hadoop1.2.1的安装
前提:1.机器最好都做ssh免密登录,最后在启动hadoop的时候会简单很多 免密登录看免密登录
2.集群中的虚拟机最好都关闭防火墙,否则很麻烦
3集群中的虚拟机中必须安装jdk.
具体安装步骤如下:
1.将 文件拷贝到linux系统中(可以拷贝到所以的虚拟机,也可以拷贝到一台虚拟机,最后进行复制)
文件拷贝到linux系统中(可以拷贝到所以的虚拟机,也可以拷贝到一台虚拟机,最后进行复制)
2.解压到/usr/local/hadoop ,看你需要安装到哪个目录就解压到哪个目录,解压命令 tar -zxvf ~/hadoop-1.2.1-bin.tar.gz -C /usr/local/hadoop ,解压完成就安装完了
接下来就应该修改配置文件
3.配置namenode和数据存储的位置,修改安装后hadoop-1.1.2下的conf文件夹下的core.site.xml文件
添加如下信息:(配置的namenode的ip和hadoop临时文件的地址)


<configuration><property><name>fs.default.name</name><value>hdfs://node05:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-1.2</value></property> </configuration>
core-site.xml
4.配置节点数(datanode) 编辑slaves文件
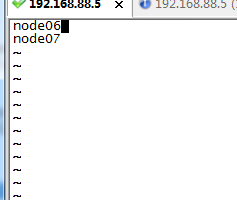
5.配置SecondaryNameNode,编辑masters文件,配置如下:
我一共用了三台虚拟机,node05是我的namenode节点.,node06,node07是我的datanode节点.同时node06也是我的SecondaryNameNode节点

6.配置数据的副本数 编辑hdfs-site.xml文件(副本数应该小于等于datanode的数量)
具体配置如下:
<configuration><property><name>dfs.replication</name><value>2</value></property> </configuration>
hdfs-site.xml
7.将我们安装的hadoop复制到其余几台虚拟机中,注意配置文件保持一致,否则会失败
8.格式化namenode,到hadoop安装后的bin目录下执行 ./hadoop namenode -format命令
如果出现Error:JAVA_HOME.....错误 请在hadoop 的conf目录下的hadoop-env.sh文件中配置如下:

9.接下来就可以启动hadoop了
启动的时候,到bin目录下执行 ./start-dfs.sh命令,(因为我这里没有安装hdfs所以执行的这个命令)
10:测试是否成功,在每台虚拟机中输入jps测试是否启动成功
node05:namenode: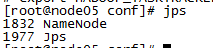
node06(是datanode也是SecondaryNameNode)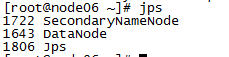
node07 datanode: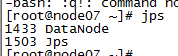
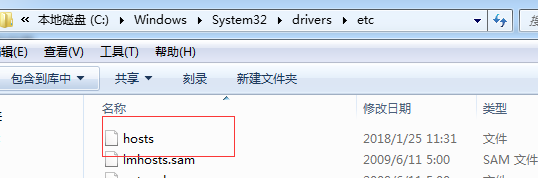
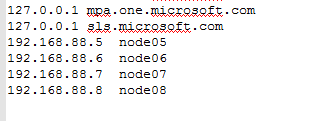
11,在物理机中,修改hosts文件,将我们的集群的ip和域名添加进去:
访问我们的namenode查看hadoop集群信息
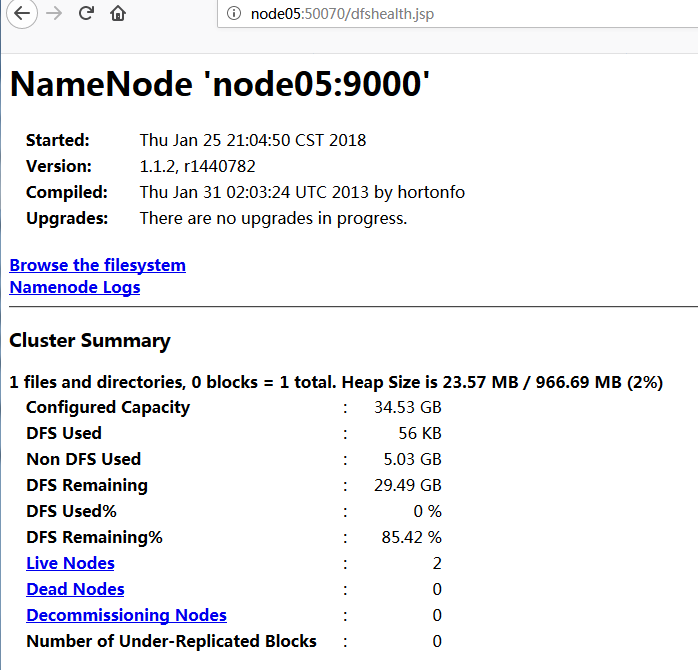
Live Nodes的节点数正确为2
如果Live Nodes的值为0
启动过程中动态查看hadoop的日志文件tail -f /usr/local/hadoop/hadoop-1.1.2/logs/hadoop-root-namenode-node05.log 查看有哪些错误,
如过提示
2018-01-25 20:54:09,903 INFO org.apache.hadoop.hdfs.server.namenode.DecommissionManager: Interrupted Monitor
java.lang.InterruptedException: sleep interrupted
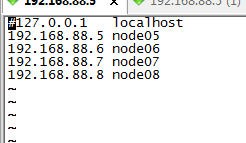
修改/etc/hosts文件
hadoop1.2.1的安装相关推荐
- hadoop1.1.2分布式安装---集群动态增减节点
0 关于配置机器别名,配置IP和别名映射,设置IP,关闭防火墙和自启动,单机下配置ssh请参考 hadoop1.1.2伪分布式安装(单机版)的文章, 链接: http://chengjianxiaox ...
- hadoop 1.2.1 安装步骤 伪分布式
最近在系统的学习hadoop 课程第一步是安装hadoop1.x,具体安装步骤如下: 一.系统安装 本文使用centos6.5安装,具体安装步骤省略 二.jdk安装 下载jdk1.7.0_51解压,在 ...
- Hadoop、Spark、Hbase、Hive的安装
为什么80%的码农都做不了架构师?>>> 工作中需要使用Hadoop环境,在三节点上搭建了一套Hadoop环境,顺便做下笔记.因为机器内存较低,没有使用CDH,为保证和线上环境 ...
- Hadoop安装(Ubuntu Kylin 14.04)
安装环境:ubuntu kylin 14.04 haoop-1.2.1 hadoop下载地址:http://apache.mesi.com.ar/hadoop/common/hadoop-1. ...
- hive-0.11.0安装方法具体解释
先决条件: 1)java环境,须要安装java1.6以上版本号 2)hadoop环境,Hadoop-1.2.1的安装方法參考 hadoop-1.2.1安装方法具体解释 本文採用的had ...
- Hadoop笔记-02 安装
文章目录 1 VBOX安装CentOS7 1.1 安装VBOX软件 1.2 下载CentOS7镜像文件 1.3 初始化VBOX虚拟盘 1.4 CentOS7网络配置 1.5 CentOS7 yum源配 ...
- hive安装:3.1.2版本
hive安装:3.1.2版本 hive下载地址: https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz 或 ...
- Postgres安装及操作笔记
目录 一.文档说明... 1 二.操作系统版本查询与yum源配置... 1 >服务端... 1 >客户端... 2 三.PostgreSQL检查与卸载... 3 1) PostgreSQL ...
- hadoop集群ambari搭建(1)之ambari-server安装
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应.管理和监控.Ambari目前已支持大多数Hadoop组件,包括HDFS.MapReduce.Hive.Pig ...
最新文章
- mysql配置日志老化配置_mysql中日志的配置与分析
- python成长之路——第四天
- Vmware学习虚拟机操作时遇到的问题和解决
- adas--智能驾驶辅助系统
- java8 注解增强_Java8新增的重复注解功能示例
- c#程序中使用quot;like“查询access数据库查询为空的问题
- 2如何识别操作系统_扫描车牌识别车牌号的功能sdk
- Klevgrand DAW LP for Mac(乙烯基唱片播放器模拟插件)
- java 遍历所有文件夹名_Java遍历文件夹下所有文件并重新命名
- 重装助手教你如何在Windows中正确调整屏幕分辨率设置
- 叙述码农和程序员的不同之处
- 《3D Point Cloud Registration for Localization using a Deep Neural Network Auto-Encoder》翻译
- 脉内分析从零开始(持续更新)
- 摄像头 SONY VISCA 协议
- java中String转Long类型
- VUE实现前台图片 标注(添加矩形框)、放大、缩小、拖拽 -----个人记录
- HTML —— 语义化标签
- 2015年中国青年生活形态调查报告
- zeppelin源码分析(0)——zeppelin要解决什么问题
- Settings.settings文件的用处