Solr与MongoDB集成,实时增量索引[转]
http://www.123905.com/
一. 概述
大量的数据存储在MongoDB上,需要快速搜索出目标内容,于是搭建Solr服务。
另外一点,用Solr索引数据后,可以把数据用在不同的项目当中,直接向Solr服务发送请求,返回xml、json等形式的内容,使得对数据的使用更灵活。
对于MongoDB与Solr的描述不在这里阐释了,本文旨在给大家提供整个Solr与MongoDB接合的方法,实现实时的增量索引。
MongoDB的官网:http://www.mongodb.org/
Solr项目的主页:http://lucene.apache.org/solr/
二. 寻找解决方案
既然有了目标是讲Solr跟MongoDB接到一起,那么就开始想想解决的方案。
网上搜了一些资料之后,汇总了下面三个方案:
1. 使用Solr的DataImport功能(Data Import)
我们先来看看Solr Wiki上对于DataImport功能的描述http://wiki.apache.org/solr/DataImportHandler
Most applications store data in relational databases or XML files and searching over such data is a common use-case.The DataImportHandler is a Solr contrib that provides a configuration driven way to import this data into Solr in both “full builds” and using incremental delta imports.
对于存储在关系型数据库及XML上的数据,Solr提供了DataImportHandler去实现全量和增量索引。
啥?人家没说支持NoSQL啊,不信,我看清楚一点。
Wiki中的内容只给出了Usage with RDBMS 和 Usage with XML/HTTP Datasource,貌似Solr目前是不支持对于NoSQL的DataImport的。
有兴趣的朋友可以尝试给Solr添加一个Mongo的DataImportHandler,可能还要写底层的Mongo驱动,工程量可能很大。
关键是这个方案不可控,成本可能会很大,因此我就不采取这种方式了。
在这里给大家分享一篇文章,Solr与MySQL集成指南
确实DataImport这个功能还是比较强大的,而且对MySQL也支持得很好,本人尝试一下将Solr跟MySQL集成起来,配置过程也很简单。
不过MySQL不是本文的重点,跑题了,因此只是尝试了一下,没有深入。
2. 使用脚本语言读取MongoDB中的数据(Script Update)
说白了就是读取整个Collection中的数据,遍历。
这种方案是最直观的,但不优雅,复用性、可维护性低,
最严重的问题在于性能,当数量级在百万以下,那还是可以接受的,一旦数据继续增长,那性能问题就凸显出来了。
然而要是你还想用这种方案,那这里还有一个需要考虑的问题,你是打算每次遍历的时候对Solr进行全量还是增量索引呢?
全量的话就直接overwrite,事情也好办;增量的话,Mongo中删除了的数据你咋整呢?
总而言之,不推荐这种方案,它的复杂度问题很明显,无论是时间上还是空间上。
3. 使用MongoDB的oplog功能(Oplog Update)
MongoDB支持集群,集群中的实例进行通信,很自然地想到它们会记录log,在MongoDB中称之为oplog(operation log),类似与MySQL的binlog。
我们可以看看MongoDB官网上对oplog的描述 http://docs.mongodb.org/manual/reference/program/mongooplog/
如果现在你还想用上面方案2的话,那oplog的存在必然是对你的工作带来极大便利的。
其一,oplog是实时记录的,配合tailable cursor,可以实现实时的更新Solr索引,见http://derickrethans.nl/mongodb-and-solr.html
其二,实现优雅,增量的新增删除的判断时间复杂度变为O(1)
看到这里,你想用oplog来实现Solr与MongoDB的集成,那需要理清下面几个问题:
(1)mongooplog如何开启,怎么配置才适合
(2)Mongo Tailable Cursor是怎么一回事
(3)使用什么语言,选择合适的Solr Client
(4)服务器宕机恢复后的处理
三. 最终方案,mongo-connector
当我性高彩烈地动手实现方案3的时候,我看到了这个http://blog.mongodb.org/post/29127828146/introducing-mongo-connector
竟然找到了一个mongo-solr的connector,当时那个心情真叫欣喜若狂啊。
它完全就是方案3的实现啊!提到的问题它都解决了,而且使用Python正好适合这个项目,一切来得太突然。
Git地址:https://github.com/10gen-labs/mongo-connector
但是配置的过程都搞了我很久,后文将整个过程记录下来
四. 项目环境及工具版本
在本地测试,服务器:Windows7 32-bit
MongoDB:mongodb-win32-i386-2.4.5
Tomcat 6
Python:2.7.4
Solr:4.5.1
mongo-connector:没有提供版本号
Python pysolr模块
Python pymongo模块
Python lxml模块:lxml-3.2.3.win32-py2.7
可能还需要一些模块,但由于我在之前已经安装了,没有列举出来。如果运行的过程中报module not found,就去安装吧~
五. Solr端准备
这里默认你已经部署Solr成功,详细的部署过程自行Google。
这里主要是讲述与本次测试相关的配置。
使用的是solr example中的multicore例子,以其中的core0为例子
schema.xml文件如下:修改_id与Mongo对应,只留下一个name字段,为String类型
![]()
其它的配置不需要修改
把它放到Tomcat中运行吧,检查是否已经配置成功
六. MongoDB端准备
看到mongo-connector项目中的说明,
Since the connector does real time syncing, it is necessary to have MongoDB running, although the connector will work with both sharded and non sharded configurations. It requires a replica set setup.
就算我们开启了oplog也不行,还需要在Mongo中启动一个replica set
1. 配置replica set
(1)
我的MONGO_HOME为 D:\mongodb
目录树如下:
-rs (d)
|—-db (d) mongo数据文件文件存放的目录
|—-rs1 (d) rs1实例数据文件存放的目录
|—-rs2 (d) rs2实例数据文件存放的目录
|—-log (d) log文件存放的目录
|—-rs1.log (f) rs1实例的log文件
|—-rs2.log (f) rs2实例的log文件
|—-mongod-rs1.bat rs1实例的启动脚本
|—-mongod-rs2.bat rs2实例的启动脚本
mongod-rs1.bat内容如下:
D:\mongodb\bin\mongod –port 27001 –oplogSize 100 –dbpath db\rs1 –logpath log\rs1.log –replSet rs/127.0.0.1:27002 –journal
pause
mongod-rs2.bat内容如下:
D:\mongodb\bin\mongod –port 27002 –oplogSize 100 –dbpath db\rs2 –logpath log\rs2.log –replSet rs/127.0.0.1:27001 –journal
pause
(2)执行两个脚本,启动两个mongod实例
(3)但这时它们还没组成一个replica set,还需要进行配置,开启mongo,连上localhost:27001,也就是实例rs1
![]()
![]()
![]()
![]()
至此,配置完成。
七. mongo-connector准备
如果是在mongo example中的multicore默认的配置上修改的话,访问http://localhost:8080/solr/core0/admin/luke?show=Schema&wt=json
应该是能看到JSON形式的core0的schema
打开mongo_connector/doc_managers/solr_doc_manager.py
进行如下修改:1.从util引入verify_url;2. ADMIN_URL修改为获取Solr核core0的JSON形式schema的URL的后半部分,因为要根据schema中的fields进行索引
![]()
在Solr多核的情况下启动mongo-connector,会报出Solr URL访问错误,它期望你传入http://localhost:8080/solr,
但http://localhost:8080/solr/core0才是实际起作用的,因此我们需要传入这个作为BASE_URL
解决办法如下:屏蔽掉url检查就行了
![]()
接下来就是启动mongo-connector了,启动命令如下:
![]()
-m Mongod实例的访问路径
-t Solr的BASE_URL
-o 记录oplog处理时间戳的文件
-n mongo命名空间,是监听哪个database哪个collection的设置,以逗号分隔多个命名空间,这里是监听test库中的test集合
-d 就是处理doc的py文件
启动结果如下:说明你的配置已经成功了
![]()
八. 测试增量索引
先看看Solr中core0的状态:现在是没有记录的,Num Docs为0
![]()
往MongoDB中插入一条数据:需要包含name字段,还记得我们上面的schema.xml吗?
![]()
查看mongo-connector的输出:update了一条记录
![]()
看看Solr现在的状态:我们看到了刚才插入的
![]()
尝试删除掉刚才那条记录,connector输出如下:多了一条update的记录,这次是<delete>
![]()
再看看Solr的状态:刚才那条记录没了,删除成功!
![]()
九. 一些说明
mongo-connector会在oplog_progress.txt中记录时间戳,可以在服务器宕机恢复后索引Mongo oplog新增的数据,记录如下:
["Collection(Database(MongoClient([u'127.0.0.1:27001', u'127.0.0.1:27002']), u’local’), u’oplog.rs’)”, 5941530871067574273]
mongo-connector的代码并不复杂,想想上面上面方案3怎么实现,那它就是怎么做的了。
有些地方还是要根据我们项目进行一些修改的。
来源:http://www.cnblogs.com/sysuys/p/3403670.html
发表在 MongoDB、云计算
优化ubuntu系统,加快开机速度和运行速度
前提:在你安装好各种软件后才开始优化
这样会减少错误的发生
以下是经过本人测试过的方案,不影响系统和电脑任何性能
可以针对ubuntu9.10系统系(包括最新的雨林木风)
首先是开机速度
1.删除掉动画模块速度会增加不少:
Java代码
- sudo apt-get remove ubuntu-xsplash-artwork libusplash0
2.设置开机不扫描硬盘,此设置可以减少一半的开机时间:
Java代码
- sudo gedit /etc/fstab
在打开的文本编辑器里
寻找所有的
UUID=
开头的语句
把结尾部分的数字全部改成 0 0
呵呵,开机速度超级快了
接下来是对臃肿的系统开刀:
系统减肥:
1.删除游戏:
Java代码
- sudo apt-get remove gnome-games-common
所有系统自带的游戏全部没了
2.删除蓝牙装备:
Java代码
- sudo apt-get remove libbluetooth3
3.删除IDE接口硬盘支持(切记你是sata硬盘才可以删除否则嘿嘿别怪我没说):
Java代码
- sudo apt-get remove hdparm
4.很多人用永中office,那么删除OO吧
Java代码
- sudo apt-get remove openoffice.org-draw openoffice.org-math openoffice.org-impress openoffice.org-calc openoffice.org-writer
5.一些基本用不到的组件,除非你知道他做什么用的。删除吧
Java代码
- sudo apt-get remove cron anacron rsync
6.删除掉打印机支持:
Java代码
- sudo apt-get remove cups hplip system-config-printer-common
7.删除掉自带brasero刻录软件
Java代码
- sudo apt-get remove libbrasero-media0
8.删除系统自带的E-mail
Java代码
- sudo apt-get remove empathy-doc evolution-common
9.删除扫描仪:
Java代码
- sudo apt-get remove xsane-common
10.此命令注意看说明:删除掉pulseaudio音量系统可以解决放电影和flash突然卡声音突然没声音突然杂音的问题,但是不好的地方是连带系统的音量控制系统一并删除。我的做法是用awn仿苹果工具条里的音量控制来代替。请各位看官慎重考虑
Java代码
- sudo apt-get remove pulseaudio
删除系统孤立的组件
Java代码
- dpkg -l |grep ^rc|awk ’{print $2}’ |tr ["\n"] [" "]|sudo xargs dpkg -P -
发表在 Linux系统
solr schema.xml 解析
<?xml version=”1.0″ encoding=”UTF-8″ ?>
<!–
前缀以solr.类限定名开头的引用于org.apache.solr.schema包
–>
<!– // –>
<!– 索引字段类型的声明 –>
<!– // –>
<types>
<!–
org.apache.solr.schema.StrField
字段类型不分词,但是会索引和保存整个句子
或词把整个句子或词作为关键词
–>
<!–
org.apache.solr.schema.boolean
用于存放boolean数据类型
–>
<!–
org.apache.solr.schema.BinaryField
二进制数据类型,数据应该发送检索在基于64位编码的字符
–>
<!–
为提供快速的范围查询,考虑使用默认的数字字段类型:
org.apache.solr.schema.TrieIntField
org.apache.solr.schema.TrieFloatField
org.apache.solr.schema.TrieLongField
org.apache.solr.schema.TrieDoubleField
–>
<!–
为了快速的进行范围查询,考虑使用:
org.apache.solr.schema.TrieDateField
–>
<!–
这些只用于为了兼容使用先前存在的索引而设置
org.apache.solr.schema.IntField
org.apache.solr.schema.LongField
org.apache.solr.schema.FloatField
org.apache.solr.schema.DoubleField
org.apache.solr.schema.DateField
org.apache.solr.schema.SortableIntField
org.apache.solr.schema.SortableLongField
org.apache.solr.schema.SortableFloatField
org.apache.solr.schema.SortableDoubleField
–>
<!–
org.apache.solr.schema.RandomSortField
这个数据类型的字段将不会被保存和查询任何数据只是做为内部排序的一种方式
–>
<!–
org.apache.solr.schema.TextField
允许定制指定的分析器,例如指定记号过滤器列表
你也可以指定一个存在的分析器类,
通过默认的构造器的class属性指定 分析器元素
<fieldType name=”text_greek”>
<analyzer/>
<filter ignoreCase=”true” words=”stopwords.txt”
enablePositionIncrements=”true” />
</fieldType>
–>
<!– // –>
<!–
有效的字段属性:
name:强制的给字段指定一个名字
type: 从之前部分定义的类型中选择一个字段类型
indexed:字段是否应该被索引被索引后可以查询和排序
stored: true表示这个字段的值需要被保存和检索
multiValued:在一个文档中一个字段存在多个值要被索引
//被解析出来的时候就像
//<country>
// <arr>
// <str>中国</str>
// <str>美国</str>
// <str>德国</str>
// </arr>
// </country>
omitNorms: false
termVectors: [false]
termOffsets:
default:如果该字段没有被赋值指定一个默认的赋值
–>
<!–
动态字段定义通过*来定义
<dynamicField name=”*_ti” type=”tint” indexed=”true” stored=”true”/>
–>
<!–
<span style=”white-space:pre”> </span> 一个文本字段域使用关键词定界符过滤器能够分割和匹配多种不同形式的关键词
因此wifi或者wi fi的查询可能匹配包含wi-fi的文档
同义词和停用此通过外部的文件定制
自动生成短语查询属性默认为true导致查询字符窜会被分割成短语形式的查询
例如:
WordDelimiterFilter splitting text:pdp-11 will cause the parser
<span style=”white-space:pre”> </span>关键词分界符过滤器分割文本:pdp-11将会导致分析器
<span style=”white-space:pre”> </span>生成文本pdp 11
<span style=”white-space:pre”> </span>而不是(text:pdp or text:11)
需要注意的是:自动生成短语查询趋向于不是以空格作为分界符的语言
–>
<!–<fieldType name=”text” positionIncrementGap=”100″ autoGeneratePhraseQueries=”true”>
<analyzer type=”index”> //用于索引该字段的时候用到的分词器
<tokenizer/> –>
<!–
在查询的时候我们只会使用同义词过滤器
<filter synonyms=”index_synonyms.txt” ignoreCase=”true” expand=”false”/>
–>
<!– <filter
ignoreCase=”true”
words=”stopwords.txt”
enablePositionIncrements=”true”
/>//停用词过滤器用于索引文档中的停用词去掉
<filter generateWordParts=”1″ generateNumberParts=”1″ catenateWords=”1″
catenateNumbers=”1″ catenateAll=”0″ splitOnCaseChange=”1″/>
<filter/>
<filter
protected=”protwords.txt”/>
<filter/>
</analyzer>
//查询的时候使用的分词器
<analyzer type=”query”>
<tokenizer/>
<filter synonyms=”synonyms.txt” ignoreCase=”true” expand=”true”/>
<filter
ignoreCase=”true”
words=”stopwords.txt”
enablePositionIncrements=”true”
/>
<filter generateWordParts=”1″ generateNumberParts=”1″ catenateWords=”0″ catenateNumbers=”0″ catenateAll=”0″ splitOnCaseChange=”1″/>
<filter/>
<filter protected=”protwords.txt”/>
<filter/>
</analyzer>
</fieldType>–>
<!–
这个字段决定和增强文档的唯一性,除非这个字段使用required=false,
这个字段必须要使用
required=true
<uniqueKey>id</uniqueKey>
–>
<!–
defaultOperator=”AND|OR”
为查询解析器指定默认的查询单元关联符号
–>
<solrQueryParser defaultOperator=”OR” />
<!–
复制字段命令在文档被添加到索引的时,复制一个字段到另外一个字段。
索引同一个字段的不同方式,添加多个字段到同一个字段为了快速简单的查询
<copyField source=”cat” dest=”text”/>
在添加文档的时候将cat这个字段的文本和text这个目标字段的文本索引到一起
<copyField source=”*_t” dest=”text” maxChars=”3000″/>
–>
<!–
指定相似度评分机制实现类 <similarity
class=”org.apache.lucene.search.DefaultSimilarity”/>
–>
</types>
发表在 杂记
centos修改主机名
第一步:
临时修改主机名
hostname myhost
第二步:
永久修改主机名
方法1:
修改/etc/sysconfig/network中的hostname
vi /etc/sysconfig/network
HOSTNAME=myhost #修改localhost.localdomain为myhost
修改network的HOSTNAME项。点前面是主机名,点后面是域名。没有点就是主机名。
这个是永久修改,重启后生效。目前不知道怎么立即生效。
想立即生效,可以同时采用第一种方法。
方法2:
修改/etc/hosts文件
vi /etc/hosts
127.0.0.1 myhost localhost #修改localhost.localdomain为myhost
shutdown -r now #最后,重启服务器即可。
一些网络文章中提出修改主机名还需修改Hosts文件,其实hosts文件和主机名修改无关。
hosts文件是配本地主机名/域名解析的。
发表在 Linux、Linux系统
如何取消CentOS 的图形界面直接进入命令行模式
/etc/inittab 中将
id:5:initdefault:
–默认运行等级是5,只要将此处改成 id:3:initdefault:即可
另外在文本模式如果想启动图形界面,可以使用下面的方法:
# startx
发表在 杂记
CentOS配置ssh无密码登录
前提配置:使用root登录修改配置文件:/etc/ssh/sshd_config,将其中三行的注释去掉,如下:

然后重启ssh服务:service sshd restart。最后退出root,以下所有操作都在hadoop用户下进行。
主机信息如下:
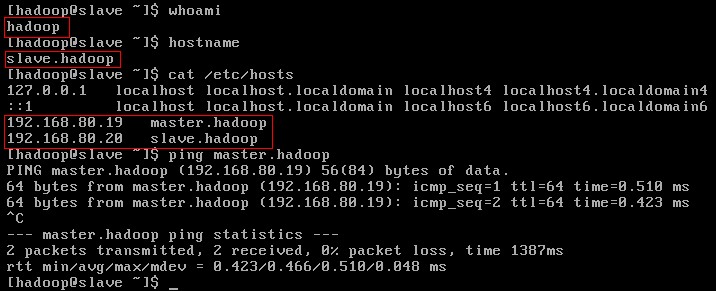
如上图,当前登录用户为hadoop,主机名为slave.hadoop,与master.hadoop主机的网络是通畅的。
当前未配置RSA校验的情况下,用ssh连接主机是需要输入密码的,如下:

如上图,执行ssh master.hadoop后会停留在下一行等待使用者输入master.hadoop主机hadoop用户的登录密码。
为避免此情况发生,进行如下操作以让主机在ssh连接时自动验证后登录。
首先,执行命令 ssh-keygen -t dsa 生成密钥对,如下:

如上图,密钥文件按照默认方式,在主目录/home/hadoop下的隐藏目录.ssh中生成,分别为id_dsa和id_dsa.pub,后者为公钥,如下图:

根据配置文件/etc/ssh/sshd_config中的AuthorizedKeysFile项的取值:.ssh/authorized_keys,公钥需要导入到该文件中才能实现校验,如下:

至此离成功只有一步之遥了。CentOS默认新生成的文件权限为:-rw-rw-r–,即自己和群组用户都可以重写该文件,这被认为是不够安全的。 如上 图,由于此前我的主机上并未存在authorized_keys文件,现在由于重定向输出新建了该文件,因此该文件的默认权限为-rw-rw-r–仍旧 不够安全。需把群组中的w权限去掉。可使用命令:chmod 644 authorized_keys。网上的资料中,都是直接chmod 600 authorized_keys,即群组和其他用户连读取文件内容的权限都没有,当然这样是最安全的,但是系统只要求到除了自己之外其他所有用户均不能改动文件就可以了。

如上图,slave.hadoop已经能够使用ssh无密码登录本机了。那么如何让它无密码登录到Master.hadoop主机中呢?当然是分发公钥文件id_dsa.pub的内容到master.hadoop主机上了。如下图:

如上图,执行命令 cat ~/.ssh/id_dsa.pub | ssh hadoop@master.hadoop ‘cat – >> ~/.ssh/authorized_keys’,并输入master.hadoop主机的hadoop用户的登录密码,即可将公钥发送到master.hadoop并追加到其authorized_keys文件中。

如上图,已经可以在slave.hadoop主机使用ssh无密码登录主机master.hadoop了。
发表在 系统架构
ubuntu 12.04精简
sudo apt-get -y –auto-remove purge unity-2d*
sudo apt-get -y purge empathy
sudo apt-get -y purge nautilus-sendto-empathy
sudo apt-get -y purge empathy-common #即时通讯
sudo apt-get -y purge thunderbird* #邮件
sudo apt-get -y purge gwibber* #微博
sudo apt-get autoremove gcalctool #计算器
sudo apt-get -y purge gnome-power-manager #电源统计
sudo apt-get -y purge ubuntuone* #Ubuntu One
sudo apt-get -y purge deja-dup #备份
sudo apt-get -y purge bluez* #卸载蓝牙
sudo apt-get -y purge simple-scan #扫描
sudo apt-get -y purge hplip* #打印
sudo apt-get -y purge printer-driver* #打印驱动
sudo apt-get -y purge rhythmbox* #音乐播放
sudo apt-get -y purge gedit* #文本编辑
sudo apt-get -y purge libreoffice* #办公套件
sudo apt-get -y purge gnome-orca #屏幕阅读
sudo apt-get -y purge onboard #屏幕键盘
sudo apt-get -y purge mahjongg #对对碰
sudo apt-get -y purge aisleriot #纸牌王
sudo apt-get -y purge gnome-sudoku #数独
sudo apt-get -y purge gnomine #扫雷
sudo apt-get -y purge wodim #命令刻碟
发表在 杂记
Ubuntu 系统优化
1:并行启动程序:
这将会使启动程序并行,加速启动过程,代码: sudo nano /etc/init.d/rc
(注意:这里用 gedit 打开可能是乱码,换个编辑器,如 nano,vi 什么的就 ok 了)找到并修改该行:
CONCURRENCY=none
为:
CONCURRENCY=shell
2:交换分区使用:
Ubuntu 默认的 vm.swappiness 值是 60,这一默认值已经很合适了。但你可以改小一些降低swap 的加载,系统性能会有一点点的提升
输入代码:
sysctl -q vm.swappiness
你会看到值是 60, 更改:
代码:
sudo sysctl vm.swappiness=10
这样你就将值由 60 改为 10,这可以大大降低系统对于 swap 的写入,建议内存为512m 或更多的朋友采用此方法。如你你发现你对于 swap 的使用极少,可以将值设为 0。这并不会禁止你对 swap 的使用,而是使你的系统对于 swap 的写入尽可能的少,同时尽可能多的使用你的实际内存。这对于你在切换应用程序时有着巨大的作用,因为这样的话它们是在物理内存而非swap 分区中。
如果你想永久得改变这一值,你需要更改 sysctl.conf 文件:
代码:
sudo gedit /etc/sysctl.conf
添加:
vm.swappiness=10
到末行,需要重启生效。
小贴士:
1G 内存推荐值为 5
2G 内存推荐值为 3
不推荐把值设为 0
3:虚拟分区–使用 tmpfs 缓存你的文件:
通过 tmpfs 可以从你的内存中分出一部分作为虚拟的缓冲硬盘,来加速文件的读写。
1.此方法推荐 1G 及以上内存用户尝试,1G 内存以下用户慎用
2.当出现“/tmp 容量不够”的提示,请加内存或不要使用本优化方法:)
编辑/etc/fstab 文件,加入以下语句:
tmpfs /tmp tmpfs mode=1777 0 0
保存后重启系统,系统就会自动把你一半的物理内存用于/tmp,只要是在/tmp 读写的文件,相当于直接读写内存,从而减少硬盘读写的次数。
这个优化方法对于经常读写硬盘的程序有比较好的优化效果,像电驴,bt 等软件,还
有网页的缓存都可以利用虚拟后/tmp 来减少对硬盘的读写
如果想严格控制物理内存的大小,语句可以改成:
tmpfs /tmp tmpfs size=100m,mode=1777 0 0
这里 size=100m 就是说让系统从物理内存中划出 100mb 作为虚拟的/tmp,但要小心的是用 size 指定的大小数值不要超过物理内存的一半,否则系统可能会反而变慢。
如果不加 size 语句,而/tmp 文件容量已经超过物理内存的一半后,它会继续将swap分区作为虚拟/tmp 直到 swap 满为止。因此要让此优化方法发挥最好的性能,则应该让/tmp的数据容量小于物理内存的一半
注意:当系统重启后 /tmp 里面的文档将会消失,所以在关闭系统前请做好/tmp 里面有用文件的备份工作
4:关闭系统启动时检查分区的功能,加快系统启动速度
在终端输入命令: sudo gedit /etc/fstab,找到以下所有类似的语句:
# /dev/sda6
UUID=5342-DSEF /media/sda6
vfat utf8,umask=007,gid=46 0
把最后那个 1 改为 0,
# /dev/sda6
UUID=5452-DF4E /media/sda6 vfat utf8,umask=007,gid=46 0
保存后,以后启动系统就不会再检查这个分区。
建议根分区保留检查功能,其余分区检查功能可以关闭
发表在 杂记
静态资源管理与模板框架 (二)
本系列文章从一个全新的视角来思考web性能优化与前端工程之间的关系,通过解读百度前端集成解决方案小组(F.I.S)在打造高性能前端架构并统一百度40多条前端产品线的过程中所经历的技术尝试,揭示前端性能优化在前端架构及开发工具设计层面的实现思路。
在上一部分,我们介绍了静态资源版本更新与缓存。今天的部分将会介绍静态资源管理与模板框架的用法。
静态资源管理与模板框架
让我们再来看看前面的优化原则表还剩些什么:
| 优化方向 | 优化手段 |
| 请求数量 | 合并脚本和样式表,拆分初始化负载 |
| 请求带宽 | 移除重复脚本 |
| 缓存利用 | 使Ajax可缓存 |
| 页面结构 | 将样式表放在顶部,将脚本放在底部,尽早刷新文档的输出 |
很不幸,剩下的优化原则都不是使用工具就能很好实现的。或许有人会辩驳:“我用某某工具可以实现脚本和样式表合并”。嗯,必须承认,使用工具进行资源合并并替换引用或许是一个不错的办法,但在大型web应用,这种方式有一些非常严重的缺陷,来看一个很熟悉的例子:
某个web产品页面有A、B、C三个资源
工程师根据“减少HTTP请求”的优化原则合并了资源
产品经理要求C模块按需出现,此时C资源已出现多余的可能
C模块不再需要了,注释掉吧!但C资源通常不敢轻易剔除
不知不觉中,性能优化变成了性能恶化……
事实上,使用工具在线下进行静态资源合并是无法解决资源按需加载的问题的。如果解决不了按需加载,则势必会导致资源的冗余;此外,线下通过工具实现 的资源合并通常会使得资源加载和使用的分离,比如在页面头部或配置文件中写资源引用及合并信息,而用到这些资源的html组件写在了页面其他地方,这种书 写方式在工程上非常容易引起维护不同步的问题,导致使用资源的代码删除了,引用资源的代码却还在的情况。因此,在工业上要实现资源合并至少要满足如下需 求:
- 确实能减少HTTP请求,这是基本要求(合并)
- 在使用资源的地方引用资源(就近依赖),不使用不加载(按需)
- 虽然资源引用不是集中书写的,但资源引用的代码最终还能出现在页面头部(css)或尾部(js)
- 能够避免重复加载资源(去重)
将以上要求综合考虑,不难发现,单纯依靠前端技术或者工具处理是很难达到这些理想要求的。现代大型web应用所展示的页面绝大多数都是使用服务端动 态语言拼接生成的。有的产品使用模板引擎,比如smarty、velocity,有的则干脆直接使用动态语言,比如php、python。无论使用哪种方 式实现,前端工程师开发的html绝大多数最终都不是以静态的html在线上运行的。
接下来我会讲述一种新的模板架构设计,用以实现前面说到那些性能优化原则,同时满足工程开发和维护的需要,这种架构设计的核心思想就是:
基于依赖关系表的静态资源管理系统与模板框架设计
考虑一段这样的页面代码:
根据资源合并需求中的第二项,我们希望资源引用与使用能尽量靠近,这样将来维护起来会更容易一些,因此,理想的源码是:
当然,把这样的页面直接送达给浏览器用户是会有严重的页面闪烁问题的,所以我们实际上仍然希望最终页面输出的结果还是如最开始的截图一样,将css放在头部输出。这就意味着,页面结构需要有一些调整,并且有能力收集资源加载需求,那么我们考虑一下这样的源码:
在页面的头部插入一个html注释“<!–[CSS LINKS PLACEHOLDER]–>”作为占位,而将原来字面书写的资源引用改成模板接口(require)调用,该接口负责收集页面所需资源。 require接口实现非常简单,就是准备一个数组,收集资源引用,并且可以去重。最后在页面输出的前一刻,我们将require在运行时收集到的 “A.css”、“B.css”、“C.css”三个资源拼接成html标签,替换掉注释占位“<!–[CSS LINKS PLACEHOLDER]–>”,从而得到我们需要的页面结构。
经过fis团队的总结,我们发现模板层面只要实现三个开发接口,既可以比较完美的实现目前遗留的大部分性能优化原则,这三个接口分别是:
- require(String id):收集资源加载需求的接口,参数是资源id。
- widget(String template_id):加载拆分成小组件模板的接口。你可以叫它为load、component或者pagelet之类的。总之,我们需要一个接口把 一个大的页面模板拆分成一个个的小部分来维护,最后在原来的大页面以组件为单位来加载这些小部件。
- script(String code):收集写在模板中的js脚本,使之出现的页面底部,从而实现性能优化原则中的“将js放在页面底部”原则。
实现了这些接口之后,一个重构后的模板页面的源代码可能看起来就是这样的了:
而最终在模板解析的过程中,资源收集与去重、页面script收集、占位符替换操作,最终从服务端发送出来的html代码为:
不难看出,我们目前已经实现了“按需加载”,“将脚本放在底部”,“将样式表放在头部”三项优化原则。
前面讲到静态资源在上线后需要添加hash戳作为版本标识,那么这种使用模板语言来收集的静态资源该如何实现这项功能呢?答案是:静态资源依赖关系表。
假设前面讲到的模板源代码所对应的目录结构为下图所示:
那么我们可以使用工具扫描整个project目录,然后创建一张资源表,同时记录每个资源的部署路径,可以得到这样的一张表:
基于这张表,我们就很容易实现 {require name=”id”} 这个模板接口了。只须查表即可。比如执行{require name=”jquery.js”},查表得到它的url是“/jquery_9151577.js”,声明一个数组收集起来就好了。这样,整个页面执行 完毕之后,收集资源加载需求,并替换页面的占位符,即可实现资源的hash定位,得到:
接下来,我们讨论如何在基于表的设计思想上是如何实现静态资源合并的。或许有些团队使用过combo服务,也就是我们在最终拼接生成页面资源引用的 时候,并不是生成多个独立的link标签,而是将资源地址拼接成一个url路径,请求一种线上的动态资源合并服务,从而实现减少HTTP请求的需求,比 如:
这个“/combo?files=file1,file2,file3,…”的url请求响应就是动态combo服务提供的,它的原理很简单,就是根据get请求的files参数找到对应的多个文件,合并成一个文件来响应请求,并将其缓存,以加快访问速度。
这种方法很巧妙,有些服务器甚至直接集成了这类模块来方便的开启此项服务,这种做法也是大多数大型web应用的资源合并做法。但它也存在一些缺陷:
- 浏览器有url长度限制,因此不能无限制的合并资源。
- 如果用户在网站内有公共资源的两个页面间跳转访问,由于两个页面的combo的url不一样导致用户不能利用浏览器缓存来加快对公共资源的访问速度。
对于上述第二条缺陷,可以举个例子来看说明:
- 假设网站有两个页面A和B
- A页面使用了a,b,c,d四个资源
- B页面使用了a,b,e,f四个资源
- 如果使用combo服务,我们会得:
- A页面的资源引用为:/combo?files=a,b,c,d
- B页面的资源引用为:/combo?files=a,b,e,f
- 两个页面引用的资源是不同的url,因此浏览器会请求两个合并后的资源文件,跨页面访问没能很好的利用a、b这两个资源的缓存。
很明显,如果combo服务能聪明的知道A页面使用的资源引用为“/combo?files=a,b”和“/combo?files=c,d”,而 B页面使用的资源引用为“/combo?files=a,b”,“/combo?files=e,f”就好了。这样当用户在访问A页面之后再访问B页面 时,只需要下载B页面的第二个combo文件即可,第一个文件已经在访问A页面时缓存好了的。
基于这样的思考,fis在资源表上新增了一个字段,取名为“pkg”,就是资源合并生成的新资源,表的结构会变成:
相比之前的表,可以看到新表中多了一个pkg字段,并且记录了打包后的文件所包含的独立资源。这样,我们重新设计一下{require name=”id”}这个模板接口:在查表的时候,如果一个静态资源有pkg字段,那么就去加载pkg字段所指向的打包文件,否则加载资源本身。 比如执行{require name=”bootstrap.css”},查表得知bootstrap.css被打包在了“p0”中,因此取出p0包的url“/pkg /utils_b967346.css”,并且记录页面已加载了“bootstrap.css”和“A/A.css”两个资源。这样一来,之前的模板代码 执行之后得到的html就变成了:
css资源请求数由原来的4个减少为2个。
这样的打包结果是怎么来的呢?答案是配置得到的。
我们来看一下带有打包结果的资源表的fis配置:
我们将“bootstrap.css”、“A/A.css”打包在一起,其他css另外打包,从而生成两个打包文件,当页面需要打包文件中的资源时,模块框架就会收集并计算出最优的资源加载结果,从而解决静态资源合并的问题。
这样做的原因是为了弥补combo在前面讲到的两点技术上的不足而设计的。但也不难发现这种打包策略是需要配置的,这就意味着维护成本的增加。但好在它有两个优势可以一定程度上弥补这个问题:
- 打包的资源只是原来独立资源的备份。打包与否不会导致资源的丢失,最多是没有合并的很好而已。
- 配置可以由工程师根据经验人工维护,也可以由统计日志生成,这为性能优化自适应网站设计提供了非常好的基础。
关于第二点,fis有这样辅助系统来支持自适应打包算法:
至此,我们通过基于表的静态资源管理系统和三个模板接口实现了几个重要的性能优化原则,现在我们再来回顾一下前面的性能优化原则分类表,剔除掉已经做到了的,看看还剩下哪些没做到的:
| 优化方向 | 优化手段 |
| 请求数量 | 拆分初始化负载 |
| 缓存利用 | 使Ajax可缓存 |
| 页面结构 | 尽早刷新文档的输出 |
“拆分初始化负载”的目标是将页面一开始加载时不需要执行的资源从所有资源中分离出来,等到需要的时候再加载。工程师通常没有耐心去区分资源的分类情况,但我们可以利用组件化框架接口来帮助工程师管理资源的使用。还是从例子开始思考:
模板源代码
在fis给百度内部团队开发的架构中,如果这样书写代码,页面最终的执行结果会变成:
模板运行后输出的html代码
fis系统会分析页面中require(id)函数的调用,并将依赖关系记录到资源表对应资源的deps字段中,从而在页面渲染查表时可以加载依赖的资源。但此时dialog.js是以script标签的形式同步加载的,这样会在页面初始化时出现资源的浪费。因此,fis团队提供了require.async的接口,用于异步加载一些资源,源码修改为:
这样书写之后,fis系统会在表里以async字段来标准资源依赖关系是异步的。fis提供的静态资源管理系统会将页面输出的结果修改为:
dialog.js不会在页面以script src的形式输出,而是变成了资源注册,这样,当页面点击按钮触发require.async执行的时候,async函数才会查表找到资源的url并加载它,加载完毕后触发回调函数。
到目前为止,我们又以架构的形式实现了一项优化原则(拆分初始化负载),回顾我们的优化分类表,现在仅有两项没能做到了:
| 优化方向 | 优化手段 |
| 缓存利用 | 使Ajax可缓存 |
| 页面结构 | 尽早刷新文档的输出 |
剩下的两项优化原则要做到并不容易,真正可缓存的Ajax在现实开发中比较少见,而尽早刷新文档的输出的情况facebook在2010年的 velocity上提到过,就是BigPipe技术。当时facebook团队还讲到了Quickling和PageCache两项技术,其中的 PageCache算是比较彻底的实现Ajax可缓存的优化原则了。fis团队也曾与某产品线合作基于静态资源表、模板组件化等技术实现了页面的 PipeLine输出、以及Quickling和PageCache功能,但最终效果没有达到理想的性能优化预期,因此这两个方向尚在探索中,相信在不久 的将来会有新的突破。
总结
其实在前端开发工程管理领域还有很多细节值得探索和挖掘,提升前端团队生产力水平并不是一句空话,它需要我们能对前端开发及代码运行有更深刻的认 识,对性 能优化原则有更细致的分析与研究。fis团队一直致力于从架构而非经验的角度实现性能优化原则,解决前端工程师开发、调试、部署中遇到的工程问题,提供组 件化框架,提高代码复用率,提供开发工具集,提升工程师的开发效率。在前端工业化开发的所有环节均有可节省的人力成本,这些成本非常可观,相信现在很多大 型互联网公司也都有了这样的共识。
本文只是将这个领域中很小的一部分知识的展开讨论,抛砖引玉,希望能为业界相关领域的工作者提供一些不一样的思路。欢迎关注fis项目,对本文有任何意见或建议都可以在fis开源项目中进行反馈和讨论。
发表在 系统架构
静态资源版本更新与缓存 (一)
每个参与过开发企业级web应用的前端工程师或许都曾思考过前端性能优化方面的问题。我们有雅虎14条性能优化原则,还有两本很经典的性能优 化指导 书:《高性能网站建设指南》、《高性能网站建设进阶指南》。经验丰富的工程师对于前端性能优化方法耳濡目染,基本都能一一列举出来。这些性能优化原则大概 是在7年前提出的,对于web性能优化至今都有非常重要的指导意义。
然而,对于构建大型web应用的团队来说,要坚持贯彻这些优化原则并不是一件十分容易的事。因为优化原则中很多要求是与工程管理相违背的,比如“把 css放在头部”和“把js放在尾部”这两条原则,我们不能让团队的工程师在写样式和脚本引用的时候都去修改一个相同的页面文件。这样做会严重影响团队成 员间并行开发的效率,尤其是在团队有版本管理的情况下,每天要花大量的时间进行代码修改合并,这项成本是难以接受的。因此在前端工程界,总会看到周期性的 性能优化工作,辛勤的前端工程师们每到月圆之夜就会倾巢出动根据优化原则做一次性能优化。
本文从一个全新的视角来思考web性能优化与前端工程之间的关系,通过解读百度前端集成解决方案小组(F.I.S)在打造高性能前端架构并统一百度40多条前端产品线的过程中所经历的技术尝试,揭示前端性能优化在前端架构及开发工具设计层面的实现思路。
性能优化原则及分类
笔者先假设本文的读者是有前端开发经验的工程师,并对企业级web应用开发及性能优化有一定的思考,因此我不会重复介绍雅虎14条性能优化原则。如果您没有这些前续知识,请移步这里来学习。
首先,我们把雅虎14条优化原则,《高性能网站建设指南》以及《高性能网站建设进阶指南》中提到的优化点做一次梳理,按照优化方向分类,可以得到这样一张表格:
| 优化方向 | 优化手段 |
| 请求数量 | 合并脚本和样式表,CSS Sprites,拆分初始化负载,划分主域 |
| 请求带宽 | 开启GZip,精简JavaScript,移除重复脚本,图像优化 |
| 缓存利用 | 使用CDN,使用外部JavaScript和CSS,添加Expires头,减少DNS查找,配置ETag,使AjaX可缓存 |
| 页面结构 | 将样式表放在顶部,将脚本放在底部,尽早刷新文档的输出 |
| 代码校验 | 避免CSS表达式,避免重定向 |
表格1 性能优化原则分类
目前大多数前端团队可以利用yui compressor或者google closure compiler等 压缩工具很容易做到“精简Javascript”这条原则;同样的,也可以使用图片压缩工具对图像进行压缩,实现“图像优化”原则。这两条原则是对单个资 源的处理,因此不会引起任何工程方面的问题。很多团队也通过引入代码校验流程来确保实现“避免css表达式”和“避免重定向”原则。目前绝大多数互联网公 司也已经开启了服务端的Gzip压缩,并使用CDN实现静态资源的缓存和快速访问;一些技术实力雄厚的前端团队甚至研发出了自动CSS Sprites工具,解决了CSS Sprites在工程维护方面的难题。使用“查找-替换”思路,我们似乎也可以很好的实现“划分主域”原则。
我们把以上这些已经成熟应用到实际生产中的优化手段去除掉,留下那些还没有很好实现的优化原则。再来回顾一下之前的性能优化分类:
| 优化方向 | 优化手段 |
| 请求数量 | 合并脚本和样式表,拆分初始化负载 |
| 请求带宽 | 移除重复脚本 |
| 缓存利用 | 添加Expires头,配置ETag,使Ajax可缓存 |
| 页面结构 | 将样式表放在顶部,将脚本放在底部,尽早刷新文档的输出 |
表格2 较难实现的优化原则
现在有很多顶尖的前端团队可以将上述还剩下的优化原则也都一一解决,但业界大多数团队都还没能很好的解决这些问题。因此,本文将就这些原则的解决方 案做进一步的分析与讲解,从而为那些还没有进入前端工业化开发的团队提供一些基础技术建设意见,也借此机会与业界顶尖的前端团队在工业化工程化方向上交流 一下彼此的心得。
静态资源版本更新与缓存
如表格2所示,“缓存利用”分类中保留了“添加Expires头”和“配置ETag”两项。或许有些人会质疑,明明这两项只要配置了服务器的相关选 项就可以实现,为什么说它们难以解决呢?确实,开启这两项很容易,但开启了缓存后,我们的项目就开始面临另一个挑战:如何更新这些缓存。
相信大多数团队也找到了类似的答案,它和《高性能网站建设指南》关于“添加Expires头”所说的原则一样——修订文件名。即:
最有效的解决方案是修改其所有链接,这样,全新的请求将从原始服务器下载最新的内容。
思路没错,但要怎么改变链接呢?变成什么样的链接才能有效更新缓存,又能最大限度避免那些没有修改过的文件缓存不失效呢?
先来看看现在一般前端团队的做法:

或者

大家会采用添加query的形式修改链接。这样做是比较直观的解决方案,但在访问量较大的网站,这么做可能将面临一些新的问题。
通常一个大型的web应用几乎每天都会有迭代和更新,发布新版本也就是发布新的静态资源和页面的过程。以上述代码为例,假设现在线上运行着index.html文件,并且使用了线上的a.js资源。index.html的内容为:
这次我们更新了页面中的一些内容,得到一个index.html文件,并开发了新的与之匹配的a.js资源来完成页面交互,新的index.html文件的内容因此而变成了:

好了,现在要开始将两份新的文件发布到线上去。可以看到,index.html和a.js的资源实际上是要覆盖线上的同名文件的。不管怎样,在发布 的过程中,index.html和a.js总有一个先后的顺序,从而中间出现一段或大或小的时间间隔。对于一个大型互联网应用来说即使在一个很小的时间间 隔内,都有可能出现新用户访问。在这个时间间隔中,访问了网站的用户会发生什么情况呢?
- 如果先覆盖index.html,后覆盖a.js,用户在这个时间间隙访问,会得到新的index.html配合旧的a.js的情况,从而出现错误的页面。
- 如果先覆盖a.js,后覆盖index.html,用户在这个间隙访问,会得到旧的index.html配合新的a.js的情况,从而也出现了错误的页面。
这就是为什么大型web应用在版本上线的过程中经常会较集中的出现前端报错日志的原因,也是一些互联网公司选择加班到半夜等待访问低峰期再上线的原 因之一。此外,由于静态资源文件版本更新是“覆盖式”的,而页面需要通过修改query来更新,对于使用CDN缓存的web产品来说,还可能面临CDN缓 存攻击的问题。我们再来观察一下前面说的版本更新手段:
我们不难预测,a.js的下一个版本是“1.0.1”,那么就可以刻意构造一串这样的请求“a.js?v=1.0.1”、 “a.js?v=1.0.2”、……让CDN将当前的资源缓存为“未来的版本”。这样当这个页面所用的资源有更新时,即使更改了链接地址,也会因为CDN 的原因返回给用户旧版本的静态资源,从而造成页面错误。即便不是刻意制造的攻击,在上线间隙出现访问也可能导致区域性的CDN缓存错误。
此外,当版本有更新时,修改所有引用链接也是一件与工程管理相悖的事,至少我们需要一个可以“查找-替换”的工具来自动化的解决版本号修改的问题。
对付这个问题,目前来说最优方案就是基于文件内容的hash版本冗余机制了。也就是说,我们希望工程师源码是这么写的:

但是线上代码是这样的:

其中”_82244e91”这串字符是根据a.js的文件内容进行hash运算得到的,只有文件内容发生变化了才会有更改。由于版本序列是与文件名写在一起的,而不是同名文件覆盖,因此不会出现上述说的那些问题。同时,这么做还有其他的好处:
- 线上的a.js不是同名文件覆盖,而是文件名+hash的冗余,所以可以先上线静态资源,再上线html页面,不存在间隙问题;
- 遇到问题回滚版本的时候,无需回滚a.js,只须回滚页面即可;
- 由于静态资源版本号是文件内容的hash,因此所有静态资源可以开启永久强缓存,只有更新了内容的文件才会缓存失效,缓存利用率大增;
- 修改静态资源后会在线上产生新的文件,一个文件对应一个版本,因此不会受到构造CDN缓存形式的攻击
虽然这种方案是相比之下最完美的解决方案,但它无法通过手工的形式来维护,因为要依靠手工的形式来计算和替换hash值,并生成相应的文件。这将是一项非常繁琐且容易出错的工作,因此我们需要借助工具。我们下面来了解一下fis是如何完成这项工作的。
首先,之所以有这种工具需求,完全是由web应用运行的根本机制决定的:web应用所需的资源是以字面的形式通知浏览器下载而聚合在一起运行的。这 种资源加载策略使得web应用从本质上区别于传统桌面应用的版本更新方式。为了实现资源定位的字面量替换操作,前端构建工具理论上需要识别所有资源定位的 标记,其中包括:
- css中的@import url(path)、background:url(path)、backgournd-image:url(path)、filter中的src
- js中的自定义资源定位函数,在fis中我们将其规定为__uri(path)。
- html中的<script src=”path”>、<link href=”path”>、<imgsrc=”path”>、已经embed、audio、video、object等具有资源加载功能的标签。
为了工程上的维护方便,我们希望工程师在源码中写的是相对路径,而工具可以将其替换为线上的绝对路径,从而避免相对路径定位错误的问题(比如js中需要定位图片路径时不能使用相对路径的情况)。

fis的资源定位设计思想
fis有一个非常棒的资源定位系统,它是根据用户自己的配置来指定资源发布后的地址,然后由fis的资源定位系统识别文件中的定位标记,计算内容hash,并根据配置替换为上线后的绝对url路径。
要想实现具备hash版本生成功能的构建工具不是“查找-替换”这么简单的。我们考虑这样一种情况:

资源引用关系
由于我们的资源版本号是通过对文件内容进行hash运算得到,如上图所示,index.html中引用的a.css文件的内容其实也包含了 a.png的hash运算结果,因此我们在修改index.html中a.css的引用时,不能直接计算a.css的内容hash,而是要先计算出 a.png的内容hash,替换a.css中的引用,得到了a.css的最终内容,再做hash运算,最后替换index.html中的引用。
这意味着构建工具需要具备“递归编译”的能力,这也是为什么fis团队不得不放弃gruntjs等task-based系统的根本原因。针对前端项目的构建工具必须是具备递归处理能力的。此外,由于文件之间的交叉引用等原因,fis构建工具还实现了构建缓存等机制,以提升构建速度。
在解决了基于内容hash的版本更新问题之后,我们可以将所有前端静态资源开启永久强缓存,每次版本发布都可以首先让静态资源全量上线,再进一步上线模板或者页面文件,再也不用担心各种缓存和时间间隙的问题了!
在本系列的下一部分,我们将介绍静态资源管理与模板框架的思路和用法。
作者简介:张云龙,百度公司Web前端研发部前端集成解决方案小组技术负责人,目前负责F.I.S项目,读者可以关注他的微博:http://weibo.com/fouber/。
转载于:https://www.cnblogs.com/xuweili/articles/3685450.html
Solr与MongoDB集成,实时增量索引[转]相关推荐
- Solr 4.x定时、实时增量索引 - 修改、删除和新增索引
2019独角兽企业重金招聘Python工程师标准>>> 一.开始增量索引前的准备工作. 1.认识data-config.xml中相关属性 <!-- transformer 格式 ...
- Solr(搜索引擎服务)和MongoDB通过mongodb-connector进行数据同步的解决方案,以及遇到的各种坑的总结(针对solr-5.3.x版本),mongodb和solr实现实时增量索引
Solr配置与MongoDB的安装 Solr安装配置到目前已经非常简单,参考官方文档:http://lucene.apache.org/solr/quickstart.html,官方文档中用的是clo ...
- solr定时实时重建索引和增量更新——sxt
定时实时重建索引和增量更新 Solr Data Import Handler Scheduler说明: 将 apache-solr-dataimportscheduler-1.0.jar 和solr自 ...
- solr定时实时重建索引和增量更新
注:在上一篇的solr增量索引中遇到了一个很大的问题:定时任务一直无法执行,后来找了很多原因,分析日志后发现增量索引的请求都没发送,又经过一番折腾才在网上找到了解决方法,是apache-solr-da ...
- MongoDB+集成SpringBoot+索引+并发优化 - 基于《MongoDB进阶与实战:唐卓章》
文章目录 MongoDB - 基于<MongoDB进阶与实战:唐卓章> 一.首次安装 服务安装 配置文件修改 可视化工具 Docker部署 二.基本使用 2.1 概念解析 2.2 Mong ...
- mysql同步mongodb_MySQL数据实时增量同步到MongoDB
一.go-mysql-transfer go-mysql-transfer是使用Go语言实现的MySQL数据库实时增量同步工具.能够实时监听MySQL二进制日志(binlog)的变动,将变更内容形成指 ...
- Coreseek:部门查询和增量索引代替实时索引
1.行业调查 索引系统需要通过主查询来获取所有的文档信息,一个简单的实现是整个表的数据到内存,但是这可能会导致整个表被锁定,并且使其它操作被阻止(例如:在MyISAM格款式上INSERT操作).同时, ...
- 基于Solr DIH实现MySQL表数据全量索引和增量索引
实现MySQL表数据全量索引和增量索引,基于Solr DIH组件实现起来比较简单,只需要重复使用Solr的DIH(Data Import Handler)组件,对data-config.xml进行简单 ...
- coreseek实时索引更新之增量索引
coreseek实时索引更新有两种选择: 1.使用基于磁盘的索引,手动分区,然后定期重建较小的分区(被称为"增量").通过尽可能的减小重建部分的大小,可以将平均索引滞后时间降低到3 ...
最新文章
- mysql latid1_【转】mysql触发器的实战经验(触发器执行失败,sql会回滚吗) | 学步园...
- PAT甲级1149 Dangerous Goods Packaging :[C++题解]哈希表、逆向思维
- 深度案例 | 神策数据如何助力房产企业数字化转型快速落地?
- ACT5.6 动手实验手册 如何在工作组模式下对客户端进行数据收集 如何在AD域环境下对...
- 1044. 火星数字(20)
- [转]理解ThreadLocal
- [GCN] 增加可视化+代码注释 of GitHub项目:Graph Convolutional Networks in PyTorch
- jquery 引号问题
- iOS 开发应用内跳转到App Store
- 《团队作业第三、第四周》五小福团队作业--Scrum 冲刺阶段--Day1--领航
- linux下SVN CVS命令大全
- python基础教程十进制_Python基础教程(四)
- McAfee迈克菲最新杀毒防火墙软件安装McAfeeEndpointSecurity10.6.1 百度云下载
- 阿里巴巴面试算法题目:25匹赛马,5个跑道,也就是说每次有5匹马可以同时比赛。问最少比赛多少次可以知道跑得最快的5匹马
- 异地多活与CAP原理
- 职业规划,如何月入1万、3万、5万、10万?
- simulink模块,提供xpctarget下驱动源码
- 判断点是否在视景体内的参考资料
- 百度地图开发(二)——开发前的准备(密钥的申请)
- 服务器上行宽带和下行宽带如何区分?