Hive数据分析实验报告
文章目录
- Hive数据分析实验报告
- 实验要求
- 1 完成本地数据user_log文件上传至HDFS中
- 2 完成HDFS文件上传至Hive中
- 3 Hive操作
- IP地址规划表
- 实验步骤
- 1 数据集预处理
- 2 数据集上传HDFS
- 3 从HDFS中导出数据集至HIVE数据库
- 4 Hive操作
- (1)查看user_log表数据结构
- (2)查看user_log表简单数据结构
- (3)查看日志前10个交易日志的**商品品牌**
- (4)查询前20个交易日志中购买商品时的**时间**和**商品的种类**
- (5)用聚合函数count()计算出表内有多少条行数据
- (6)在函数内部加上distinct,查出**user_id不重复**的数据有多少条
- (7)排除顾客刷单(查询**不重复的数据**)
- (8)查询双11当天有多少人**购买**了商品
- (9)品牌2661,当天**购买**此品牌商品的数量
- (10)查询多少用户当天**点击**了2661品牌的该店
- (11)查询双十一当天男女**购买**商品比例
- (12)查询某一天在该网站**购买**商品超过5次的用户id
- (13)创建姓名缩写表,其中字段大于4条,并使查询插入,最后显示姓名缩写表格数据
Hive数据分析实验报告
实验要求
1 完成本地数据user_log文件上传至HDFS中
2 完成HDFS文件上传至Hive中
用户行为日志user_log.csv,日志中的字段定义如下:
- user_id | 买家id
- item_id | 商品id
- cat_id | 商品类别id
- merchant_id | 卖家id
- brand_id | 品牌id
- month | 交易时间:月
- day | 交易事件:日
- action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- province| 收货地址省份
3 Hive操作
(1)查看user_log表数据结构
(2)查看user_log表简单数据结构
(3)查看日志前10个交易日志的商品品牌
(4)查询前20个交易日志中购买商品时的时间和商品的种类
(5)用聚合函数count()计算出表内有多少条行数据
(6)在函数内部加上distinct,查出user_id不重复的数据有多少条
(7)排除顾客刷单(查询不重复的数据)
(8)查询双11当天有多少人购买了商品
(9)品牌2661,当天购买此品牌商品的数量
(10)查询多少用户当天点击了2661品牌的该店
(11)查询双十一当天男女购买商品比例
(12)查询某一天在该网站购买商品超过5次的用户id
(13)创建姓名缩写表 其中字段大于4条,并使查询插入,最后显示姓名缩写表格数据
IP地址规划表
![]()
实验步骤
1 数据集预处理
- 安装unzip
yum install unzip
- 创建数据存放文件夹
mkdir /usr/local/dbtaobao/dataset
- 解压数据集zip包
cp -r /mnt/hgfs/data_format.zip /usr/local/dbtaobao/dataset/
cd /usr/local/dbtaobao/dataset/
unzip data_format.zip
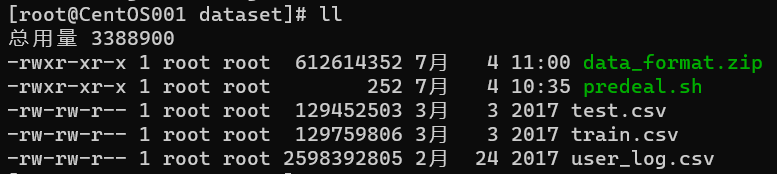
- 查看user_log.csv前5行数据
head -5 user_log.csv

- 删除第一行
sed -i '1d' user_log.csv
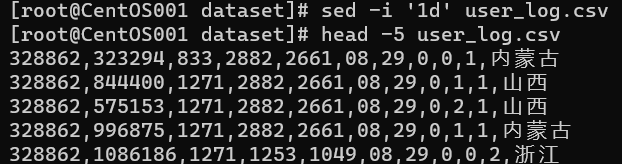
提取10000条user_log中日期为11月11日的数据,并存放于small_user_log中
- 创建脚本predeal.sh
infile=$1
outfile=$2
awk -F "," 'BEGIN{id=0;}{if($6=11 && $7=11){id=id+1;print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11","$12if(id==10000){exit}}}' $infile > $outfile
- 为predeal.h提权
chmod +x ./predeal.sh
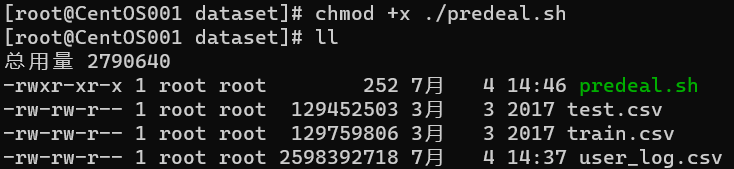
- 运行脚本predeal.sh,查看输出
./predeal ./user_log.csv ./small_user_log.csv

2 数据集上传HDFS
- 在hdfs中创建存放user_log的文件夹
start-all.sh
hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
- 向hdfs推送small_user_log.csv
hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log
![]()
- 查看上传成功的数据文件前10行
hdfs dfs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10
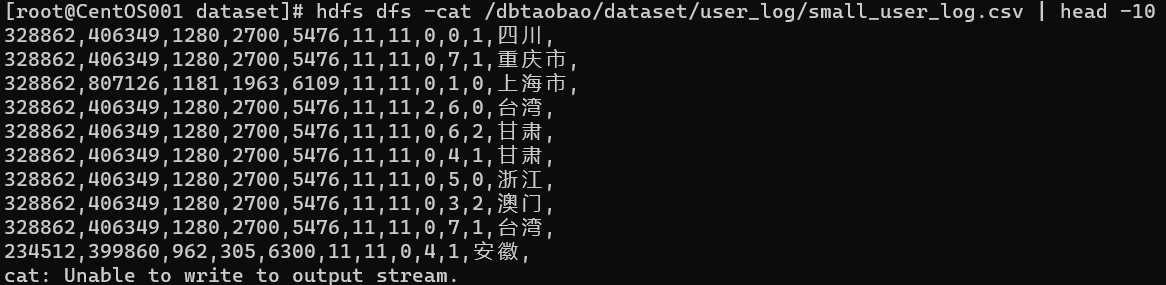
3 从HDFS中导出数据集至HIVE数据库
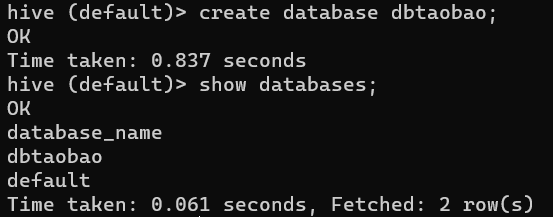
- 创建HIVE数据库dbtaobao
create database dbtaobao;
- 创建user_log表
create external table dbtaobao.user_log(user_id int,item_id int,cat_id int,merchant_id int,brand_id int,month string,day string,action int,age_range int,gender int,province string) comment 'Welcome to Alex dblab, now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile location '/dbtaobao/dataset/user_log';
- 查看表user_log前十行数据
use dbtaobao;
select * from user_log limit 10;
![]()
4 Hive操作
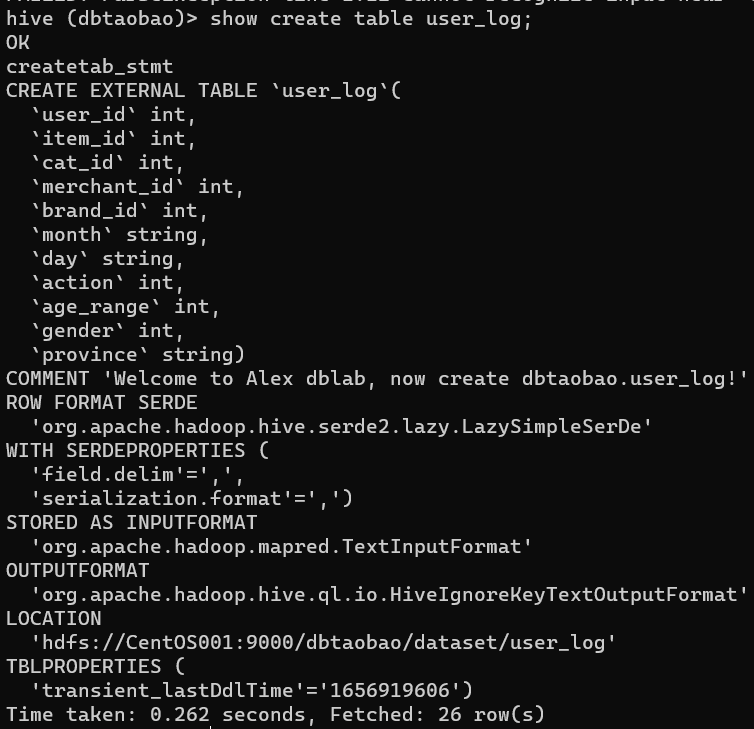
(1)查看user_log表数据结构
show create table user_log;
(2)查看user_log表简单数据结构
desc user_log;
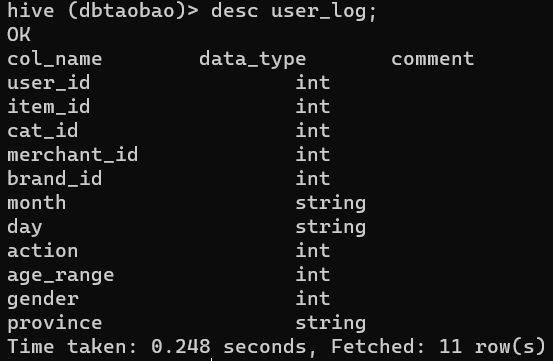
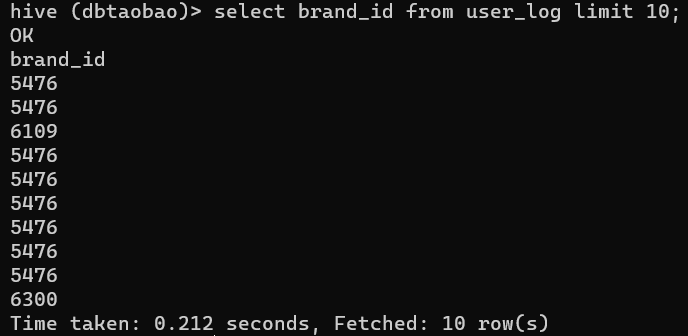
(3)查看日志前10个交易日志的商品品牌
select brand_id from user_log limit 10;
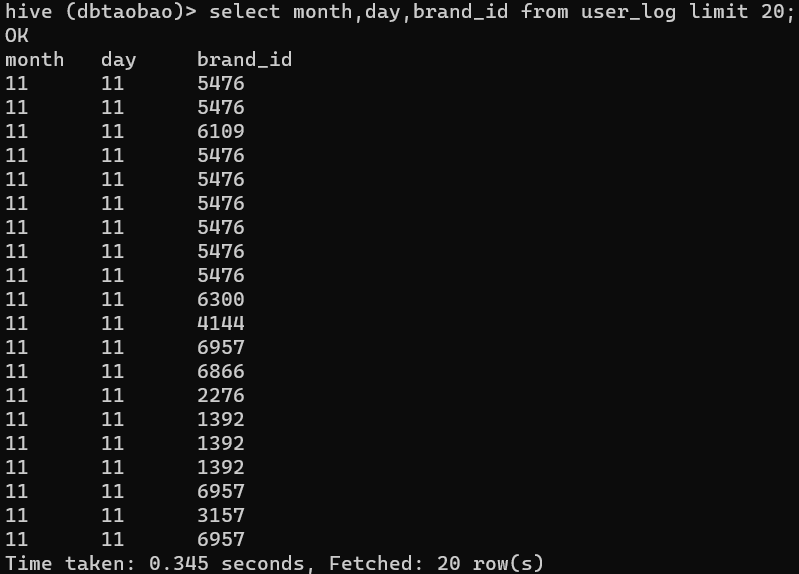
(4)查询前20个交易日志中购买商品时的时间和商品的种类
select month,day,brand_id from user_log limit 20;
(5)用聚合函数count()计算出表内有多少条行数据
select count(*) from user_log;
![]()
Result : 10000
(6)在函数内部加上distinct,查出user_id不重复的数据有多少条
select count(distinct user_id) from user_log;
![]()
Result : 358
(7)排除顾客刷单(查询不重复的数据)
select count(distinct user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province) from user_log;
![]()
Result : 9944
(8)查询双11当天有多少人购买了商品
select count(distinct user_id) from user_log where action='2';
![]()
Result : 358
(9)品牌2661,当天购买此品牌商品的数量
select count(*) from user_log where brand_id='2661' and action='2';
![]()
Result : 3
(10)查询多少用户当天点击了2661品牌的该店
select count(distinct user_id) from user_log where brand_id='2661' and action='0';
![]()
Result : 1
(11)查询双十一当天男女购买商品比例
select count(distinct user_id) from user_log where gender='0' and action='2';
select count(distinct user_id) from user_log where gender='1' and action='2';
![]()
Result : 238 (女)
![]()
Result : 214 (男)
男女比例=214/238=89.916%男女比例 = 214 / 238 = 89.916\% 男女比例=214/238=89.916%
(12)查询某一天在该网站购买商品超过5次的用户id
select user_id from user_log where action='2' group by user_id having count(action='2')>5;
![]()
Result :
user_id
1321
6058
16464
18378
23786
26516
32569
35260
41494
47958
55440
61703
69247
70816
71744
84400
106446
106629
153790
161778
171909
173427
179194
186568
188977
196638
203651
211273
212058
212504
217844
219316
234456
242845
249869
251260
256190
261596
270040
272775
274559
278823
278884
283204
284990
289429
310348
310632
320313
328230
330576
332670
333389
345251
356220
356408
366342
370679
378206
379005
389295
396129
407719
409280
422917
(13)创建姓名缩写表,其中字段大于4条,并使查询插入,最后显示姓名缩写表格数据
- 创建表gr
create external table dbtaobao.GR(user_id int,item_id int,age_range int,gender int,province string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile;
![]()
- 从表user_log中导入user_id,item_id,age_range,gender,province数据到表gr
insert into table gr select user_id,item_id,age_range,gender,province from user_log;
![]()
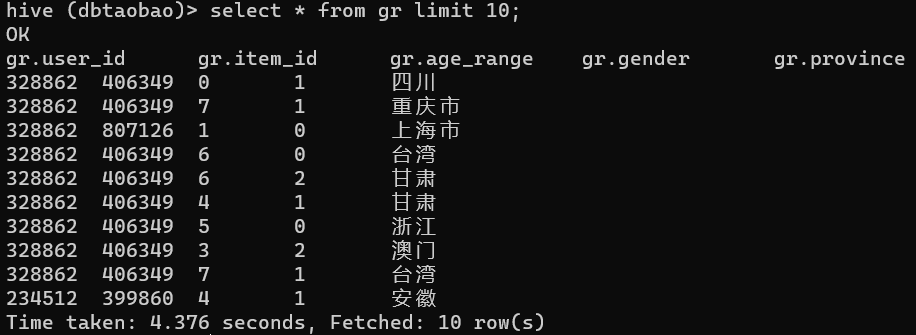
- 查询表gr的前十条数据
select * from gr limit 10;
Hive数据分析实验报告相关推荐
- python数据分析实验报告_用Python处理实验数据
开篇语 近来忙于考试以及应付专业课,基本很少写简书了.昨晚攻坚了三个学生工作的任务(妈妈的吻.好久没有这么疯狂工作了.还是很爽的哦!) 只恨这张图没有标记时间,其实已经是十二点四十多了 今天难得清静, ...
- python数据分析实验报告_Python数据分析综合小练习:销售数据分析
有这样一个小小的练习题: 卖电子商品的老板,每天记录了自己卖出的U盘,电脑支架,插座,电池,音箱,鼠标,usb数据线,手机充电线等数量,客户的需求是一方面,也可以通过客户购买关联性比较强的商品进行引导 ...
- python数据分析实验报告_Python 数据分析入门实战
本训练营中,我们将学习怎么样使用 Python 进行数据分析.课程将从数据分析基础开始,一步步深入讲解.从 Python 的基础用法到数据分析的各种算法,并结合各种实例,讲解数据分析过程中的方方面面. ...
- python数据分析实验报告_使用 Python 3 进行气象数据分析
项目简介 :本实验将对意大利北部沿海地区的气象数据进行分析与可视化.我们在实验过程中先会运用 Python 中 matplotlib 库的对数据进行图表化处理,最终在图表分析的支持下得出我们的结论. ...
- Hadoop平台搭建与数据分析实验报告
目录 Hadoop简介 实验一:构建虚拟机网络 (一)Virtual Box的安装及配置
- python股票数据分析实验报告_Python实验报告
一. 实验原理 ( 要求.任务等 ) (一).Python的开发环境 Python诞生于20世纪90年代初,是一种解释型.面向对象.动态数据类型的高级程序设计语言,是最受欢迎的程序设计语言之一. 编写 ...
- 【Python与数据分析实验报告】Pandas数据分析基础应用
目录 任务内容 (1)将数据进行转置,转置后型如eg.csv, 缺失值用NAN代替. (2) 对数据中的异常值进行识别并用NA代替. (3) 计算每个用户用电数据的基本统计量,包括:最大值.最小值.均 ...
- (精)广东工业大学 2018实时大数据分析——ShinglingMinhash实验报告
(精)广东工业大学 2018实时大数据分析--Shingling&Minhasn实验报告 一.实验内容 采用Shinling及Minhash技术分析以下两段文本的Jaccard相似度: (1) ...
- 数据分析挖掘实验报告及算法源码
数据分析挖掘实验报告及算法源码 四个实验21面,帮助你学习参考使用,帮助你取得更好成绩 报告地址:数据分析挖掘实验报告及其算法源码 1.Apriori关联规则算法 必修 实验类型 设计 Python3 ...
最新文章
- 企业推广OA信息化三大法宝
- twitter storm源码走读(二)
- linux ejb远程调用,[转载]在容器外使用EJB 3.0 Persistence
- CSS基础必备知识点04
- 别等找工作时才明白:程序员只会敲代码是不行的!不看后悔!
- python教程推荐-关于推荐系统的详细介绍
- Github 是如何用 Github 撰写 Github 文档的
- 结构梁配筋最牛插件_结构工程师应该了解的一些基本概念知识
- 概率图模型(PGM):贝叶斯网(Bayesian network)初探
- 缓和曲线回头曲线交点法坐标计算实例
- FT232RL FTDI USB转串口芯片SSOP28 国产替代
- 银河英雄传说旗舰名称考证—帝国军
- 什么是应用宝统一链接服务器,腾讯只悄悄地在手Q中整合应用宝,就开始逆天了...
- 如何使用中国知网查询文献,并自动生成参考文献格式引文?
- 国际结算银行:嵌入式监管可大幅简化合规监管
- 【目标检测】K-means计算anchors
- 数据分析师成长路径-第二阶段
- ARM NEON优化4.RGB图像转灰度图
- 计算机软盘与磁性材料,磁盘,硬盘,软盘分别是什么,有什么联系
- 记一次投票系统维护以及防止刷票springboot+redis