python爬取bilibili弹幕_python爬虫:bilibili弹幕爬取+词云生成

如果你懒得看下边的文字,我录了一个完整的教学视频在b站上。
我的B站教学:https://www.bilibili.com/video/av75377135?p=2
工作原理
b站是提供弹幕接口的,所以我们的整体操作进行如下:
1.到B站获取cid2.将cid与网站固定格式进行链接3.用python请求网页4.进行简单的单词处理5.生成词云
接下来我们就按照刚才说的顺序进行详细解释
操作顺序
1.到B站获取cid
首先点进一个视频网页,点击F12-network获取监测页面,然后一定要点击播放视频,我们就会在监测页面中看到一个叫heartbeat的XHR脚本,点开任意一个即可。
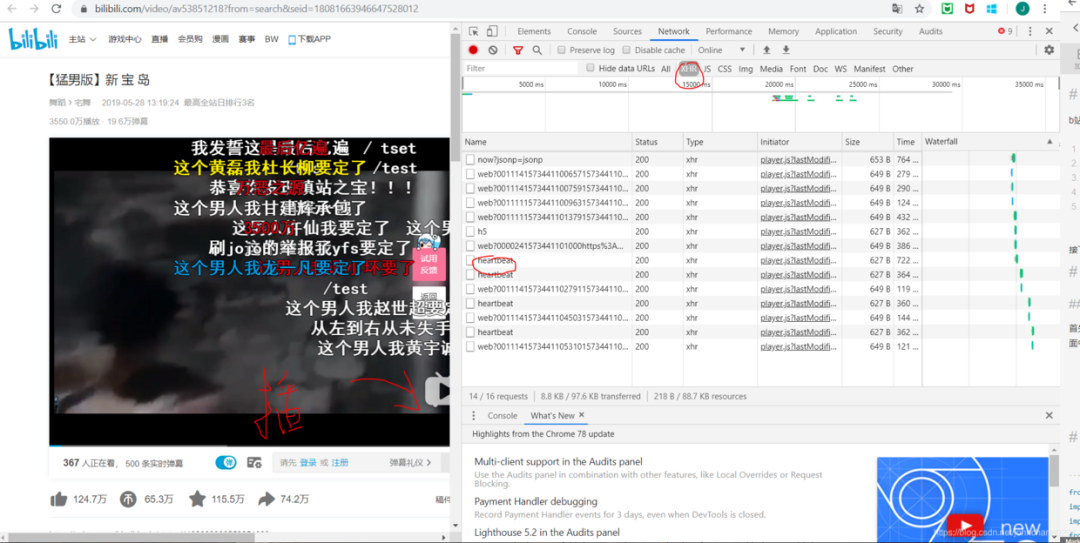
点击之后我们需要看Headers,里边包括了我们想知道的信息。往下滚动就会发现cid,这个id是唯一的,也就是说下次抓取的时候还可以用这个id。
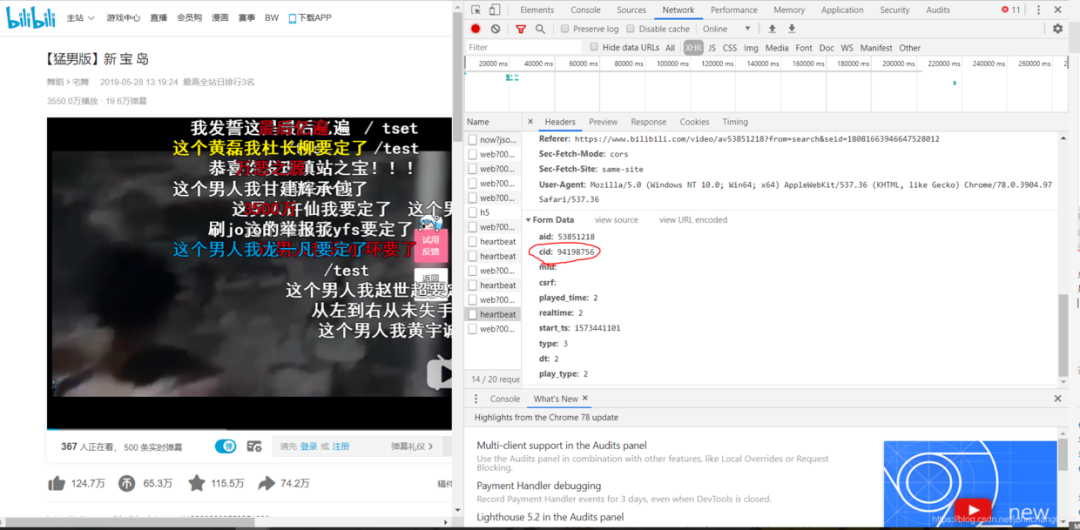
2.将cid与网站固定格式进行链接
我们拿到cid之后就可以去检查一下是否可以获取弹幕了。获取的固定xml格式是: https://comment.bilibili.com/视频的cid.xml
例如在这里我们的页面就是:
'https://comment.bilibili.com/94198756.xml'
我们把这个链接用网页的方式打开,就能看到如下内容:
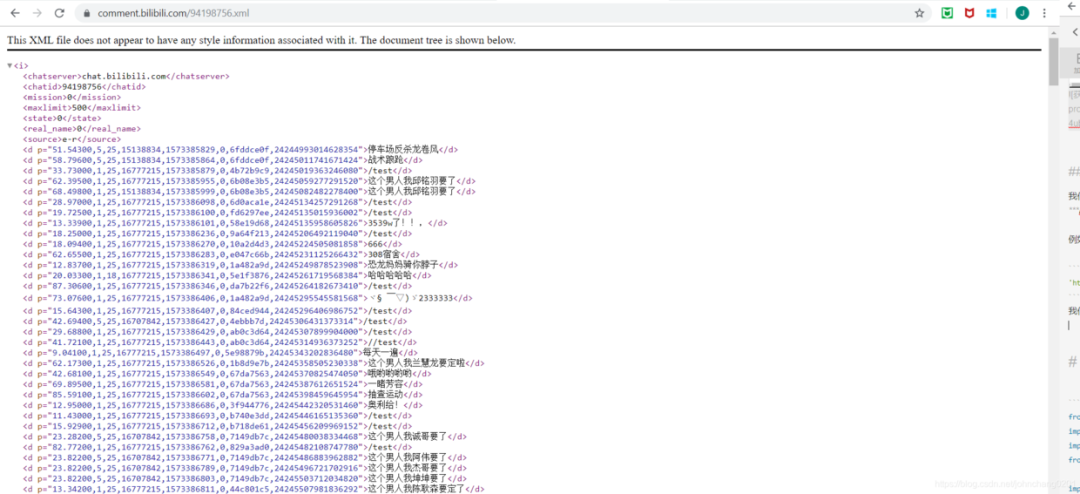
这样我们就确定可以爬取了。
3.用python请求网页
因为是开源的,我们也不需要设置代理agent什么的,直接获取就行
import requestsfrom bs4 import BeautifulSoupurl= 'https://comment.bilibili.com/94198756.xml'request = requests.get(url)#获取页面request.encoding='utf8'#因为是中文,我们需要进行转码,否则出来的都是unicode
通过之前的网页查看,我们发现弹幕的XML规律如下:
停车场反杀龙卷风
都是d开头,所以我们只需要用beautifulsuop来选取所有的‘d’就可以
soup = BeautifulSoup(request.text, 'lxml')results = soup.find_all('d')#找出所有'd'comments = [comment.text for comment in results]#因为出来的时候是bs4格式的,我们需要把他转化成list
这样一个完整的弹幕list就已经有了,这里要注意,b站弹幕提取上线是1000条,所以大于一千的就会随机选取1000条弹幕给你。
4.进行简单的单词处理
拿到之后的弹幕并不能直接满足我们进行单词分析,我们要进行一些简单的清理 (1)有一些英文我们需要统一大小写
comments = [x.upper() for x in comments]#统一大小写
(2)去掉弹幕中的空格 例:‘仙 人 指 路’ 和 ‘仙人指路’ 是没有区别的
comments_clean = [comment.replace(' ','') for comment in comments]#去掉空格
(3)我们简单的看一下弹幕之后发现弹幕里边的’/test’是有很多,但是我们并不需要它,诸如此类:
set(comments_clean)#看一下都有啥类似的没用的词语useless_words = ['//TEST','/TESR','/TEST','/TEST/','/TEXT','/TEXTSUPREME','/TSET','/Y','\\TEST']comments_clean = [element for element in comments_clean if element not in useless_words]#去掉不想要的字符
进行完上述处理之后,我们就可以进行词云的制作了。不过在制作之前,还是让我们简单的看一下词频。(不是最终的,因为一会要把句子里的词分开)
import pandas as pdcipin = pd.DataFrame({'danmu':comments_clean})cipin['danmu'].value_counts()
(4)分词 在这里我们把刚才得到的弹幕用jieba库进行分词
danmustr = ''.join(element for element in comments_clean)#把所有的弹幕都合并成一个字符串import jiebawords = list(jieba.cut(danmustr))#分词
(5)进一步clean 分词之后,我们会发现里边有很多的符号或者是单字,这些是没有意义的,我们要去掉这一些。
fnl_words = [word for word in words if len(word)>1]#去掉单字
5.生成词云
至此我们可以通过词词频来生成词云了 首先我们要下载词云的包
!pip install wordcloud
然后生成词云
import wordcloudwc = wordcloud.WordCloud(width=1000, font_path='simfang.ttf',height=800)#设定词云画的大小字体,一定要设定字体,否则中文显示不出来wc.generate(' '.join(fnl_words))
这样就生成了,我们现在来看一下
from matplotlib import pyplot as pltplt.imshow(wc)

如果不满意样子的话是可以在wordcloud.WordCloud里边调整的,例如可以调整画布大小,随机字体颜色区间,画布背景等等。或者更傻的方式就是重新跑一下wc.generate(’ '.join(fnl_words))就可以出来新的图片了
最后保存一下我们做好的图片
wc.to_file(r"C:\Users\CCHANG\Desktop\danmu_pic.png")
顺带提一句,我们还可以拿一个图片作为蒙版按形状生成图片。
我们需要先上传一个图片,把它做成numpy.array的形式。我们就自己画一个图吧,记住,上传的图片背景主题一定要对比鲜明
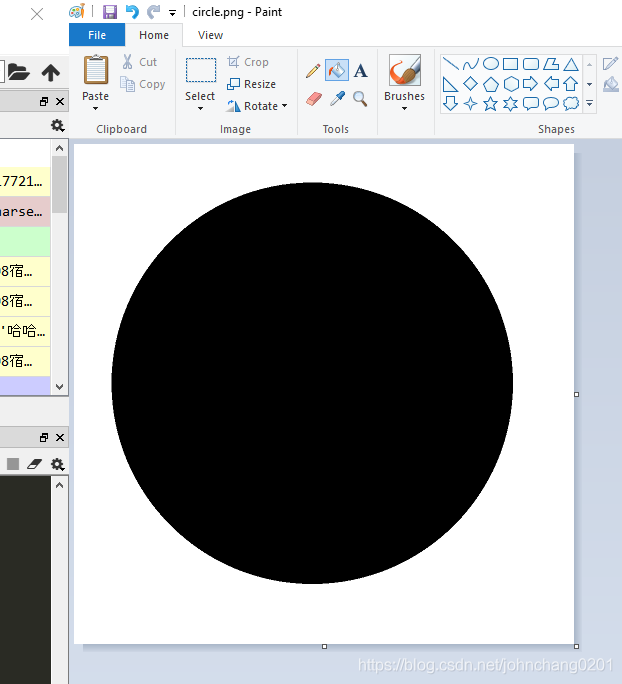
import cv2img = cv2.imread(r'C:\Users\CCHANG\Desktop\circle.png', cv2.IMREAD_UNCHANGED) #直接读取成了数字格式resized = cv2.resize(img, (800, 800),interpolation = cv2.INTER_AREA)#我们把它重新设定一下大小
不过有的时候用cv2不是非常稳定,所以我们还有另一种方法
from PIL import Imageimport numpy as npimg = Image.open(r'E:\录屏\course3\mask.jpg')resized = np.array(img)
然后我们调整wordcloud里边的一些设置,再生成一次
wc_1 = wordcloud.WordCloud(background_color='black',width=1000,height=800,mask=resized,font_path='simfang.ttf'# ,color_func = wordcloud.random_color_func())wc_1.generate_from_text(' '.join(fnl_words))#绘制图片plt.imshow(wc_1)plt.axis('off')plt.figure()plt.show() #显示图片
最后就变成了这样

记得保存哦~
wc_1.to_file(r'C:\Users\CCHANG\Desktop\danmu_pic_2.png')
记得如果看不懂就去看我的B站教学https://www.bilibili.com/video/av75377135?p=2
完整代码
import requestsfrom bs4 import BeautifulSoupimport pandas as pdimport jiebaimport wordcloudfrom matplotlib import pyplot as plturl= 'https://comment.bilibili.com/94198756.xml'request = requests.get(url)#获取页面request.encoding='utf8'#因为是中文,我们需要进行转码,否则出来的都是unicodesoup = BeautifulSoup(request.text, 'lxml')results = soup.find_all('d')#找出所有'd'comments =[comment.text for comment in results]#得到完整的listcomments = [x.upper() for x in comments]#统一大小写comments_clean = [comment.replace(' ','') for comment in comments]#去掉空格set(comments_clean)#看一下都有啥类似的没用的词语useless_words = ['//TEST','/TESR','/TEST','/TEST/','/TEXT','/TEXTSUPREME','/TSET','/Y','\\TEST']comments_clean =[element for element in comments_clean if element not in useless_words]#去掉不想要的字符cipin = pd.DataFrame({'danmu':comments_clean})cipin['danmu'].value_counts()#查看词频danmustr = ''.join(element for element in comments_clean)#把所有的弹幕都合并成一个字符串words = list(jieba.cut(danmustr))#分词fnl_words = [word for word in words if len(word)>1]#去掉单字wc = wordcloud.WordCloud(width=1000, font_path='simfang.ttf',height=800)#设定词云画的大小字体,一定要设定字体,否则中文显示不出来wc.generate(' '.join(fnl_words))plt.imshow(wc)#看图wc.to_file(r"C:\Users\CCHANG\Desktop\danmu_pic.png")#保存#######################################################加蒙板的图片import cv2img = cv2.imread(r'C:\Users\CCHANG\Desktop\circle.png', cv2.IMREAD_UNCHANGED) #直接读取成了数字格式resized = cv2.resize(img, (800, 800),interpolation = cv2.INTER_AREA)#我们把它重新设定一下大小#不过有的时候用cv2不是非常稳定,所以我们还有另一种方法#from PIL import Image#import numpy as np#img = Image.open(r'E:\录屏\course3\mask.jpg')#resized = np.array(img)wc_1 = wordcloud.WordCloud(background_color='black',width=1000,height=800,mask=resized,font_path='simfang.ttf'# ,color_func = wordcloud.random_color_func())wc_1.generate_from_text(' '.join(fnl_words))#绘制图片plt.imshow(wc_1)plt.axis('off')plt.figure()plt.show() #显示图片wc_1.to_file(r'C:\Users\CCHANG\Desktop\danmu_pic_2.png')
作者:https://blog.csdn.net/johnchang0201/article/details/103004229

IT入门 感谢关注
python爬取bilibili弹幕_python爬虫:bilibili弹幕爬取+词云生成相关推荐
- python爬取收费素材_Python爬虫练习:爬取素材网站数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 在工作中的电子文案.ppt,生活中的新闻.广告,都离不开大量的素材,而素材 ...
- python爬取新闻网站内容_python爬虫案例:抓取网易新闻
此文属于入门级级别的爬虫,老司机们就不用看了. 本次主要是爬取网易新闻,包括新闻标题.作者.来源.发布时间.新闻正文. 首先我们打开163的网站,我们随意选择一个分类,这里我选的分类是国内新闻.然后鼠 ...
- python爬视频网站数据_python爬虫基础应用----爬取无反爬视频网站
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- python爬百度贴吧_Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖内 ...
- python爬取携程网游记_Python爬虫案例:爬取携程评论
前言 之前爬取美团,马蜂窝等网站的数据都挺顺利,大众点评(这个反爬机制有点麻烦)在磕磕绊绊中也算成功(重点是网页页数的变化和关键字的隐藏替换)但携程居然遇到了瓶颈. 主要是查看源代码时发现关键商户信息 ...
- python手机壁纸超清_python爬虫学习之爬取5K分辨率超清唯美壁纸
前言 Python现在非常火,语法简单而且功能强大,很多同学都想学Python!所以小的给各位看官们准备了高价值Python学习视频教程及相关电子版书籍,欢迎前来领取! 简介 壁纸的选择其实很大程度上 ...
- 利用python爬取租房信息_Python爬虫实战(1)-爬取“房天下”租房信息(超详细)
#前言html 先看爬到的信息:python 今天主要用到了两个库:Requests和BeautifulSoup.因此我先简单的说一下这两个库的用法,提到的都是此文须要用到的.编程 #Requests ...
- python爬取凤凰新闻_Python爬虫实践(10)--爬取凤凰网汽车资讯详情
本期为python爬虫实践的第十节,传送门: python 通过上一期教程的代码,我们已经可以抓取到凤凰网汽车频道的资讯列表.本期教程,我们接着上一期的代码,去进一步获取资讯的详细内容. 资讯列表信息 ...
- python爬取控制台信息_python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- python爬取豆瓣书籍_python爬虫学习,爬取豆瓣各分类书单
点击蓝字"python教程"关注我们哟! 代码展示:pachon2.5.py # -- coding: utf-8 -- import urllib import urllib2 ...
最新文章
- gsonformat插件_收藏非常有用的IDEA插件,没用过这些IDEA插件?怪不得写代码头疼
- 道指mt4代码_道恩转债上市首日遭大股东清仓式减持!
- ROS-OccupancyGrid学习笔记
- OpenMV(二)--IDE安装与固件下载
- python绘图数字_绘制一个绘图,其中Yaxis文本数据(非数字)和Xaxis数字d
- Asp.Net实例:C# 绘制统计图(二) ——折线统计图的绘制
- python 中空NULL的表示
- OpenCV(一)Mac下OpenCV的安装和配置
- 人脸识别中常用的几种分类器
- 中交四航局及中广核工程公司学员参加友勤第12期Oracle P6项目管理软件培训班
- 如何选择网页更新提醒工具
- 支持Android 11安卓Flash播放器终极版源码方案2022(2:网页中嵌入)
- 一种基于C6748 DSP+FPGA的软件无线电平台的设计及应用
- sap 流程图 退货销售订单_ERP系统:退货流程的解决方案
- Excel自动调整行高/行高适应文字内容
- 意大利奢侈品牌-Kiton 华丽进驻北京新光天地-时尚生活-泛高尔夫网
- 面试经验:腾讯微信事业群 - 微信总部机器学习岗面试
- 笔试题-2023-思远半导体-数字IC设计【纯净题目版】
- Class1导数与变化率
- 计算机默认网关不可用如何解决问题,Win10网络诊断后提示“默认网关不可用”的问题怎么解决?...
热门文章
- Vista SP1、IIS7,安装ASP.Net 1.1、VS2003、NetAdvantage 2004vol、Sql Server2000全攻略
- java接口与集合_【总结】Java常用集合接口与集合类
- oracle透明网关 中文,Oracle透明网关的一些文章
- oracle 邮件过程,oracle 发邮件 存储过程
- 用单片机测量流体流速的_影响超声波流量计(热量表)测量精度的主要因素
- hive 多用户访问模注意问题
- 模块导入以及书写规则
- 每日一题20180330-Linux
- ORACLE快速遍历树及join基表很大的性能问题
- 【bzoj3514】 Codechef MARCH14 GERALD07加强版