python输入数据爬取_python根据用户需求输入想爬取的内容及页数爬取图片方法详解...
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。
主要步骤:
1.提示用户输入爬取的内容及页码。
2.根据用户输入,获取网址列表。
3.模拟浏览器向服务器发送请求,获取响应。
4.利用xpath方法找到图片的标签。
5.保存数据。
代码用面向过程的形式编写的。
关键字:requests库,xpath,面向过程
现在就来讲解代码书写的过程:
1.导入模块
import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配
import requests # 爬虫主要的包
from urllib.request import urlretrieve # 本文用来下载图片
import os # 标准库,本文用来新建文件夹
每个模块的作用都已经备注了。
2.提示用户输入内容和页数
if not os.path.exists("王一博图片"):
os.mkdir("王一博图片") # 判断有没有该文件夹,如果没有就创建改文件夹
k = input("请输入你想搜索的关键字:")
num = int(input("请输入你想搜索的页数:"))
3.准备好url和header
header = {"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Mobile Safari/537.36"
}
base_url = "https://www.duitang.com/search/?kw=" + k + "&type=feed#!s-p"
title_url = []
n = 0
user-agent是服务器识别浏览器的重要参数,我们就用这个来蒙骗服务器,user-agent在浏览器里可以找到
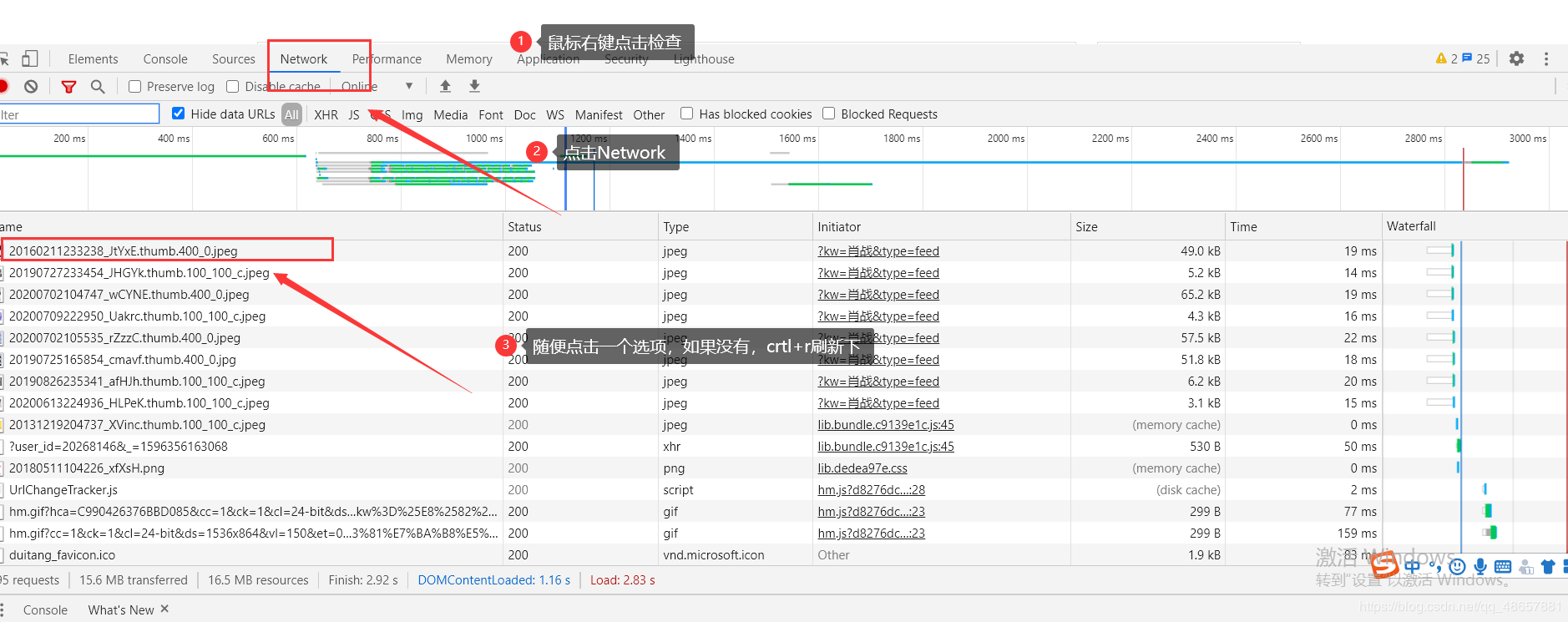
那么现在我们就关注右边
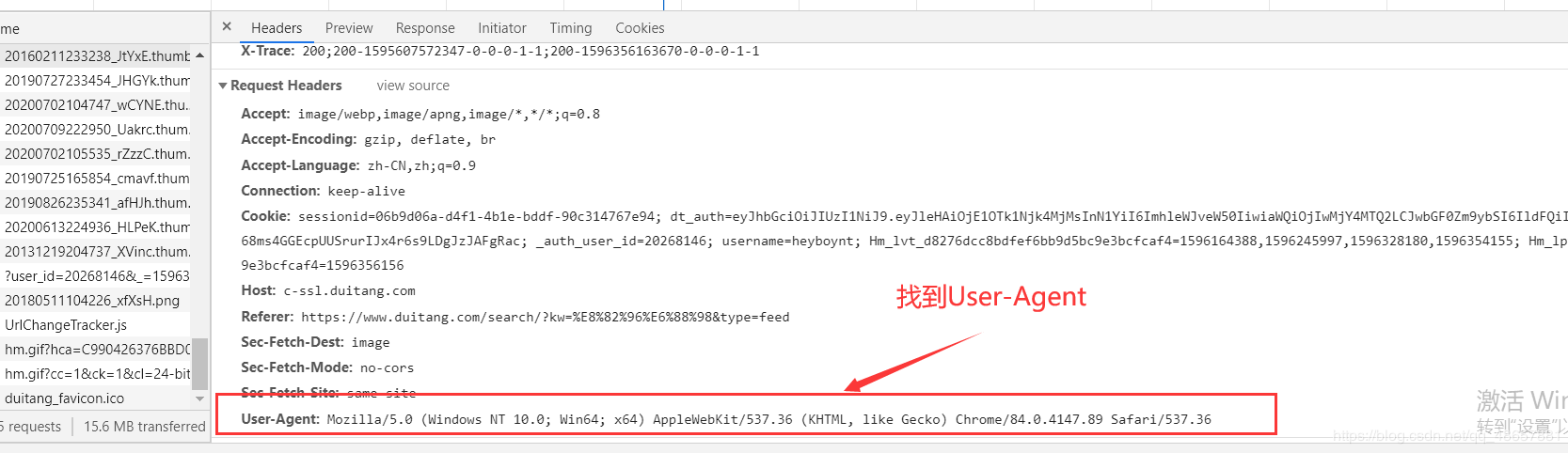
这样header就找到了,注意要以字典的形式
4.发送请求、
for i in range(num):
title_url = base_url + str(i)
respons = requests.get(title_url, headers=header).text
html = parsel.Selector(respons) # 解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
pic_url = html.xpath('//div[@class="mbpho"]/a/img/@src').extract()
一切准备就绪后,就可以发送请求了。request.get.text返回的是网页的源代码,然后将源代码转换为Selector对象,再通过xpath的方法找到图片的网址。
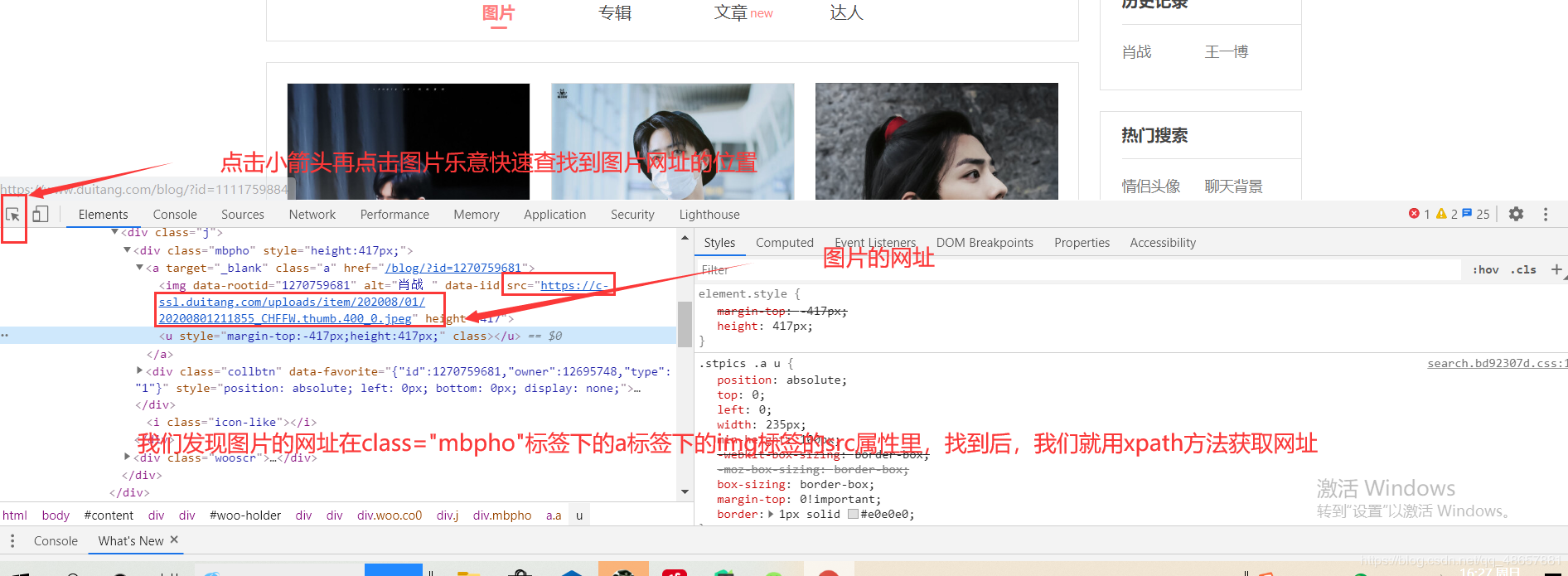
5.保存数据
获取图片的图片的链接后,我们就可以保存了。
for url in pic_url:
n = n + 1
file_path = "王一博图片" + '/' + str(n)+".jpg"
urlretrieve(url, file_path) # 下载图片,具体的用法可以去搜索下,很简单的
print("第%d张图片下载成功" % n)
注意:这里的for循环是在上面的循环里嵌套的。
最后来看看全部的代码吧!
import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配
import requests
from urllib.request import urlretrieve # 本文用来下载图片
import os # 标准库,本文用来新建文件夹
if not os.path.exists("王一博图片"):
os.mkdir("王一博图片") # 判断有没有该文件夹,如果没有就创建改文件夹
k = input("请输入你想搜索的关键字:")
num = int(input("请输入你想搜索的页数:"))
header = {"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Mobile Safari/537.36"
}
base_url = "https://www.duitang.com/search/?kw=" + k + "&type=feed#!s-p"
title_url = []
n = 0
for i in range(num):
title_url = base_url + str(i)
respons = requests.get(title_url, headers=header).text
html = parsel.Selector(respons)
pic_url = html.xpath('//div[@class="mbpho"]/a/img/@src').extract()
# print(pic_url)
for url in pic_url:
n = n + 1
file_path = "王一博图片" + '/' + str(n)+".jpg"
urlretrieve(url, file_path) # 下载图片,具体的用法可以去搜索下,很简单的
print("第%d张图片下载成功" % n)
来看看运行的结果,以搜索王一博,搜索5页为例。
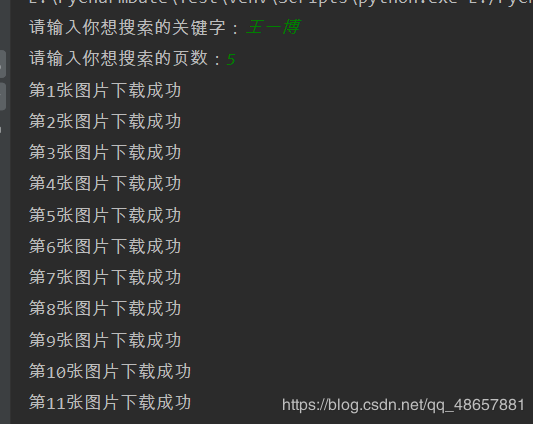
然后你就发信多了一个王一博的文件夹了,点开就可以看见王一博的帅照了。
到此这篇关于python根据用户需求输入想爬取的内容及页数爬取图片方法详解的文章就介绍到这了,更多相关python爬取图片方法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
python输入数据爬取_python根据用户需求输入想爬取的内容及页数爬取图片方法详解...相关推荐
- python输入字符串并反序result_python字符串反转的四种方法详解
python字符串反转的四种方法详解 这篇文章主要介绍了python字符串反转的四种详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.用red ...
- python的装饰器迭代器与生成器_python3 装饰器、列表生成器、迭代器、内置方法详解等(第四周)...
前言: 为什么要学习python3? 原因: 1.学习一门语言能力 2.通过该语言能力完成测试自动化以及独立完成自测框架知识 那么我要做什么呢? 1.每天花十个小时完成python3的学习 要在什么地 ...
- python输入数据的维度_python – Keras LSTM输入维度设置
我试图用keras训练LSTM模型,但我觉得我在这里弄错了. 我收到了错误 ValueError: Error when checking input: expected lstm_17_input ...
- python接口自动化项目_python接口自动化(四十二)- 项目结构设计之大结局(超详解)...
简介 这一篇主要是将前边的所有知识做一个整合,把各种各样的砖块---模块(post请求,get请求,logging,参数关联,接口封装等等)垒起来,搭建一个房子.并且有很多小伙伴对于接口项目测试的框架 ...
- 用python爬取网页数据并存入数据库中源代码_Python爬取51cto数据并存入MySQL方法详解...
[] 实验环境 1.安装Python 3.7 2.安装requests, bs4,pymysql 模块 实验步骤1.安装环境及模块 可参考https://www.jb51.net/article/19 ...
- python怎么取共轭_python print出共轭复数的方法详解
python print出共轭复数的方法详解 发布时间:2020-09-21 01:42:19 来源:脚本之家 阅读:92 作者:爱喝马黛茶的安东尼 复数是由一个实数和一个虚数组合构成,表示为:x+y ...
- python下载微信公众号文章_python如何导出微信公众号文章方法详解
1.安装wkhtmltopdf 下载地址:https://wkhtmltopdf.org/downloads.html 我测试用的是windows的,下载安装后结果如下 2 编写python 代码导出 ...
- python支持向量机回归_Python中支持向量机SVM的使用方法详解
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类.因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm. 一.导 ...
- python中文字符串多余空格_python使用正则表达式去除中文文本多余空格,保留英文之间空格方法详解...
python使用正则表达式去除中文文本多余空格,保留英文之间空格方法详解 在pdf转为文本的时候,经常会多出空格,影响数据观感,因此需要去掉文本中多余的空格,而文本中的英文之间的正常空格需要保留,输入 ...
最新文章
- 在asp.net(C#)中怎么获得一个目录的大小?
- Github 3.4k星,200余行代码,让你实时从视频中隐身
- 《DBA修炼之道:数据库管理员的第一本书》——1.2节独特的优势
- 【iCore4 双核心板_ARM】例程三十八:DSP MATH库测试
- 开启mysql慢查询日志,不重启数据库的方法
- SAP Cloud for Customer最新版本2002 RUI如何启用adaptation模式
- 服务器芯片采购,服务器采购具体要求.pdf
- 【计算机组成原理】乘法阵列器
- C 标准库 - string.h
- php 时间选择,PHP-在学说2中的日期之间选择条目
- LeetCode 80. 删除排序数组中的重复项 II
- MySQL 修改和删除索引
- css3毛玻璃效果白边问题
- 话里话外:按单制造(MTO II)信息化管理特点
- [转]NVIDIA/ATI显卡后缀命名大盘点
- 太秀了!程序媛小姐姐写出代码版《本草纲目》,刘畊宏回复:很cool!
- 蓝湖 Axure 墨刀
- 仿京东PC网页商品详情的放大镜效果(原理+代码)
- 【IoT】 产品设计之结构设计:材料工艺选择及特点(PP、PVC、PE、PS、ABS、PC)
- 一台电脑怎么安装32位和64位的jdk,怎么配置环境变量
热门文章
- Android之ActivityLifecycleCallbacks的得到当前的activity的状态
- linux c之<setjmp.h>使用总结
- linux环境下最简单的C语言例子
- CLion 中使用 C++ 版本的 OpenCV
- 王道408数据结构——第二章 线性表
- 看了《隐秘的角落》才知道,掉头发有多可怕!10个掉头发最快的专业!快看看你中枪了没有!...
- 找对象不能只看TA的外表
- 21岁就破解困扰人们300年难题的天才,却一生坎坷,怀才不遇,至死还得不到认可...
- 全校师生放6天春假;清华大学设立天文系;郭守敬望远镜光谱数突破千万;《自然》发表最新发现;百度败诉需道歉;这就是今天的大新闻...
- 催人泪下!一个程序员的悲惨故事