Open Compound Domain Adaptation
摘要
一个典型的源域方法是在源域(如晴天)的标注数据上训练模型,以在目标域(如雨天)的测试数据上获得高性能。无论目标包含单个同质域还是多个异质域,现有的工作总是假设域之间存在明显的区别,这在实践中往往是不正确的(例如,天气变化)。我们研究了一个开放复合域适配(OCDA)问题,其中目标是多个同质域的合成物,没有域标签,反映了来自混合和新情况的真实数据收集。我们提出了一种基于对OCDA的两种技术见解的新方法:(1)、课程领域适应策略,以数据驱动的自组织方式引导跨领域的泛化;(2)、内存模块,以提高模型对新领域的灵活性。我们在数字分类、面部表情识别、语义分割和强化学习方面的实验证明了我们的方法的有效性。
1、引言
当测试数据与训练数据来自相同的底层分布时,监督学习可以实现视觉任务的竞争性性能。不幸的是,这种假设在现实中往往不成立,例如,测试数据可能包含与训练数据相同的对象类别,但不同的背景、姿势和外观。
领域自适应的目标是使在训练数据上学习的模型适应于不同分布的测试数据。这种分布差距通常表示为定义良好的数据域的离散概念之间的转换,例如,晴天收集的图像与雨天收集的图像。尽管领域泛化和潜在领域适应都试图处理复杂的目标领域,但现有的大多数研究通常假设领域之间存在已知的明确区分。
在实际中很难定义域之间的这种已知和明确的区别,例如,测试图像可以在混合的、不断变化的、有时从未见过的天气条件下收集。由于有许多因素共同导致数据方差,将数据分离到离散域变得不太可能。
我们建议研究开放复合领域适应(OCDA),连续和更现实的设置域适应(cf图1和表1)。任务是学习模型从源域数据标签和适应无标号复合目标域数据可以从源域在各种不同的因素。我们的目标域可以看作是多个传统同质域的组合,其中每个域在一个或两个主要因素上都是独特的,但没有给出域标签。例如,SVHN、MNIST、MNISTM、USPS、SynNum这5个著名的数字识别数据集,其区别主要在于背景和文本字体。将它们视为不同的领域不一定是最佳实践,在某些情况下也不可行。相反,我们的复合目标域将它们放在一起。此外,在推断阶段,OCDA不仅在复合目标域测试模型,而且在训练时未见过的开放域测试模型。
在我们的OCDA设置中,目标域不再具有主要的单模态分布,这对现有的域适应方法提出了挑战。我们提出了一种基于对OCDA的两种技术见解的新方法:(1)、课程领域适应策略,以数据驱动的自组织方式跨领域区分引导归纳;(2)、内存模块,以提高模型对新领域的敏捷性。
不像现有的课程适应方法依赖于实例难度的整体衡量,我们根据复合目标域中未标记实例与已标记源域中的个体差距来安排它们的学习。这样我们就解决了一个越来越难的领域适应问题直到我们覆盖了整个目标领域。
具体来说,我们首先训练神经网络:(1)、区分标记源域中的类,(2)、从与标记源域数据差异最小的容易目标实例中捕获域不变性。一旦网络不再能够区分源域和简单的目标域数据,我们就向网络提供更困难的目标实例,这些实例离源域更远。该网络学习保持对分类任务的鉴别性,同时对整个复合目标域具有更强的鲁棒性。
![]()
从技术上讲,我们必须解决描述每个实例与源域之间的差距的挑战。我们首先从数据中提取特定于域的特性表征,然后排名目标实例根据距离源域的特征空间,假设这些特性不会导致甚至分散的网络学习区别的特征分类。我们使用类别混淆损失来提取特定领域的因素,并将其表示为带有随机类别标签扭曲的传统交叉熵损失。
我们的第二个技术见解是,在推理过程中使用一个记忆模块为开放域准备模型,该记忆模块有效地增强了分类输入的表示。直观地说,如果输入与源域足够接近,那么从其自身提取的特征很可能已经导致了准确的分类。否则,输入激活的记忆功能可以介入并发挥更重要的作用。因此,这个内存增强的网络在处理开放域方面比普通的网络更加灵活。
综上所述,我们做出了以下贡献:1)我们将传统的离散域适应扩展到OCDA,一个更现实的连续域适应设置。2)我们开发了一个OCDA解决方案,具有两个关键的技术见解:用于处理混合域目标的实例特定课程域适配和用于处理开放域的内存增强功能。3)我们设计了分类、识别、分割和强化学习的几个基准,并进行了全面的实验来评估我们的方法在OCDA设置下的有效性。
2、相关工作
我们根据表1回顾文献。
无监督域适配
目标是在没有基础真值注释的情况下保持新领域的识别精度。代表性的技术包括潜在分布对齐、反向传播、梯度反转、对抗判别、联合最大均值差异、周期一致性和最大分类器差异。虽然他们的结果很有希望,但传统的域自适应设置侧重于“一个源域,一个目标域”,不能处理存在多个目标域的更复杂的场景。
![]()
潜在和多目标域适配
目标是将非监督域自适应扩展到潜在的或多个或连续的目标域,当只有源域有类标签时。这些方法通常假设有明确的域区别或需要域标签(例如,测试实例i属于目标域j),但这种假设在现实场景中很少成立。在这里,我们向复合域适配更进一步,其中测试集中的类别标签和域标签都不可用。
开放/部分设置的域适配
另一种研究途径是解决源域和目标域之间的类别共享/非共享问题,即开放集和部分集域适配。 他们假设目标域包含以下两种情况:(1)、源域中没有出现的新类别; 或者2)只是出现在源域中的类别的子集。 这两种设置都涉及到类别的“开放性”。 相反,这里我们研究领域的“开放性”,即存在在训练阶段缺失的新领域。
3、我们的方法到OCDA
图2和3展示了我们的整体工作流程。 它有三个主要组成部分:1)在源域中仅使用类标签分解域特征,2)为课程域调整调度数据,3)处理新域的内存模块。
3.1、松开域特征
我们将领域特有的特征与阶级间的区别区分开来。 它们允许我们构建一个增量领域适应的课程。
我们首先使用标记的源域数据。训练一个神经网络分类器。 让
表示倒数第二层的编码器,
表示分类器。 编码器主要捕获数据的分类区分表示。
我们假设该类别鉴别编码器不包括的所有因素都反映了域特征。 它们可以由另一个编码器提取,
满足两个性质:(1)、完整性:
,即两个编码器的输出必须为解码器重建输入提供足够的信息,2)正交性:域编码器
与类编码器
之间的互信息应该很少。 我们将满足第一个属性的算法细节留给附录,因为它们不是我们的创新性。
![]()
对于和
之间的正交性,我们提出了一种类混淆算法,它在以下两个子问题之间交替使用:
其中上标是实例索引,
是域编码器
试图混淆的鉴别器。 我们首先用源域中的标记数据训练鉴别器
。 对于目标域中的数据,我们通过我们之前训练过的分类器
为它们分配伪标签。 学习域编码器
由于
(在标签空间中一致选择的随机标签)而导致类混淆。 训练分类器
后,第一个子问题本质上学习了域编码器,将输入
分类为一个随机类
。 算法1详细描述了域解纠缠过程。
图4 (a)和(b)分别可视化了类编码器和域编码器
所嵌入的示例。 类编码器将实例放置在集群中的同一个类中,而域编码器根据实例的常见外观放置实例,而不管它们的类是什么。
3.2、课程域适配
我们根据与源域的距离对复合目标域中的所有实例进行排序,用于课程域的[54]适配。 我们计算目标实例xt和源域之间的域间隙,作为它们在域特征空间中的平均距离:
。
我们分阶段训练网络,每次训练几个时代,逐渐吸收越来越远离源域的实例。 在课程学习的每个阶段,我们最小化两个损失:一个是在已标记的源域上定义的交叉熵损失,另一个是在源域和当前覆盖的目标实例之间计算的域混淆损失。 图4 (c)展示了我们实验中的一个课程。
![]()
3.3、开放适配的内存模块
现有的领域自适应方法通常使用直接从输入中提取的特征进行自适应。 在训练过程中,当输入来自一个与所见域显著不同的新域时,这种表示就会变得不充分,并可能欺骗分类器。 我们提出了一个内存模块来增强我们的模型; 它允许知识从源领域转移,因此网络可以动态平衡输入传递的信息和记忆传递的知识,以便对以前未见过的领域更敏捷地分类。
![]()
类别内存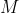 :
:
我们设计了一个内存模块来存储来自源域的类信息。 受原型分析的启发,我们也使用类心
来构造我们的内存
,其中
为目标类的数量。
增强器 :
:
对于每个输入实例,我们构建一个增强器来增强其直接表示,并在内存中加入关于源域的知识:
,其中
是一个softmax函数。 我们将这个增强器添加到直接表示
中,由域指标进行加权。
域指示 :
:
在开放领域,网络必须动态地校准有多少知识从源领域转移,有多少知识依赖于输入的直接表示。 直观地说,输入x和源域之间的域间隙越大,内存特性的权重就越大。 我们为这种域感知设计了一个域指示器:,其中
是一个带有tanh激活函数的轻量级网络,而
是我们之前学过的域编码器。
源增强表示 :
:
输入的最终表示是直接图像特征和记忆增强特征之间的动态平衡版本:
它以领域感知的方式将类别区分知识从标记的源域转移到输入域。 运算符⊗是元素乘法。 采用余弦分类器,我们对该表示进行,然后将其发送到softmax分类层。 当输入与源域存在显著差异时,所有这些选择都有助于处理域不匹配。
4、实验
数据集
为了便于对各种任务(如分类、分割和导航)进行综合评估,我们精心设计了四个开放式复合域适应(OCDA)基准:C-Digits、C-Faces、C-Driving和C-Mazes。
1、C-Digits:该基准旨在评估不同外观和背景下的分类适应能力。 它建立在5个经典数字数据集(SVHN, MNIST, MNIST-M, USPS和SynNum)上,其中SVHN作为源域,MNIST, MNIST-M和USPS混合作为复合目标域,SynNum为开放域。 我们使用SWIT作为一个额外的开放域进行进一步的分析。
2、C-Faces:该基准旨在评估不同相机姿态下的分类适应能力。 它构建在Multi-PIE数据集上,其中C05(正面视图)作为源域,C08-C14(左侧视图)作为复合目标域,C19(右侧视图)作为开放域。
3、C-Driving:该基准旨在评估仿真到不同真实驾驶场景的细分适应能力。 源域采用GTA-5数据集,复合域和开放域采用BDD100K数据集(不同场景包括“rainy”、“snowy”、“cloudy”和“overcast”)。
4、C-Mazes:该基准旨在评估不同环境表象下的导航适应能力。 它构建在GridWorld环境[17]之上,其中使用不同颜色的迷宫作为源域和开放域。 由于强化学习通常假设不事先访问环境,因此这里不存在复合目标域。
![]()
网络架构:为了与之前的工作进行公平的比较,我们分别使用改进的LeNet-5[19]和ResNet-18作为CDigits和C-Faces的骨干网。 在[45,56,33]之后,预训练的VGG-16是CDriving的骨干网络。 在之后,我们使用ResNet-18测试我们的强化学习方法。
评价指标:C-digits性能通过数字分类精度来衡量,C-Faces性能通过面部表情分类精度来衡量。 C-Driving的性能由标准mIOU衡量,C-Mazes的性能由300步的平均成功率衡量。 我们用五次运行来评估每个方法的性能,并报告平均值和标准偏差。 此外,我们报告了单个领域的结果和平均结果的综合分析。
比较的方法:对于分类任务,我们选择了传统的无监督域自适应方法(ADDA, JAN, MCD)和最新的多目标域自适应方法(MTDA, BTDA, DADA)进行比较。 由于MTDA, BTDA和DADA与我们的工作最相关,我们直接将我们的结果与他们的论文中报道的数字进行对比。 对于分割任务,我们比较了三种最先进的方法,AdaptSeg, CBST, IBN-Net和PyCDA。 对于强化学习任务,我们使用MTL、MLP和SynPo进行基准测试,这是跨环境适应的代表性工作。 为了进行公平的比较,我们将这些方法应用于与我们相同的骨干网。
4.1、消融实验
领域聚焦因子解纠缠的有效性
在此我们验证了区域聚焦因子解纠缠有助于发现复合目标区域中的潜在结构。 它是通过不同编码找到的k近邻的域识别率来探测的。 图5 (b)显示,我们解纠缠产生的特征识别率(~ 95%)比没有解纠缠产生的特征识别率(~ 65%)高得多。
课程领域适应的有效性
图5 (a)还显示,在复合领域,课程培训对USPS绩效的贡献大于MNIST和MNITS-M。 另一方面,从图4和表2可以看出USPS是距离源域SVHN最远的目标域。 这意味着课程领域的适应可以通过一种易难的适应计划来轻松地适应遥远的目标领域。
记忆增强表象的有效性
回忆一下,内存增强表示由两个主要组件组成:来自内存的增强器和域指示符。 从图5 (a)中,我们观察到类增强器对所有目标域都有很大的改进。 这是因为增强器将有用的语义概念从内存传输到任何域的输入。 另一个观察结果是,域指示器在开放域(“SynNum”)上是最有效的,因为它通过利用域关系帮助动态校准表示(图5 (c))。
4.2、比较结果
C-Digits.
表2显示了不同方法的性能比较。 我们有以下观察。 首先,ADDA和JAN通过增强全局分布对齐来提高复合域的性能。 然而,它们也牺牲了开放域上的性能,因为没有内置机制来处理任何新域,将模型“过度拟合”到所见的域。 其次,MCD在开放域上提高了结果,但在复合目标域上的精度下降。 最大化分类器的差异增加了对开放域的鲁棒性; 然而,在复合目标域中,它也未能捕获到细粒度的潜在结构。 最后,与其他多目标领域自适应方法(MTDA和DADA)相比,该方法发现了领域结构,并进行了领域感知的知识转移,在所有测试领域都具有显著优势。
C-Faces.
在C-Faces基准测试中也可以得到类似的观察结果,如表3所示。 由于人脸表示本质上是分层的,JAN在C14上展示了具有竞争力的结果,这是由于它的分层传输策略。 在不同相机姿态下的域转移下,我们的方法在复合域和开放域上仍然优于其他方法。
C-Driving.
我们比较了最新的语义分割自适应方法,如AdaptSeg, CBST和IBN-Net。 所有方法都在BDD100K数据集的真实驾驶场景下进行测试。 我们可以看到,我们的方法在复合域(1.1%增益)和开放域(2.4%增益)上都有明显的优势,如表4(左)所示。 我们在附录中详细说明每个类的准确性。 质量比较如图6 (a)所示。
C-Mazes.
为了直接与SynPo进行比较,我们还评估了它们提供的GridWorld环境。 这个基准测试的任务是学习能够在给定迷宫中成功收集所有宝物的导航策略。 现有的强化学习方法会受到环境变化的影响,我们在这里模拟迷宫的外观。 最终结果列于表4(右)。 我们的方法在导航体验中传递视觉知识,比现有技术提高了30%以上。
4.3、进一步的分析
对复合目标域复杂性的鲁棒性:
通过改变复合目标域中的传统目标域数据集的数量来控制复合目标域的复杂性。 在这里,我们逐渐将构成域从单个目标域(即MNIST)增加到两个,最终增加到三个(即MNIST + MNIST-M + USPS)。 从图7 (a)中,我们观察到随着数据集数量的增加,我们的方法只会经历适度的性能下降。 经过学习的课程使知识能够逐步转移,能够应对复合目标领域的复杂结构。
![]()
![]()
开放域数量的稳健性
性能变化w.r.t.开放域的数量如图7 (b)所示。这里我们包括两个新的数字数据集,USPS-M(以类似的方式制作MNIST-M)和SWIT,作为额外的开放域。 与JAN和MCD相比,我们的方法对不同数量的开放域更具弹性。 框架中的域指示模块有助于动态标定嵌入,从而增强了对开放域的鲁棒性。 图8给出了获得的JAN, MCD嵌入与我们方法的t-SNE可视化比较。
5、总结
我们形式化了一个更现实的主题,称为领域鲁棒学习的开放复合领域适应。 我们提出了一个新的模型,其中包括自组织课程领域自适应bootstrap泛化和记忆增强的特征表示,以构建面向开放领域的敏捷性。 我们开发了分类、识别、分割和强化学习的几个基准,并证明了我们的模型的有效性。
Open Compound Domain Adaptation相关推荐
- 迁移学习——Domain Adaptation
Domain Adaptation 在经典的机器学习问题中,我们往往假设训练集和测试集分布一致,在训练集上训练模型,在测试集上测试.然而在实际问题中,测试场景往往非可控,测试集和训练集分布有很大差异, ...
- 近期必读的9篇CVPR 2019【域自适应(Domain Adaptation)】相关论文和代码
[导读]最近小编推出CVPR2019图卷积网络.CVPR2019生成对抗网络.[可解释性],CVPR视觉目标跟踪,CVPR视觉问答,医学图像分割,图神经网络的推荐相关论文,反响热烈.最近,Domain ...
- Domain adaptation:连接机器学习(Machine Learning)与迁移学习(Transfer Learning)
domain adaptation(域适配)是一个连接机器学习(machine learning)与迁移学习(transfer learning)的新领域.这一问题的提出在于从原始问题(对应一个 so ...
- 基于matlab的fisher线性判别及感知器判别_Deep Domain Adaptation论文集(一):基于label迁移知识...
本系列简单梳理一下<Deep Visual Domain Adaptation: A Survey>这篇综述文章的内容,囊括了现在用深度网络做领域自适应DA(Domain Adaptati ...
- 迁移学习之域自适应理论简介(Domain Adaptation Theory)
©作者 | 江俊广 单位 | 清华大学 研究方向 | 迁移学习 本文主要介绍域自适应(Domain Adaptation)最基本的学习理论,全文不涉及理论的证明,主要是对部分理论的发展脉络的梳理,以及 ...
- 从近年顶会论文看领域自适应(Domain Adaptation)最新研究进展
©PaperWeekly 原创 · 作者 | 张一帆 学校 | 中科院自动化所博士生 研究方向 | 计算机视觉 Domain Adaptation 即在源域上进行训练,在目标域上进行测试. 本文总结了 ...
- 详解3D物体检测模型 SPG: Unsupervised Domain Adaptation for 3D Object Detection via Semantic Point Generation
本文对基于激光雷达的无监督域自适应3D物体检测进行了研究,论文已收录于 ICCV2021. 在Waymo Domain Adaptation dataset上,作者发现点云质量的下降是3D物件检测器性 ...
- 【论文阅读】Universal Domain Adaptation
Universal Domain Adaptation SUMMARY@2020/3/27 文章目录 Motivation Related Work Challenges / Aims /Contri ...
- 【论文阅读】Deep Cocktail Network: Multi-source Unsupervised Domain Adaptation with Category Shift
Deep Cocktail Network: Multi-source Unsupervised Domain Adaptation with Category Shift SUMMARY@ 2020 ...
最新文章
- 第二篇:Mysql---约束条件、修改表的结构、键值
- 模拟教务评教(强智教务)—一件评教实现原理
- java重写6,java重写equals()方法和hashCode()方法
- VS Tools for AI全攻略
- 自定义异常 java
- html5 动态3d箭头,HTML5旋转的3D镐 | 箭头
- stl之vector的应用
- windows PC电脑必备3个实用软件
- python中的time的时间戳_python中的时间time、datetime、str和时间戳
- SAP物料编码- -
- Java 汉字转拼音(完美支持解决多音字)
- 名词性从句引导词的基本用法
- 10.24程序员日,开源社给大家送上大礼!【抢票贴】#疯狂倒计时24小时,10月24-25日I WANT YOU!#...
- 从视频中提取光流 UCF-101
- 不需要解压使用对pdf文件进行压缩
- Android音频混响特效的设置
- 缓冲区溢出攻击指什么?如何防御?
- 大数据入门第零天——总体课程体系概述
- CTF题库RSA实践 (RSA-Tool2 by tE! 工具的使用)
- Cannot find module coa/compile.js