习 神经网络 神经元_神经网络如何学习?
采矿协议_采矿电信产品推荐相关推荐
- 20-50人,拓展基地_拓展训练_拓展基地_拓展公司推荐_嗨牛团建
20-50人,拓展基地_拓展训练_拓展基地_拓展公司推荐_嗨牛团建 20-50人,拓展基地_拓展训练_拓展基地_拓展公司推荐_嗨牛团建 posted on 2016-08-31 12:39 lexus ...
- 车载以太网之DoIP协议_第一篇
车载以太网之DoIP协议_第一篇 1.DoIP含义 1.1 DoIP使用场景 1.2 DoIP在Autosar中的位置 2.以太网协议 2.1 物理层与数据链路层 2.2 网络层与传输层 2.3 Do ...
- wps 模拟分析 规划求解_【图书推荐】金属塑性加工过程有限元数值模拟及软件应用...
科学出版社 梅瑞斌 著 <金属塑性加工过程有限元数值模拟及软件应用>共6章,第1章主要讲述金属塑性加工工艺及求解方法:第2章主要讲述塑性力学及有限元理论基础:第3章分别采用有限元商用软件A ...
- 智能情绪分析技术_石化缘推荐:炼化企业智能机器人巡检技术应用前景分析!...
本期内容由湖南天一奥星泵业有限公司冠名 炼化企业智能机器人巡检技术应用前景分析 王国彤1,孙秉才2,储胜利2,宋亚敏1(1.中国石油天然气股份有限公司大连石化分公司,辽宁省大连市:2.中国石油集团安全 ...
- 五款常用协议分析处理工具推荐
工欲善其事,必先利其器,一款好的工具,能取到事半功倍的效果. 进行协议分析,好的辅助工具必不可少,本文推荐五款最常用且易用的协议分析工具给大家,包括两款综合抓包及分析工具,一款协议重放工具,一款pca ...
- nbns协议_网络协议详解1 - NBNS
NetBIOS 简介 NetBIOS,Network Basic Input/Output System的缩写,一般指用于局域网通信的一套API,相关RFC文档包括 RFC 1001, RFC 100 ...
- autojs怎么post协议_超9成人都理解错了HTTP中GET与POST的区别
GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一二. 最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数. 你可能自己 ...
- SPT20 协议_协议离婚协议书模板锦集6篇
协议离婚协议书模板锦集6篇 随着社会不断地进步,很多情况下我们需要用到协议书,签订签订协议书是最有效的法律依据之一.那么协议书怎么写才能发挥它最大的作用呢?以下是小编整理的协议离婚协议书6篇,仅供参考 ...
- flask渲染图像_用于图像推荐的Flask应用
flask渲染图像 After creating a Python-based machine learning application you might want to get it runnin ...
- nda协议_如何将NDA项目添加到您的投资组合
nda协议 Being on the job hunt meant I needed to update my portfolio again. I had a new project to add, ...
最新文章
- PgSQL · 特性分析 · full page write 机制
- IE再次曝出安全漏洞 微软表示正在调查
- 简单入门循环神经网络RNN:时间序列数据的首选神经网络
- UITableView reloadData 跳动闪动
- python标准库之socket
- 数据从hadoop到oracle,如何向 hadoop 导入数据
- mcldownload文件夹_《我的世界》中国版游戏空间精简教程 多余文件删除方法
- python dendrogram_收藏 | Python数据可视化的一些简单总结
- [Python] 索引序列函数:enumerate() / enumerate(sequence, start=0)
- TOMCAT启动提示NB: JAVA_HOME should point to a JDK not a JRE解决
- Win10第二天开机后默认的pdf阅读器被自动修改成Microsoft Edge,三种解决办法(第三种办法适合本机情况,摸索半个月)
- pycharm中python环境的配置
- 深度学习目标检测---使用labelimg对自己的数据集进行标记(windows系统)
- Python中将两个DataFrame拼接时遇到:InvalidIndexError: Reindexing only valid with uniquely valued Index objects
- 由Tomcat 8005端口想到的...
- 杭电计算机专业期末考试助攻,杭电嘻哈:舶来文化亦可玩出小清新
- Android去除烦人的默认闪退
- 【转】PS学堂之一:展示一下自己做的圆形印章
- linux开启dhcpclient服务,dhcp client 配置
- 如何正视自身价值和自我定位 --------从产品定价方法来看求职者自身价值的估量...
热门文章
- Android学习笔记---常用技巧(图片的旋转)
- Beginning Python chapter 3: Working with strings
- 慕课网 机器学习基础、任务、分类等笔记
- opencv打开双目,采集标定双目的图片
- debug, release strlen与sizeof
- orb特征描述符 打开相机与图片物体匹配
- unity 引用using 空间 变量声明
- Atitit 深入理解耦合Coupling的原理与attilax总结 目录 1.1. 耦合作为名词在通信工程、软件工程、机械工程等工程中都有相关名词术语。 2 1.2. 所有的耦合形式可分为5类:
- Atitit 防注入 sql参数编码法 目录 1.2. 提升可读性pg_escape_literal — 转义文字以插入文本字段 1 1.2.1. 说明 1 1.3. 推荐pg_escape_str
- Atitit mvc框架的实现 mvc的原理demo v2 sbb.docx 目录 1. 原理流程, 1 1.1. 项目启动的时候启动mvc框架扫描,建立url 方法对应表 1 1.2. 执行ur