L1正则项-稀疏性-特征选择
原文链接: http://chenhao.space/post/b190d0eb.html
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
所谓稀疏模型就是模型中很多的参数是0,这就相当于进行了一次特征选择,只留下了一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
那么问题来了,为什么L1正则化会产生稀疏解?
L1/L2正则化损失函数
线性回归L1正则化损失函数:
minw[∑i=1N(wTxi−yi)2+λ∥w∥1]........(1)\min_w [\sum_{i=1}^{N}(w^Tx_i - y_i)^2 + \lambda \|w\|_1 ]........(1) wmin[i=1∑N(wTxi−yi)2+λ∥w∥1]........(1)
线性回归L2正则化损失函数:
minw[∑i=1N(wTxi−yi)2+λ∥w∥22]........(2)\min_w[\sum_{i=1}^{N}(w^Tx_i - y_i)^2 + \lambda\|w\|_2^2] ........(2) wmin[i=1∑N(wTxi−yi)2+λ∥w∥22]........(2)
正则化作用
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
L2正则化可以防止模型过拟合,一定程度上,L1也可以防止过拟合。
L1正则化与稀疏性
事实上,”带正则项”和“带约束条件”是等价的。为了约束 www 的可能取值空间从而防止过拟合,我们为该优化问题加上一个约束,就是 www 的L1范数不能大于m:
{min∑i=1N(wTxi−yi)2s.t.∥w∥1⩽m.........(3)\begin{cases} \min \sum_{i=1}^{N}(w^Tx_i - y_i)^2 \\ s.t. \|w\|_1 \leqslant m.\end{cases}........(3) {min∑i=1N(wTxi−yi)2s.t.∥w∥1⩽m.........(3)
(1)(1)(1)式和(3)(3)(3)式是等价的,为了求解带约束条件的凸优化问题,写出拉格朗日函数:
∑i=1N(wTxi−yi)2+λ(∥w∥1−m)........(4)\sum_{i=1}^{N}(w^Tx_i - y_i)^2 + \lambda (\|w\|_1-m)........(4) i=1∑N(wTxi−yi)2+λ(∥w∥1−m)........(4)
设 w∗w^∗w∗ 和 λ∗\lambda^∗λ∗ 是原问题和对偶问题的最优解,则根据???条件得:
{0=∇w[∑i=1N(W∗Txi−yi)2+λ∗(∥w∥1−m)]0⩽λ∗.........(5)\begin{cases} 0 = \nabla_w[\sum_{i=1}^{N}(W^{*T}x_i - y_i)^2 + \lambda^* (\|w\|_1-m)] \\ 0 \leqslant \lambda^*.\end{cases}........(5) {0=∇w[∑i=1N(W∗Txi−yi)2+λ∗(∥w∥1−m)]0⩽λ∗.........(5)
(5)(5)(5)式中的第一个式子不就是 w∗w^*w∗ 为带 L2 正则项的优化问题的最优解的条件嘛,而 λ∗\lambda^*λ∗ 就是L2正则项前面的正则参数。
由上面公式推导可看出,L1正则项相当于为参数定义了一个棱形的解空间(因为必须保证L1范数不能大于m,L1范数的值又等于所有参数绝对值之和,即 ∣w1∣+∣w2∣+∣w3∣+...+∣wn∣⩽m|w_1|+|w_2|+|w_3|+...+|w_n| \leqslant m∣w1∣+∣w2∣+∣w3∣+...+∣wn∣⩽m),假设参数为2个,即 ∣w1∣+∣w2∣⩽m|w_1|+|w_2| \leqslant m∣w1∣+∣w2∣⩽m ,我们画出它的解空间:
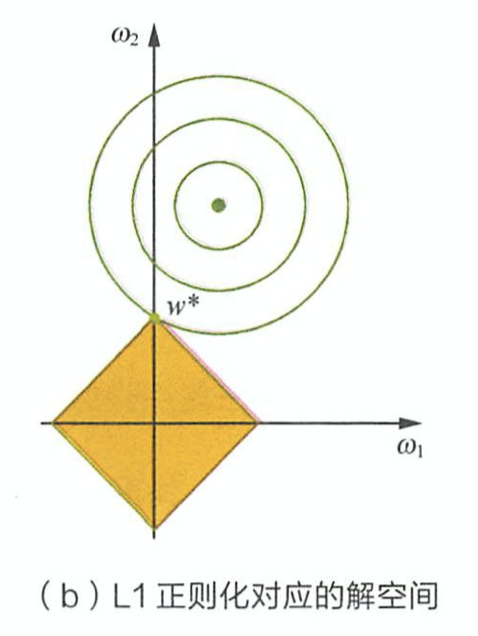
设L1正则化损失函数:J=J0+λ∑w∣w∣J = J_0 + \lambda \sum_{w} |w|J=J0+λ∑w∣w∣ ,其中 J0=∑i=1N(wTxi−yi)2J_0 = \sum_{i=1}^{N}(w^Tx_i - y_i)^2J0=∑i=1N(wTxi−yi)2 是原始损失函数,后面那一项是L1正则化项,λ\lambdaλ 是正则化系数。图中的等线图就是 J0J_0J0 ,棱形是L1正则化项的解空间,当它们俩在某点处相交时,该点就是最优解。很明显,在棱形的解空间中,棱角顶点很容易与等线图相交。
在上图中,它们相交就意味中 w1w_1w1 和 w2w_2w2 至少有一个为0,当参数更多时也是同理。
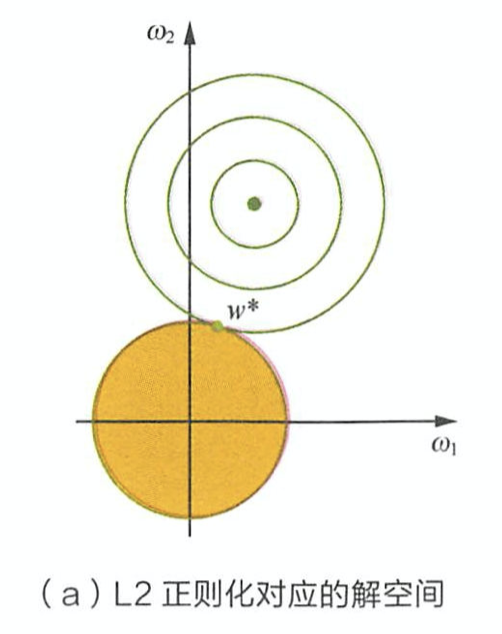
L2正则化的空间解如下图(公式推导跟L1差不多):
参考资料
- 百面机器学习
- 深入理解L1、L2正则化
L1正则项-稀疏性-特征选择相关推荐
- 为什么L1正则化会有稀疏性?为什么L1正则化能进行内置特征选择?
# 个人认为,这两个应该是同一个问题. 首先给大家推荐一个比较直观地搞懂L1和L2正则化的思考,有视频有图像,手动赞! https://zhuanlan.zhihu.com/p/25707761 当然 ...
- L1正则化与稀疏性、L1正则化不可导问题
转:L1正则化与稀疏性 坐标轴下降法(解决L1正则化不可导的问题).Lasso回归算法: 坐标轴下降法与最小角回归法小结 L1正则化使得模型参数具有稀疏性的原理是什么? 机器学习经典之作<pat ...
- L1、L2正则化与稀疏性
禁止转载,谢谢! 1.正则化(Regularization)的基本概念 - 什么是正则化/如何进行正则化 定义:在机器学习中正则化(regularization)是指在模型的损失函数中加上一个正则 ...
- L1为什么具有稀疏性
解释一: 假设费用函数 L 与某个参数 x 的关系如图所示: 则最优的 x 在绿点处,x 非零. 现在施加 L2 regularization,新的费用函数()如图中蓝线所示: 最优的 x 在黄点处, ...
- 机器学习速成课程 | 练习 | Google Development——编程练习:稀疏性和 L1 正则化
稀疏性和 L1 正则化 学习目标: 计算模型大小 通过应用 L1 正则化来增加稀疏性,以减小模型大小 降低复杂性的一种方法是使用正则化函数,它会使权重正好为零.对于线性模型(例如线性回归),权重为零就 ...
- L1正则化及其稀疏性的傻瓜解释
本文翻译自:L1 Norm Regularization and Sparsity Explained for Dummies, 特别感谢原作者Shi Yan! 0. 前言 好吧,我想我就是很笨的那一 ...
- 稀疏性和L1正则化基础 Sparsity and Some Basics of L1 Regularization
Sparsity 是当今机器学习领域中的一个重要话题.John Lafferty 和 Larry Wasserman 在 2006 年的一篇评论中提到: Some current challenges ...
- 机器学习-过拟合、正则化、稀疏性、交叉验证概述
在机器学习中,我们将模型在训练集上的误差称之为训练误差,又称之为经验误差,在新的数据集(比如测试集)上的误差称之为泛化误差,泛化误差也可以说是模型在总体样本上的误差.对于一个好的模型应该是经验误差约等 ...
- 正则化,岭回归Shrinkage,lasso稀疏性推导和论文总结
参考原文https://github.com/Catherine08/AI-paper-reading/blob/master/Regression%20shrinkage%20and%20selec ...
- 机器学习/算法面试笔记1——损失函数、梯度下降、优化算法、过拟合和欠拟合、正则化与稀疏性、归一化、激活函数
正值秋招,参考网络资源整理了一些面试笔记,第一篇包括以下7部分. 1.损失函数 2.梯度下降 3.优化算法 4.过拟合和欠拟合 5.正则化与稀疏性 6.归一化 7.激活函数 损失函数 损失函数分为经验 ...
最新文章
- 编译原理词法分析实验
- java 进阶 知乎_(二)零基础写Java知乎爬虫之进阶篇
- 计算机科学中抽象的作用,抽象释义
- 计算机二级法律一班题目,湖南省计算机二级考试 程序设计题目精选30道
- javascript怎么禁用浏览器后退按钮
- php中NULL、false、0、 有何区别?
- 模型算法_详解SVM模型之SMO算法
- 十一、JAVA接口的定义和使用
- vtd xml java_新兴XML处理方法VTD-XML介绍
- PADS2007小技巧收集----本人总结
- 干货!Web 网页设计规范
- 全网最全的 Java 各类技术栈架构图汇总(建议收藏)
- iPad如何访问共享文件夹
- MapReduce实现商品推荐算法(用户购买向量*商品同现矩阵)
- 费马小定理 (证明)
- 『ACM』ACM部分训练日记(以此纪念和队友与FLS一起度过的快乐时光)
- sklearn梯度提升树(GBDT)调参小结
- Swagger2快速入门
- centos7安装docker并配置daocloud
- 实现uniapp的app和小程序开发中能使用axios进行跨域网络请求,并支持携带cookie
热门文章
- 资源屋分享两款导航网站源码 支持自动收录、自动审核、自动检测友链功能
- Dell/R730XD sas盘 raid0与JBOD性能比较
- Jetpack:Room超详细使用踩坑指南!
- 词霸天下---177 词根 【 -vast- = -wast- 空,荒废 】仅供学习使用
- Windows 打开和关闭默认共享方法汇总
- R语言 dbWriteTable 写入数据库为空和乱码问题
- 北京第一年-OpenGL-7 egl wgl glx agl glew window display surface context rendertarget glfw都是什么?
- Hive系列(三)实操
- sd卡数据恢复源码android,SD卡数据恢复非常简单,想学的看过来!
- Linux代理服务器 Centos Nginx安装、反向代理配置、Nginx开机自启动及日志每天自动分割压缩