机器学习基石HOW部分(1)
机器学习基石HOW部分(1)
标签:机器学习基石
第九章
analytic solution wLIN=X†y with linear regression hypotheses and squared error
从方程的形式、误差的衡量方式、如何最小化Ein的角度出发,并简单分析了Hat Matrix的性质与几何意义,希望对线性回归这一简单的模型有个更加深刻的理解。
方程的形式
linear regression hypothesis: h(x)=wTx ,长得很像 perceptron,只不过是少了sign。
线性回归:寻找直线。平面或者超平面,使得输入数据的残差最小(残差是指观测值与预测值(拟合值)之间的差,即是实际观察值与回归估计值的差。在回归分析中,测定值与按回归方程预测的值之差,以δ表示。残差δ遵从正态分布N(0,σ2)。)
误差的衡量
平方误差(squared error):
如何最小化Ein
先看看Ein的矩阵能够怎样表示:
现在很明显,要得到最小的Ein就是把上面的矩阵最小化。
minwEin(w)=1N||Xw−y||2
X与y来源于D,是固定不变的,因此它是一个以w为变量的函数。
画画Ein的图,它是连续,处处可微的凸函数。
图如下:
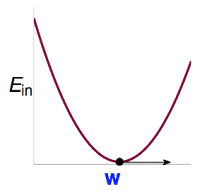
很明显,当Ein的曲线到达谷底的时候,Ein有最小值。结合微积分的只是,当曲线的导数为0的时候,Ein最小。
于是,要得到最小的Ein就变成了找到WLIN使得 ∇Ein(wLIN)=0.
把微分从一元的简单形式开始计算,然后推广到多元。经过计算得到∇Ein(w)=2N(XTXw−XTy)
现在就是要找到WLIN使得∇Ein(w)=2N(XTXw−XTy)=0
当XTX可逆的时候,答案还是很容易算出来的。就是让XTXw=XTy,然后就可以得到Ein(wLIN)=(XTX−1XTy)
因为N>>d+1,所以XTX一般都是可逆的,此时解是唯一的。
如果XTX不可逆,那就会有许多解了。
XTX可逆,可以用一个神奇的X†来代替(XTX)−1XT,由此,
用以wLIN为参数的线性方程对原始数据做预测,可以得到拟合值y=XwLIN=XX†y。这里又称H=XX†为Hat Matrix,帽子矩阵,H为y带上了帽子,成为y^,取名字取得很形象。
###Hat Matrix
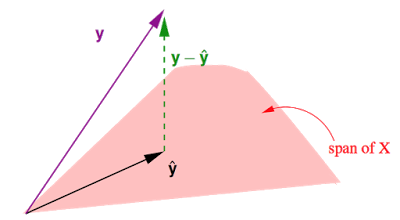
- y^=XwLIN是X的一个线性组合,X中每个column对应RN下的一个向量,共有d+1个这样的向量,因此y^在这d+1个向量所构成的span(平面)上。
- 事实上我们要做的就是在这个平面上找到一个向量y^使得他与真实值之间的距离|y−y^|最短。不难发现当y^是y在这个平面上的投影时,即y−y^⊥span时,|y−y^|最短。
- 所以之前说过的Hat Matrix H,为y戴上帽子,所做的就是投影这个动作,寻找span上y的投影。
- Hy=y^,(I−H)y=y−y^。(I为单位矩阵)
trace(I−H)=N−(d+1)
一个矩阵的trace等于该矩阵的所有特征值(Eigenvalues)之和。
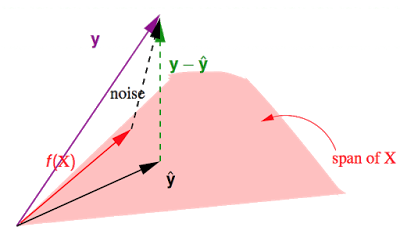
假设y由f(X)∈span+noise构成的。有y=f(X)+noise。之前讲到H作用于某个向量,会得到该向量在span上的投影,而I−H作用于某个向量,会得到那条与span垂直的向量,在这里就是图中的y−y^,即(I−H)noise=y−\hat{y}$。
这个y−y^是真实值与预测值的差,其长度就是就是所有点的平方误差之和。于是就有:Ein(wLIN)=1N||y−y^||2=1N||(I−H)noise||2=1Ntrace(I−H)||noise||2=1N(N−(d+1))||noise||2
因此Ein¯¯¯¯¯==noiselevel⋅(1−d+1N)、Eout¯¯¯¯¯¯==noiselevel⋅(1+d+1N)
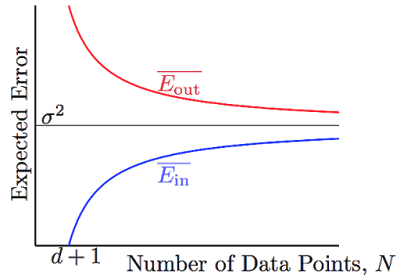
N -> ∞,Ein¯¯¯¯¯和Eout¯¯¯¯¯¯都都向σ2(noise level)收敛,并且他们之间的差异被2(d+1)N给bound住了。有那么点像VC bound,不过要比VC bound来的更严格一些。
所以,兜兜转转,说明了用线性回归,学习是可行的。
转载于:https://www.cnblogs.com/huang22/p/5401164.html
机器学习基石HOW部分(1)相关推荐
- 太赞了!NumPy 手写所有主流 ML 模型,由普林斯顿博士后 David Bourgin打造的史上最强机器学习基石项目!...
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! 用 NumPy 手写所有主流 ML 模型,普林斯顿博士后 David Bourgi ...
- NumPy 手写所有主流 ML 模型,由普林斯顿博士后 David Bourgin打造的史上最强机器学习基石项目!...
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! 用 NumPy 手写所有主流 ML 模型,普林斯顿博士后 David Bourgi ...
- 台湾大学林轩田机器学习基石课程学习笔记1 -- The Learning Problem
红色石头的个人网站:redstonewill.com 最近在看NTU林轩田的<机器学习基石>课程,个人感觉讲的非常好.整个基石课程分成四个部分: When Can Machine Lear ...
- 台湾大学林轩田机器学习基石课程学习笔记15 -- Validation
红色石头的个人网站:redstonewill.com 上节课我们主要讲了为了避免overfitting,可以使用regularization方法来解决.在之前的EinEinE_{in}上加上一个reg ...
- 台湾大学林轩田机器学习基石课程学习笔记14 -- Regularization
红色石头的个人网站:redstonewill.com 上节课我们介绍了过拟合发生的原因:excessive power, stochastic/deterministic noise 和limited ...
- 台湾大学林轩田机器学习基石课程学习笔记13 -- Hazard of Overfitting
红色石头的个人网站:redstonewill.com 上节课我们主要介绍了非线性分类模型,通过非线性变换,将非线性模型映射到另一个空间,转换为线性模型,再来进行分类,分析了非线性变换可能会使计算复杂度 ...
- 台湾大学林轩田机器学习基石课程学习笔记12 -- Nonlinear Transformation
红色石头的个人网站:redstonewill.com 上一节课,我们介绍了分类问题的三种线性模型,可以用来解决binary classification和multiclass classificati ...
- 台湾大学林轩田机器学习基石课程学习笔记11 -- Linear Models for Classification
红色石头的个人网站:redstonewill.com 上一节课,我们介绍了Logistic Regression问题,建立cross-entropy error,并提出使用梯度下降算法gradient ...
- 台湾大学林轩田机器学习基石课程学习笔记10 -- Logistic Regression
红色石头的个人网站:redstonewill.com 上一节课,我们介绍了Linear Regression线性回归,以及用平方错误来寻找最佳的权重向量w,获得最好的线性预测.本节课将介绍Logist ...
- 台湾大学林轩田机器学习基石课程学习笔记8 -- Noise and Error
红色石头的个人网站:redstonewill.com 上一节课,我们主要介绍了VC Dimension的概念.如果Hypotheses set的VC Dimension是有限的,且有足够多N的资料,同 ...
最新文章
- c语言 打开文件夹空格,关于文件操作,碰到空格就换行
- 11、CROSS JOIN:交叉连接(笛卡尔积)
- python安全攻防---scapy使用
- python中利用re模块使用正则表达式
- fcpx插件Corporate Story for Mac(商务公司视频宣传片头模板)
- 自定义异常 java
- RHEL 8 - 用OpenSCAP工具对容器镜像进行漏洞安全合规扫描,并修复
- python treemap_使用TreeMap
- jQuery学习(四)— jQuery的ready事件和原生JS的load事件的区别
- [Delphi]怎样访问Internet Explorer中的WebBrowser
- luhn算法java_Java信用卡验证– Java中的Luhn算法
- svn添加提交备注限制和自动发布web项目
- WLAN配置实例(二)——三层组网隧道转发
- 苹果手机录屏软件_4款手机录屏软件推荐,你觉得哪款更好用?
- 李宏毅机器学习Lesson2——Logistic Regression实现收入预测
- 计算机组成原理问题集合
- 文献阅读-一种基于机器学习方法的海事监视雷达海杂波抑制方法
- python解析xps文件_xps文件的基本操作
- Spring Boot任务管理
- 小兔子在终端给大家拜年啦