AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect。在观测数据中的应用需要和Instrument Variable结合来看,这里我们只讨论CACE的框架给随机AB实验提供的一些learning。你碰到过以下低实验渗透低的情况么?
- 新功能入口很深,多数进组用户并未真正使用新功能,在只能在用户层随机分流的条件下,如何计算新功能的收益
- 触达策略,在发送触达时进行随机分组,但触达过程存在损失,真正触达的用户占比很小,如何计算触达收益
背景
当然如果你的新策略渗透非常低,可能你的策略本身就需要调整。但就一些本身旨在提高少数用户体验的策略,或者策略初期试水的情况,CACE可能会比AB组的整体差异(ATE)更合适作为你实验的衡量指标。因为它可能会告诉你策略对少部分用户产生了显著受益,你要做的只是去继续迭代扩大用户渗透而已。
ATE关注的是整个实验组-对照组的收益,当然也会是策略全量上线后预估能拿到的对全用户的收益。CACE估计的则是实验对真正触达的用户预估产生的收益。注意这部分用户的收益并不能泛化到全用户,其一实验对不同用户的影响不同,其二策略的渗透率天然有限。往往渗透率越低对用户的选择性越强,触达的用户和整体用户的差异更大,计算出的CACE更难泛化到全用户上
CACE框架
让我们回忆下ATE的计算, T是treatment,例如app增加的新功能, Y是outcome,比如用户app使用时长,实验效果一般通过ATE估计,因为这会最贴近实验全量后在全用户上拿到的最终受益
CACE额外加入了变量W实验渗透,也就是用户是否真正使用过新功能,CACE估计的是实验对真正触达的用户产生的收益。如果你的实验渗透100%那CACE=ATE,随着实验渗透的降低,理论上CACE会比ATE越来越高,因为部分用户的收益被全体用户稀释。
说了这么多CACE咋算嘞?别急先来展示2种错误却经常被使用的方法
- Per-protocol Analysis = 实验组渗透用户 - 对照组全用户
- As-treated Analysis = 实验组渗透用户 - 实验组未渗透用户
上面两种方法都同时踩中了一个叫做Selection Bias的坑,也就是功能渗透本身是受到用户行为/主观意愿影响,因此会存在用户选择。从而导致渗透用户既不能代表全用户,也会和未渗透用户存在差异。真要在错的里面找个对的出来,Per-protocol一般更好一点。
CACE计算
用户定义
CACE把用户分为4类, compiler, never-taker, always-taker, defier,简单说compiler是给药就吃不给就不吃,never-taker是打死也不吃,always-taker是没事就吃药,defier是不给我药我偏要吃。这四类人群可以通过W和Z进行定义如下
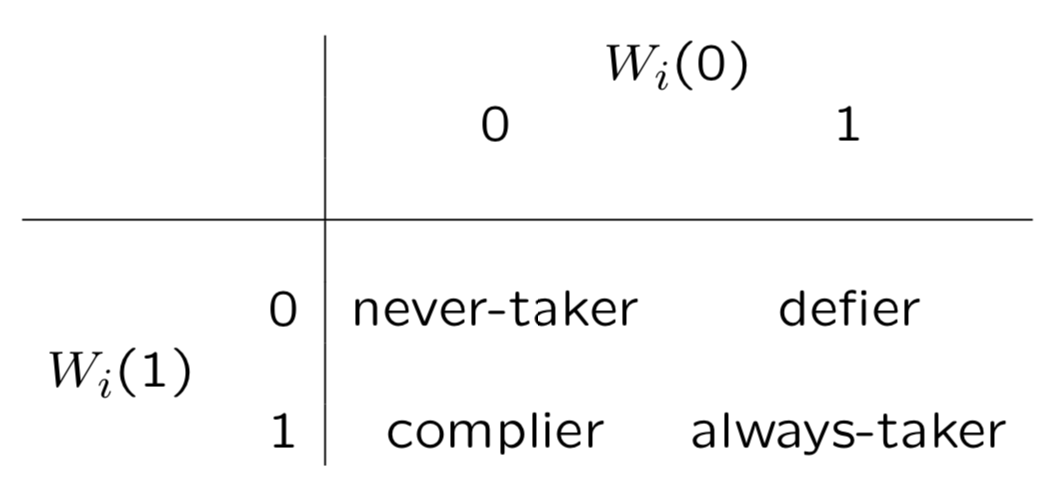
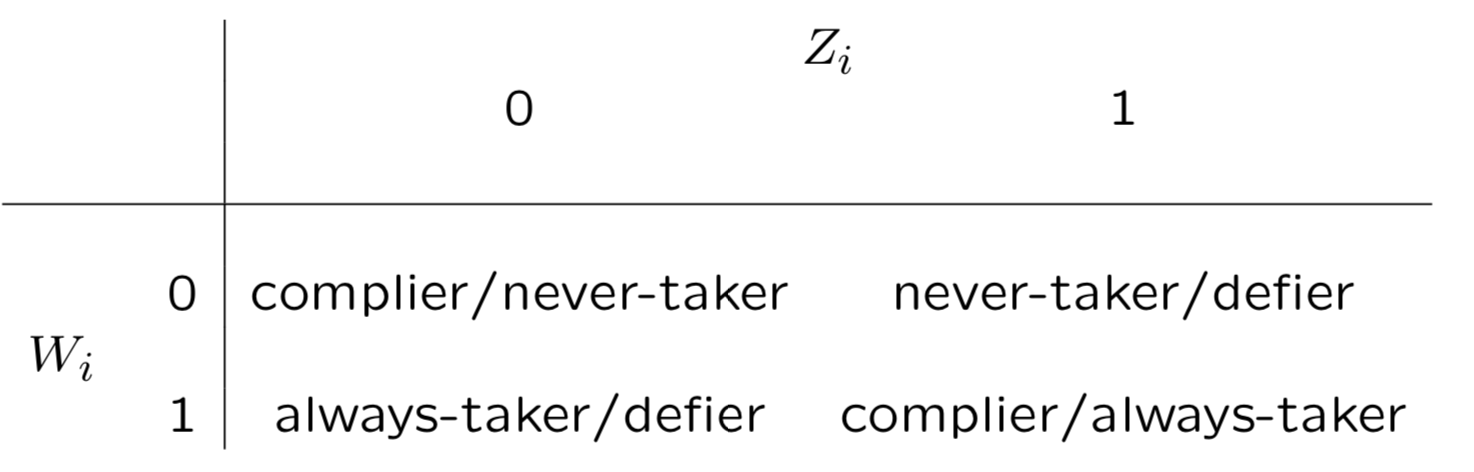
### 假设 要想CACE的计算成立,还需要满足3条假设
1. Independence
这个在随机AB实验中一定成立,但在观测数据中需要额外寻找Instrument variable这里不予讨论
2. Exclusion Restriction
这个假设即便在随机AB实验中也不一定成立,因此需要基于策略本身进行判断,基本原则就是Treatment分组本身对用户没有影响,只有确实被Treatment渗透的用户才受到影响。假设2保证了never-taker,always-taker在实验组和对照组中的表现一致。
印象中有看到过假设2不成立应该如何计算CACE的paper,不过还没碰到过类似情况,以后有用到再加上吧。
3. Monotonicity/No-Defier
单调假设在绝大多数情况下都成立,也就是T对W是正效应,不存在Defier。 这时W和Z对应的人群会被简化为以下,never-taker指向人群就是实验组未渗透人群因此可以直接估计
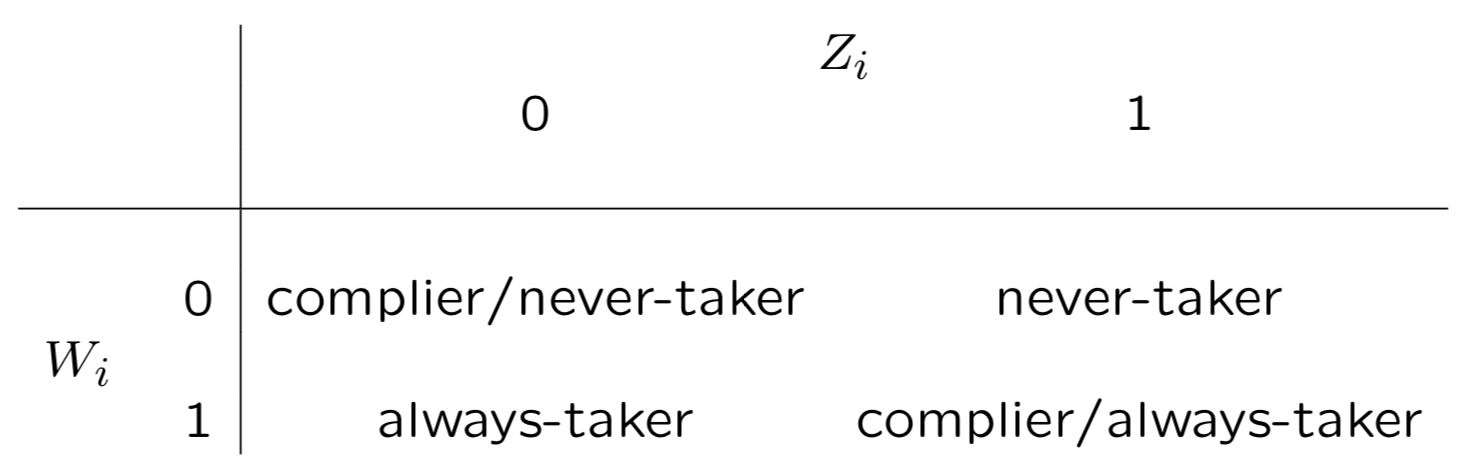
计算
随机实验的假设保证了compiler, always-taker, 和never-taker在对照组和实验组中的占比是相同的,因此我们可以直接计算出compiler, always-taker, never-taker在人群中的占比,如下
因为实验组中未渗透用户一定是never-taker, 对照组中渗透用户一定是always-taker(在一些功能型随机实验中并不存在always-taker),因此这部分用户的表现可以直接拿到
我们以此为突破口就可以计算得到compiler的CACE,先把对照组和实验组的人群进行分解如下
很显然AB组的差异只来源于compiler的差异,其实在没有always taker的情况下, CACE只是按实验组渗透等比的放大了组间收益而已
对于显著性的计算,我个人更偏向于只把CACE应用在原始ATE已经显著的情况下,以避免针对一些没有意义的波动数据进行分析,CACE只是用于估计渗透用户的绝对收益。当然如果想要计算CACE的显著性,可以用Bootstrap来拿到SE。当然因为CACE本身是ratio,也可以用更科学的方法来计算SE,具体细节可以参照Ref4。
用这个方法难免会被问到这部分用户的收益能否泛化到全体用户,理论上是不能的,但也不能一锤子打死。一个比较简单直观的方法是去比较\(E(Y(0)|compiler)\),\(E(Y(0)|always)\),\(E(Y(0)|never)\)之间是否存在显著差异,差异越大,能泛化的可能一般是越小的。
对AB实验的高端玩法感兴趣?
AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE相关推荐
- 路由+ros+linux,ROS+openwrt(旁路由) IP分流稳定出国方案 ESXI高端玩法
ROS+openwrt(旁路由) IP分流稳定出国方案 ESXI高端玩法 2020-03-18 08:39:45 21点赞 173收藏 73评论 原来一直都是单openwrt方案(应该是ks lede ...
- 城里人的高端玩法(对股票及金融创新的本质的经典讲解)
转自:许哲 http://zhuanlan.zhihu.com/wontfallinyourlap/20116480 (以下是个故事,纯虚构) Long long ago,有一座风景秀丽的小村庄,这里 ...
- 揭秘闲鱼赚钱项目的高端玩法
一个行业项目存在越久,它被挖掘出来的东西也就越多,自媒体.电商.网赚项目有许许多多,但真正赚到钱的却没几个人,究其原因还是项目操作门槛的问题. 项目的操作门槛越低,竞争也就越激烈,要是人人都可以轻松操 ...
- 单靠MySQL进了字节,高端玩法才是王道!
前两天看到字节一个老哥写的帖子,提到高阶开发者必须掌握的技能,其中他明确提出了"精通MySQL". 为啥MySQL对开发人员如此重要? 第一,不管你去面试哪家公司,数据库是必问项, ...
- 揭秘!信息检索技术高端玩法
<SIGIR 顶会论文解读>重磅发布 由 7 位阿里巴巴技术专家精心打造,内容覆盖推荐系统 .成交转化模型 . 回音室效应 . 全空间多任务转化率预估建模 . DeepMatch 召回模型 ...
- 【ChatGPT高端玩法】ChatGPT一分钟制作PPT
系列文章目录 第一章 ChatGPT一分钟制作PPT 第二章 ChatGPT生成Excel统计格式 第三章 ChatGPT生成Excel提取字符公式 第四章 ChatGPT生成思维导图 目录 实现步骤 ...
- Kotlin 高端玩法之DSL
如何在 kotlin 优雅的封装匿名内部类(DSL.高阶函数) 匿名内部类在 Java 中是经常用到的一个特性,例如在 Android 开发中的各种 Listener,使用时也很简单,比如: //la ...
- 【ChatGPT高端玩法】ChatGPT生成Excel提取字符公式
系列文章目录 第一章 ChatGPT一分钟制作PPT 第二章 ChatGPT生成Excel统计格式 第三章 ChatGPT生成Excel提取字符公式 第四章 ChatGPT生成思维导图 目录 一.适合 ...
- python高端玩法_这7种Python的全新玩法,一般人都不知道!
Python第三方模块众多,下面我介绍一些比较实用而又有趣的模块,主要分为爬虫.数据处理.可视化.机器学习.神经网络.股票财经.游戏这7个方面. 主要内容如下: 1.爬虫:相信大部分人都用Python ...
- 揭秘微商2015年的高端玩法
如果你已经点进来,不论你是不是微商,但最起码对这个行业是感兴趣的,或者是知道一点,当然如果你纯属好奇,那这篇文章算是一个科普知识吧! 微商之前的发展模式大家应该都知道,这里简单的列一下: 1.账号包装 ...
最新文章
- git常用命令和场景
- php tp3.0计算每天的订单,TP5.1结合taskphp3.0定时任务
- css3制作八棱锥_CSS基础八部分-第二部分
- SignalR 中丰富多彩的消息推送方式
- linuxpython安装_Linux安装python3.6
- css不继承上级样式_CSS基础知识(一)
- 【unity3d study ---- 麦子学院】---------- unity3d常用组件及分析 ---------- Animator动画状态机...
- python aes加解密
- java.library.path设置无效
- C语言冒泡排序算法及代码
- mysql 分表联合查询_解决分表后联合查询
- 01 - vulhub - ActiveMq - CVE-2015-5254
- html的实习报告,HTML实习报告
- 解决工商银行网银插件报‘非正常运行的网银工具’问题
- 字符串函数的模拟实现
- 项目2-Time类中的运算符重载
- 保护模式下的CPL,RPL,DPL与特权级检查(二)
- 速学Latex之数学公式编辑
- 【观察】跨入5G新时代,维谛技术(Vertiv)的行与思
- 计算机科学与技术用什么配置的笔记本,笔记本电脑什么配置好?这两大标准你知道吗?...