PCANet --- 用于图像分类的深度学习基准
PCANet --- 用于图像分类的深度学习基准
Ldpe2G 发布于 2年前,共有 37 条评论
前言
论文网站:http://arxiv.org/abs/1404.3606
论文下载地址:PCANet: A Simple Deep Learning Baseline for Image Classification?
论文的matlab代码(第一个就是):Matlab Codes for Download
本文的C++ 和 Scala 代码:https://github.com/Ldpe2G/PCANet
该文提出了一个简单的深度学习网络,用于图像分类,用于训练的图像的特征的提取包含以下步骤:
1、cascaded principal component analusis 级联主成分分析;
2、binary hashing 二进制哈希;
3、block-wise histogram 分块直方图
PCA(主成分分析)被用于学习多级滤波器(multistage filter banks),
然后用binary hashing 和 block histograms分别做索引和合并。
最后得出每一张训练图片的特征,每张图片的特征化为 1 x n 维向量,然后用这些特征向量来训练
支持向量机,然后用于图像分类。
正文
训练过程
首先假设我们的训练图片的为N张, ,每张图片大小为 m x n。
,每张图片大小为 m x n。
第一阶段的主成分分析
首先对每一幅训练图像做一个处理,就是按像素来做一个分块,分块大小为 k1 x k2。
上图解释什么事按像素分块,假设图像是灰度图大小为 5 x 5,分块大小为 2 x 2。
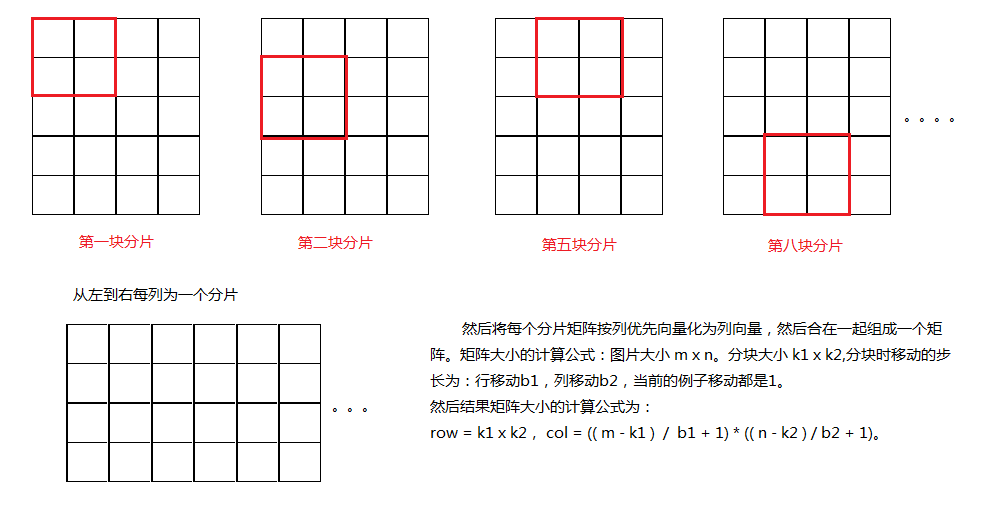
然后得到的分片矩阵大小是 4 x 16,按照上述计算公式可以得到。
然后如果图像是RGB 图像,则首先将三个通道分开,每个通道都做上 诉的分片,得到的分块矩阵,
做一个竖直方向上的合并得到RGB图像的分块矩阵,则如果RGB图像大小为 5 x 5,分块大小2x2,
则得到的分块矩阵大小为 12 x 16。
需要注意的是按照论文的说法,分块的矩阵的列数为m*n,所以5x5矩阵的分块矩阵应该有25列,
但是从代码的实现上看,是按照上图的公式来计算的。
假设第 i 张图片, ,分块后得到的矩阵为
,分块后得到的矩阵为 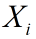 ,然后对每一列减去列平均,得到
,然后对每一列减去列平均,得到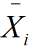 。
。
接着对N张训练图片都做这样一个处理,得到
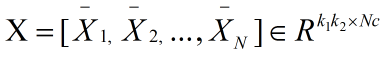
c为分快矩阵的列数。
然后接着求解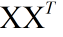 的特征向量,取前
的特征向量,取前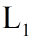 个最大的特征值对应的特征向量。
个最大的特征值对应的特征向量。
作为下一阶段的滤波器。数学表达为:
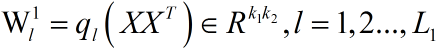
然后第一阶段的主成分分析就完成了。因为我将matlab代码移植到了opencv,所以对原来的代码
比较熟悉,这是结合代码来发分析的,代码实现和论文的描述有些不同。
第二阶段的主成分分析
过程基本上和第一阶段一样。不同的是第一阶段输入的N幅图像要和第一阶段得到的滤波器
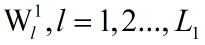 分别做卷积,得到 L1 x N 张第二阶段的训练图片。
分别做卷积,得到 L1 x N 张第二阶段的训练图片。
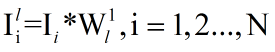 。
。
在卷积之前首先做一个0边界填充,使得卷积之后的图片和大小相同。
同样对每一张图片做分块处理,然后把由N张图片和L1 个滤波器卷积得到的图片的
分块结果合在一起,首先得到:
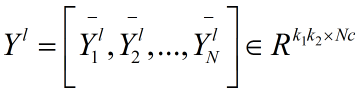
这是N张图片和其中一个滤波器卷积的分块结果。
然后将所有的滤波器输出合在一起:
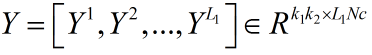
但实际上在代码的实现上,同一张图片 对应的所有滤波器的卷积是放在一起的,
其实就是顺序的不同,对结果的计算没有影响。
然后求解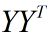 的特征向量,取前
的特征向量,取前 个最大的特征值对应的特征向量。
个最大的特征值对应的特征向量。
作为滤波器。

哈希和直方图
然后就来到特征训练的最后一步了。
然后对每一幅第二阶段主成分分析的输入图片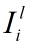 做以下计算:
做以下计算:
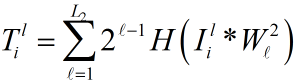
每张图片和L2个滤波器分别进行卷积。H(.)函数表示将一个矩阵转换为一个相同大小的
只包含0和1的矩阵,就是原来元素大于0,则新的矩阵对应的位置为1,否则为0.
然后乘以一个权值再加起来。权值由小到大依次对应的滤波器的也是由小到大。
然后对矩阵 ,将其分成B块,得到的分块矩阵大小为 k1k2 x B,
,将其分成B块,得到的分块矩阵大小为 k1k2 x B,
然后统计分块矩阵的直方图矩阵,直方图的范围是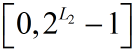 ,
,
直方图矩阵大小为 2^L2 x B。
然后将直方图矩阵向量化为行向量得到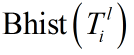 ,
,
最后将所有的的链接起来
得到代表每张训练图的特征向量。
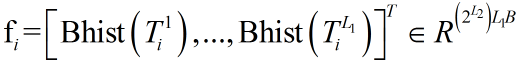
上图解释直方图统计:
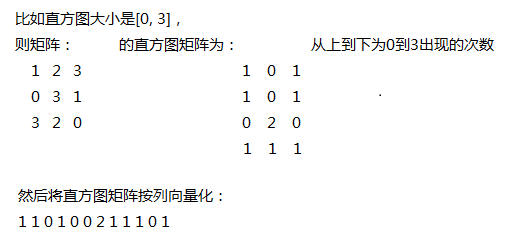
然后训练的步骤就完成了。
接着开始支持向量机的训练和测试。
测试&结果
svm的核函数用的是线性核函数,论文的matlab用的是Liblinear,
由国立台湾大学的Chih-Jen Lin博士开发的,主要是应对large-scale的data classification。
然后opencv的svm的类型我选择了CvSVM::C_SVC,参数C设为1。
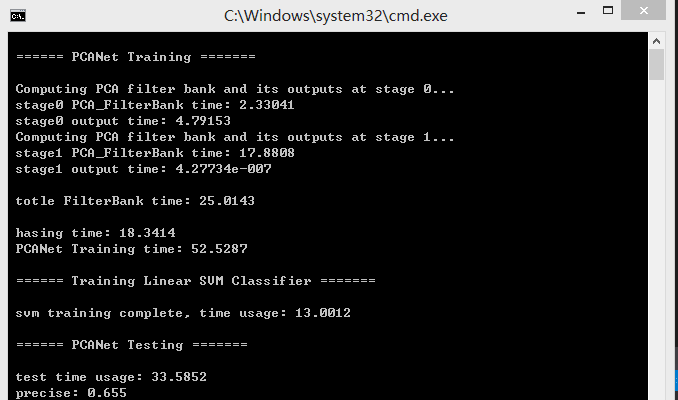
这是我将论文的matlab代码移植到opencv的测试结果,
用了120张图片作测试,精确度为65.5%,比论文中用同样的数据集caltech101,
得到的精度68%要差一点。
对SVM有兴趣的读者可以参考这位博主的文章:
支持向量机通俗导论(理解SVM的三层境界)
PCANet --- 用于图像分类的深度学习基准相关推荐
- (论文精读)PCANet:一种简单的图像分类的深度学习基线
PCANet:一种简单的图像分类的深度学习基线 \quad\quad这篇文章主要对论文<PCANet: A Simple Deep Learning Baseline forImage Clas ...
- 深度学习 图像分类_深度学习时代您应该阅读的10篇文章了解图像分类
深度学习 图像分类 前言 (Foreword) Computer vision is a subject to convert images and videos into machine-under ...
- 猫狗兔图像分类的深度学习模型设计方法
1 报告内容 1-1 背景介绍 猫狗兔图像分类项目是基于图片分类项目Dogs vs. Cats--猫狗大战的拓展项目,项目要解决的问题实际是计算机视觉领域的图像分类问题.图像分类一般的工作模式为给定 ...
- 基于TensorFlow使用RTX 2080 Ti深度学习基准(2020年)
在本文中,讨论了RTX 2080 Ti与其他GPU相比的深度学习性能.我们使用RTX 2080 Ti来训练ResNet-50,ResNet-152,Inception v3,Inception v4, ...
- 未能加载程序集或它的一个依赖项_英伟达发布kaolin:一个用于加速3D深度学习研究的PyTorch库...
由于大多数现实环境是三维的,因此理想情况下,应针对3D数据训练旨在分析视频或现实环境中的完整任务的深度学习模型.诸如机器人,自动驾驶汽车,智能手机和其他设备之类的技术工具目前正在产生越来越多的3-D数 ...
- 使用ANNdotNET GUI工具创建CIFAR-10深度学习模型
目录 编辑说明 数据准备 在Anndotnet中创建新的图像分类项目文件 在ANNdotNET中创建mlconfig 创建网络配置 结论 在这篇文章中,我们将为CIFAR-10数据集创建和训练深度学习 ...
- OpenCV-Python实战(18)——深度学习简介与入门示例
OpenCV-Python实战(18)--深度学习简介与入门示例 0. 前言 1. 计算机视觉中的深度学习简介 1.1 深度学习的特点 1.2 深度学习大爆发 2. 用于图像分类的深度学习简介 3. ...
- 深度学习笔记:在小数据集上从头训练卷积神经网络
目录 0. 前言 1. 数据下载和预处理¶ 2. 搭建一个小的卷积网络 3. 数据预处理 4. 模型训练¶ 5. 在测试集进行模型性能评估 6. 小结¶ 0. 前言 本文(以及接下来的几篇)介绍如何搭 ...
- AlexNet(深度学习模型)详解
AlexNet是一种深度卷积神经网络,由Alex Krizhevsky.Ilya Sutskever和Geoffrey Hinton于2012年在ImageNet图像分类竞赛中首次引入.这项竞赛是一个 ...
最新文章
- seaborn heatmap绘制热力图cmap参数的含义
- spring中事务的设计和实现
- Atitit.rust语言特性 attilax 总结
- 获取目录的大小函数linux,Linux C++获取文件夹大小1(通过lstat实现)
- 如何使用两个堆栈实现队列_使用两个队列实现堆栈
- 地球人口承载力估计(信息学奥赛一本通-T1005)
- mac下flink的wordcount案例
- 实现一个简单的HTTP
- MNIST数据集下载与读取
- pad连接与数据流动
- 第一次跳槽总结(产品经理,简历面试)
- 货币时间价值(学习笔记)
- CSS 样式修改技巧及心得汇总
- 【Linux】特别篇--sqlite3数据库的使用
- 《Test-Driven Development for Embedded C》读书笔记(三)
- 计算机专业屏幕尺寸,简单查看电脑屏幕尺寸、配置
- html点击按钮动复制推广地址,JavaScript实现点击按钮就复制当前网址
- 基于Matlab的磁力计校准(附源码)
- 无监督异常检测中的阈值确定
- 好失落,面试了5家公司,都让我回去等通知