OpenCL 与 CUDA
根据网站资料,简单地汇编一下CUDA与OpenCL的区别。如有错误请指出。
题外话: 美国Sandia国家实验室一项模拟测试证明:由于存储机制和内存带宽的限制,16核、32核甚至64核处理器对于超级计算机来说,不仅不能带来性能提升,甚至可能导致效率的大幅度下降。
什么是OpenCL?
是由苹果(Apple)公司发起,业界众多著名厂商共同制作的面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境。便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
什么是CUDA?
CUDA是一个基于Nvidia GPU的并行计算的架构。CUDA最主要的包含两个方面:一个是ISA指令集架构;第二硬件计算引擎;实际上是硬件和指令集。 也就是说我们可以把CUDA看做是与X86或者cell类似的架构,但是是基于是GPU,而不是传统的CPU。
![]()
OpenCL实际上是什么?
- OpenCL实际上是针对异构系统进行并行编程的一个全新的API,OpenCL可以利用GPU进行一些并行计算的工作。
- OpenGL是针对图形的,而OpenCL则是针对并行计算的API。
- OpenCL开发的过程中,技术平台均为NVIDIA的GPU,实际上OpenCL是基于NVIDIA GPU的平台进行开发的。另外OpenCL的第一次演示也是运行在NVIDIA的GPU上。
- 从本质上来说,OpenCL就是一个相当于Windows平台中DirectX那样的技术。或者说,它是一个连接硬件和软件的API接口。在这一点上,它和OpenGL类似,不过OpenCL的涉及范围要比OpenGL大得多,它不仅是用来作用于3D图形。如果用一句话描述,OpenCL的作用就是通过调用处理器和GPU的计算资源,释放硬件潜力,让程序运行得更快更好。
CUDA实际上是什么?
- CUDA架构是原生的,专门为计算接口而建造的这样的一个架构,这种硬件架构包括指令集都是非常适合于这种并行计算,为异构计算而设计的一整套的架构。CUDA架构可以支持API,包括OpenCL或者DirectX,同时CUDA还支持C、C++语言,还包括Fortran、Java、Python等各种各样的语言。
![]()
OpenCL与CUDA的关系是什么?
- CUDA和OpenCL的关系并不是冲突关系,而是包容关系。OpenCL是一个API,在第一个级别,CUDA架构是更高一个级别,在这个架构上不管是OpenCL还是DX11这样的API,还是像C语言、Fortran、DX11计算,都可以支持。作为程序开发员来讲,一般他们只懂这些语言或者API,可以采用多种语言开发自己的程序,不管他选择什么语言,只要是希望调用GPU的计算能,在这个架构上都可以用CUDA来编程。
- 关于OpenCL与CUDA之间的技术区别,主要体现在实现方法上。基于C语言的CUDA被包装成一种容易编写的代码,因此即使是不熟悉芯片构造的科研人员,也可能利用CUDA工具编写出实用的程序。而OpenCL虽然句法上与CUDA接近,但是它更加强调底层操作,因此难度较高,但正因为如此,OpenCL才能跨平台运行。
- CUDA是一个并行计算的架构,包含有一个指令集架构和相应的硬件引擎。OpenCL是一个并行计算的应用程序编程接口(API),在NVIDIA CUDA架构上OpenCL是除了C for CUDA外新增的一个CUDA程序开发途径。
- 如果你想获得更多的对硬件上的控制权的话,你可以使用OpenCL这个API来进行编程,如果对API不是太了解,也可以用CUDA C语言来编程,这是两种不同编程的方式,他们有他们相同点和不同点。但是有一点OpenCL和CUDA C语言进行开发的时候,在并行计算这块,他们的概念是差不多的,这两种程序在程序上是有很大的相似度,所以程序之间的相互移植相对来说也是比较容易。

- CUDA C语言与OpenCL的定位不同,或者说是用人群不同。CUDA C是一种高级语言,那些对硬件了解不多的非专业人士也能轻松上手;而OpenCL则是针对硬件的应用程序开发接口,它能给程序员更多对硬件的控制权,相应的上手及开发会比较难一些。
- 程序员的使用习惯也是非常重要的一方面,那些在X86 CPU平台使用C语言的人员,会很容易接受基于CUDA GPU平台的C语言;而习惯于使用OpenGL图形开发的人员,看到OpenCL会更加亲切一些,在其基础上开发与图形、视频有关的计算程序会非常容易。
给点实例看看?
- OpenCL 教學: http://www.kimicat.com/opencl-1/opencl-jiao-xue-yi
- 在 Windows 下使用 OpenCL: http://www.kimicat.com/opencl-1/zai-windows-xia-shi-yong-opencl
- 在 Xcode 中使用 OpenCL: http://www.kimicat.com/opencl-1/zai-xcode-zhong-shi-yong-opencl
- CUDA 教学: http://www2.kimicat.com/cuda%E7%B0%A1%E4%BB%8B
从很多方面来看,CUDA和OpenCL的关系都和DirectX与OpenGL的关系很相像。如同DirectX和OpenGL一样,CUDA和OpenCL中,前者是配备完整工具包、针对单一供应商(NVIDIA)的成熟的开发平台,后者是一个开放的标准。
虽然两者抱着相同的目标:通用并行计算。但是CUDA仅仅能够在NVIDIA的GPU硬件上运行,而OpenCL的目标是面向任何一种Massively Parallel Processor,期望能够对不同种类的硬件给出一个相同的编程模型。由于这一根本区别,二者在很多方面都存在不同:
1)开发者友好程度。CUDA在这方面显然受更多开发者青睐。原因在于其统一的开发套件(CUDA Toolkit, NVIDIA GPU Computing SDK以及NSight等等)、非常丰富的库(cuFFT, cuBLAS, cuSPARSE, cuRAND, NPP, Thrust)以及NVCC(NVIDIA的CUDA编译器)所具备的PTX(一种SSA中间表示,为不同的NVIDIA GPU设备提供一套统一的静态ISA)代码生成、离线编译等更成熟的编译器特性。相比之下,使用OpenCL进行开发,只有AMD对OpenCL的驱动相对成熟。
2)跨平台性和通用性。这一点上OpenCL占有很大优势(这也是很多National Laboratory使用OpenCL进行科学计算的最主要原因)。OpenCL支持包括ATI,NVIDIA,Intel,ARM在内的多类处理器,并能支持运行在CPU的并行代码,同时还独有Task-Parallel Execution Mode,能够更好的支持Heterogeneous Computing。这一点是仅仅支持数据级并行并仅能在NVIDIA众核处理器上运行的CUDA无法做到的。
3)市场占有率。作为一个开放标准,缺少背后公司的推动,OpenCL显然没有占据通用并行计算的主流市场。NVIDIA则凭借CUDA在科学计算、生物、金融等领域的推广牢牢把握着主流市场。再次想到OpenGL和DirectX的对比,不难发现公司推广的高效和非盈利机构/标准委员会的低效(抑或谨慎,想想C++0x)。
我接触的很多开发者(包括我本人)都认为,由于目前独立显卡市场的萎缩、新一代处理器架构(AMD的Graphics Core Next (GCN)、Intel的Sandy Bridge以及Ivy Bridge)以及新的SIMD编程模型(Intel的ISPC等)的出现,未来的通用并行计算市场会有很多不确定因素,CUDA和OpenCL都不是终点,我期待未来会有更好的并行编程模型的出现(当然也包括CUDA和OpenCL,如果它们能够持续发展下去)。
1. CUDA有远好于OpenCL的生态系统,更易用,对程序员更友好。OpenCL的API设计怪异,缺乏一致性,功能亦不正交,很不直观,远未成熟。
2. OpenCL的portability被夸大了,事实上根据我的经验,AMD和NV的OpenCL实现,组合行为是有差异的,并且有些十分隐蔽,难于调试。而且同样的代码在AMD和NV是有性能差异的,有时候差异非常大,为了一致的性能不得不写两套代码。如果有更多的vendor呢?
3.OpenCL作为开放的标准,完全依赖于厂商的实现,不同厂商支持标准不同。如果NV放弃支持OpenCL,那它还是通用的开放的标准吗?
4. 即使NV倒闭,会有OpenCUDA出现的。
现在AMD在推新的HSA,其IL类似NV的PTX,不知是何用意。Java会在未来(JAVA 9? 2015?)支持NV/AMD GPU 加速。OpenCL的美好只存在于未来,问题是这个未来有多远。
CUDA助力OpenCL GPU并行计算无处不在
通用计算新锐OpenCL CUDA来助阵
通用计算新锐OpenCL CUDA来助阵
GPU经过多年的发展,从功能单一的3D计算逐步扩充了视频解码、通用计算等,而且值得一提的是通用计算这个目前最璀璨的技术新星被科研单位及个人消费者普遍关注。
众所周知,NVIDIA是GPU的通用计算技术先驱者,它的CUDA架构产品深入人心。而在通用计算的API层面不止NVIDIA一家独秀,Apple(苹果)公司主导的OpenCL也赢得了业界同行的大力支持,当然NVIDIA也是OpenCL的核心成员之一。

2008年12月9日,2008亚洲SIGGRAPH大会上,全球视觉计算技术的行业领袖NVIDIA公司于今日正式宣布,完全支持Khronos Group新近发布的OpenCL 1.0技术规范。OpenCL(开放式计算语言)是一种全新计算应用程序接口
(API),它让开发人员能够利用GPU内部巨大的并行计算动力。OpenCL的加入是GPU革命史上又一重大的里程碑,为NVIDIA开发人员提供了另一个功能强大的编程选择。

Khronos Group是一个非营利的,会员组织的行业协会;Khronos 致力于创造免授权费用的应用程序接口 API 及相关标准生态系统,并将其标准及相关技术应用于包括手持设备,控制台以及嵌入式系统中的高级动态多媒体应用,以提供用以将这些多媒体技术转化为现实生产力的基础。例如OpenGL ES、OpenKODE、OpenMAX、OpenVG、OpenSL ES、COLLADA等,当然还有今天的主角OpenCL。

OpenCL一经提出就得到了全球顶级软硬件厂商的广泛支持,尤其是已经走在通用计算前沿的NVIDIA公司更是大力支持,NVIDIA公司嵌入式内容副总裁Neil Trevett就在Khronos机构中担任OpenCL工作组主席一职。
Neil Trevett先生表示:“OpenCL技术规范是NVIDIA等行业领袖意识到这一机遇之后所取得的成果。凭借其开放式、跨平台的标准,该技术规范将在整个异构并行计算市场中得到更多的认可。NVIDIA将继续活跃于OpenCL工作组以便推动该技术规范的发展,并在所有NVIDIA平台中提供对OpenCL的支持,从而为开发人员提供另外一种方式来利用我们GPU中的超强计算动力。”
OpenCL是什么?与CUDA关系如何?
OpenCL是什么?与CUDA关系如何?

OpenCL实际上是针对异构系统进行并行编程的一个全新API,简单来说OpenCL它可以利用GPU进行一些并行计算方面的工作。这是API应用程序的编程接口,图形里面也有很多API,比如OpenGL、DirectX是针对图形的,OpenCL是针对并行计算的API。
OpenCL开发人员可以利用GPU和CPU的计算能力,把GPU和CPU异构的系统运用在很多并行计算的领域里面。Khronos就是这样一个组织,它由很多厂商组成,并有非常多的成员,这个工作组同时也是OpenCL的一个协调机构,也就是Khronos这个工作组它来负责制定OpenCL的规格、架构等等各方面。业界最主要的和图形或者和计算相关的厂商都是Khronos的成员。
值得一提的是OpenCL得到Khronos组织里很多成员的支持,同时也验证大家对开发GPU并行计算的能力这个需求越来越多,也正是因为有这个需求成就了OpenCL。

那么NVIDIA和OpenCL是一个怎样的关系呢?
实际上OpenCL对于业界来说是非常重要也是非常好的一个标准,它的出现令业界拥有了一个共同的标准利用GPU的强大计算能力,然后应用在图形以外各种各样的并行计算中。其中NVIDIA一直也参与OpenCL的工作,正如前文所提及的NVIDIA副总裁Neil Trevett先生,他现在就任OpenCL工作组的主席,引导很多OpenCL的开发,当然这个组织中还有很多其他开发公司。
OpenCL最早是Apple公司提出来的,从OpenCL一开始NVIDIA就和Apple公司进行非常紧密的合作。OpenCL开发的过程中,它的技术平台都是NVIDIA的GPU,实际上OpenCL是基于NVIDIA GPU的平台进行开发的。另外OpenCL的第一次演示,也是在NVIDIA的GPU上演示的,可以说到目前为止NVIDIA GPU几乎是进行OpenCL程序的唯一的平台。
另外还有非常重要的一点,对于Apple公司来说,他们是把GPU计算当成一种未来的趋势,他们非常重视OpenCL,他们将会在新一代的产品里面选择最适合于OpenCL运行的平台。所以说他们新一代苹果的笔记本电脑全都采用了NVIDIA的平台,不管是MacBook Pro、Mac OSX都是采用了NVIDIA公司的平台。实际上这也是从另外一个方面证明NVIDIA的GPU对于OpenCL的支持,到目前为止是最好的一个硬件的平台。
彻底了解CUDA架构/OpenCL存在意义
彻底了解CUDA架构/OpenCL存在意义

CUDA是什么?很多人认为它是一个由NVIDIA设计的一种新软件或者新API,不过笔者在此要告诉大家,CUDA是一种硬件架构,也就是说目前NVIDIA的GeForce产品全都基于CUDA架构设计。CUDA架构最主要的包含两个方面:一个是ISA指令集架构;第二硬件计算引擎。实际上它就是硬件和指令集,这两个方面是CUDA的架构。
NVIDIA GPU的架构就是CUDA的架构,举例来说,你可以把它看成是跟Intel的X86或者IBM的Cell,他们都是CPU架构,而CUDA架构是基于GPU的架构。
CUDA的GPU架构和CPU架构很类似,比如X86是包含一套指令集和执行X86各种各样的CPU,而对于CUDA也是一样的,NVIDIA有一套指令集ISA,还有各种各样执行指令集和各种各样的硬件引擎。另外CUDA到目前为止,它包含了一个C语言的编译器,就是在CUDA上面的C语言,CUDA这个架构还可以支持其他的API,包括OpenCL或者DirectX,同时以后NVIDIA的CPU还支持其他语言,包括Fortran、Java、Python等各种各样的语言,可以说这种架构是原生的,专门为计算接口而建造的这样的一个架构。CUDA硬件架构包括指令集都是非常适合于并行计算,为异构计算而设计的一整套架构。

也许会有人疑问,既然有了CUDA为何还需要OpenCL,或者类似OpenCL的API呢?
简单来说,对于编程人员他可以选择不同的方式来进行编程,他们可以选择OpenCL API编程也可以选择C for CUDA语言来编程。
而API和语言的编程、开发存在着本质的不同,API是一个编程接口,它的核心是函数库和应用程序开发的一个硬件接口。用API来编程的话它有一个好处,那就是可以访问比较低层次的硬件资源,但这样的最大化控制硬件资源带来了很多弊端,例如在内存管理上就必须靠编程人员手动控制,这就需要编程人员要拥有高超的编程技术和深厚的经验积累。而就C for CUDA来说,编程人员在利用C for CUDA语言来编程的时候,无需考虑过多与自身编程目的以外的因素。再拿前文提及的内存管理来说,C for CUDA使用Runtime进行管理。
不过不管OpenCL还是C for CUDA语言来编程,最终它都是需要通过一个驱动程序来变成一个PTX的代码,PTX相当于CUDA的指令集来进行执行,然后交给图形处理其或者交给硬件来进行执行。这两个最终达到都是使用PTX或者在我们GPU上进行执行。
简单来说,如果你想获得更多的对硬件上的控制权,你可以使用API来进行变成。而如果你对API不是十分了解,或者说无法很好的掌控API编程,这时你可以用CUDA C语言来编程。二者是两种不同编程的方式,它们有相同点也有不同点,但是有一点OpenCL和CUDA C语言进行开发的时候,在并行计算方面它们的概念十分接近,这也就奠定了程序之间的相互移植会比较容易。

对C语言编程了解的读者应该知道,C语言利用的驱动程序就是API,也许谈及这个很抽象,实际上C for CUDA就是一种C语言的扩展,而针对扩展的主要方面就是并行运算编程,这些是通过C的扩展来获得。基本上认为CUDA的程序也是一种标准的C语言的程序,然后你使用一些关键字然后来对并行这方面计算,然后做一些区分。C语言最终编译会成为PTX的代码,然后在GPU上执行。
OpenCL是一个API,就是应用程序的编程接口,OpenCL和OpenGL很像,这种API你可以调用API里面的函数库,通过程序开发调用各种各样的函数,实现各种各样的功能。对于API来说一般它对硬件设备有比较完整的访问权,你可以访问硬件设备,可以对内存进行管理,最后OpenCL通过编译和驱动程序可以生成PTX代码在GPU上进行执行。
OpenCL未来发展目标激进
OpenCL未来发展目标激进

通过OpenCL的路线图我们能够看出,目前OpenCL还处于Alpha版本,但NVIDIA的产品已经可以非常好的支持OpenCL。明年第一季度Khronos Group会发布OpenCL Beta版本,而OpenCL1.0正式版也可能在明年正式推出。不过OpenCL最开始可能出现在Mac OS上,不过随着以后的逐渐扩展,例如Windows或者Linux等系统都将会得以支持。

对于CUDA C语言,NVIDIA一直不断地对其进行更深层次的开发,同时也不断的有新版本的出现,到目前为止已经是CUDA 2.0。CUDA C语言NVIDIA研发已经超过5年时间,基本上从2003年左右就开始开发这个语言开发。
并且到目前为止,开发人员的数量已经是超过25000人,应用程序超过100个,特别在科学计算的领域里CUDA的应用极为广泛,几乎涉及到各种各样的HPC高性能计算的领域。甚至现在HPC进入排行榜前100的高性能计算机里面也有使用NVIDIA基于CUDA的Tesla系统,它的开发语言正是使用了CUDA C语言。目前GPU集群组成的高性能计算机集群数量已经达到了30个,在中国也有相关产品。
CUDA C语言是一个跨操作系统的开发工具,现在支持Windows、Linux、Mac OS,几乎把控了目前最主流的操作系统。NVIDIA的CUDA C语言提供了很多的库,这些库主要包括FFT、BLAS等,它们可以提供各种各样现成的代码让编程人员使用。
也许有这样的开发者,他可能对CUDA并不熟悉,但他又想要使用CUDA的高性能计算该怎么办?很简单,他就把现有的应用软件,例如FFT,使用CUDA的FFT的代码直接替换,就这样他便可以获得20倍以上的性能提升。也就是说,这些库是CUDA C语言非常重要的资源,可以让大家缩短研发周期、体验CUDA带来的高性能,例如一些数学软件像Matlab、Mathematica、LabView都有CUDA的插件,可以使用C语言的插件让他更容易的利用CUDA。
CUDA/OpenCL共进退 前途无量
CUDA/OpenCL共进退 前途无量

这是NVIDIA的CUDA C语言路线图,现在CUDA正处于2.0版本,到今年年底NVIDIA可能会推出CUDA 2.1版本,到明年会有CUDA 2.2、CUDA2.3版本,最后迎来CUDA 3.0。随着CUDA版本的升级,它的功能也在不断地升级,比如最早的CUDA只能支持单精度的浮点计算,现在可以支持双精度,还可以支持各种各样的库。

总结的来说,OpenCL无论对开发人员还是业界人员、消费者来说,都是一个非常好的API,一个应用程序的接口。它可以使开发者更容易的开发出跨平台GPU计算程序,并将GPU强大的计算能力利用到各种各样应用计算中。
对于NVIDIA来说,现在CUDA架构上除了C语言以外,现在新增加了OpenCL或者DX11这样的API,对于开发人员来说也是提供了一种更好的GPU计算的开发环境。因为对API很熟悉的开发人员,他们肯定会很高兴的看到OpenCL或者新的API的加入,对于这些人来说他们很容易利用这种API进行各种各样GPU计算程序开发。对于NVIDIA来说还会继续对C语言包括其他语言的支持,实际上对NVIDIA CUDA C语言来说Runtime C仍是目前唯一的语言环境。今后除了C语言外,NVIDIA还会推出更多的CUDA语言,这包括Fortran,还会有Java等。
性能与功能兼备 OpenCL和CUDA全解释

Khronos组织最近规范了OpenCL 1.0, OpenCL实际上是针对异构系统进行并行编程的一个全新的API,简单来说OpenCL它可以利用GPU,然后进行一些并行计算这方面的工作,这是API应用程序的编程接口,图形里面也有很多API,比如OpenGL那是针对图形的,OpenCL是针对并行计算的API。OpenCL开发人员可以利用GPU和CPU的计算能力,把GPU和CPU异构的系统运用在很多并行计算的领域里面。Khronos是一个组织,有很多厂商组成,有非常多的成员,这个工作组同时也是OpenCL的一个协调机构,也就是Khronos这个工作组他来负责制定OpenCL的规格、架构等等各方面。业界最主要的和图形或者和计算相关的厂商都是Khronos的成员。

OpenCL里面有很多的成员,这就导致了有更多可以利用OpenCL来开发的程序、软件以及各种各样的应用。这从一方面肯定了OpenCL强大的聚合实力,但一方面也预示着这将会形成一个旺盛的需求。实际上,OpenCL对于业界来说是非常重要也是非常好的一个标准,NVIDIA看准了这一标准,利用GPU的强大计算能力应用在图形以外各种各样的并行计算方面,NVIDIA一直在参与OpenCL的工作。NVIDIA副总裁Neil Trevett,目前则是OpenCL工作组的主席,引导很多OpenCL的开发。这个组织里面当然还有很多其他开发公司。NVIDIA公司不少员工都在参与这项工作。

OpenCL最早是Apple公司提出来的,由于OpenCL一开始NVIDIA就和Apple公司进行非常紧密的合作。所以目前OpenCL也完全是基于NVIDIA GPU的平台进行开发的。Apple十分重视OpenCL,不管是MacBook Pro、Mac OSX等新产品采用了NVIDIA的平台。目前OpenCL路线图目前还是属于Alpha版本,明年第一季度可能是Beta的版本,09年时OpenCL1.0可能正式推出,OpenCL最开始可能出现在Mac OS上,以后逐渐的扩展到其他的操作系统,像Windows或者Linux。

NVIDIA一直还是不断地对这个语言进行更深层次的开发,到目前为止已经是CUDA 2.0。开发人员的数量已经超过25000个,应用程序数量也已经超过100个,特别是很多的科学计算的领域等几乎涉及到各种各样的HPC高性能计算的领域都有CUDA的身影出现,甚至现在HPC进入排行榜前100的高性能计算机里面也有使用Tesla系统,Tesla系统就是一个GPU集群计算典范,现在支持Windows、Linux、Mac OS,几乎最主流的操作系统NVIDIA都能支持。CUDA最主要的包含两个方面:一个是ISA指令集架构;第二硬件计算引擎;实际上是硬件和指令集,这两个方面是CUDA的架构。从这张图片可以看到,当GPU变身成CUDA运算时候,NVIDIA的GPU的架构就全是CUDA的架构,你可以把它看成是跟X86或者cell,他们都是架构,这个也是CUDA架构,但是是基于GPU的架构。这个和CPU的架构很类似,比如X86是包含一套指令集和执行X86各种各样的CPU,对于CUDA也是一样的,NVIDIA自有一套指令集ISA,还有各种各样执行指令集各种各样的硬件引擎。另外CUDA到目前为止,它包含了一个C语言的编译器,就是在CUDA上面的C语言,CUDA这个架构还可以支持其他的API,包括OpenCL或者DirectX,同时以后NVIDIA还有其他的语言,包括Fortran、Java、Python等各种各样的语言,可以说这种架构是原生的,专门为计算接口而建造的这样的一个架构,NVIDIA的硬件架构包括指令集都是非常适合于这种并行计算,这种异构计算而设计的一整套的架构。

CUDA和OpenCL的关系是不冲突的,OpenCL是一个API,在第一个级别,CUDA这个架构是更高一个级别,但是在这个架构上不管是OpenCL还是DX11这样的API,还是像C语言、Fortran、DX11计算,NVIDIA都可以支持。作为程序开发员来讲,一般他只懂这些语言或者API,他可以选择我用什么样的语言来开发我的程序,不管他选择什么语言,他希望调用GPU的计算能,在这个架构上都可以用CUDA来编程,对于编程人员来讲这个很容易,他不需要对OpenCL的架构有非常深的了解,他就可以做到。这个方面上面实际上是一些开发工具,这个道理和CPU的编程实际上还是很类似的,比如你有X86的指令集,又有X86各种各样的CPU,然后你只需要对这个指令集编辑,X86架构上有各种各样的开发工具,当然也有C语言,Fortran语言有Python语言,或者是其他的像Java或者以前的Pascal语言,你用不同的语言进行开发,最后你的执行还是在X86的架构上执行。NVIDIA的CUDA也是一样,有CUDA这一套指令集,有这样的硬件,也就是说有不同的途径来进行开发,你可以用OpenCL或者DirectX这样的API来进行计算的开发,也可以用C语言或者Fortran或者Java开发,这个道理是一模一样的,可以做这方面的类比。OpenCL和C语言的一些异同点。对于编程人员来说他可以选择不同的东西来进行编程,就像之前说的可以选择OpenCL编程也可以选择CUDA上面的C语言来编程,或者API的语言来编程。API和C语言进行开发是有一些不同的,API是一个编程接口,它的核心是函数库和应用程序开发的一个硬件接口,对于API来编程的话,它有一个好处,那就是可以访问比较低层次的硬件,但是他也有一点,就是很多的东西特别是像内存的管理,这个是需要程序员自己来进行管理的。而C语言相对来说NVIDIA在利用CUDA C语言来编程的时候,很多东西是由开发环境来进行管理的,比如内存他是用runtime进行管理的,runtime实际上就是运行时的一些支持程序来进行这方面的管理。不管OpenCL或者CUDA C语言来编程,最终它都是需要通过一个驱动程序来变成一个PTX的代码,PTX相当于CUDA的指令集来进行执行,然后交给图形处理其或者交给硬件来进行执行。这两个最终达到都是使用PTX或者在GPU上进行执行。基本上大家可以理解为如果你想获得更多的对硬件上的控制权的话,你可以使用API来进行编程,比如我是一个科学家我对API不是太了解,你也可以用CUDA C语言来编程,这是两种不同编程的方式,他们有他们相同点和不同点。但是有一点OpenCL和CUDA C语言进行开发的时候,在并行计算这块,他们的概念是差不多的,这两种程序在程序上是有很大的相似度,所以程序之间的相互移植相对来说也是比较容易。

大家如果使用了C语言的话都知道C语言使用驱动程序就是API,实际上是一种抽象,这个抽象主要是指和硬件相关的抽象。实际上CUDA C语言是一种C语言的扩展,这扩展的一部分主要是进行并行运算编程的一方面,这些是通过C的扩展来获得的。基本上认为CUDA的程序也是一种标准的C语言的程序,然后你使用一些关键字然后来对并行这方面计算,然后做一些区分。C语言最终编译会成为PTX的代码,然后在GPU上执行。OpenCL是一个API,就是应用程序的编程接口,OpenCL和OpenGL很像,这种API的话你可以调用API里面,通过程序开发调用各种各样的函数,实现各种各样的功能。对于API来说一般它对硬件设备有比较完整的访问权,你可以访问硬件的设备,可以对内存进行管理,这是由开发人员通过编程来做的这些事情。最后完了OpenCL通过编译、通过驱动程序可以生成PTX代码在GPU上进行执行。邓老师讲的这个目的是如果你作为编程人员要利用GPU的计算能力开发你的应用的时候,有两种模式——根据你不同的需求:如果你需要对硬件有更多的控制,你可以通过OpenCL来编你的API和你的程序,那么它可以在CPU上运行;如果你不需要这个,同时对硬件有控制权,而且你又不太懂API这些东西,只要用C就可以编程了,或者CUDA来编程,编完程序以后也可以在CPU的硬件上跑,这个东西不需要在CUDA支持GPU上跑。讲这个的目的是不同的编程模式可以选择不同的方法,就是用OpenCL还是用CUDA C语言。
OpenCL和OpenGL在很多方面都很类似,实际上他们也是一个共同的组织来进行管理的。对OpenGL图形开发比较熟悉的人他使用OpenCL计算这方面的开发,他们就会非常熟悉它里面所涉及的很多方面,这是OpenCL的一个非常明显的特点。如果你对图形编程很熟悉的话,使用DX11编程,可能比较容易,这是API的一个好处。但是对于大部分的科学家来说,可能对API,OpenCL这种东西可能完全不熟悉,他需要的是我就像在CPU上编程一样,对CPU的计算编程,他可以使用CUDA C语言,在CUDA C语言里面把CPU看成专门做计算的协处理器来进行编程的。这是两个之间不同的模式。
总结:
OpenCL不管对开发人员还是业界人员来说还是消费者来说都是一个非常好的API,一个应用程序的接口。它可以使得开发者很容易的开发出跨平台的GPU计算的程序,充分利用GPU强大的计算能力然后应用在各种各样计算的方面。
对于NVIDIA来说,在CUDA的架构上除了C语言以外,现在新增加了OpenCL或者DX11这样的API,对于开发人员来说也提供了一种更多的GPU计算的开发环境的一种选择。他们如果对API很熟悉的一批人,他们肯定会很高兴的看到OpenCL或者新的API的加入,对于这些人来说他们很容易利用这种计算的API然后开发各种各样GPU计算的程序。对于NVIDIA来说还会继续对C语言包括其他语言的支持,实际上对NVIDIA CUDA C语言来说目前还是唯一的针对GPU的runtime C的语言环境,runtime C的语言环境意思是GPU直接执行这个C语言。
现在已经有非常多的用户已经在使用CUDA C语言,刚才介绍有25000名这样的开发者,应用程序也有很多,而且这种应用程序每一刻都在不断地增加数量。CUDA C语言还会进一步的发展,就像刚才所说的还会有新的版本推出,而且会和像OpenCL和DX11这种计算API会共存,今后也是这样。除了C语言以外NVIDIA还会推出更多的其他CUDA的语言,包括Fortran,还会有Java等。
性能与功能兼备 OpenCL和CUDA全解释
编者按:Apple是OpenCL创始人,NVIDIA支持DirectX以及OpenGL,这会形成一个对立还是和谐的合作?从Apple最新的Macbook中可以看到两者已经很好地融合在一起。究竟这种关系是怎样融合起来的?今天我们籍着这个话题为你一一解答:
最近NVIDIA的CUDA技术成功地让GPU分担了CPU任务,成功地让GPU拥有了CPU计算能力,随着CUDA以及GeForce深入到PC,更多的应用将会被提出。Apple最新产品Macbook也应用了NVIDIA的MCP7A芯片组以实现多媒体更高速运算。众所周知,NVIDIA是DirectX以及OpenGL的忠实支持者以及这两个规范下的重要拥护者,而Apple则是OpenCL的重要拥护者。究竟他们之间是一种怎样的关系?(下面是CUDA应用的各种例子:)

《GPU新里程 NV物理加速Demo体验测》

《发自内在的诱惑 9400M游戏及PS体验》

《开始说画 讯景9600GSO体验NV新技术》
在这些精彩的应用背后,究竟隐藏着一个怎样的开发项目?NVIDIA未来对于CUDA以及其项目有无进一步的消息?究竟,CUDA与CopnCL是怎样的一个融合体?
关于OpenCL与CUDA的一些问题:
问:
AMD是OpenCL里面的吗?
答:
对。OpenCL是包含很多家公司的,主要业界的公司都包含在里面,包括IBM、戴尔这些公司包括HP。OpenCL是一个非常开放的行业组织,所有的公司都在里面,他们和NVIDIA是没有冲突的,NVIDIA也是很积极地参与技术。
Stream基本上还是基于一种传统CPU的一种方式,AMD当然他会说他会有CAL,CAL实际上是套指令集,可以用汇编语言的方式来开发软件,但是汇编方式开发软件的话,对搞计算的人来说不大现实,你要让他用汇编语言来说的话可能确实是一个折磨。还有一个Brook,这个是斯坦福大学开发的,它是类似于C的东西,他是把底层GPGPU的计算方式类似于C的这种语言,他不是C语言而是类C语言,语法和C语言比较类似,他内部做的还是使用顶点这样的数据。
另外Stream的方式还有一个很大的问题,他主要是基于本地的板载内存,板载内存存入数据,然后换算完了再写到板载内存。这样对GPU非常强大的计算能力来说,带宽是一个非常大的障碍,你想想每秒种进行1P的数字计算的话,你需要多少的带宽?32位浮点的话这是4个字节,如果你1P的话,NVIDIA把他承加这部分也算上就相当于再乘以2,至少需要每秒2P的吞吐量然后才能够满足它,板载内存的话每秒需要几十P,这实际上是Stream的方式,从效率上是一个比较低的计算。而对于开发者来说也会碰到很多的问题,对于NVIDIA来说支持C,这是真正GPU上运行的C语言。C语言有一个很重要的特点,需要有存储体系,对于NVIDIA GPU来说是有存储体系的,内部有share memory,然后大部分的数据,编译器会把大部分的数据尽可能的让它在share memory上进行计算,share memory带宽非常高,因为它在芯片内部,它的速度接近于寄存器的速度,他在share memory上跑的话,然后再把这个数据再输出,这样的话他真正地可以利用到绝大部分的计算机。实际上CUDA的效率,在应用软件上可以看出来,像传统的高性能计算领域的话,NVIDIA的峰值速度比如像G80是300多G浮点计算能力,效率是非常高的。这也是为什么这么多人在使用CUDA C语言来进行开发,这是一个很重要的原因。
实际上你说要使用Stream来开发的应用软件,我知道的只有一个是folding@home,ATI比NVIDIA进入早两年,但是NVIDIA进入以后使用CUDA的语言来写folding@home客户端的软件,性能立刻比它高好几倍,folding@home你可以看到一个很特别的——他原来一个版本是可以跑在它上一代的架构应该是3850或者3870的GPU上,但是如果它4850和4870出来以后,从原点上来说他的计算能力比3850、3870要高2.5倍,但是它的folding@home的性能反而下降了,原来他是200左右,就是3870,他是每天可以模拟200万秒的性能等级,4870出来以后每天只能模拟170万秒。这是为什么?这个软件不是使用Brook开发的,直接使用汇编的方式开发的,这样的话你需要对每一个新的GPU,你都要对他进行编程,每个架构都需要对它重新进行编程,然后才可以得到一个最好的效率。中间有很长时间4870的性能都比3870在folding@home上低,后来他确实重新编程了,过了好几个月,有些新的版本出来了,4870比3870高了。这就是说使用汇编方式的话会带来一个非常大的问题,你任何一个应用软件里面都需要重新优化、重新编程。
汇编语言实际上就是机器码来进行编程,这个是属于体力比较好的人才能干的了,就是记忆也比较好的人才能干的了。高级语言相对来说确实要简单太多了,就像刚才我说的有些人甚至对编程都不是很熟悉的,他只要基本上知道源代码里面哪些代码是在做什么东西,然后他就可以使用CUDA,他不见得核心部分计算部分一定要自己编,就像刚才说的NVIDIA有很多现成的库,都是直接写好的函数,这个函数把原来的函数替代掉,就可以取得很好的性能。NVIDIA提供很多函数库,这些函数库有一些是NVIDIA公司开发的,像FFT、线性代数或者是快速傅里叶变换等,但是有一些库是第三方帮NVIDIA开发的。NVIDIA实际上形成一个非常好的环境,不断的有人针对CUDA来开发,不管是应用软件或者是中间件,这些中间件的话就包含各种各样的库。
对于CUDA来说,说老实话和Stream相比的话,几乎现在没什么可比性。确实对OpenCL、DirectX这样应用的话,我相信在CUDA的架构上运行这个程序也比在Stream上运行程序好的多。因为NVIDIA使用的架构实际上你开发的时候,NVIDIA就考虑到计算方面的应用。别的方案的话,他有可能计算仅仅是图形的一个副产品。NVIDIA在开发的时候图形和计算这两部分几乎作为同等重要的,两个都必须要满足的东西来做架构方面的设计。
问:
OpenCL它的特点一个是开放,OpenGL也很开放,但是它的更新实际上非常、非常的慢,OpenCL会有这种情况吗?
答:更新的话,这是由一个专门的组织Khronos,这个组织是有很多厂商来组成的,每个厂商派一些人然后进来在组织里面,然后每个公司互相协商,然后制定各种各样的标准,比如你推出一个新的版本要达到什么功能,价格是怎么样的?这些厂商来进行协商的,厂商不太一样,比如Microsoft我自己的东西,我说的算,这是完全不一样的。但是我相信OpenCL从目前来看的话,它还是挺快的,你看它现在的α版本明年一季度就进入β版本,明年终第一版就会推出。
问:
OpenGL和DirectX的关系一样,我现在看到CUDA这边更新的频率明显比OpenCL快很多,NVIDIA想把这个东西打造成一个GPU通用计算上的DirecX吗?
答: 我觉得应该是没有什么可比性的。刚刚强调DirectX是API,CUDA不是API,CUDA是一个硬件架构。刚才说的很多版本是CUDA C语言的版本,这是CUDA C语言版本的路线图,(PPT)C是语言,CUDA是一个硬件架构,GPU的架构。大家很容易会把C和CUDA融在一块儿,不是这样的。CUDA架构类似与X86的架构。 实际上CUDA的C语言和OpenCL在并行计算这块,它的一些观念都挺类似的,包括它计算的数据组织方式都很类似。我相信NVIDIA在OpenCL的规格、开发方面联系一直是非常紧密的,包括Apple也参与到其中。NVIDIA在这方面的很多经验,也会得到一些体现。这两个程序之间的移植也是很容易的,现在他使用CUDA C语言来写,OpenCL出来以后,如果他想移植OpenCL的程序,相对来说不用全部重头写。
问:
这个东西能否用在微软上?
答:
可以,像OpenGL也不是微软的,但是一样可以在微软上跑。
问:
现在一般都是OpenCL?
答:
这个是程序模型的原因,而且现在看起来在OpenCL在Vista下,目前看起来没有太大的问题。原来大家都一直以为在Vista下面OpenCL不会有ICD,实际上最后还是有ICD。这个东西的话现在OpenGL的软件,我经常跑各种各样的专业软件,很多在OpenGL下来以后都没有问题,非常典型的OpenGL的应用程序跑地都挺好的。对于OpenCL或者OpenGL在微软下,你可以看成是一个API,这个API你是可以安装的,比起微软自己原来带有的这个东西。这算是一种应用程序吧。
问:
OpenCL看似更趋向于底层开发的API,那相对于CUDA C来说,OpenCL开发的程序执行效率会不会比CUDA C效率更高一些?
答:
完全不存在这个问题。说老实话效率高不高,并不取决于你用的什么语言,什么样的API,更大程度上取决于你的代码,你代码的优化程度是怎样的?这个才是影响他代码的效率。
问:
在OpenCL出来之前,CUDA并行计算的优势已经很大了,现在为什么还非要出一个OpenCL通过中间的东西来调用,我感觉不是费一道事吗?
答:
OpenCL是一个跨平台的一种API,这个API就像OpenGL一样,它也是希望跨平台,就是跨软件和硬件的API,OpenCL也是一样也是跨软件和硬件平台的API,算是一个业界的标准,不管是哪一家的,原则上都可以支持OpenCL这个平台,支持API。OpenCL不是NVIDIA推出来的,OpenCL最开始是Apple提出来的,但是NVIDIA确实是在这个标准的制定当中,NVIDIA和Apple进行了很紧密的合作,然后NVIDIA提供了很多支持包括硬件方面的支持。 模式不一样适用的人群也不一样。适用的人群也不一样,我的理解是OpenCL和OpenGL他们在很多方面都非常的接近,如果习惯使用OpenGL他如果用OpenCL来开发的话会感觉到轻车熟路,就像是Computer shader也一样,如果你是多媒体这方面的应用,你又想使用图形又想使用GPU的来计算,你用Computer shader来做很容易。但是对CUDA C来说,它是用的人群是你能够使用C语言的人你都可以使用CUDA C来开发。使用人群完全是不一样的,我想可能也有一些人虽然他也会C语言,但是他还是希望用OpenCL来进行开发,用他跨平台的特性。另外或者因为其他的一些原因,包括他希望更多对硬件方面的控制,然后他应用软件里面他可能希望对内存进行完全的控制,这些用户的话他可能就会选用OpenCL来进行开发。这是两个不同的东西。我相信即使OpenCL出来以后,CUDA C语言的使用者还是会越来越多的。
如果认为一种开发环境就可以取代其他的开发环境,这个是不现实的。我举个例子来说在X86的架构上,除了C语言以外还有Java、Fortran还有Pascal语言,这些不可能互相取代的,每种语言、每种API都有它使用的人群,都有喜欢用的人。不同的语言、不同的API都会满足不同人群的。我觉得现在不是太多,GPU计算和API语言不是太多,现在还比较少,NVIDIA还会不断地推出Java、Pascal或者C++也会支持。如果以前没有Fortran,那些老年人你要让他们学习C语言的话,他们可能用Fortran用了几十年,所以说让他开发的话他就比较痛苦,现在有了Fortran,他就可以直接用Fortran来写CUDA的程序,说不同开发的途径有不同的用户,这个是肯定的。
问:
Havok现在怎么样了?
答:
Havok目前为止基本上只能使用CPU做物理计算,而PhysX可以使用GPU、可以使用CPU也可以使用PPU来做物理方面的计算。当然这三种里面GPU的效率是最高的,PPU的话估计现在也没什么人买,GPU的效率是最高的,而且他真的是可以带来10倍的性能提升,这个性能提升在物理计算方面,CPU和GPU相比的话性能提升10倍,这是很常见的。而且PhysX它是可以作为一种最基本的平台,还有很多第三方的中间件在上面,基于PhysX。它实际上是利用PhysX的平台可以实现别的东西,比如类似于人工智能。NVIDIA曾经给大家提供过一个美式橄榄球的游戏视频,那个游戏真的是很酷,但是我不能放给大家看,那家公司要求NVIDIA只能提供视频给大家,不能把游戏给大家看。真的是很酷,非常大的场面,那个场面里面每个观众都是一个不同的人,有一个体育场9000人,每个观众都是一个实际的人,而且每个观众都是不太一样的。最主要他真正的把人的动作模拟的非常逼真,你撞击撞到什么位置,比如说你看到撞过来的你会下意识的做一些防守的动作。这些防守的动作人跑过来不同的方向,动作也不一样的。比如你跌倒,跌倒空中你可能会有下意识的支撑动作,这些都会有,以后游戏真的是会越来越逼真。NVIDIA所谓静态逼真和动态逼真就是这样。静态逼真像这个,Crysis已经做的很逼真了,但是真正动起来还是感觉比较僵硬,就是整个场景里面不管人物的动作或者其他的运动都是事先设置好的,就像放的录像一样,而不是真正时时运算出来的。如果你使用大量物理计算的话,真的可以获得很好的动态逼真度。如果要实时计算对硬件的要是就会很高,如果持有CPU加速的话它的动态架构和NVIDIA的动态架构就有区别,就会影响速度不一样。Havok用CPU来做物理计算,它计算能力只能那么高,你里面设置的物理效果相对来说就会很有限。而且CPU还有很重要的任务在人工智能或者场景管理的方面,所以说使用GPU来做物理方面的加速是非常有效的。另外还有一点新的180驱动支持更多的GPU PhysX的配置,你可以使用2片的显卡,一片用来渲染,一片用来做物理加速,这是效率最高的一种方式。你用一片来做同时做渲染同时做物理计算,这也是可以的,和纯粹使用CPU做物理计算的话性能会高很多,但是并行计算和渲染都是需要GPU的计算资源,所以如果你用单独的一片显卡的话,用来做物理加速的话,性能又会得到一个很大的提升。大家最好可以测试一下这方面的效果。
问:
比如像EA的100多款游戏,它那个PhysX主要是用GPU运算还是CPU运算?
答:
只要是PhysX支持的游戏当然是GPU了。每一款游戏都可以采用不同的策略,我相信这些游戏开发商的话也会采用不同的策略来处理这些事情,当然他最好的效果肯定是使用GPU来做物理这方面的计算,然后游戏里面放大量的物理效果,这是最好的方式。当然也会有一些比较简化的模式,就是说你没有NVIDIA的显卡,然后给你提供一个比较简单,物理效果比较少的模式。你还可以运行,但是物理效果带来的各种各样的好处相对就比较少。这也是为什么跟大家强调的,NVIDIA现在叫GeForce + CUDA,里面有很多的新功能,PhysX是NVIDIA独有的,这是别人没有办法做到的。你要想作为一个玩家,你想享受更好的效果当然要在NVIDIA的显卡上运行,才会有更好的效果。这个市场是开放的,谁都可以去,但是看谁能够跑在前面。
问:
PhysX是跨平台的吗?PhysX主要是用于游戏吗?现在大部分的游戏基本上都是DirecX的。
答:
游戏机也可以支持。OpenGL和DirecX的API是独立的,现在OpenGL游戏确实越来越少,所以大部分的游戏都是DirecX的。
问:
PhysX不是跑在CPU上的?
答:
他是跑在GPU上。对于PhysX来说CPU也可以跑。
Badaboom 1.1介绍:
Elemental公司会提供Badaboom 1.1版的。Badaboom输出形式还是在H.264,这个已经成为业界的标准了。所有的手持设备都支持H.264,因为H264编码效率确实比较高,但是输入的形式情况千差万别,输入现在有很多用不同的编码格式,不同的封装格式。编码格式比如像WMA、Mpeg2、VC1等来自各种各样的渠道。还有封装格式比如像AVI、MKV等。不同的编码格式和封装格式现在Badaboom 1.1都可以支持,这是一个方面。另外一个方面增加了更多的预设式的东西,原来主要提供的是Apple的iphone、ipod或者iTV这种的支持,新的提供更多的支持包括像youtube,youtube这在国外用的很多,另外还有Black Berry 9000的支持,另外对微软播放器rom的支持。当然我还可以提供用户自定义的输出格式,如果你想自定义,分辨率自定义影片的细节你也可以自己定义,包括码率等。第三非常重要的一点Badaboom 1.1可以支持Main Profile的H.264。过去都是Baseline的编码器,Baseline和Main Profile最重要的区别是Main Profile可以使用基于二进制的可编程的双编码。它就是说在相同的码率下,它的画质就更好。Main Profile一个非常重要的特点,几乎所有的像蓝光的影片H.246的影片几乎都是采用Main Profile,因为Main Profile可以提供更好的画质。现在像快速的编码器现在只有Elemental的Badaboom 1.1可以支持Main Profile。另外一个是支持全高清的输出,1080P的输出,现在的版本支持到720P,以后可以支持到1018P的输出。还有一点是非常重要的,可以支持多GPU。如果你有两个GPU的话可以获得性能翻番,即是有两个GPU来进行编码。这是它的一些基本情况。
实际上对于Badaboom来说,有一点非常重要Badaboom确实是非常容易使用,而且真正是解放CPU的一种转码工具。Badaboom特别是在像H.264进行转码的时候,H.264的影片比如蓝光的影片你把他转成ipod的影片,CPU的占有率非常低,所有的视频编码和解码全在GPU上完成。而且你在转码的过程中毕竟还需要二三十分钟,转码过程中可以做别的没有任何问题。NVIDIA不像别的公司宣称什么同时利用CPU和GPU,我都不太清楚他究竟用的是CPU还是GPU?大家可以测试一下,你看看它GPU的功耗有没有增加?这是最简单的一个方法,看看GPU有没有负载?因为从原理上来说一个视频流,除非你不怕数据在CPU和GPU来回倒,要不然的话一个视频流很难把负载分到CPU和GPU上,这两个数据处理的方式完全不一样的。
从另外一个角度,就是画质,这是非常重要的。编码的效率和画质是严重相关,我可以这样说,NVIDIA甚至可以做出一个可以损失一点画质,然后我可以获得好几倍性能提升的编码,因为H.264的编码太多了,比如你帧间预测的时候,你可以少拿几个关键帧,或者你完全不要帧间预测,只有帧队预测你也可以进行编码,但是效果怎么样,那是另外一回事。最终所有运动视频的编码,最重要的一点是运动预测。如果多帧之间有运动的关系,不用保存所有的图形,你只要保存运动的适量就可以了,所以大大降低文件的尺寸。如果你没有预测的话,意味着每一张画面都要进行压缩,你要达到比较小的分率的话,压缩质量惨不忍睹。过去最早的Mpeg 2也可以使用CPU来做时时的压缩,当然也可以买一个1万块钱的压缩卡,1万块钱的压缩卡这和CPU压缩有什么区别?CPU压缩的几乎没法看。我可以做到速度很高但是画质很差。NVIDIA希望在最好画质的情况下获得尽可能快的性能,这也是Elemental这家公司想的。现在看起来Badaboom的画质和顶级的非常专业的编码工具得到的画质几乎是一样的,但是它的性能比这些编码工具快很多。
我觉得好像预测然后“这个很快,这个真的很快,快了以后当然画质不太好,这算是一个小缺点。”画质不太好这是一个大缺点,不是一个小缺点,NVIDIA转码的话是最好的画质,当然是越快越好,但是画质是绝对不能妥协的。就像3D游戏一样,大家看一眼画质,全世界都再说这个画质是不是有问题,NVIDIA就是追求最好的画质然后尽可能提升性能。
问:
像现在掌上设备不支持Cabac解码吗?
答:
掌上设备我还不太清楚是不是所有的不支持,但是大部分的都支持Baseline,但是还有一个Main Profile编码方式还是有一个非常大的好处,比如你要想把一个1080P的视频转成720P,码率小一点,然后放在网络上,让大家下载。
问:
有些人在国外破解的BD都是原版的,下载做成720P的。
答:
以后可以用Badaboom,比如Badaboom它可以自己定义输出的,包括码率可以自己定义,还是很方便,现有的还是用H.264。
问:
像纯做编码,这块像Badaboom做这个?它不是有编码加速吗?
答:
在这个过程中,其他公司再做的时候NVIDIA也不能透露,但是这肯定是他们的第一步,后续的还会有做。在BD方面相对来说比较的快一点,因为你要做核心来重新编写的话,这个可能开发的周期也比较长。而且CUDA看起来做滤镜这方面还是特别实用的,现在CUDA程序还有好几种。
谁主沉浮 OpenCL与CUDA架构深入解析!
前言
最近,Khronos公布了OpenCL(Open Computing Language)的第一个测试版本,一经发布便在通用计算领域掀起来轩然大波!OpenCL是由苹果公司发起,业界众多著名厂商共同制作的面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境。便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。

那么OpenCL与NVIDIA的CUDA架构是什么关系,是否是外界认为的竞争关系?目前众多的通用计算标准中,比如NVIDIA的CUDA、Khronos的OpenCL、AMD的Stream,CAL、Brook+、微软下一代的Computer shader等,他们之间有什么异同,看完这篇文章,相信你就会有一个大概的了解……
OpenCL来了!
Khronos是一个开发组织,著名的OpenGL就是出自Khronos之手,Khronos有很多厂商组成,OpenCL工作组同时也是OpenCL的一个协调机构,来负责制定OpenCL的规格、架构等等各方面。业界最主要的和图形或者和计算相关的厂商都是Khronos的成员。
OpenCL实际上是针对异构系统进行并行编程的一个全新的API,OpenCL可以利用GPU进行一些并行计算的工作。我们知道,图形里面有很多API,比如OpenGL是针对图形的,而OpenCL则是针对并行计算的API。 OpenCL开发人员可以利用GPU和CPU的计算能力,把GPU和CPU异构的系统运用在很多并行计算的领域。

OpenCL对于业界来说是非常重要也是非常好的一个标准,这样业界有一个共同的标准可以利用GPU的强大计算能力,然后应用在图形以外各种各样的并行计算方面。NVIDIA公司的副总裁Neil Trevett是OpenCL工作组的主席,引导很多OpenCL的开发,NVIDIA公司很多员工都在参与这项工作。
OpenCL最早由Apple公司提出的,OpenCL发起NVIDIA就和Apple公司进行非常紧密的合作。OpenCL开发的过程中,技术平台均为NVIDIA的GPU,实际上OpenCL是基于NVIDIA GPU的平台进行开发的。另外OpenCL在大概两个多月以前进行了第一次演示,也是运行在NVIDIA的GPU上。

对于Apple公司来说是把GPU计算当成一种未来的趋势,他们非常重视OpenCL,在新一代的产品里面选择了最适合于OpenCL运行的平台。所以新一代苹果的笔记本电脑全都采用了NVIDIA的平台,不管是MacBook Pro还是MaBook。实际上这也是从另外一个方面证明NVIDIA的GPU对于OpenCL的支持。
OpenCL与CUDA并非敌对关系
很多人对什么是CUDA可能还有一些疑虑,并没有搞清楚CUDA到底是什么。实际上CUDA最主要的包含两个方面:一个是ISA指令集架构;第二硬件计算引擎;实际上是硬件和指令集。 也就是说我们可以把CUDA看做是与X86或者cell类似的架构,但是是基于是GPU,而不是传统的CPU。
这个其实很好理解,把它和传统的和CPU的架构比较下相信就更容易理解,传统X86是包含一套指令集和执行X86各种各样的CPU,对于CUDA也是一样,CUDA有一套指令集ISA,还有执行指令集各种各样的硬件引擎。CUDA到目前为止包含了一个C语言的编译器,当然CUDA架构还可以支持其他的API,包括OpenCL或者DirectX,同时CUDA还会有其他的语言,包括Fortran、Java、Python等各种各样的语言,可以说CUDA架构是原生的,专门为计算接口而建造的这样的一个架构,这种硬件架构包括指令集都是非常适合于这种并行计算,为异构计算而设计的一整套的架构。
 OpenCL与CUDA的关系
OpenCL与CUDA的关系
上图很好的解释CUDA和OpenCL的关系,他们并不是冲突关系,而是包容关系。OpenCL是一个API,在第一个级别,CUDA架构是更高一个级别,在这个架构上不管是OpenCL还是DX11这样的API,还是像C语言、Fortran、DX11计算,都可以支持。作为程序开发员来讲,一般他们只懂这些语言或者API,可以采用多种语言开发自己的程序,不管他选择什么语言,只要是希望调用GPU的计算能,在这个架构上都可以用CUDA来编程。
CUDA编程的道理和CPU的编程很类似,比如有了X86的指令集,又有X86各种各样的CPU,那么我们只需要对这个指令集编程即可。X86架构上有各种各样的开发工具,当然也有C语言,Fortran语言,Python语言,Java或者以前的Pascal语言,不论你使用什么语言进行开发,最后还是在X86的架构上执行。CUDA也是一样,有了CUDA的指令集,有了支持CUDA的硬件,我们就可以采用不同的途径来进行开发,比如可以采用OpenCL或者DirectX这样的API,也可以用C语言或者Fortran或者Java开发,最终都可以在CUDA架构上运行。
OpenCL与CUDA C语言的异同
前文已经说过,CUDA架构与OpenCL是包容关系,我们把他们放在同一级别进行讨论本来就是错误的,与OpenCL在同一级别不是CUDA架构,而是CUDA的C语言包,也就是我们常说的CUDA版本,比如,CUDA 1.0、CUDA 2.0等等,下面来介绍一下OpenCL和CUDA C语言的一些异同。

对于编程人员来说可以选择不同的开发环境来进行编程,例如我们可以选择OpenCL编程也可以选择CUDA上面的C语言来编程,或者API的语言来编程。API和C语言进行开发是有一些不同的,API是一个编程接口,它的核心是函数库和应用程序开发的一个硬件接口,对于API来编程的话,好处在于可以访问比较低层次的硬件,单弊端也是显而易见的,那就是很多程序特别是像内存的管理,需要程序员自己来进行管理。而我们在利用CUDA C语言来编程的时候,底层的硬件管理是由CUDA开发包来进行管理,比如内存是用runtime进行管理(runtime实际上就是运行时的一些支持程序来进行底层硬件的管理),而不需要开发者考虑底层的硬件效率。不管OpenCL或者CUDA C语言来编程,最终都是需要通过一个驱动程序来变成一个PTX的代码,PTX相当于CUDA的指令集来进行执行,然后交给图形处理其或者交给CPU来进行执行。
也就是说,如果开发人员想获得更多的对硬件上的控制权的话,可以使用API来进行编程,而如果类似科学家如果对API不是太了解,那么就可以用CUDA C语言来编程,这是两种不同编程的方式,他们有他们相同点和不同点。OpenCL和CUDA C语言进行开发的时候,在并行计算上的概念很相似,在程序上是也有很大的相似度,所以程序之间的相互移植相对来说也比较容易。
当然我们也许会有疑问,那就是OpenCL看似更趋向于底层开发的API,那相对于CUDA C来说,OpenCL开发的程序执行效率会不会比CUDA C效率更高一些?实际上这个问题是不用担心的,执行效率高不高,并不取决于采用的什么语言,什么样的API,更大程度上取决于的代码的优化程度!
不同编程模式解读
下面我们来深入解读一下CUDA与C语言编程模式的异同。对C语言进行编程的人员都知道,C语言使用驱动程序就是API,实际上是一种抽象,这个抽象主要是指和硬件相关的抽象。实际上CUDA C语言是一种C语言的扩展,这扩展的一部分主要是进行并行运算编程的方面,这些是通过C的扩展来获得的。基本上认为CUDA的程序也是一种标准的C语言的程序,然后使用一些关键字然后来对并行这方面计算,最后做一些区分。C语言最终编译会成为PTX的代码,然后在GPU上执行。OpenCL是一个API,就是应用程序的编程接口,OpenCL和OpenGL很像,这种API可以调用API最底层的数据,通过程序开发调用各种各样的函数,实现各种各样的功能。对于API来说一般它对硬件设备有比较完整的访问权,以访问硬件的设备,可以对内存进行管理,这是由开发人员通过编程来做的这些事情。最后OpenCL通过编译、通过驱动程序可以生成PTX代码在GPU上进行执行。

编程人员要利用GPU的计算能力开发你的应用的时候,有两种模式:如果你需要对硬件有更多的控制,可以通过OpenCL来编你的API和你的程序,那么它可以在CPU上运行;如果不需要底层的硬件管理,同时对硬件有控制权,而且又不太懂API这些程序,只要用C语言就可以编程了,或者CUDA C语言来编程,编完程序以后也可以在CPU的硬件上运行。
OpenCL和OpenGL在很多方面都很类似,他们也是一个共同的组织Khronos来进行管理的。对OpenGL图形开发比较熟悉的人使用OpenCL计算这方面的开发,他们就会非常熟悉它里面所涉及的很多方面,这是OpenCL的一个非常明显的特点。如果你对图形编程很熟悉的话,就像是Computer shader,如果是多媒体等方面的应用,又想使用图形又想使用GPU的来计算,用Computer shader的DX11编程,可能比较容易。但是对于大部分的科学家来说,可能对API,OpenCL可能完全不熟悉,他需要的就像在CPU上编程一样,对CPU的计算编程,可以使用CUDA C语言,在CUDA C语言里面我们把CPU看成专门做计算的协处理器来进行编程,这是两个之间不同的模式。
如果认为一种开发环境就可以取代其他的开发环境,这个是不现实的。举个例子,在X86的架构上,除了C语言以外还有Java、Fortran还有Pascal语言,这些不可能互相取代的,每种语言、每种API都有它使用的人群。不同的语言、不同的API都会满足不同人群的。GPU计算和API语言不是太多,目前还比较少,NVIDIA还会不断地推出Java、Pascal或者C++也会支持。如果以前没有Fortran,那些“老古董”程序员要让他们学习C语言的话基本不可行,他们可能用Fortran用了几十年,让他们使用C语言开发的话他就比较痛苦,所以OpenCL与CUDA C语言并不存在谁将取代谁的问题。
CUDA与ATI Stream异同
我们知道,ATI方面也有自己的通用计算编程接口,叫做Stream。那么他与CUDA架构又有什么不同呢?
Stream基本上还是基于一种传统CPU的一种方式,Stream主要包括CAL与Brook+。CAL是一套指令集,可以用汇编语言的方式来开发软件,然而我们汇编方式开发软件的话,对搞计算的人来说不大现实,让他们用汇编语言来说的话可能确实是一个折磨。Brook+是斯坦福大学开发的,它是类似于C语言的东西,是把底层GPGPU的计算方式类似于C的这种语言,这里要说明的是Brook+不是C语言而是类C语言,语法和C语言比较类似,但内部做的还是使用顶点这样的数据。
 Stream视频编码
Stream视频编码
另外Stream的方式还有一个很大的问题,那就是主要是基于本地的板载内存存入数据,换算完成再写到板载内存。这样对GPU非常强大的计算能力来说,带宽是一个非常大的障碍。例如每秒种进行1P的数字计算的话,需要多少的带宽?32位浮点4个字节,如果是1P的话,我们把乘加这部分也计算在内就相当于再乘以2,至少需要每秒2P的吞吐量然后才能够满足,板载内存每秒需要几十P。可见Stream的方式从效率上是一个比较低的计算,而对于开发者来说也会碰到很多的问题。
对于CUDA来说我们支持的C语言,是真正GPU上运行的C语言。C语言有一个很重要的特点,需要有存储体系,而NVIDIA GPU在设计之初就考虑到了这点,内部有拥有share memory,编译器会把大部分的数据尽可能的在share memory上进行计算。share memory带宽非常高,因为它在芯片内部,速度接近于寄存器。数据在share memory上运行,然后再把这个数据再输出,这样的话真正地可以利用到绝大部分的GPU性能。
汇编语言的弊端
基于Stream来开发的应用软件,我们知道的只有一个是folding@home,ATI比NVIDIA进入早两年,但是NVIDIA进入以后使用CUDA的语言来写folding@home客户端的软件,性能比ATI的GPU要高好几倍。folding@home的一个版本可以运行在在上一代的架HD3(报价参数 图片 评测)850或者HD3870的GPU上,但是HD4850和HD4870发布后,从浮点性能上来说计算能力比HD3850、HD3870要高2.5倍,但是folding@home的性能反而下降了?原来HD3870是200ns/day左右,每天可以模拟200万秒的性能等级,但是HD4870发布后每天只能模拟170ns/day,这又是为什么?其原因是软件不是使用Brook+开发的,而直接使用汇编的方式,这就需要对每一个新的GPU进行编程,每个架构都需要对它重新进行编程,然后才可以得到一个最好的效率,这就是说使用汇编方式的话会带来一个非常大的问题,任何一个应用软件里面都需要重新优化、重新编程。

汇编语言实际上就是机械码来进行编程,属于体力比较好、记忆也比较好的人才能胜任的工作。高级语言相对来说确实要简单太多了,例如有些人甚至对编程都不是很熟悉,他只要基本上知道源代码里面哪些代码是在做什么东西,然后他就可以使用CUDA,核心部分计算部分一定要自己编写,因为CUDA有很多现成的库,都是直接写好的函数,这个函数把原来的函数替代掉,就可以取得很好的性能。NVIDIA提供很多函数库,这些函数库有一些是NVIDIA公司开发的,像FFT、线性代数或者是快速傅里叶变换等,但是有一些库是第三方帮NVIDIA开发的。CUDA实际上形成一个非常好的环境,不断的有人针对CUDA来开发,不管是应用软件或者是中间件,这些中间件的话就包含各种各样的库。
因此对于CUDA来说,与Stream相比几乎现在没什么可比性。对OpenCL、DirectX这样应用在CUDA的架构上运行程序也比在Stream上运行程序好的多。因为NVIDIA在使用的CUDA架构实际上字开发的时候,就考虑到通用计算方面的应用。而ATI方面,可能通用计算仅仅是图形的一个副产品。
OpenCL与CUDA C语言路线图
目前OpenCL路线图目前还是属于Alpha版本。明年第一季度可能是Beta的版本,09年OpenCL1.0可能会正式推出,OpenCL最早会出现在Mac OS上,以后逐渐的扩展到其他的操作系统,像Windows或者Linux。
 OpenCL路线图
OpenCL路线图
下面来介绍一下CUDA C语言的情况,NVIDIA一直还是不断地对这个语言进行更深层次的开发,也不断的有新版本的出现,到目前为止已经是CUDA 2.0。CUDA C语言研发已经超过5年时间,NVIDIA从03年左右就开始开发C语言。到目前为止,开发人员的数量已经是超过25000个,而且现在应用程序已经超过100个,特别是很多的科学计算的领域,几乎涉及到各种各样的HPC高性能计算的领域都有CUDA的身影出现,甚至现在HPC进入排行榜前100的高性能计算机里面也有使用NVIDIA的Tesla系统,GPU集群就是配置成高性能计算机的集群数量已经达到了30个,我国大陆也有采用。
CUDA C语言是一个跨操作系统的开发工具,现在支持Windows、Linux、Mac OS,几乎最主流的操作系统都支持,SUN公司的Solaris系统也会支持。一些数学软件像Matlab、Mathematica、LabView都有CUDA的插件,可以使用C语言的插件让他更容易的利用CUDA。

上面是C语言的路线图,目前的版本是CUDA 2.0,到今年年底CUDA 2.1会与我们见面,到明年会有2.2、2.3版本,到明年年底会到CUDA 3.0版本。随着CUDA版本的升级,它的功能也在不断地升级,比如最早的CUDA只能支持单精度的浮点计算,现在可以支持双精度,可以支持各种各样的库,各种各样的功能也是越来越多。
并行计算时代已经到来……
OpenCL的面世,不管对开发人员还是业界人员来说还是消费者来说都是一个非常好的API,它可以使得开发者很容易的开发出跨平台的GPU计算的程序,充分利用GPU强大的计算能力然后应用在各种各样计算的方面。 除了CUDA的架构上除了C语言以外,现在新增加了OpenCL或者DX11这样的API,对于开发人员来说也提供了一种更多的GPU计算的开发环境的一种选择。如果对API很熟悉的程序员,肯定会很高兴的看到OpenCL或者新的API的加入,对于这些人来说他们很容易利用这种计算的API然后开发各种各样GPU计算的程序。

NVIDIA也会继续对C语言包括其他语言的支持,实对NVIDIA CUDA C语言来说目前还是唯一的针对GPU的runtime C的语言环境(runtime C的语言环境是指GPU直接执行这个C语言)。CUDA C语言还会进一步的发展,不断会有新的版本推出。CUDA C语言会和OpenCL和DX11这种计算API会共存。

除了C语言以外NVIDIA还会推出更多的其他CUDA的语言,包括Fortran,还会有Java等。不管C语言还是Fortran,与OpenCL、Computer shader这种API是一种长期共存的关系。 GPU通用计算时代已经到来了,你已经准备好了吗……
OpenCL和CUDA的使用比较
OpenCL和CUDA虽然不是同一个平级的东西,但是也可以横向比较!
对OpenCL和CUDA的异同做比较:
- 指针遍历
OpenCL不支持CUDA那样的指针遍历方式, 你只能用下标方式间接实现指针遍历. 例子代码如下:
// CUDA
struct Node { Node* next; }
n = n->next;
// OpenCL
struct Node { unsigned int next; }
n = bufBase + n;
- Kernel 程序异同
CUDA的代码最终编译成显卡上的二进制格式,最后由cudart.dll(个人猜测)装载到GPU并且执行。OpenCL中运行时库中包含编译器,
使用伪代码,程序运行时即时编译和装载。这个类似JAVA, .net 程序,道理也一样,为了支持跨平台的兼容。kernel程序的语法也
有略微不同,如下:
- __global__ void vectorAdd(const float * a, const float * b, float * c)
- { // CUDA
- int nIndex = blockIdx.x * blockDim.x + threadIdx.x;
- c[nIndex] = a[nIndex] + b[nIndex];
- }
- __kernel void vectorAdd(__global const float * a, __global const float * b, __global float * c)
- { // OpenCL
- int nIndex = get_global_id(0);
- c[nIndex] = a[nIndex] + b[nIndex];
- }
可以看出大部分都相同。只是细节有差异:
1)CUDA 的kernel函数使用“__global__”申明而OpenCL的kernel函数使用“__kernel”作为申明。
2)OpenCL的所有参数都有“__global”修饰符,代表这个参数所指地址是在全局内存。
3)众所周知,CUDA采用threadIdx.{x|y|z}, blockIdx.{x|y|z}来获得当前线程的索引号,而OpenCL
通过一个特定的get_global_id()函数来获得在kernel中的全局索引号。OpenCL中如果要获得在当前工作
组(对等于CUDA中的block)中的局部索引号,可以使用get_local_id()
- Host代码的异同
把上面的kernel代码编译成“vectorAdd.cubin”,CUDA调用方法如下:
- const unsigned int cnBlockSize = 512;
- const unsigned int cnBlocks = 3;
- const unsigned int cnDimension = cnBlocks * cnBlockSize;
- CUdevice hDevice;
- CUcontext hContext;
- CUmodule hModule;
- CUfunction hFunction;
- // create CUDA device & context
- cuInit(0);
- cuDeviceGet(&hContext, 0); // pick first device
- cuCtxCreate(&hContext, 0, hDevice));
- cuModuleLoad(&hModule, “vectorAdd.cubin”);
- cuModuleGetFunction(&hFunction, hModule, "vectorAdd");
- // allocate host vectors
- float * pA = new float[cnDimension];
- float * pB = new float[cnDimension];
- float * pC = new float[cnDimension];
- // initialize host memory
- randomInit(pA, cnDimension);
- randomInit(pB, cnDimension);
- // allocate memory on the device
- CUdeviceptr pDeviceMemA, pDeviceMemB, pDeviceMemC;
- cuMemAlloc(&pDeviceMemA, cnDimension * sizeof(float));
- cuMemAlloc(&pDeviceMemB, cnDimension * sizeof(float));
- cuMemAlloc(&pDeviceMemC, cnDimension * sizeof(float));
- // copy host vectors to device
- cuMemcpyHtoD(pDeviceMemA, pA, cnDimension * sizeof(float));
- cuMemcpyHtoD(pDeviceMemB, pB, cnDimension * sizeof(float));
- // setup parameter values
- cuFuncSetBlockShape(cuFunction, cnBlockSize, 1, 1);
- cuParamSeti(cuFunction, 0, pDeviceMemA);
- cuParamSeti(cuFunction, 4, pDeviceMemB);
- cuParamSeti(cuFunction, 8, pDeviceMemC);
- cuParamSetSize(cuFunction, 12);
- // execute kernel
- cuLaunchGrid(cuFunction, cnBlocks, 1);
- // copy the result from device back to host
- cuMemcpyDtoH((void *) pC, pDeviceMemC, cnDimension * sizeof(float));
- delete[] pA;
- delete[] pB;
- delete[] pC;
- cuMemFree(pDeviceMemA);
- cuMemFree(pDeviceMemB);
- cuMemFree(pDeviceMemC);
OpenCL的代码以文本方式存放在“sProgramSource”。 调用方式如下:
- const unsigned int cnBlockSize = 512;
- const unsigned int cnBlocks = 3;
- const unsigned int cnDimension = cnBlocks * cnBlockSize;
- // create OpenCL device & context
- cl_context hContext;
- hContext = clCreateContextFromType(0, CL_DEVICE_TYPE_GPU, 0, 0, 0);
- // query all devices available to the context
- size_t nContextDescriptorSize;
- clGetContextInfo(hContext, CL_CONTEXT_DEVICES, 0, 0, &nContextDescriptorSize);
- cl_device_id * aDevices = malloc(nContextDescriptorSize);
- clGetContextInfo(hContext, CL_CONTEXT_DEVICES, nContextDescriptorSize, aDevices, 0);
- // create a command queue for first device the context reported
- cl_command_queue hCmdQueue;
- hCmdQueue = clCreateCommandQueue(hContext, aDevices[0], 0, 0);
- // create & compile program
- cl_program hProgram;
- hProgram = clCreateProgramWithSource(hContext, 1, sProgramSource, 0, 0);
- clBuildProgram(hProgram, 0, 0, 0, 0, 0);// create kernel
- cl_kernel hKernel;
- hKernel = clCreateKernel(hProgram, “vectorAdd”, 0);
- // allocate host vectors
- float * pA = new float[cnDimension];
- float * pB = new float[cnDimension];
- float * pC = new float[cnDimension];
- // initialize host memory
- randomInit(pA, cnDimension);
- randomInit(pB, cnDimension);
- // allocate device memory
- cl_mem hDeviceMemA, hDeviceMemB, hDeviceMemC;
- hDeviceMemA = clCreateBuffer(hContext, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cnDimension * sizeof(cl_float), pA, 0);
- hDeviceMemB = clCreateBuffer(hContext, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cnDimension * sizeof(cl_float), pA, 0);
- hDeviceMemC = clCreateBuffer(hContext,
- CL_MEM_WRITE_ONLY,
- cnDimension * sizeof(cl_float), 0, 0);
- // setup parameter values
- clSetKernelArg(hKernel, 0, sizeof(cl_mem), (void *)&hDeviceMemA);
- clSetKernelArg(hKernel, 1, sizeof(cl_mem), (void *)&hDeviceMemB);
- clSetKernelArg(hKernel, 2, sizeof(cl_mem), (void *)&hDeviceMemC);
- // execute kernel
- clEnqueueNDRangeKernel(hCmdQueue, hKernel, 1, 0, &cnDimension, 0, 0, 0, 0);
- // copy results from device back to host
- clEnqueueReadBuffer(hContext, hDeviceMemC, CL_TRUE, 0, cnDimension * sizeof(cl_float),
- pC, 0, 0, 0);
- delete[] pA;
- delete[] pB;
- delete[] pC;
- clReleaseMemObj(hDeviceMemA);
- clReleaseMemObj(hDeviceMemB);
- clReleaseMemObj(hDeviceMemC);
- 初始化部分的异同
CUDA 在使用任何API之前必须调用cuInit(0),然后是获得当前系统的可用设备并获得Context。
cuInit(0);
cuDeviceGet(&hContext, 0);
cuCtxCreate(&hContext, 0, hDevice));
OpenCL不用全局的初始化,直接指定设备获得句柄就可以了
cl_context hContext;
hContext = clCreateContextFromType(0, CL_DEVICE_TYPE_GPU, 0, 0, 0);
设备创建完毕后,可以通过下面的方法获得设备信息和上下文:
size_t nContextDescriptorSize;
clGetContextInfo(hContext, CL_CONTEXT_DEVICES, 0, 0, &nContextDescriptorSize);
cl_device_id * aDevices = malloc(nContextDescriptorSize);
clGetContextInfo(hContext, CL_CONTEXT_DEVICES, nContextDescriptorSize, aDevices, 0);
OpenCL introduces an additional concept: Command Queues. Commands launching kernels and
reading or writing memory are always issued for a specific command queue. A command queue is
created on a specific device in a context. The following code creates a command queue for the
device and context created so far:
cl_command_queue hCmdQueue;
hCmdQueue = clCreateCommandQueue(hContext, aDevices[0], 0, 0);
With this the program has progressed to the point where data can be uploaded to the device’s
memory and processed by launching compute kernels on the device.
- Kernel Creation
CUDA kernel 以二进制格式存放与CUBIN文件中间,其调用格式和DLL的用法比较类似,先装载二进制库,然后通过函数名查找
函数地址,最后用将函数装载到GPU运行。示例代码如下:
CUmodule hModule;
cuModuleLoad(&hModule, “vectorAdd.cubin”);
cuModuleGetFunction(&hFunction, hModule, "vectorAdd");
OpenCL 为了支持多平台,所以不使用编译后的代码,采用类似JAVA的方式,装载文本格式的代码文件,然后即时编译并运行。
需要注意的是,OpenCL也提供API访问kernel的二进制程序,前提是这个kernel已经被编译并且放在某个特定的缓存中了。
// 装载代码,即时编译
cl_program hProgram;
hProgram = clCreateProgramWithSource(hContext, 1, “vectorAdd.c", 0, 0);
clBuildProgram(hProgram, 0, 0, 0, 0, 0);
// 获得kernel函数句柄
cl_kernel hKernel;
hKernel = clCreateKernel(hProgram, “vectorAdd”, 0);
- 设备内存分配
内存分配没有什么大区别,OpenCL提供两组特殊的标志,CL_MEM_READ_ONLY 和 CL_MEM_WRITE_ONLY 用来控制内存
的读写权限。另外一个标志比较有用:CL_MEM_COPY_HOST_PTR 表示这个内存在主机分配,但是GPU可以使用,运行时会自动
将主机内存内容拷贝到GPU,主机内存分配,设备内存分配,主机拷贝数据到设备,3个步骤一气呵成。
// CUDA
CUdeviceptr pDeviceMemA, pDeviceMemB, pDeviceMemC;
cuMemAlloc(&pDeviceMemA, cnDimension * sizeof(float));
cuMemAlloc(&pDeviceMemB, cnDimension * sizeof(float));
cuMemAlloc(&pDeviceMemC, cnDimension * sizeof(float));
cuMemcpyHtoD(pDeviceMemA, pA, cnDimension * sizeof(float));
cuMemcpyHtoD(pDeviceMemB, pB, cnDimension * sizeof(float));
// OpenCL
hDeviceMemA = clCreateBuffer(hContext, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cnDimension * sizeof(cl_float), pA, 0);
hDeviceMemB = clCreateBuffer(hContext, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cnDimension * sizeof(cl_float), pA, 0);
hDeviceMemC = clCreateBuffer(hContext, CL_MEM_WRITE_ONLY, cnDimension * sizeof(cl_float), 0, 0);
- Kernel Parameter Specification
The next step in preparing the kernels for launch is to establish a mapping between the kernels’
parameters, essentially pointers to the three vectors A, B and C, to the three device memory regions,
which were allocated in the previous section.
Parameter setting in both APIs is a pretty low-level affair. It requires knowledge of the total number
, order, and types of a given kernel’s parameters. The order and types of the parameters are used to
determine a specific parameters offset inside the data block made up of all parameters. The offset in
bytes for the n-th parameter is essentially the sum of the sizes of all (n-1) preceding parameters.
Using the CUDA Driver API:
In CUDA device pointers are represented as unsigned int and the CUDA Driver API has a
dedicated method for setting that type. Here’s the code for setting the three parameters. Note how
the offset is incrementally computed as the sum of the previous parameters’ sizes.
cuParamSeti(cuFunction, 0, pDeviceMemA);
cuParamSeti(cuFunction, 4, pDeviceMemB);
cuParamSeti(cuFunction, 8, pDeviceMemC);
cuParamSetSize(cuFunction, 12);
Using OpenCL:
In OpenCL parameter setting is done via a single function that takes a pointer to the location of the
parameter to be set.
clSetKernelArg(hKernel, 0, sizeof(cl_mem), (void *)&hDeviceMemA);
clSetKernelArg(hKernel, 1, sizeof(cl_mem), (void *)&hDeviceMemB);
clSetKernelArg(hKernel, 2, sizeof(cl_mem), (void *)&hDeviceMemC);
携手OPENCL CUDA架构能否成惟一领袖
如果你是苹果的粉丝,你一定会结识一个新朋友——NVIDIA;如果你是NVIDIA的粉丝,那你一定欣喜自己与万人迷“苹果”走的更近。在今年10月24日,老乔津津有味的拿着一串数据来宣布旗下MacBook全系列产品以及今后相关众多Mac产品将采用NVIDIA相关方案,苹果的粉丝被教父的Keynote所打动,开始学习只有DIY发烧友才关注的一些技术名词,他们在论坛里热情高涨,讨论着“HybridSLI”、“CUDA”、“PureVideo”等等。
|
||
| 视觉革命与计算革命 |

苹果与NVIDIA本月又联手上演好戏,本月,苹果又向大家宣布的OPENCL标准,它将在苹果明年初推出的新一代操作系统Snow Leopard上开始支持,虽然我们看到支持的成员几乎涵盖了业内所有的知名企业,但大家应该清楚,在孕育OPENCL的过程中,能够提供硬件平台的只有NVIDIA,当然OPENCL标准工作组Khronos也首次将如此多的业内精英撮合到一起为了一个“并行计算”的新API。
|

大家为什么要支持OPENCL?首先简单了解一下OPENCL和异构系统?OPENCL英文全称Open Computing Language,是基于异构系统并行编程的一个全新API,命名上虽然与OPENGL(Open Graphics Library)类似但方向上有很大不同,但开发上又存在一些联系。在未来计算领域,异构系统已经被公认为发展趋势,即CPU与平行处理器的异构形式,这也是未来Intel的发展方向。而我们目前能看到的能够提供异构系统,并有成熟软件平台支持的仅有NVIDIA的CUDA架构。
在OPENCL标准组织中,由于Intel和AMD的加入,让大家对CUDA与OPENCL的关系产生很多疑问,本来已经成熟的CUDA平台,为什么还需要一个新API的加入?Intel和AMD如何和OPENCL兼容?OPENCL和CUDA谁更好?这都是非常集中的问题。
我们来看看Khronos OPENCL组织是如何组成的。我们知道,在OPENGL时期,该标准也是由Khronos这样一个协调机构来运作的。而你会发现,这次OPENCL由苹果作为代表发布,也正是苹果选择NVIDIA战略中的重要一环,与其说OPENCL是苹果发起的,还不如说是NVIDIA策划的。而事实的确如此,NVIDIA副总裁Neil Trevett正是现在Khronos OPENCL工作的主席,OPENCL的标准的创立也是NVIDIA技术为基础的,其中骨干员工也大半来自NVIDIA。其实这也不难理解,要做一个异构并行计算的系统和标准API,除了NVIDIA,你还能找谁呢?
|

而下面这张图也许是在此次OPENCL发布后较为常见的一个,不过其中意义大家不一定能够完全领会,我们在这里做一个说明。这是一张能够解释大家对OPENCL与CUDA关系疑问的重要“结构”图。NVIDIA第一次明确了两个重要名词“CUDA架构”与“CUDA C语言”。在以往理解中,我们常默认CUDA就是指基于NVIDIA GPU或并行处理器的编译器、C语言、库和相关软件开发环境;而硬件方面,则是指所有支持CUDA的GPU。今天,NVIDIA明确了包括硬件支持和软件环境一起,我们称之为CUDA架构,而常用的基于C语言的开发环境则是CUDA C,或者CUDA Fortran,CUDA C++,以及今后的CUDA JAVA等等。而OPENCL,也与之并列。
|

具体来说,NVIDIA将CUDA架构看作是一个异构计算中并行计算部分的核心,无论你使用怎样的高级语言或者是怎样的API的形式进行开发,在硬件上均符合CUDA架构(即NVIDIA GPU/并行处理器)。这有点类似于传统CPU领域,无论你使用何种高级语言、汇编语言、API进行软件开发,但是都为X86架构服务。
解决了OPENCL与CUDA,确切的说是与CUDA C的争论的问题,大家仍心存疑问。NVIDIA在初期宣传CUDA C时,其优势就在于高级语言对软件开发的便利和普遍性,而OPENCL API级别的编程相对C语言来说又有什么优势和必要?我们认为,此时NVIDIA宣传CUDA与1年前初期阶段已经有所不同,高级语言的支持是CUDA努力的主要方向,而如何全方位的吸引开发人员的加入,这对CUDA来说同样重要。
|
||
| CUDA C擅长与服务的对象 |
|
||
| OPENCL的特点与服务对象 |

我们从图中看到,API和C语言在开发技术上有所不同,NVIDIA表示对原有OPENGL开发人员来说一定会喜欢OPENCL,因为其中有很多类似之处;同时,NVIDIA也表示,由于都是基于CUDA架构,所以OPENCL与CUDA C之间如果真需要迁移也是相对方便的(似乎没有太大必要,总之都是基于同样硬件架构的)。NVIDIA认为,目前对于并行计算而言,开发语言和API并不是太多,而是太少,未来DirectX11 Compute Shader同样是基于CUDA架构的。
OPENCL的发布仅仅是一个开始,从路线图来看要到2009年中,OPENC 1.0正式版才将发布,这个时间似乎要比苹果Snow Leopard操作系统发布时间还稍晚些,但基于NVIDIA CUDA架构的OPENCL开发的软件在新一代MacOS上有怎样的表现,却非常值得期待。
|
||
| OPENCL的发展蓝图 |

|
||
| CUDA C语言的路线图 |
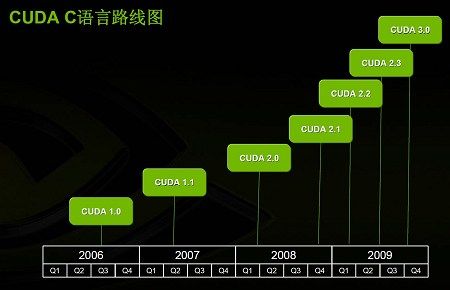
CUDA C语言路线图则非常细致,但在这里NVIDIA没有公布每个版本带来的变化。但纵观半年来CUDA2.0发布后的变化,在初期第三方和NVIDIA开发的一些算法已经被CUDA 2.0加入到库中,例如FFT高速傅立叶变换,FIR滤波等等。对于需要这些数学计算的使用者来说,不需要懂得C语言、CUDA编程,只要替换库中的相关语句和参数,便可以让它的计算提速几十倍。
OPENCL与CUDA的关系大家应该非常清楚了,但我们最为好奇的是,在中国市场一个看上去仅仅MacOS支持的API会得到如此大关注,这有些令人不能理解。虽然苹果的IPOD和IPHONE在中国市场的欢迎程度相当高,但MacOS的占有率是相当低,即便MacBook的用户也有大半人数和大半时间在使用着Windows操作系统,苹果发布OPENCL,将在下一代操作系统Snow Leopard中使用,竟然有人关心这种边缘新闻?
|
||
| 乔布斯为什么会喜欢NVIDIA? |

经过前文一大串的讲述,我们对OPENCL应该有了大概的了解。而我们的身份似乎不经意间变成了苹果和NVIDIA的拥护者,大家主动的对OPENCL和CUDA提出各种各样的问题,其热情完全不亚于对待3G IPHONE和Macbook Air的发布上市,将对待品牌的热情延续到技术品牌与技术本身,实在是一件神奇的事情。这不由让我们想起了神奇的乔布斯,老乔。
曾经有朋友评价,苹果选择NVIDIA非常符合老乔的性格,理由很简单,老乔喜欢有个性的东西,同时也具有对未来敏锐的前瞻性,Macbook系列使用NVIDIA GPU产品,其实只是一个开始。而我更加同意另一个有趣的观点,他们认为老乔这次是被NVIDIA 黄仁勋感动了,这也同样很容易理解。当OPENCL在MacOS上得以应用,让Macbook因此受益时,这才仅仅是NVIDIA CUDA架构与并行计算革命中的一部分,CUDA架构的作为不仅仅是OPENCL如此简单,CUDA架构目前已经成为并行计算革命的惟一领导者。
从CUDA开始读OpenCL
就像大一学C++,大二学汇编一样,我也写弄了些个月的CUDA,然后,想想,应该开始刨根问底地,去学点在CUDA之下层的东西,可能会对异构这个编程了解的多。
1 简介
OpenCL全称:开发计算语言,是并行程序的开发标准,使用与任何异构平台——包括多CPU、GPU、CPU与GPU结合等。OpenCL由Khronos Group维护。
OpenCL是一个用于异构平台上编程的开放性行业标准。这个平台可以包括 CPU GPU和其他各类计算设备,例如 DSP和Cell/B.E.等等。
OpenCL和CUDA的关系很和谐,前者是异构编程规范标准,后者是英伟达基于OpenCL之上开发的一个更面向程序员的GPUAPI。所以,OpenCL适合于包括英伟达和AMD等的显卡
程序开发。
2 认识OpenCL的框架
2.1 平台模型
[1个host]-[1..N个device] (主机:host;设备:device)
[1个device]-[1..N个CU] (计算单元:CU)
[1个CU]-[1..N个PE] (处理单元:PU)
host端管理者整个平台的所有计算资源,应用程序会从host端向各个 OpenCL设备的处理单元发送计算命令。在一个计算单元内的所有处理单元会执行完全相同的一套指令
流程。指令流可以是 SIMD模式或者SPMD模式。所有由OpenCL编写的应用程序都是从Host启动并结束,最终的计算都发生在PE中。
2.2 内存模型
内存介绍:
全局内存 (global memory):工作空间内所有的工作节点都可以读写此类内存中的任意元素。OpenCL C提供了缓存global buer的内建函数。
常量内存 (constant memory):工作空间内所有的工作节点可以只读此类内存中的任意元素。 host负责分配和初始化 constant buer,在内核执行过程中保持不变。
局部内存 (local memory):从属于一个工作组的内存,同一个工作组中所有的工作节点都可以共享使用该类内存。其实现既可以为 OpenCL执行为其分配一块专有内存空间,
也有可能直接将其映射到一块global buer上。
私有内存 (private memory):只从属于当前的工作节点。一个工作节点内部的private buer其他节点是完全不可见的。
在这点上,基本上和CUDA介绍的内存是一样的。这里的局部内存和CUDA的私有变量差不多一个概念。
内存使用:
在内存的使用上,有两种方式:内存拷贝和内存映射。
拷贝数据是指host通过相应的OpenCL API将数据从host写入到OpenCL设备的内存中或者从 OpenCL设备内存读出数据到 host内存中。
内存映射方法允许用户通过相应 OpenCLAPI将OpenCL的内存对象映射到 host端可见的内存地址空间中。映射之后用户就可以在 host端的映
射地址读写该内存了,在读写完成之后用户必须使用对应 API解除这种映射关系。同拷贝内存方式一样,映射内存也分block和non-block模式。
2.3 执行模型
OpenCL的执行模型可以分为两部分,一部分是在 host上执行的主程序(host program),另一部分是在 OpenCL设备上执行的内核程序(kernels),OpenCL通过主程序来
定义上下文并管理内核程序在OpenCL设备的执行。
执行模式最重要的是分配线程网络,这点和CUDA是一回事,可以引用。
2.4 编程模型
OpenCL支持按数据并行的编程模型和按任务并行的编程模型。
数据并行模型是指同一系的列指令会作用在内存对象的不同元素上,即在不同内存元素上按这个指令序列定义了统一的运算。
在任务并行编程模型是指工作空间内的每个工作节点在执行 kernel程序时相对于其他节点是绝对独立的。在这种模式下对每个工作节点都相当于工作在一个单一的计算单
元内,该单元内只有单一工作组,该工作组中只有该节点本身在执行。用户可以通过如下方法实现按任务并行:
-使用OpenCL设备支持的向量类型数据结构
-同时执行或选择性执行多个kernels
-在执行kernels同时交叉性执行一些native kernels程序
OpenCL提供了两个领域的同步:
-在同一个工作组中所有的工作节点之间的同步
-同一个上下文中不同的 command queues之间和同一个 command queue的不同commands之间的同步
从CUDA了解openCL是在阅读和理解相关CUDA编程知识后,在读《OpenCL中文教程》的一个第一章和第二章的知识汇总,去掉了CUDA编程指南中讲解的雷同知识。在了解和
明白OpenCL是怎么一回事儿后,我将开始openCL的Hello world了,虽然,仅仅一个helloword可能没什么意义,但是,象征性的程序必须写起来。
OpenCL 与 CUDA相关推荐
- OpenCL与Cuda
作者:Boy Holy 链接:https://www.zhihu.com/question/19780484/answer/33008684 来源:知乎 著作权归作者所有,转载请联系作者获得授权. 根 ...
- GPU编程语言选择(OpenCL、CUDA 与C++ AMP)
其实在C++ AMP之前已经有了两个异构编程框架:CUDA与OpenCL.CUDA(Compute Unified Device Architecture)是显卡厂商Nvidia于2007年推出的业界 ...
- OpenCL和CUDA全解释
Khronos组织最近规范了OpenCL 1.0, OpenCL实际上是针对异构系统进行并行编程的一个全新的API,简单来说OpenCL它可以利用GPU,然后进行一些并行计算这方面的工作,这是API应 ...
- 使用显卡程序加速(opencl、cuda)
opencl源码 https://gitee.com/mirrors/hashcat.git CPU使用冯诺依曼结构,缓存大,处理单元少 GPU处理图像每个像素可以单独处理,缓存小,处理单元很多 op ...
- OpenCL与CUDA,CPU与GPU
OpenCL OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式.免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计 ...
- Ubuntu 20.04显卡驱、cuda和cudnn安装以及OpenCV3.3.1的加上openCL和cuda功能编译
文章目录 一.显卡驱动安装 1.1 卸载Ubuntu的SoftWare Update中安装的显卡驱动和将neavue黑名单 二.cuda安装注意事项和错误解决 三.编译OpenCV错误解决 一.显卡驱 ...
- VS2015 + CUDA 8.0 配置GTX1070的OpenCL 开发环境
一.查看计算机对OpenCL异构计算的支持情况 使用 GPU Caps Viewer 查看计算机对OpenCL的支持情况,目前最新的版本是 gpu-caps-viewer-1-32-0, 下载地址:h ...
- 从CUDA开始读OpenCL
就像大一学C++,大二学汇编一样,我也写弄了些个月的CUDA,然后,想想,应该开始刨根问底地,去学点在CUDA之下层的东西,可能会对异构这个编程了解的多. 1 简介 OpenCL全称:开发计算语言,是 ...
- CUDA与OpenCL架构
原文https://www.cnblogs.com/hlwfirst/p/5003504.html CUDA与OpenCL架构 目录 CUDA与OpenCL架构 目录 1 GPU的体系结构 1.1 G ...
最新文章
- java线程 kill linux_linux查看进程和线程的命令
- 使用HTML5 FormData轻松完成Ajax表单提交
- celery-01-异步任务模块-解决发送邮件的延时问题
- freeswitch 发update sip消息_VOS修改SIP注册端口
- 记一次生产数据库系统内存使用过高的案例
- 计算机课平时成绩重要吗,大学计算机基础课程平时成绩评定方法的研究.pdf
- 远在美国的凤姐为何选择回国理財?
- 马云说的新零售是错的【完善版】
- 简单计算器与面积结合计算器
- Unity UnityWebRequest从网页加载图片并永久保存在本地
- Android获内外网IP地址工具类(Json解析读取)
- 服务器80端口找不到,如何查询服务器80端口被关闭
- 用于提升多样性的Maximum Mutual Information算法
- 竞争压力下,运营商终于开打价格战了,中国移动提供超低价套餐
- 裸女街上走秀一小时 路人疯狂拍照无人制止
- matplot画图-画曲线(一)
- LabVIEWCNN基础
- SEO关键词排名优化的核心因素
- 计算机相关专业的兼职大总结
- JavaWeb——动态页面技术(JSP/EL/JSTL)
热门文章
- 【转】C++中如何区分构造函数与重载operator()得到的仿函数?
- 【转】深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈
- 【转】刨根究底CSS(2):CSS中的各种值——初始值,就是默认值吗?
- [你必须知道的.NET]第十八回:对象创建始末(上)
- 【转】aspx,ascx和ashx使用小结
- 【Excel】使用VLOOKUP+IF实现多列条件匹配查询
- 【Python CheckiO 题解】Multicolored Lamp
- REVERSE-PRACTICE-BUUCTF-26
- linux禁止u盘自动运行,求设置U盘自动运行和禁止运行的方法。
- 【51Nod - 1163】最高的奖励 (贪心+优先队列 或 妙用并查集)