sql server 入门_SQL Server查询调整入门
sql server 入门
This article will cover some essential techniques for SQL query tuning. Query tuning is a very wide topic to talk about, but some essential techniques never change in order to tune queries in SQL Server. Particularly, it is a difficult issue for those who are a newbie to SQL query tuning or who are thinking about starting it. So, this article will be a good starting point for them. Also, other readers can refresh their knowledge with this article. In the next parts of this article, we will mention these techniques that help to tune queries.
本文将介绍一些用于SQL查询优化的基本技术。 查询调优是一个非常广泛的话题,但是为了调优SQL Server中的查询,某些基本技术从未改变。 尤其对于那些刚开始使用SQL查询优化或正在考虑启动它的人来说,这是一个难题。 因此,本文将是他们的一个很好的起点。 另外,其他读者可以通过本文来刷新自己的知识。 在本文的下一部分中,我们将提及有助于调优查询的这些技术。
避免在SELECT语句中使用星号“ *” (Avoid using the asterisk “*” sign in SELECT statements)
We should use the asterisk (star) sign solely when we need to return all columns of the table. However, this usage type becomes a bad habit by the programmers, and they start to type their queries with the “SELECT * “ statement. At various times in my database administrator career, I have experienced that the “SELECT * “ statement used to retrieve only one column of the multicolumn tables. Worse than this experience, the developer is not aware of this problem. This usage approach causes more network and I/O activity, so it affects the query performance negatively because of the more resource consumption. Now, we will make a pretty simple test to find out the performance difference between the “SELECT *” statement against “SELECT column_name1, column_name2, column_nameN” statement. Assume that, on a web application, we only need to show two columns, but we used the asterisk sign in our query.
仅在需要返回表的所有列时,才应仅使用星号(星号)。 但是,这种用法类型已成为程序员的坏习惯,并且他们开始使用“ SELECT * ”语句键入其查询。 在数据库管理员的职业生涯中的很多时候,我都经历过“ SELECT * ”语句仅用于检索多列表的一列。 比这种情况更糟糕的是,开发人员没有意识到这一问题。 这种使用方法会导致更多的网络和I / O活动,因此由于更多的资源消耗,会对查询性能产生负面影响。 现在,我们将进行一个非常简单的测试,以找出“ SELECT * ”语句与“ SELECT column_name1,column_name2,column_nameN ”语句之间的性能差异。 假设在Web应用程序上,我们只需要显示两列,但是在查询中使用星号。
SQL Server Management Studio (SSMS) offers a very helpful tool that helps to analyze and compare the executed queries performance metrics. This tool name is Client Statistics, and we will activate this option before executing the following two queries.
SQL Server Management Studio(SSMS)提供了非常有用的工具,可以帮助分析和比较执行的查询的性能指标。 该工具名称是客户统计 , 并且我们将在执行以下两个查询之前激活此选项。

Now we will execute the sample queries respectively and open the Client Statistics tab.
现在,我们将分别执行示例查询并打开“ 客户端统计信息”选项卡。
---Query-1 first execute this query---
SELECT *
FROM Sales.SalesOrderDetail;
---Query-2 ---SELECT SalesOrderId , CarrierTrackingNumber
FROM Sales.SalesOrderDetail;
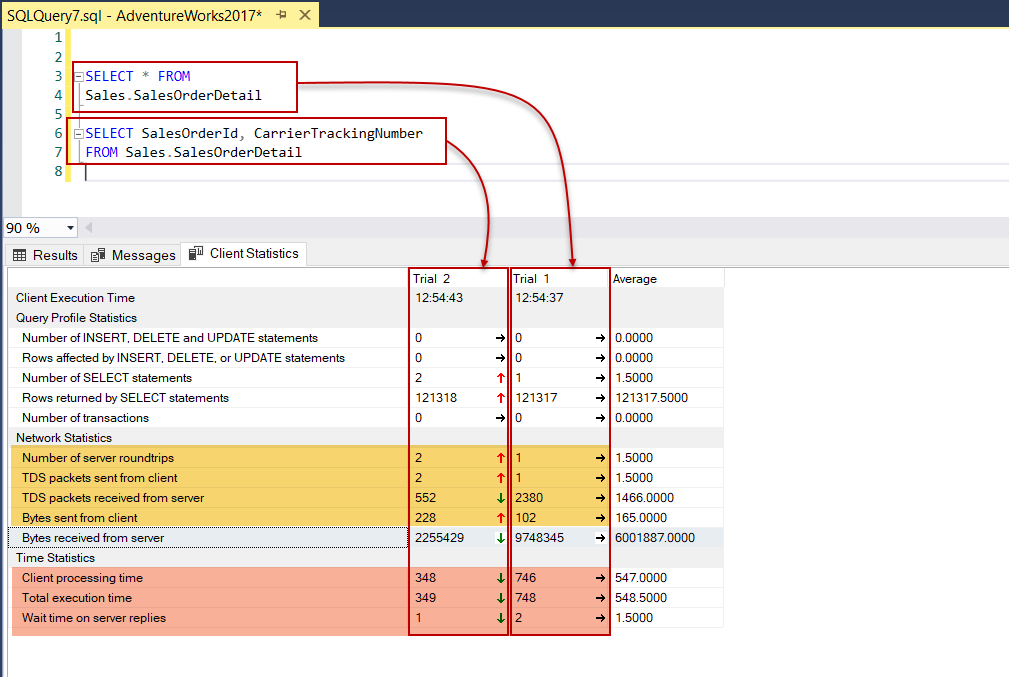
As we can see obviously, there is a dramatic difference between the received network measurements of these two select statements in the Network Statistics section. At the same time, the Time Statistics measurement comparison result does not change for the “SELECT *” statement. It shows poor performance than the “SELECT column_name1, column_name2, column_nameN” statement. In light of this information, we can come to this outcome “As possible as we should not use the asterisk signs in the SELECT statements.
显而易见,在“ 网络统计”部分中,这两个选择语句的接收到的网络度量之间存在巨大差异。 同时,“ SELECT * ”语句的“ 时间统计”测量比较结果不会更改。 它显示的性能比“ SELECT column_name1,column_name2,column_nameN”语句差。 根据这些信息,我们可以得出以下结果:“尽可能避免在SELECT语句中使用星号。
不要在WHERE子句中使用标量值函数 (Don’t use scalar-valued functions in the WHERE clause)
A scalar-valued function takes some parameters and returns a single value after a certain calculation. The main reason for why the scalar-valued functions affect performance negatively, the indexes cannot be used on this usage approach. When we analyze the following query execution plan, we will see an index scan operator because of the SUBSTRING function usage in the WHERE clause.
标量值函数接受一些参数,并在进行特定计算后返回单个值。 标量值函数对性能产生负面影响的主要原因是,不能在这种使用方法上使用索引。 当我们分析以下查询执行计划时,我们将看到索引扫描 运算符,因为WHERE子句中使用了SUBSTRING函数。
SELECT ProductNumber FROM Production.Product
WHERE SUBSTRING(ProductNumber,1,2) = 'AR'
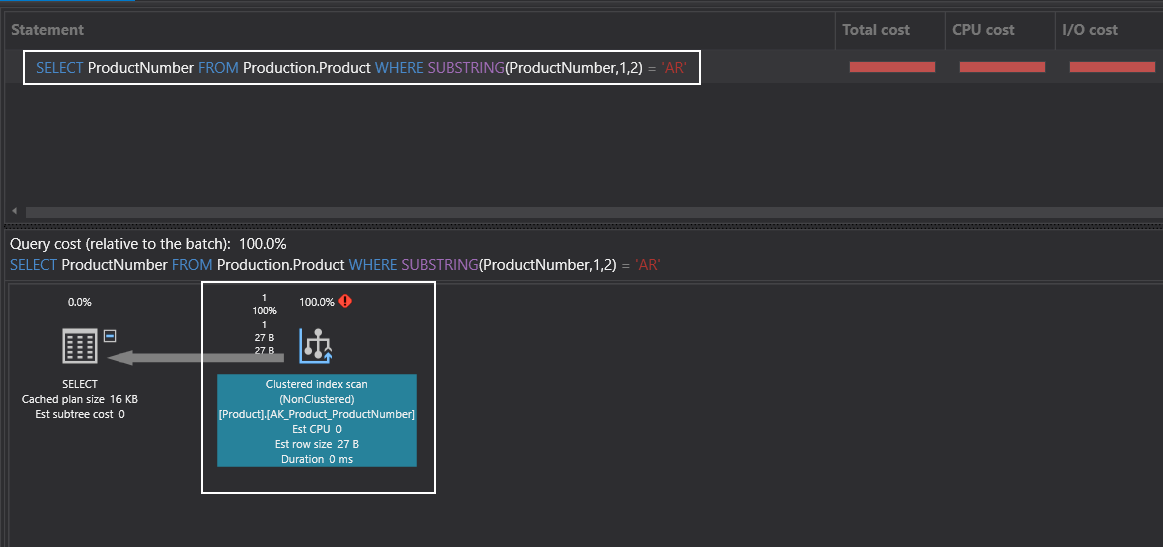
The index scan operator reads all index pages in order to find the proper records. However, this operator consumes more I/O and takes more time. As possible, we should avoid the index scan operator when we see it in our execution plans.
索引扫描操作员读取所有索引页以找到正确的记录。 但是,该操作员消耗更多的I / O并花费更多的时间。 当在执行计划中看到索引扫描运算符时,应尽可能避免使用它。
On the other hand, particularly for this query, we can improve their performance with a little touch. Now we will change this query as below so the query optimizer will decide to use another operator.
另一方面,特别是对于此查询,我们可以稍加改进即可提高其性能。 现在,我们将按以下方式更改此查询,以便查询优化器决定使用其他运算符。
SELECT ProductNumber FROM Production.Product
WHERE ProductNumber LIKE 'AR%'
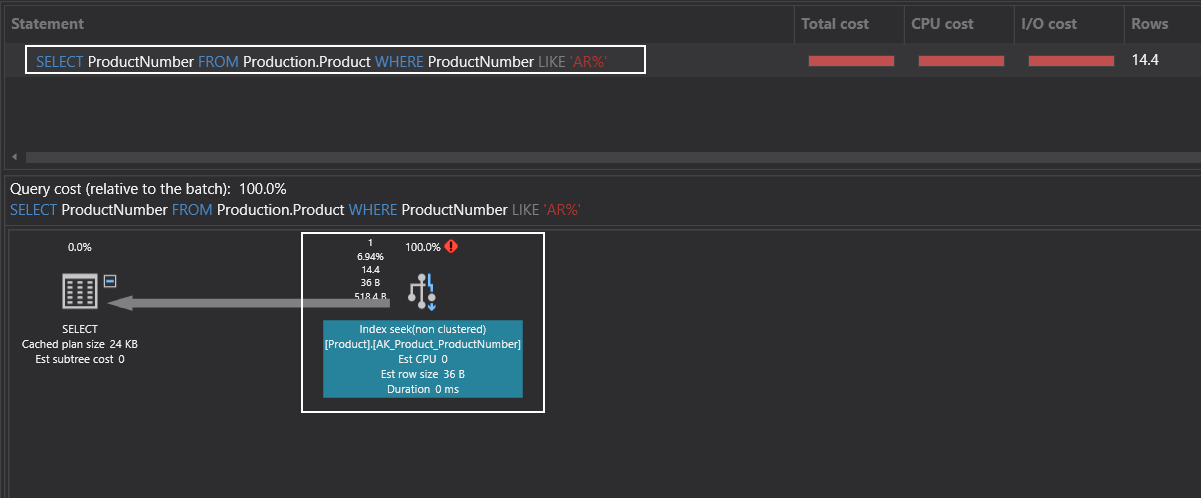
The index seeks operator only reads the qualified rows because this operator effectively uses the indexes to retrieve the selective rows. At the same time, it shows great performance when against the index scan operator.
索引查找运算符仅读取合格的行,因为该运算符有效地使用索引来检索选择的行。 同时,与索引扫描运算符相比,它显示出出色的性能。
Tip: Scalar-valued functions are executed for each row of the resultset, so we should consider the rows number of the resultset when we use them. They can damage the query performance when trying to use for the queries which will return a huge number of rows. However, Microsoft has broken this traditional chain with SQL Server 2019 and made some performance improvements in the query optimizer for the scalar-valued functions, and it has been generating more accurate execution plans if any query contains the scalar-valued function. You can see the following article for more details about this improvement:
提示:标量值函数是针对结果集的每一行执行的,因此使用它们时,应考虑结果集的行数。 当试图用于查询时,它们会损坏查询性能,这将返回大量的行。 但是,Microsoft打破了SQL Server 2019的传统链条,并在针对标量值函数的查询优化器中进行了一些性能改进,并且如果任何查询包含标量值函数,它都会生成更准确的执行计划。 您可以查看以下文章,以获取有关此改进的更多详细信息:
Improvements of Scalar User-defined function performance in SQL Server 2019
SQL Server 2019中标量用户定义函数性能的改进
使用覆盖索引来提高查询性能 (Use the covering indexes to improve the query performance)
Covering indexes contains all referenced columns of the query, so they improve the selectivity of the index, and if any query uses this index, it accesses the data more efficiently. However, before creating any covered index, we need to figure out cost-benefit analyses because any new index directly affects the performance of the insert statement. Now we will analyze the execution plan of the following query.
覆盖索引包含查询的所有引用列,因此它们提高了索引的选择性,并且如果有任何查询使用此索引,它将更有效地访问数据。 但是,在创建任何覆盖索引之前,我们需要弄清楚成本效益分析,因为任何新索引都会直接影响insert语句的性能。 现在,我们将分析以下查询的执行计划。
SELECT CarrierTrackingNumber,UnitPrice FROM Sales.SalesOrderDetail
WHERE UnitPrice BETWEEN 10 AND 10000
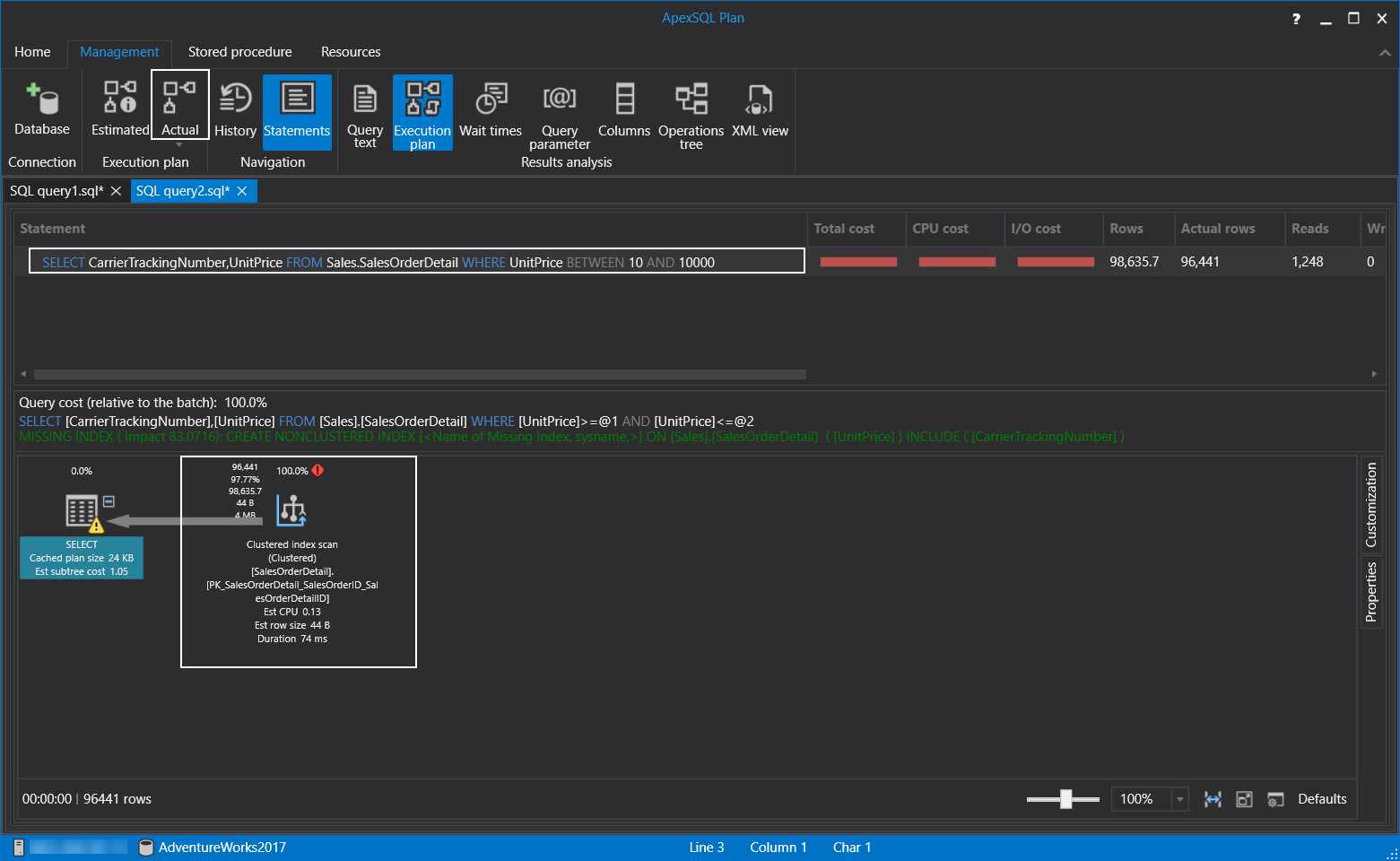
As we learned, the index scan operation is not shown good performance during the execution of the query. To overcome this problem, we will create the following index. The main characteristic of this index is that it covers all the columns of the query through the index key or included columns.
据我们了解,在执行查询期间,索引扫描操作未显示出良好的性能。 为了克服这个问题,我们将创建以下索引。 该索引的主要特征是它通过索引键或包含的列覆盖了查询的所有列。
CREATE NONCLUSTERED INDEX IX_00Cover
ON [Sales].[SalesOrderDetail] ([UnitPrice])
INCLUDE ([CarrierTrackingNumber])
After the creation of the index, we will re-analyze the actual execution plan of the same query.
创建索引后,我们将重新分析同一查询的实际执行计划。
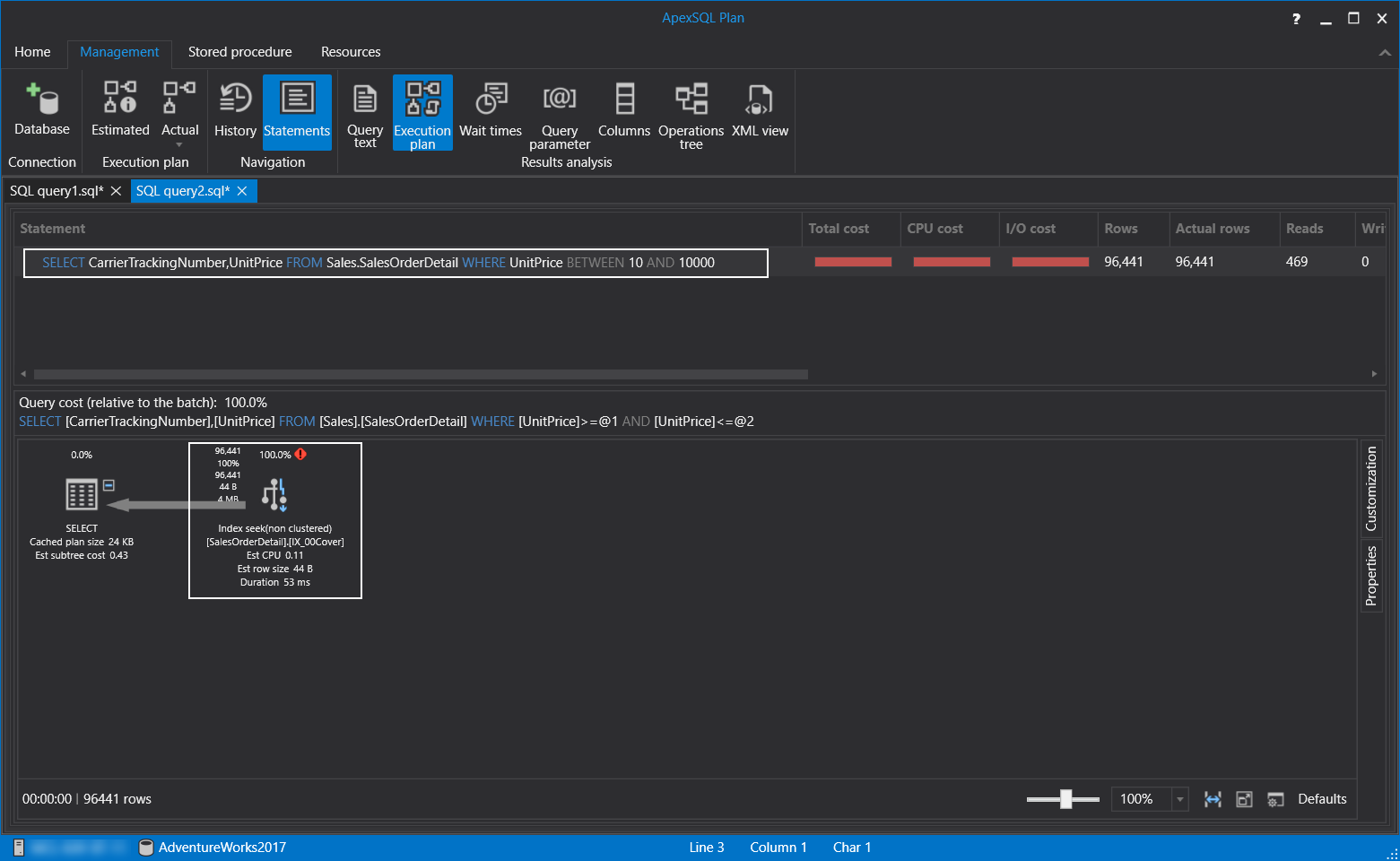
The execution plan of the query has started to use an index seek operator, and this operator shows better performance than the index scan operator.
查询的执行计划已开始使用索引查找运算符,并且该运算符显示出比索引扫描运算符更好的性能。
使用UNION ALL运算符,而不是UNION运算符 (Use the UNION ALL operator instead of the UNION operator)
UNION ALL and UNION operators are used to combine two or more than two result sets of the select statements. However, the main difference between these two operators is the UNION operator eliminates the duplicate rows from the result set. In terms of the query tuning, UNION ALL operator perform better performance than UNION operator. As a result, if we don’t consider the duplicate rows in the result set, we should use UNION ALL operator in our select statements. When we compare execution plans of the following queries, we will see a noticeable difference between these two execution plans. At first, we will compare the execution plans.
UNION ALL和UNION运算符用于组合select语句的两个或两个以上结果集。 但是,这两个运算符之间的主要区别是UNION运算符从结果集中消除了重复的行。 在查询调优方面, UNION ALL运算符的性能优于UNION运算符。 因此,如果我们不考虑结果集中的重复行,则应在select语句中使用UNION ALL运算符。 当我们比较以下查询的执行计划时,我们将看到这两个执行计划之间的明显差异。 首先,我们将比较执行计划。
---Query-1---
SELECT Vendor.AccountNumber, Vendor.Name
FROM Purchasing.Vendor AS Vendor
UNION ALL
SELECT Vendor.AccountNumber, Vendor.Name
FROM Purchasing.Vendor AS Vendor---Query-2---
SELECT Vendor.AccountNumber, Vendor.Name
FROM Purchasing.Vendor AS Vendor
UNION
SELECT Vendor.AccountNumber, Vendor.Name
FROM Purchasing.Vendor AS Vendor

When we analyze the comparison of the execution plans, we can see that the Sort operator adds extra cost to the select statement, which is using the UNION operator. As a final word about these two operators, if we don’t consider the duplicate records, we should use UNION ALL operator to combine the result sets.
在分析执行计划的比较时,我们可以看到Sort运算符为select语句增加了额外的成本, 使用UNION运算符。 最后,关于这两个运算符,如果我们不考虑重复的记录,则应使用UNION ALL运算符组合结果集。
使用实际执行计划而不是估计执行计划 (Use Actual Execution Plans instead of Estimated Execution Plans)
The execution plan offers us to the visual presentation of the query processing steps. When we analyze any execution plan, we can clearly understand the road map of the query, and it is also a significant beginning point to tune a query. The estimated and actual execution plans are the two types of execution plans that can be used by us to analyze the queries. During the creation of the estimated execution plan, the query does not execute but generated by the query optimizer. Despite that, it does not contain any runtime metrics and warnings.
执行计划为我们提供了查询处理步骤的可视化表示。 在分析任何执行计划时,我们可以清楚地了解查询的路线图,这也是调整查询的重要起点。 估计执行计划和实际执行计划是我们可以用来分析查询的两种执行计划。 在创建估计的执行计划期间,查询不会执行,而是由查询优化器生成。 尽管如此,它不包含任何运行时指标和警告。
On the other hand, the actual execution plan contains more reliable information and measurements about the query. Actual Execution plans provide an advantage to tune the query performance.
另一方面,实际执行计划包含有关查询的更可靠的信息和度量。 实际执行计划为调整查询性能提供了一个优势。
Another approach can be combo usage for the execution plans for the queries which have longer execution times. At first, we can check the estimated execution plan and then re-analyze the actual execution plan.
另一种方法可以是对执行时间较长的查询的执行计划进行组合使用。 首先,我们可以检查估计的执行计划,然后重新分析实际的执行计划。
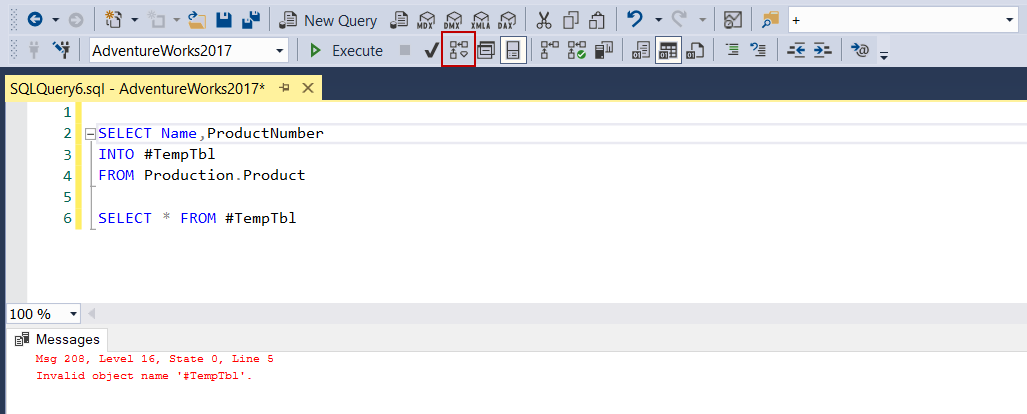
Tip: If a query includes any temp table, the estimated execution plan can not be generated. It will be given an error when we try to generate it. The following query will return an error when trying to generate an estimated execution plan.
提示:如果查询中包含任何临时表,则无法生成估计的执行计划。 当我们尝试生成它时,将给出一个错误。 尝试生成估计的执行计划时,以下查询将返回错误。
SELECT Name,ProductNumber
INTO #TempTbl
FROM Production.ProductSELECT * FROM #TempTbl
结论 (Conclusion)
In this article, we learned essential techniques to tune SQL queries. Performance tuning is a very complicated and struggling task to accomplish, but we can learn this concept from easy to difficult, and this article can be a good beginning point to start. Also, the following topics are vital to improving our query tuning skills; therefore, you can look at the following articles for the next steps of your learnings.
在本文中,我们学习了调优SQL查询的基本技术。 性能调优是一项非常复杂且艰巨的任务,但是我们可以从容易到艰难地学习这一概念,并且本文可以作为一个很好的起点。 另外,以下主题对于提高我们的查询调优技能至关重要。 因此,您可以查看以下文章,以了解接下来的学习步骤。
- Using the SQL Execution Plan for Query Performance Tuning 使用SQL执行计划进行查询性能调整
- SQL Server Query Execution Plans for beginners – Types and Options 面向初学者SQL Server查询执行计划–类型和选项
翻译自: https://www.sqlshack.com/getting-started-with-sql-server-query-tuning/
sql server 入门
sql server 入门_SQL Server查询调整入门相关推荐
- sql server 内存_SQL Server内存性能指标–第5部分–了解惰性写入,空闲列表停顿/秒和待批内存授予
sql server 内存 SQL Server performance metrics series with the SQL Server memory metrics that should b ...
- sql server运算符_SQL Server执行计划中SELECT运算符的主要概念
sql server运算符 One of the main responsibilities of a database administrator is query tuning and troub ...
- php执行sql内存溢出_SQL Server 2017:SQL排序,溢出,内存和自适应内存授予反馈
php执行sql内存溢出 This article explores SQL Sort, Spill, Memory and Adaptive Memory Grant Feedback mechan ...
- sql server分页_SQL Server中的分页
sql server分页 Pagination is a process that is used to divide a large data into smaller discrete pages ...
- sql数据透视_SQL Server中的数据科学:取消数据透视
sql数据透视 In this article, in the series, we'll discuss understanding and preparing data by using SQL ...
- sql server 别名_SQL Server别名概述
sql server 别名 This article gives an overview of SQL Server Alias and its usage for connecting with S ...
- 2008 r2 server sql 中文版补丁_SQL Server 2008 SP4 补丁
SQL Server 2008 SP4 补丁对于客户而言,Microsoft SQL Server 2008 Service Pack 4 中的几个关键改进如下所示: 改进了从 SQL Server ...
- sql server 面试_SQL Server审核面试问题
sql server 面试 In this article, we will discuss a number of common and important SQL Server Audit que ...
- sql server 入门_SQL Server中的数据挖掘入门
sql server 入门 介绍 (Introduction) In past chats, we have had a look at a myriad of different Business ...
最新文章
- VS 常见快捷键(转)
- Mysql与sqlite注意
- 牛客练习赛40 A.小D的剧场
- 第一章 GuassDB数据库介绍
- c语言报告程序分析报告,2012C语言程序分析报告.doc
- Bert/Transformer汇总
- getbook netty实战_Netty 入门教程
- GUI编程tkinter模块常用参数(python3)
- matlab实现线性规划
- r720支持多少频率的内存吗_DDR4 2400到DDR4 3200,最大内存频率买多少?为什么买了高频 速度却上不去...
- 【个人笔记 - 目录】OpenCV4 C++ 快速入门 30讲
- 网络工程师应该掌握的知识要点 (共45个)
- 算法的时间复杂度与空间复杂度
- 如何在生产环境排查 Rust 内存占用过高问题
- EPS格式转黑白照片(高清晰版本)
- 相机视场角和焦距_镜头焦距和视场角介绍!
- 5G无线技术基础自学系列 | 时域资源
- Cisco Packet Tracer 8.0 发布,百度网盘下载
- CAD如何绘制多边形的外切圆?
- 微信小程序view控件自动换行