机器学习为您揭秘雾霾怎么形成
通过最佳实践帮助您实现上述案例效果
Step1:数据导入MaxCompute
1.1 创建需要上传的本地数据
北京天气指标表:
| 字段名 | 含义 | 类型 | 描述 |
| time | 日期 | string | 精确到天 |
| hour | 时间 | string | 表示的是时间,第几小时的数据 |
| pm2 | 指标 | string | pm2.5的指标 |
| pm10 | 指标 | string | pm10的指标 |
| so2 | 指标 | string | 二氧化硫的指标 |
| co | 指标 | string | 一氧化碳的指标 |
| no2 | 指标 | string | 二氧化氮的指标 |
源数据:wumai_data
1.2 创建MaxCompute表
1.2.1 开通MaxCompute
阿里云实名认证账号访问https://www.aliyun.com/product/odps ,开通MaxCompute,选择按量付费进行购买。
http://img.alicdn.com/tps/TB1TxkNOVXXXXaUaXXXXXXXXXXX-1124-472.png" width="836">
http://img.alicdn.com/tps/TB1qRw3OVXXXXX_XFXXXXXXXXXX-1243-351.png" width="836">
http://img.alicdn.com/tps/TB1gvgQOVXXXXXUXVXXXXXXXXXX-1208-337.png" width="836">
1.2.2 数加上创建MaxCompute project
操作步骤:
步骤1: 进入数加管理控制台,前面开通MaxCompute成功页面,点击管理控制台,或者导航产品->大数据(数加)->MaxCompute 点击“管理控制台”。
http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/pic/49126/cn_zh/1487754370705/a1.png" width="836">
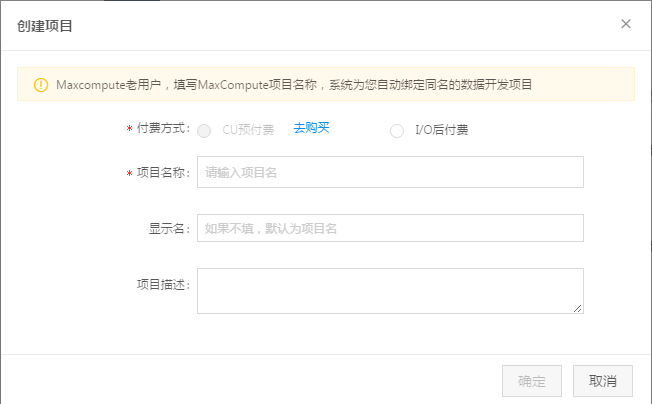
步骤2: 创建项目。付费模式选择I/O后付费,输入项目名称:
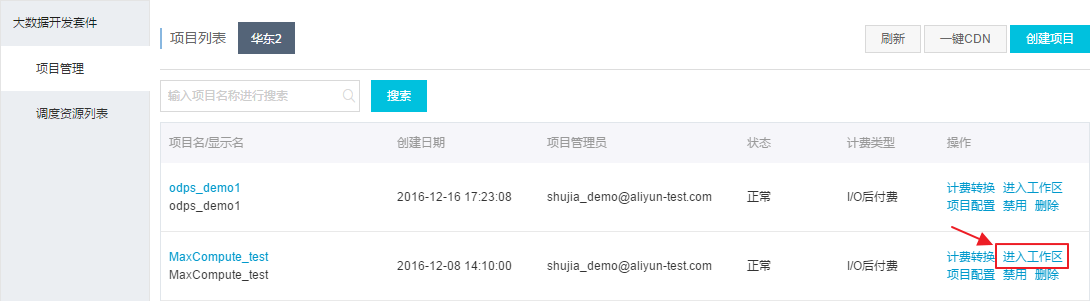
步骤3: 创建MaxCompute表。进入大数据开发套件的数据开发页面:
以开发者身份进入阿里云数加平台>大数据开发套件>管理控制台,点击对应项目操作栏中的进入工作区
1.2.3 创建表
点击菜单数据管理,右上新建表

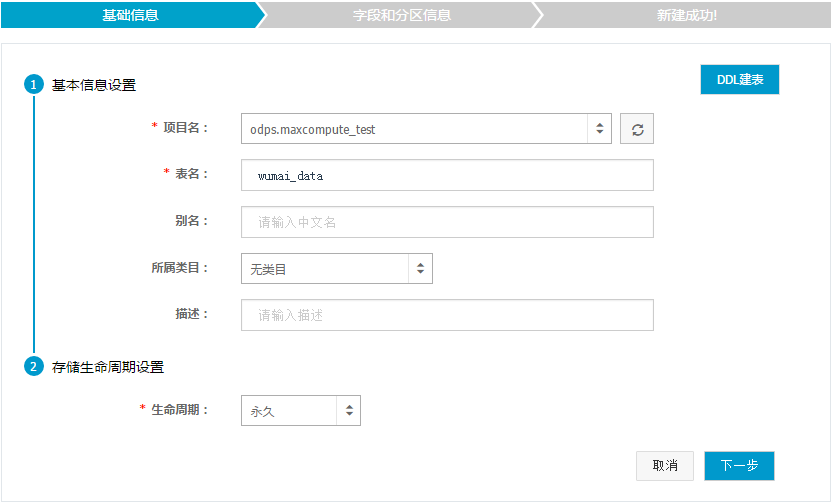
1.2.4 填写信息配置
在新建表页面中填写基础信息的各配置项,点击下一步
在新建表页面中填写字段和分区信息的各配置项

1.2.5 点击提交
新建表提交成功后,系统将自动跳转返回数据表管理界面,点击我管理的表即可看到新建表
1.3 导入本地文件
进入大数据开发套件控制台,点击对应项目的进入工作区,点击菜单数据开发-->导入-->导入本地数据

选择目标表,并选择字段匹配方式,点击导入

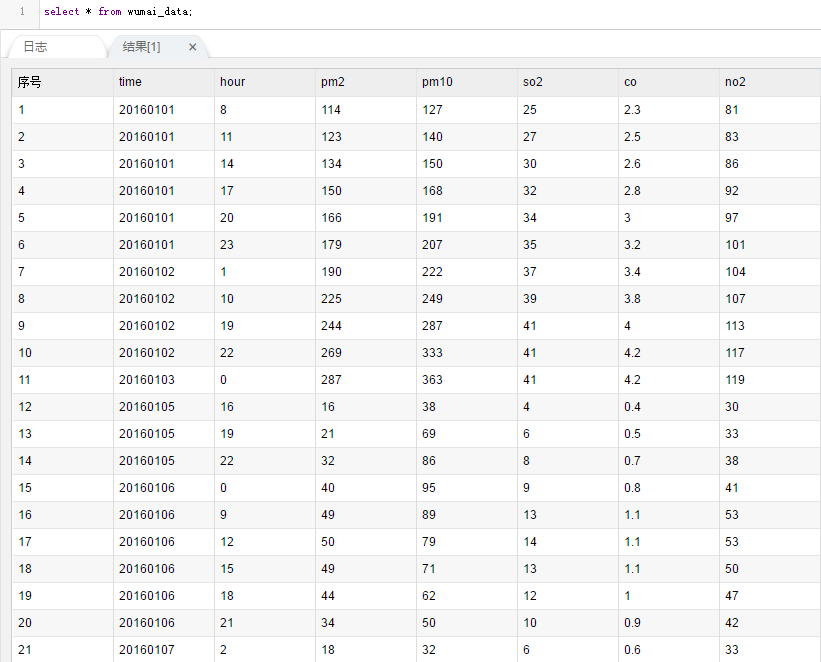
文件导入成功后,系统右上角将提示文件导入成功,同时可以执行select语句查看数据
Step2:机器学习中的数据准备
进入机器学习管理控制台,点击对应项目的进入机器学习
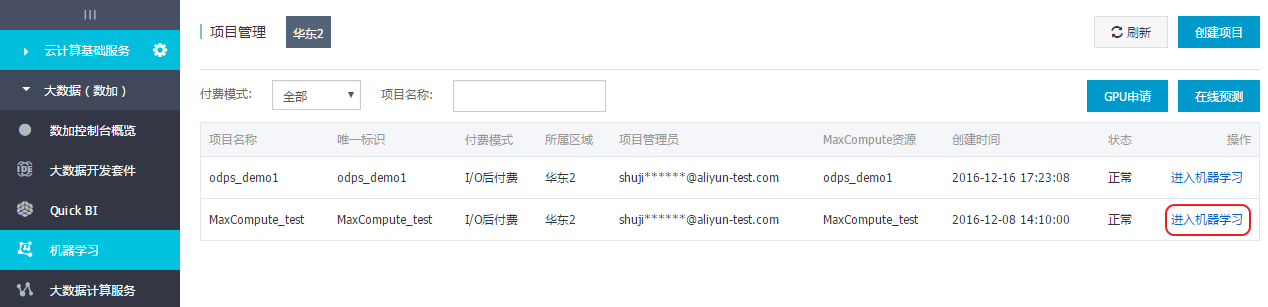
选择需要的租户及工作空间,点击“提交”
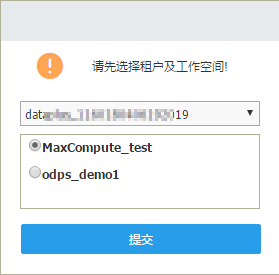
进入机器学习页面后,右击我的实验点击新建空白实验,输入实验名和实验描述

切换到组件栏,向画布中拖入读数据表,点击读数据表,在右侧表选择栏填入你的MaxCompute表
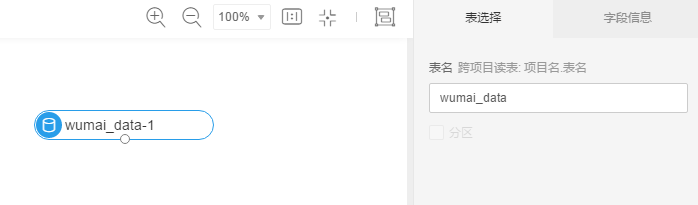
切换到字段信息栏,可以查看输入表的字段名、数据类型和前100行数据的数值分布

Step3:数据探索流程
实验流程图:
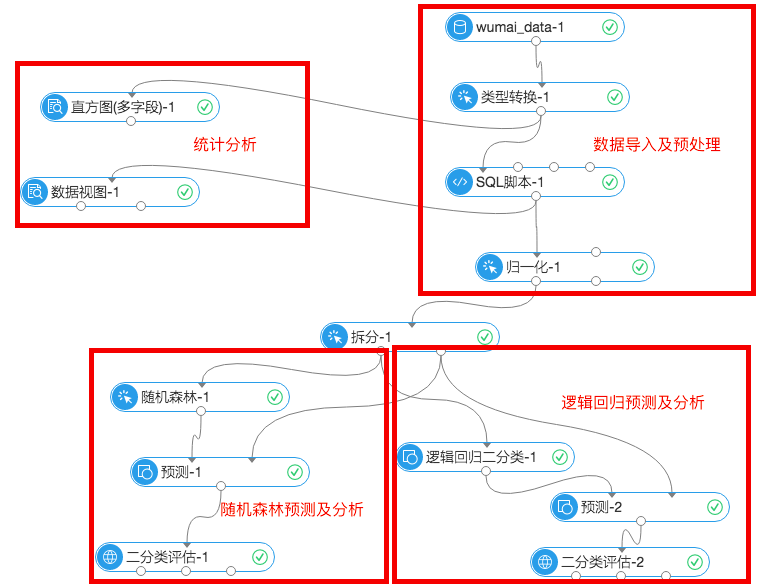
3.1 数据预处理
3.1.1 类型转换
通过类型转换把string型的数据转double。把pm2这一列作为目标列,数值超过200的情况作为重度雾霾天气打标为1,低于200标为0
向画布中拖入数据合并-->类型转换,将源数据表的数据输入到类型转换中,点击类型转换,在右侧进行字段设置
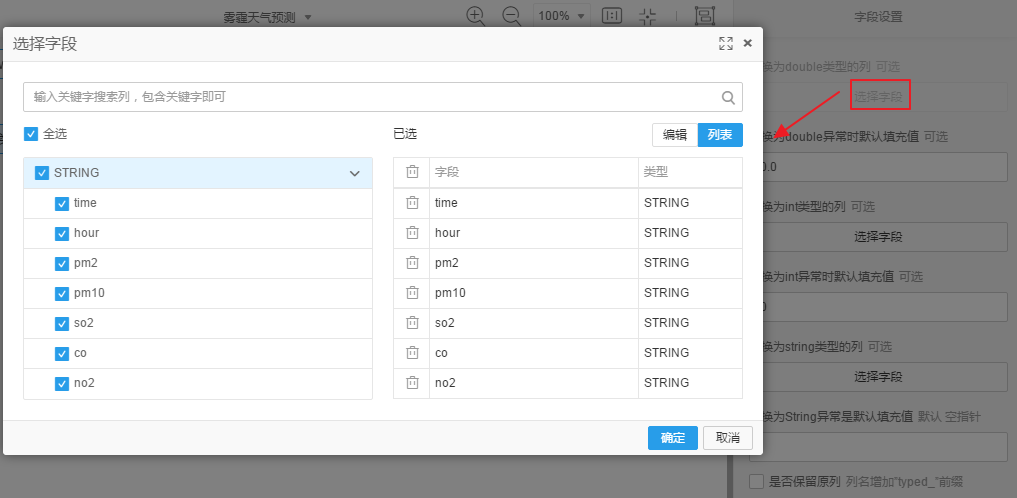
右击类型转换点击执行后,查看数据
3.1.2 SQL脚本
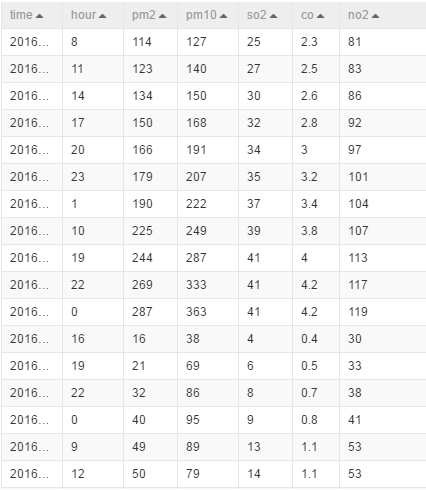
向画布中拖入工具-->SQL脚本,将类型转换的结果输入到SQL脚本中,点击SQL脚本,在右侧写入SQL语句
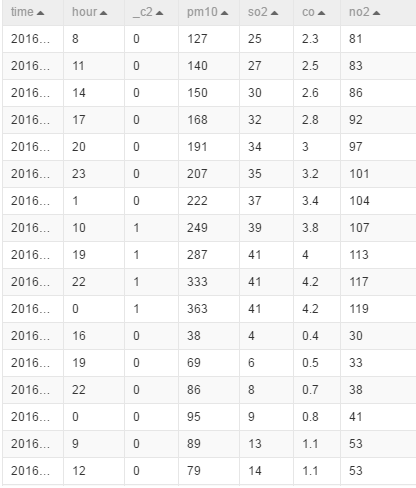
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1};
右击SQL脚本点击执行后,查看结果
3.1.3 归一化
归一化主要是去除量纲的作用,把不同指标的污染物单位统一。
向画布中拖入数据合并-->归一化,将SQL脚本输入到归一化数据表中,点击归一化,在右侧选择字段
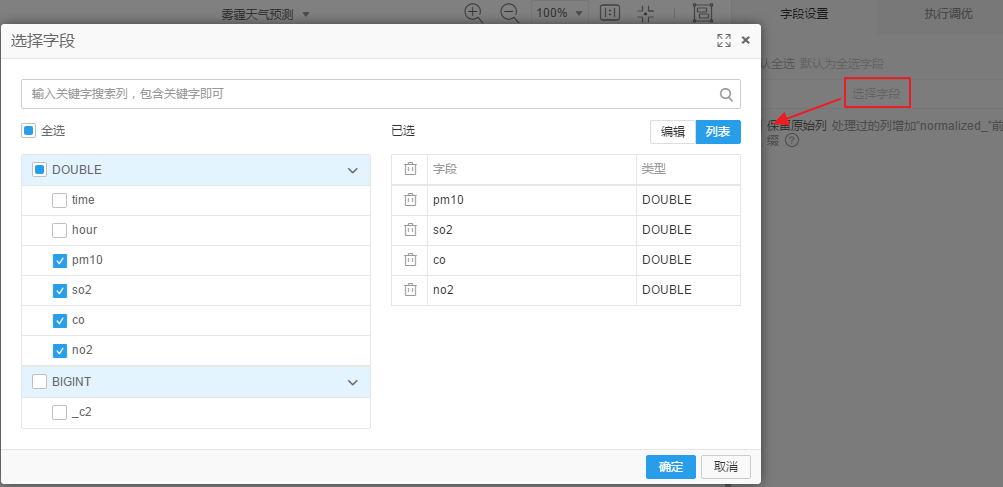
右击归一化点击执行后,查看结果
http://img.alicdn.com/tps/TB1mXZJOVXXXXcZaXXXXXXXXXXX-504-485.png">

3.2 统计分析
我们在统计分析的模块用了两个组件:
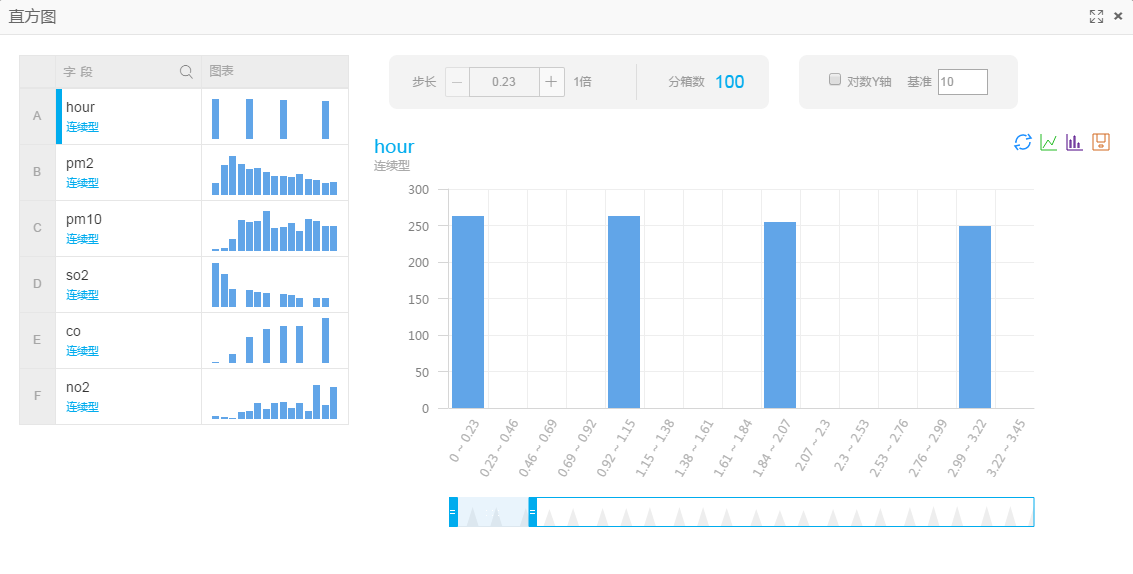
3.2.1 直方图
通过直方图可以可视化的查看不同数据在不同区间下的分布。通过这组数据的可视化展现,我们可以了解到每一个字段数据的分布情况,以PM2.5为例,数值区间出现最多的是11.74~15.61,一共出现了430次。
向画布中拖入统计分析-->直方图(多字段),将类型转换的结果输入到直方图(多字段)中,点击直方图(多字段),在右侧选择字段

右击直方图(多字段)点击执行后,查看分析报告
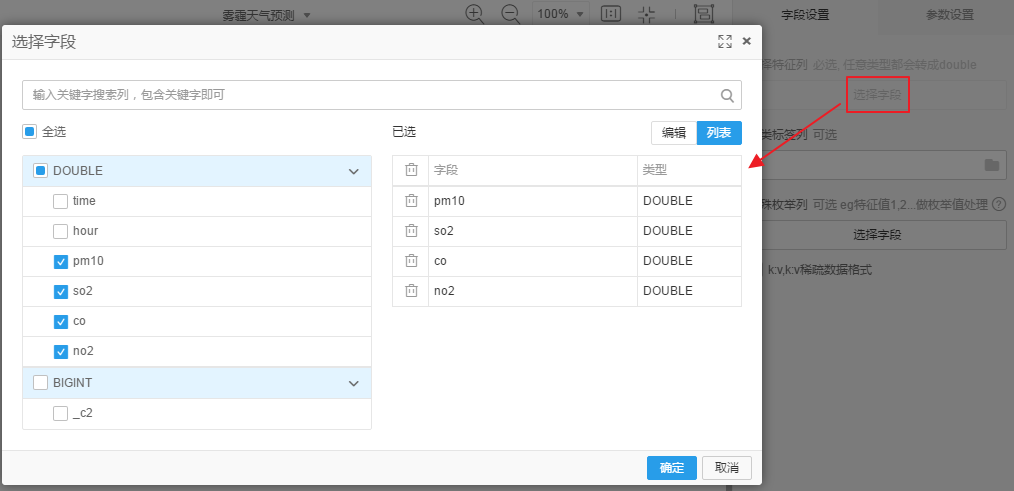
3.2.2 数据视图
通过数据视图可以查看不同指标的不同区间对于结果的影响。
向画布中拖入统计分析-->数据视图,将SQL脚本的结果输入到数据视图中,点击数据视图,在右侧选择字段
右击数据视图点击执行后,查看分析报告
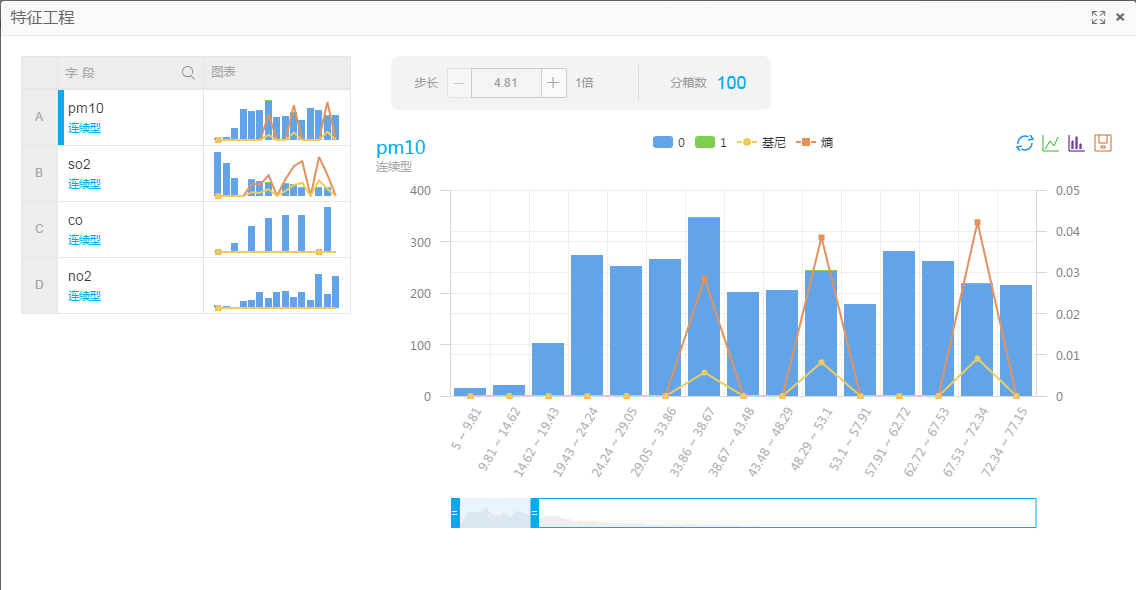
以no2为例,在112.33~113.9这个区间产生了7个目标列为0的目标,产生了9个目标列为1的目标。也就是说当no2为112.33~113.9区间的情况下,出现重度雾霾的天气的概率是非常大的。熵和基尼系数是表
示这个特征区间对于目标值的影响,数值越大影响越大,这个是从信息量层面的影响。
3.3 拆分
向画布中拖入数据预处理-->拆分,将归一化的数据结果表输入到拆分中,点击拆分,在右侧进行参数设置(这里为默认值)
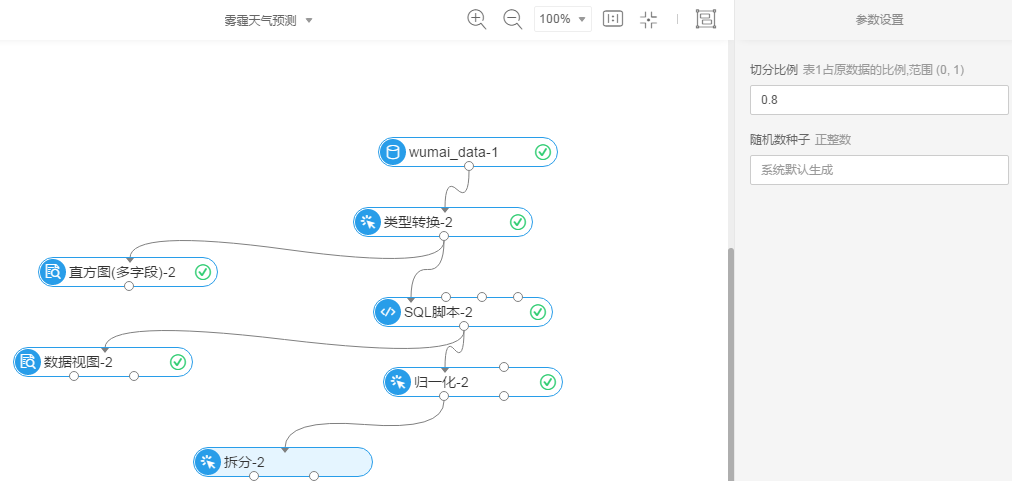
右击拆分点击执行后,查看数据


3.4 随机森林预测及分析
本案其实是采用了两种不同的算法对于结果进行预测,我们先来看看随机森林这一分支。我们通过将数据集拆分,百分之八十的数据训练模型,百分之二十的数据预测。最终模型的呈现可以可视化的显示出来,在左边模型菜单下查看,随机森林是树状模型。
3.4.1 随机森林
向画布中拖入机器学习-->多分类-->随机森林,将拆分输出表的数据输入到随机森林中,点击随机森林,在右侧选择字段和标签列


3.4.2 预测
向画布中拖入机器学习-->预测,将随机森林结果和拆分的输出表2分别输入到预测的模型结果输入和预测数据输入中
右击预测点击执行后,查看数据
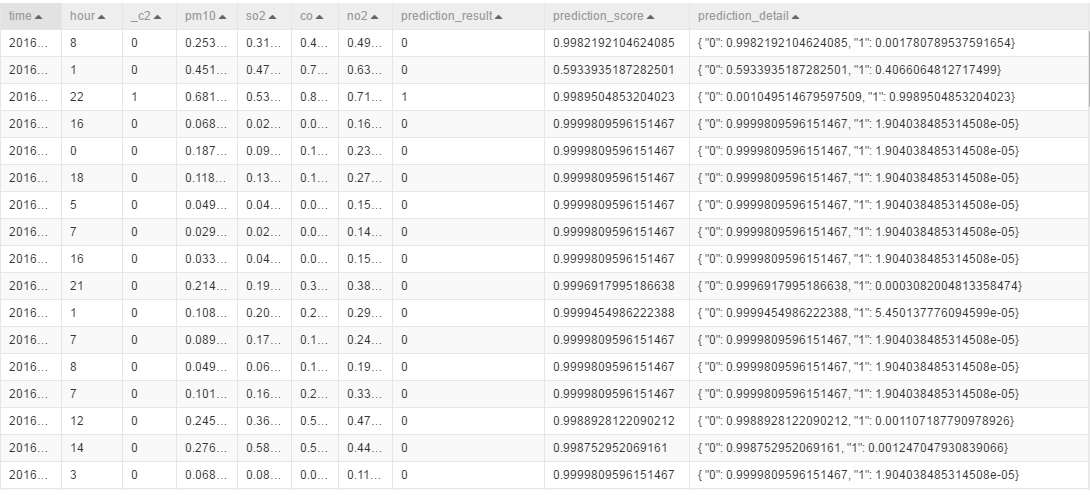
3.4.3 二分类评估
向画布中拖入机器学习-->评估-->二分类评估,将预测的结果输入到二分类评估中,点击二分类评估,在右侧进行字段设置

右击二分类评估点击执行后,查看评估报告
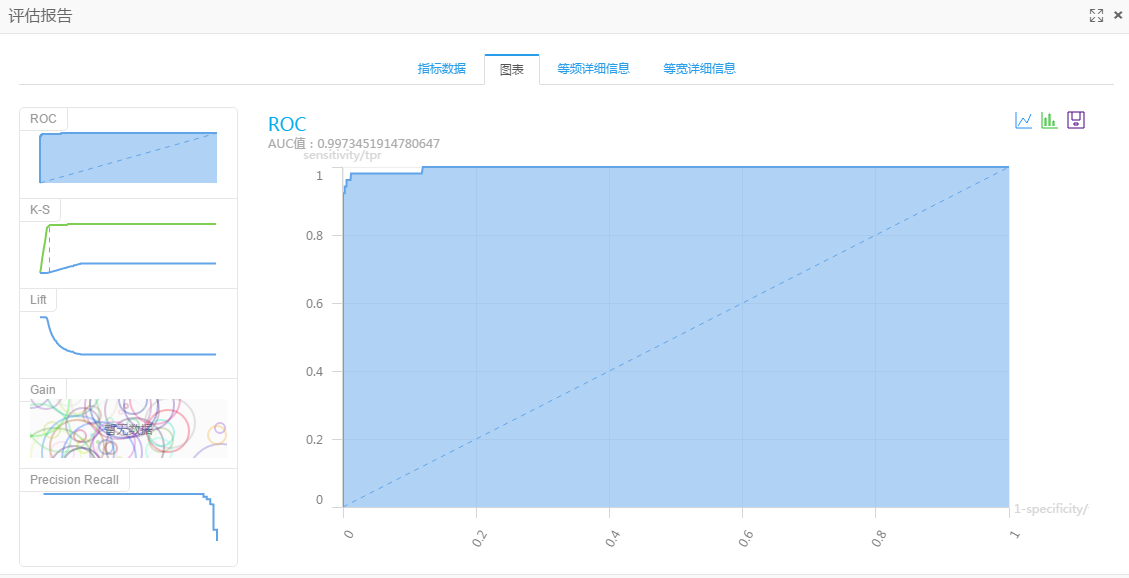
我们看到AUC是0.99,也就是说如果我们有了本文用到的天气指标数据,就可以预测天气是否雾霾,而且准确率可以达到百分之九十以上。
3.5 逻辑回归预测及分析
3.5.1 逻辑回归二分类
向画布中拖入机器学习-->二分类-->逻辑回归二分类,将拆分的输出表1连接到逻辑回归二分类的训练表中,点击逻辑回归二分类,在右侧选择字段和目标列
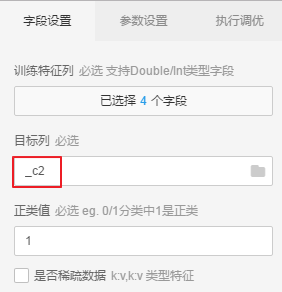
3.5.2 预测
向画布中拖入机器学习-->预测,将逻辑回归二分类的逻辑回归模型和拆分的输出表2分别输入到预测的模型结果输入和预测数据输入中
右击预测点击执行后,查看数据
3.5.3 二分类评估
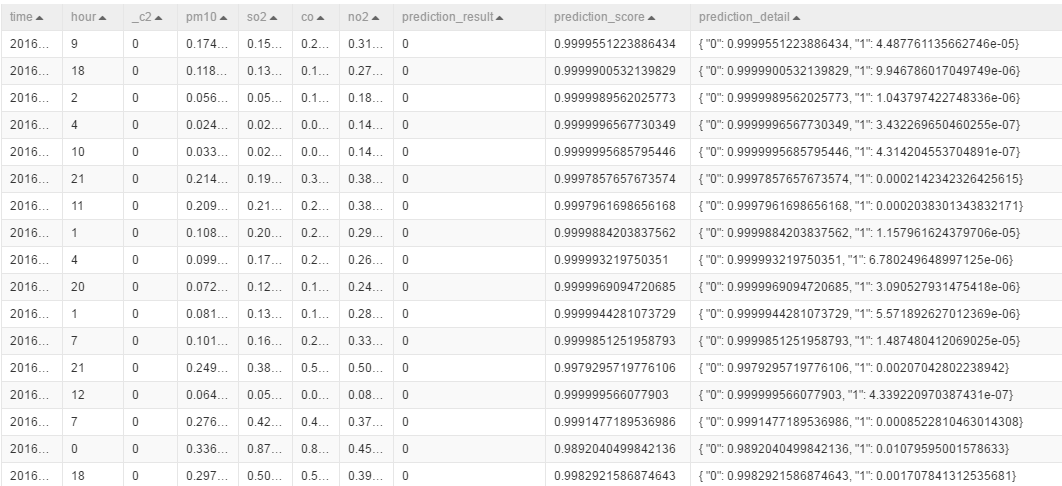
向画布中拖入机器学习-->评估-->二分类评估,将预测的结果输入到二分类评估中,点击二分类评估,在右侧进行字段设置
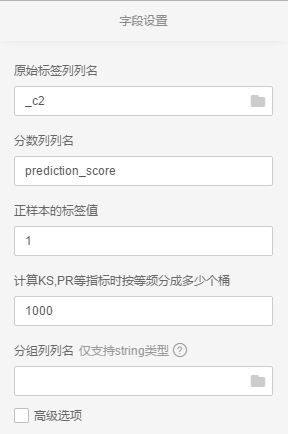
右击二分类评估点击执行后,查看评估报告

逻辑回归的AUC为0.98,比用随机森林计算得到的结果略低一点。如果排除调参对于结果的影响因素,可以说明针对这个数据集,随机森林的训练效果会更好一点。
3.6 结果评估
上面介绍了如何通过搭建实验来搭建针对PM2.5的预测流程,准确率达到百分之九十以上。下面我们来分析一下哪种空气指标对于PM2.5影响最大,首先来看下逻辑回归的生成模型:
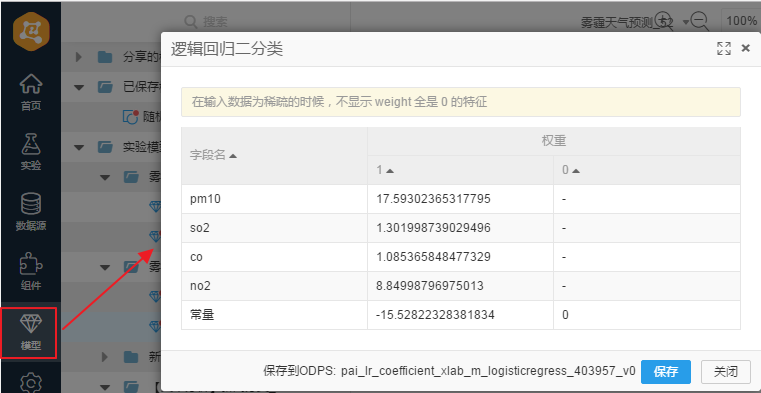
注意:要显示出生成模型需要设置自动生成PMML,如下图所示:
因为经过归一化计算的逻辑回归算法有这样的特点,模型系数越大表示对于结果的影响越大,系数符号为正号表示正相关,负号表示负相关。我们看一下正号系数里pm10和no2最大。pm10和pm2只是颗粒尺寸大小不同,是一个包含关系,这里不考虑。剩下的no2(二氧化氮)对于pm2.5的影响最大。我们只要查阅一下相关文档,了解下哪些因素会造成no2的大量排放即可找出影响pm2.5的主要因素。
下面是网上找到的关于no2排放的论述,文中说明了no2主要来自电厂和汽车尾气。[no2来源文章|http://tech.sina.cn/d/zr/2016-12-08/detail-ifxypipt0516239.d.html]
机器学习为您揭秘雾霾怎么形成相关推荐
- 【机器学习PAI实践三】雾霾成因分析
一.背景 如果要人们评选当今最受关注话题的top10榜单,雾霾一定能够入选.如今走在北京街头,随处可见带着厚厚口罩的人在埋头前行,雾霾天气不光影响了人们的出行和娱乐,对于人们的健康也有很大危害.本文通 ...
- 阿里云工程师用机器学习破解雾霾成因
原文链接;http://click.aliyun.com/m/13911/ 免费开通大数据服务:https://data.aliyun.com/m/experience 日前,一位署名为"傲 ...
- 谷歌地图的全球森林监察系统,揭秘中国雾霾的惊天秘密!
来源:老牛时评 谷歌公司最近推出的全新交互式地图--"全球森林监察"它可以实时显示全球森林的覆盖情况. 该幅地图的数据来源有多个,其中包括了NASA的森林面积覆盖率的分析数据. 于 ...
- “雾霾”天里坐看云起时-【软件和信息服务】2014.01
2013年是中国关注雾霾的元年,中国经济高速发展了30多年后,我们终于幡然醒悟:雾霾和各种污染也开始正式进入公众和各级政府的视野.VMware在12月6日召开的VSS上海站并没有因为雾霾肆虐而降低热度 ...
- 雾霾太重?深度神经网络教你如何图像去雾
导读 北京城被中度污染天气包围,到处都是灰蒙蒙一片--雾霾天又来了.从11日起,雾霾天气就开始出现,根据北京环境监测中心最新预报,这一轮雾霾短期内不会明显好转,尤其是今明两天,北京空气质量维持在4级中 ...
- 大数据预测雾霾以及存在的商机
近段时间,全国范围内尤其是京津冀地区接连陷入雾霾之困,北京更是频频发布空气重污染红色预警,中小学连续停课,机动车单双号限行.雾霾的背后,重污染天气的预警预测工作显得尤为重要,不仅可以让公众提前合理安排 ...
- 大数据分析中国冬季重度雾霾的成因(二)
2013年1月,华北地区的特征是负表面风速异常(更弱的水平扩散) 和正空气温度梯度异常(垂直对流弱大气层稳定).虽然沉淀也可能降低PM2.5,但之前的研究并未发现PM2.5的浓度和冷空气的导致沉淀有显 ...
- 大数据分析中国冬季重度雾霾的成因(一)
· 2013年华北地区经历了历史上最为严重的雾霾,研究表明雾霾是由于过去30年都未曾出现过的极其恶劣的通风条件造成的,统计分析表明这个恶劣的通风条件与上一个秋冬季的大范围降雪导致北极圈冰 ...
- 雾霾入侵机房会产生哪些危害?该如何防护?
前言: 相信雾霾的概念大家已经再熟悉不过了,空气污染对人的危害可想而知,会引发多种呼吸道的疾病,给人们的工作和生活都带来巨大影响,同样的,空气污染对于数据中心同样也有严重影响,尤其是对数据中心里运行的 ...
- 雾霾经济:这10款产品,马云看了都想投资
PMCAFF(www.pmcaff.com):互联网产品社区,是百度,腾讯,阿里等产品经理的学习交流平台.定期出品深度产品观察,互联产品研究首选. 雾霾爆表,有的公司却凭借雾霾把生意做得风生水起,连马 ...
最新文章
- 872.叶子相似的树
- response设置content-type
- 使用Navicat连接MySQL时出现2059报错的解决方法
- 第五届工业互联网大数据:配件需求29th方案与代码
- matplotlib 横坐标少了一个点_比 matplotlib 效率高十倍的数据可视化神器
- Java技巧: 根据网址查询DNS/IP地址
- 离散结构和离散数学中文书_在离散数学中对场景执行的操作
- vscode私钥设置_VSCode远程开发配置指南
- RedHat Linux 7.3基础环境搭建
- Harbor的安装部署(二)
- 408数据结构:1.顺序表的定义
- JS编写全选,复选按钮
- MATLAB离散控制系统
- 2、硬件工程师之元器件学习—电阻(二)
- python adf检验_ADF检验结果怎么看?
- 太极图形html5代码,canvas绘制太极图的实现示例
- 接入网+承载网+核心网
- Android 全埋点方案盘点
- 【强哥推荐】VSCode常用快捷键配置文件表、代码片段,记得收藏
- php lt lt lt eod,[PHP]EOD及mail发布_PHP