潜在语义分析原理以及python实现代码!!!!
在Wiki上看到的LSA的详细介绍,感觉挺好的,遂翻译过来,有翻译不对之处还望指教。
原文地址:http://en.wikipedia.org/wiki/Latent_semantic_analysis
前言
浅层语义分析(LSA)是一种自然语言处理中用到的方法,其通过“矢量语义空间”来提取文档与词中的“概念”,进而分析文档与词之间的关系。LSA的基本假设是,如果两个词多次出现在同一文档中,则这两个词在语义上具有相似性。LSA使用大量的文本上构建一个矩阵,这个矩阵的一行代表一个词,一列代表一个文档,矩阵元素代表该词在该文档中出现的次数,然后再此矩阵上使用奇异值分解(SVD)来保留列信息的情况下减少矩阵行数,之后每两个词语的相似性则可以通过其行向量的cos值(或者归一化之后使用向量点乘)来进行标示,此值越接近于1则说明两个词语越相似,越接近于0则说明越不相似。
LSA最早在1988年由 Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landauer, Karen Lochbaum and Lynn Streeter提出,在某些情况下,LSA又被称作潜在语义索引(LSI)。
概述
词-文档矩阵(Occurences Matrix)
LSA 使用词-文档矩阵来描述一个词语是否在一篇文档中。词-文档矩阵式一个稀疏矩阵,其行代表词语,其列代表文档。一般情况下,词-文档矩阵的元素是该词在文档中的出现次数,也可以是是该词语的tf-idf(term frequency–inverse document frequency)。
词-文档矩阵和传统的语义模型相比并没有实质上的区别,只是因为传统的语义模型并不是使用“矩阵”这种数学语言来进行描述。
降维
在构建好词-文档矩阵之后,LSA将对该矩阵进行降维,来找到词-文档矩阵的一个低阶近似。降维的原因有以下几点:
- 原始的词-文档矩阵太大导致计算机无法处理,从此角度来看,降维后的新矩阵式原有矩阵的一个近似。
- 原始的词-文档矩阵中有噪音,从此角度来看,降维后的新矩阵式原矩阵的一个去噪矩阵。
- 原始的词-文档矩阵过于稀疏。原始的词-文档矩阵精确的反映了每个词是否“出现”于某篇文档的情况,然而我们往往对某篇文档“相关”的所有词更感兴趣,因此我们需要发掘一个词的各种同义词的情况。
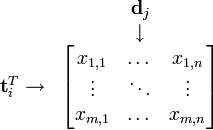
可以看到,每一行代表一个词的向量,该向量描述了该词和所有文档的关系。
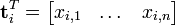
相似的,一列代表一个文档向量,该向量描述了该文档与所有词的关系。

词向量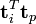 的点乘可以表示这两个单词在文档集合中的相似性。矩阵
的点乘可以表示这两个单词在文档集合中的相似性。矩阵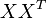 包含所有词向量点乘的结果,元素(i,p)和元素(p,i)具有相同的值,代表词p和词i的相似度。类似的,矩阵
包含所有词向量点乘的结果,元素(i,p)和元素(p,i)具有相同的值,代表词p和词i的相似度。类似的,矩阵 包含所有文档向量点乘的结果,也就包含了所有文档那个的相似度。
包含所有文档向量点乘的结果,也就包含了所有文档那个的相似度。
现在假设存在矩阵 的一个分解,即矩阵可分解成正交矩阵U和V,和对角矩阵
的一个分解,即矩阵可分解成正交矩阵U和V,和对角矩阵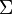 的乘积。
的乘积。
这种分解叫做奇异值分解(SVD),即:

因此,词与文本的相关性矩阵可以表示为:
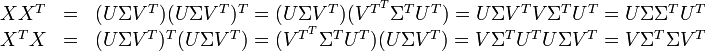
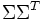 与
与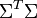 是对角矩阵,因此
是对角矩阵,因此 肯定是由的特征向量组成的矩阵,同理
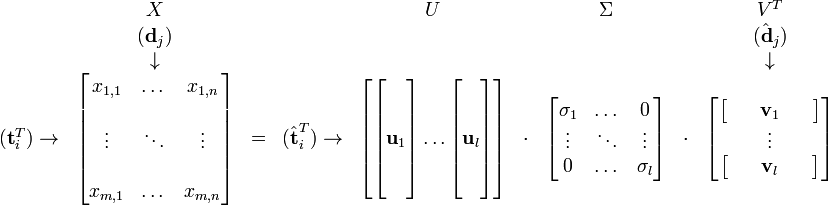
肯定是由的特征向量组成的矩阵,同理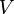 是特征向量组成的矩阵。这些特征向量对应的特征值即为中的元素。综上所述,这个分解看起来是如下的样子:
是特征向量组成的矩阵。这些特征向量对应的特征值即为中的元素。综上所述,这个分解看起来是如下的样子:
 被称作是奇异值,而
被称作是奇异值,而  和
和 则叫做左奇异向量和右奇异向量。通过矩阵分解可以看出,原始矩阵中的
则叫做左奇异向量和右奇异向量。通过矩阵分解可以看出,原始矩阵中的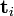 只与U矩阵的第i行有关,我们则称第i行为
只与U矩阵的第i行有关,我们则称第i行为  。同理,原始矩阵中的
。同理,原始矩阵中的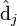 只与
只与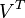 中的第j列有关,我们称这一列为。与并非特征值,但是其由矩阵所有的特征值所决定。
中的第j列有关,我们称这一列为。与并非特征值,但是其由矩阵所有的特征值所决定。
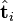 与含有k个奇异值的矩阵相乘,实质是从高维空间到低维空间的一个变换,可以理解为是一个高维空间到低维空间的近似。同理,向量
与含有k个奇异值的矩阵相乘,实质是从高维空间到低维空间的一个变换,可以理解为是一个高维空间到低维空间的近似。同理,向量 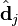 也存在这样一个从高维空间到低维空间的变化。这种变换用公式总结出来就是这个样子:
也存在这样一个从高维空间到低维空间的变化。这种变换用公式总结出来就是这个样子:
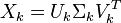
- 判断文档
 与
与  在低维空间的相似度。比较向量
在低维空间的相似度。比较向量 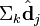 与向量
与向量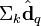 (比如使用余弦夹角)即可得出。
(比如使用余弦夹角)即可得出。 - 通过比较
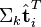 与
与 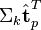 可以判断词
可以判断词 和词
和词 的相似度。
的相似度。 - 有了相似度则可以对文本和文档进行聚类。
- 给定一个查询字符串,算其在语义空间内和已有文档的相似性。

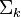 的逆矩阵可以通过求其中非零元素的倒数来简单的得到。
的逆矩阵可以通过求其中非零元素的倒数来简单的得到。
 将其映射到语义空间,再与文档进行比较。
将其映射到语义空间,再与文档进行比较。
低维的语义空间可以用于以下几个方面:
- 在低维语义空间可对文档进行比较,进而可用于文档聚类和文档分类。
- 在翻译好的文档上进行训练,可以发现不同语言的相似文档,可用于跨语言检索。
- 发现词与词之间的关系,可用于同义词、歧义词检测。.
- 通过查询映射到语义空间,可进行信息检索。
- 从语义的角度发现词语的相关性,可用于“选择题回答模型”(multi choice qustions answering model)。
(原文还说了一些其它方面,感觉不是很重要,不翻译了,放上原文)
Synonymy and polysemy are fundamental problems in natural language processing:
- Synonymy is the phenomenon where different words describe the same idea. Thus, a query in a search engine may fail to retrieve a relevant document that does not contain the words which appeared in the query. For example, a search for "doctors" may not return a document containing the word "physicians", even though the words have the same meaning.
- Polysemy is the phenomenon where the same word has multiple meanings. So a search may retrieve irrelevant documents containing the desired words in the wrong meaning. For example, a botanist and a computer scientist looking for the word "tree" probably desire different sets of documents.
Commercial applications[edit]
LSA has been used to assist in performing prior art searches for patents.[5]
Applications in human memory[edit]
The use of Latent Semantic Analysis has been prevalent in the study of human memory, especially in areas of free recall and memory search. There is a positive correlation between the semantic similarity of two words (as measured by LSA) and the probability that the words would be recalled one after another in free recall tasks using study lists of random common nouns. They also noted that in these situations, the inter-response time between the similar words was much quicker than between dissimilar words. These findings are referred to as the Semantic Proximity Effect.[6]
When participants made mistakes in recalling studied items, these mistakes tended to be items that were more semantically related to the desired item and found in a previously studied list. These prior-list intrusions, as they have come to be called, seem to compete with items on the current list for recall.[7]
Another model, termed Word Association Spaces (WAS) is also used in memory studies by collecting free association data from a series of experiments and which includes measures of word relatedness for over 72,000 distinct word pairs.[8]
算法局限性
LSA的一些缺点如下:
- 新生成的矩阵的解释性比较差.比如
-
- {(car), (truck), (flower)} ↦ {(1.3452 * car + 0.2828 * truck), (flower)}
-
(1.3452 * car + 0.2828 * truck) 可以解释成 "vehicle"。同时,也有如下的变换
- {(car), (bottle), (flower)} ↦ {(1.3452 * car + 0.2828 * bottle), (flower)}
- 造成这种难以解释的结果是因为SVD只是一种数学变换,并无法对应成现实中的概念。
- LSA无法扑捉一词多以的现象。在原始词-向量矩阵中,每个文档的每个词只能有一个含义。比如同一篇文章中的“The Chair of Board"和"the chair maker"的chair会被认为一样。在语义空间中,含有一词多意现象的词其向量会呈现多个语义的平均。相应的,如果有其中一个含义出现的特别频繁,则语义向量会向其倾斜。
- LSA具有词袋模型的缺点,即在一篇文章,或者一个句子中忽略词语的先后顺序。
- LSA的概率模型假设文档和词的分布是服从联合正态分布的,但从观测数据来看是服从泊松分布的。因此LSA算法的一个改进PLSA使用了多项分布,其效果要好于LSA。
教你在Python中实现潜在语义分析
介绍
你有没有去过那种运营良好的图书馆?我总是对图书馆馆员通过书名、内容或其他主题保持一切井井有条的方式印象深刻。但是如果你给他们数千本书,要求他们根据书的种类整理出来,他们很难在一天内完成这项任务,更不用说一小时!
但是,如果这些书以电子的形式出现,就难不倒你了,对吧?所有的整理会在几秒之间完成,并且不需要任何人工劳动。自然语言处理(NLP)万岁!
看看下面这段话:

你可以从高亮的词语中总结出,这段话有三个主题(或概念)——主题1、主题2和主题3。一个良好的主题模型可以识别出相似的词语并将它们放在一组或一个主题下。上述示例中最主要的主题是主题2,表明这段文字主要关于虚假视频。
是不是很好奇?太好了!在本文中,我们将学习一种叫做主题建模的文本挖掘方法。这是一种非常有用的提取主题的技术,在面对NLP挑战时你会经常使用到它。
注意:我强烈建议您通读这篇文章了解SVD和UMAP等定义。它们在本文中经常出现,因此对它们有基本的理解有助于巩固这些概念。
目录
1. 什么是主题模型?
2. 何时使用主题建模?
3. 潜在语义分析(LSA)概述
4. 在Python中实现LSA
数据读取和检查
数据预处理
文档-词项矩阵(Document-Term Matrix)
主题建模
主题可视化
5. LSA的优缺点
6. 其他主题建模技术
什么是主题模型?
主题模型可定义为一种在大量文档中发现其主题的无监督技术。这些主题本质上十分抽象,即彼此相关联的词语构成一个主题。同样,在单个文档中可以有多个主题。我们暂时将主题模型理解为一个如下图所示的黑盒子:

这个黑盒子(主题模型)将相似和相关的词语聚集成簇,称为主题。这些主题在文档中具有特定的分布,每个主题都根据它包含的不同单词的比例来定义。
何时使用主题建模?
回想一下刚才提到的将相似的书籍整理到一起的例子。现在假设你要对一些电子文档执行类似的任务。只要文档的数量不太多,你就可以手动完成。但是如果这些文档的数量非常多呢?
这就是NLP技术脱颖而出的地方。对于这个任务而言,主题建模非常适用。

主题建模有助于挖掘海量文本数据,查找词簇,文本之间的相似度以及发现抽象主题。如果这些理由还不够引人注目,主题建模也可用于搜索引擎,判断搜索字段与结果的匹配程度。越来越有趣了,是不是?那么,请继续阅读!
潜在语义分析(LSA)概述
所有语言都有自己的错综复杂和细微差别,比如一义多词和一词多义,这对机器而言很难捕捉(有时它们甚至也被人类误解了!)。
例如,如下两个句子:
1. I liked his last novel quite a lot.
2. We would like to go for a novel marketing campaign.
在第一个句子中,'novel' 指一本书,而在第二个句子中,它的含义是新奇的、新颖的。
我们能够轻松地区分这些单词,是因为我们可以理解这些词背后的语境。但是,机器并不能捕捉到这个概念,因为它不能理解单词的上下文。这就是潜在语义分析(LSA)发挥作用的地方,它可以利用单词所在的上下文来捕捉隐藏的概念,即主题。
因此,简单地将单词映射到文档并没有什么用。我们真正需要的是弄清楚单词背后的隐藏概念或主题。LSA是一种可以发现这些隐藏主题的技术。现在我们来深入探讨下LSA的内部工作机制。
LSA的实施步骤
假设我们有m篇文档,其中包含n个唯一词项(单词)。我们希望从所有文档的文本数据中提取出k个主题。主题数k,必须由用户给定。
生成一个m×n维的文档-词项矩阵(Document-Term Matrix),矩阵元素为TF-IDF分数

然后,我们使用奇异值分解(SVD)把上述矩阵的维度降到k(预期的主题数)维
SVD将一个矩阵分解为三个矩阵。假设我们利用SVD分解矩阵A,我们会得到矩阵U,矩阵S和矩阵VT(矩阵V的转置)


矩阵Uk(document-term matrix)的每个行向量代表相应的文档。这些向量的长度是k,是预期的主题数。代表数据中词项的向量可以在矩阵Vk(term-topic matrix)中找到。
因此,SVD为数据中的每篇文档和每个词项都提供了向量。每个向量的长度均为k。我们可以使用余弦相似度的方法通过这些向量找到相似的单词和文档。
在Python中实现LSA
是时候启动Python并了解如何在主题建模问题中应用LSA了。开启Python环境后,请按照如下步骤操作。
数据读取和检查
在开始之前,先加载需要的库。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option("display.max_colwidth", 200)
在本文中,我们使用sklearn中的"20 Newsgroup"数据集,可从这里下载,然后按照代码继续操作。
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('header','footers',quotes'))
documents = dataset.data
len(documents)
Output: 11,314
Dataset.target_names
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
该数据集包含分布在20个不同新闻组中的11314篇文档。
数据预处理
首先,我们尝试尽可能地清理文本数据。我们的想法是,使用正则表达式replace("[^a-zA-Z#]", " ")一次性删除所有标点符号、数字和特殊字符,这个正则表达式可以替换除带空格的字母之外的所有内容。然后删除较短的单词,因为它们通常并不包含有用的信息。最后,将全部文本变为小写,使得大小写敏感失效。
news_df = pd.DataFrame({'document':documents})
# removing everything except alphabets
news_df['clean_doc'] = news_df['document'].str.replace("[^a-zA-Z#]", " ")
# removing short words
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
# make all the lowercase
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: x.lower())
最好将文本数据中的停止词删除,因为它们十分混乱,几乎不携带任何信息。停止词是指'it', 'they', 'am', 'been', 'about', 'because', 'while'之类的词汇。
要从文档中删除停止词,我们必须对文本进行标记,将文本中的字符串拆分为单个的标记或单词。删除完停止词后,我们将标记重新拼接到一起。
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# tokenization
tokenized_doc = news_df['clean_doc'].apply(lambda x: x.split())
# remove stop-words
tokenized_doc = tokenized_doc.apply(lambda x: [item for item in x ifitem not in stop_words])
# de-tokenization
detokenized_doc = []
for i in range(len(news_df)):
t = ' '.join(tokenized_doc[i])
detokenized_doc.append(t)
news_df['clean_doc'] = detokenized_doc
文档-词项矩阵(Document-Term Matrix)
这是主体建模的第一步。我们将使用sklearn的TfidfVectorizer来创建一个包含1000个词项的文档-词项矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words='english',
max_features =1000, # keep top 1000 terms
max_df = 0.5,
smooth_idf = True)
X = vectorizer.fit_transform(news_df['clean_doc'])
X.shape # check shape of the document-term matrix
(11314, 1000)
我们也可以使用全部词项来创建这个矩阵,但这回需要相当长的计算时间,并占用很多资源。因此,我们将特征的数量限制为1000。如果你有计算能力,建议尝试使用所有词项。
主题建模
下一步是将每个词项和文本表示为向量。我们将使用文本-词项矩阵,并将其分解为多个矩阵。我们将使用sklearn的TruncatedSVD来执行矩阵分解任务。
由于数据来自20个不同的新闻组,所以我们打算从文本数据中提取出20个主题。可以使用n_components参数来制定主题数量。
from sklearn.decomposition import TruncatedSVD
# SVD represent documents and terms in vectors
svd_model = TruncatedSVD(n_components=20, algorithm='randomized', n_iter=100, random_state=122)
svd_model.fit(X)
len(svd_model.components_)
20
svd_model的组成部分即是我们的主题,我们可以通过svd_model.components_来访问它们。最后,我们打印出20个主题中前几个最重要的单词,看看我们的模型都做了什么。
terms = vectorizer.get_feature_names()
for i, comp in enumerate(svd_model.components_):
terms_comp = zip(terms, comp)
sorted_terms = sorted(terms_comp, key=lambda x:x[1], reverse=True)[:7]
print("Topic "+str(i)+": ")
for t in sorted_terms:
print(t[0])
print(" ")
Topic 0: like know people think good time thanks
Topic 0: like know people think good time thanks
Topic 1: thanks windows card drive mail file advance
Topic 2: game team year games season players good
Topic 3: drive scsi disk hard card drives problem
Topic 4: windows file window files program using problem
Topic 5: government chip mail space information encryption data
Topic 6: like bike know chip sounds looks look
Topic 7: card sale video offer monitor price jesus
Topic 8: know card chip video government people clipper
Topic 9: good know time bike jesus problem work
Topic 10: think chip good thanks clipper need encryption
Topic 11: thanks right problem good bike time window
Topic 12: good people windows know file sale files
Topic 13: space think know nasa problem year israel
Topic 14: space good card people time nasa thanks
Topic 15: people problem window time game want bike
Topic 16: time bike right windows file need really
Topic 17: time problem file think israel long mail
Topic 18: file need card files problem right good
Topic 19: problem file thanks used space chip sale
主题可视化
为了找出主题之间的不同,我们将其可视化。当然,我们无法可视化维度大于3的数据,但有一些诸如PCA和t-SNE等技术可以帮助我们将高维数据可视化为较低维度。在这里,我们将使用一种名为UMAP(Uniform Manifold Approximation and Projection)的相对较新的技术。
import umap
X_topics = svd_model.fit_transform(X)
embedding = umap.UMAP(n_neighbors=150, min_dist=0.5, random_state=12).fit_transform(X_topics)
plt.figure(figsize=(7,5))
plt.scatter(embedding[:, 0], embedding[:, 1],
c = dataset.target,
s = 10, # size
edgecolor='none'
)
plt.show()

如上所示,结果非常漂亮。每个点代表一个文档,颜色代表20个新闻组。我们的LSA模型做得很好。可以任意改变UMAP的参数来观察其对图像的影响。
可在此找到本文的完整代码。
LSA的优缺点
如上所述,潜在语义分析非常有用,但是确实有其局限性。因此,对LSA的优缺点都有充分的认识十分重要,这样你就知道何时需要使用LSA,以及何时需要尝试其他方法。
优点:
LSA快速且易于实施。
它的结果相当好,比简单的向量模型强很多。
缺点:
因为它是线性模型,因此在具有非线性依赖性的数据集上可能效果不佳。
LSA假设文本中的词项服从正态分布,这可能不适用于所有问题。
LSA涉及到了SVD,它是计算密集型的,当新数据出现时难以更新。
其他主题建模技术
除了LSA,还有其他一些先进并有效的主题建模技术,如LDA(Latent Dirichlet Allocation)和Ida2Vec。我们有一篇关于LDA的精彩文章,你可以在这里查看。Ida2vec是一个基于word2vec单词嵌入的更先进的主题建模技术。如果你想对它有更多了解,可以在下方的评论中留言,我们很乐意回答你的问题。
尾记
本文意于与大家分享我的学习经验。主题建模是个非常有趣的话题,当你在处理文本数据集时会用到许多技巧和方法。因此,我敦促大家使用本文中的代码,并将其应用于不同的数据集。如果您对本文有任何疑问或反馈,请与我们联系。快乐地去挖掘文本吧!
原文标题:
Text Mining 101: A Stepwise Introduction to Topic Modeling using Latent Semantic Analysis (using Python)
原文链接:
https://www.analyticsvidhya.com/blog/2018/10/stepwise-guide-topic-modeling-latent-semantic-analysis/
潜在语义分析原理以及python实现代码!!!!相关推荐
- 哈夫曼编码原理与Python实现代码(附手动推导过程原稿真迹)
哈夫曼编码依据字符出现概率来构造异字头(任何一个字符的编码都不是其他字符的前缀)的平均长度最短的码字,通过构造二叉树来实现,出现频次越多的字符编码越短,出现频次越少的字符编码越长.为了演示哈夫曼编码原 ...
- 蒙特.卡罗方法求解圆周率近似值原理与Python实现
对于某些不能精确求解的问题,蒙特.卡罗方法是一种非常巧妙的寻找近似解的方法. 以求解圆周率的问题为例,假设有一个单位圆及其外切正方形,我们往正方形内扔飞镖,当扔的次数足够多以后,"落在圆内的 ...
- 教你在Python中实现潜在语义分析(附代码)
作者:PRATEEK JOSHI 翻译:李润嘉 校对:万文菁 本文约3400字,建议阅读15分钟. 本文将通过拆解LSA的原理及代码实例来讲解如何运用LSA进行潜在语义分析. 介绍 你有没有去过那种运 ...
- 随机森林分类算法python代码_随机森林的原理及Python代码实现
原标题:随机森林的原理及Python代码实现 最近在做kaggle的时候,发现随机森林这个算法在分类问题上效果十分的好,大多数情况下效果远要比svm,log回归,knn等算法效果好.因此想琢磨琢磨这个 ...
- 弗雷歇距离的原理及python代码实现(动态规划)
弗雷歇距离的原理及python代码实现(动态规划) 在网上看了很多关于弗雷歇距离的介绍,结合自己的理解,出一版更通俗易懂.更清晰具体的解释. 最简单的解释自然是最短狗绳长度,但我将从另一个角度来解释它 ...
- java寻优算法_模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径...
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
- 【机器学习入门】(9) 逻辑回归算法:原理、精确率、召回率、实例应用(癌症病例预测)附python完整代码和数据集
各位同学好,今天我和大家分享一下python机器学习中的逻辑回归算法.内容主要有: (1) 算法原理:(2) 精确率和召回率:(3) 实例应用--癌症病例预测. 文末有数据集和python完整代码 1 ...
- CRC爆破png图片宽度和高度原理以及python代码
CRC爆破png图片宽度和高度原理以及python代码 文章目录 CRC爆破png图片宽度和高度原理以及python代码 1.PNG图片的格式 2.CRC 3.Python爆破图片宽度和高度 参考文章 ...
- 【集成学习】:Stacking原理以及Python代码实现
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好.今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理.并在博文的后面附 ...
最新文章
- 上海居民被垃圾分类逼疯!这款垃圾自动分类器也许能帮上忙
- Python之基础知识
- html5电影在线看,HTML5-电影影评网
- 苹果截屏快捷键_新手小白用苹果电脑搞科研,学会这些才不至于尴尬!
- Codeforces Round #705 (Div. 2) D. GCD of an Array 质因子分解 + stl维护
- 最优化理论与算法笔记
- [存档]获取通讯录信息并写到SD卡上
- SQL STUFF用法很有趣的语法
- 【mongodb系统学习之十】mongodb查询(二)
- 2019一注结构成绩_2019年福建地区计算机考研汇总分析
- 俄罗斯方块python代码
- 数字图像处理基本知识点1(冈萨雷斯)
- c语言编程实现合取析取,C++实现离散数学求主合取范式和主析取范式
- 视频分割技巧,把视频分割成多段进行保存
- 讯飞配音使用记录:Excel VBA 编程处理多段短文字配音切分及 Hedit、GoldWave 后期处理、编程合成 WAV 文件
- 1400㎡,联诚发龙腾LED透明屏点燃五月天新加坡演唱会!
- iphone型号表_苹果所有产品型号大全
- 3种iPhone手机数据备份,轻松备份和恢复数据
- web后端--Django学习笔记04
- 大数据软件应用举例商圈分析城市管理