python学习(十八)爬虫中加入cookie
转载自:原文链接
前几篇文章介绍了urllib库基本使用和爬虫的简单应用,本文介绍如何通过post信息给网站,保存登陆后cookie,并用于请求有
权限的操作。保存cookie需要用到cookiejar类,可以输出cookie信息查看下
123456789101112131415 |
import http.cookiejarimport urllib.request
#声明一个CookieJar对象实例来保存cookiecookie = http.cookiejar.CookieJar()#HTTPCookieProcessor对象来创建cookie处理器handler = urllib.request.HTTPCookieProcessor(cookie)#通过handler来构建openeropener = urllib.request.build_opner(handler)#通过opner访问网址response = opner.open('http://www.baidu.com')#访问cookie中的数据for item in cookie: print('Name = '+ item.name) print('Value = '+ item.value)
|
1 通过http.cookiejar.CookieJar()创建一个cookiejar对象,用来保存上网留下的cookie。
2 为了处理cookie,需要创建cookie处理器,通过urllib.request.HTTPCookieProcessor(cookie)根据cookie
创建cookie处理器。
3 接下来根据cookie处理器,建立opener, urllib.request.build_opener(handler)创建opener
4 通过openr访问cookie中的数据
可以保存cookie,用于以后访问有权限的网页。下面将cookie写入文件
123456789101112 |
#定义文件名filename = 'cookie.txt'#定义MozillaCookieJar对象保存cookie,并且cookie关联上filename文件cookie = http.cookiejar.MozillaCookieJar(filename)#创建cookie处理器handler = request.HTTPCookieProcessor(cookie)#通过handler构建openeropener = request.build_opener(handler)#利用opener请求网页response = opener.open('http://www.baidu.com')#保存cookie到文件cookie.save(ignore_discard = True, ignore_expires = True)
|
1 传入文件名,调用http.cookiejar.MozillaCookieJar创建cookie,
cookie和文件名绑定了。
2 根据cookie创建处理器, request.HTTPCookieProcessor创建handler
3 根据Cookie处理器创建opener
4 用opener访问网站,生成cookie
5 cookie.save保存到filename文件中,ignore_discard表示忽略是否过期,
及时被丢弃也保存。ignore_expires表示文件存在则覆盖写入。
对于保存好的cookie文件,可以提取并访问其他网页。
123456789101112 |
filename = 'cookie.txt'#创建MozillaCookieJar对象cookie = http.cookiejar.MozillaCookieJar()#从文件中读取cookie内容到变量cookie.load(filename, ignore_discard = True, ignore_expires = True)#生成cookie处理器handler = request.HTTPCookieProcessor(cookie)#创建openeropener = request.build_opener(handler)#用opener打开网页response = opener.open('http://www.baidu.com')print(response.read().decode('utf-8'))
|
1 用MozillaCookieJar创建cookie
2 调用cookie.load加载文件内容到cookie中
3 根据cookie创建HTTPCookieProcessor
4 根据handler创建opener
5 利用opener打开网页,返回response
下面综合应用上面的知识,用爬虫模拟登陆,然后获取有权限的网页和信息。
通过浏览器审查元素的方式可以查看访问网站的request和response,用fiddler更方便一些,用fidder监控浏览器
数据,然后模拟浏览器发送登录请求。
随便找一个需要登陆的网站
http://www.lesmao.cc/forum.php
找到登陆按钮,点击登陆,查看fiddler监控的数据。
可以在fiddler中看到这个request请求post数据给网站。

通过webform这一选项看到我们投递的消息
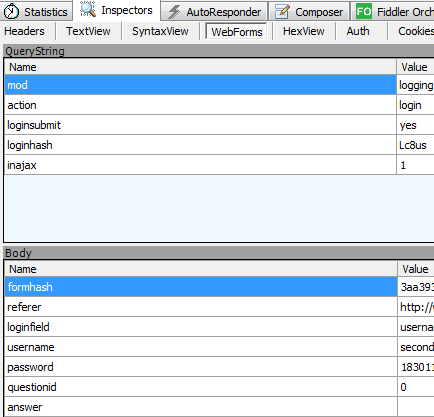
有些网页是需要登陆才能访问的,如
http://www.lesmao.cc/home.php?mod=space&do=notice&view=system
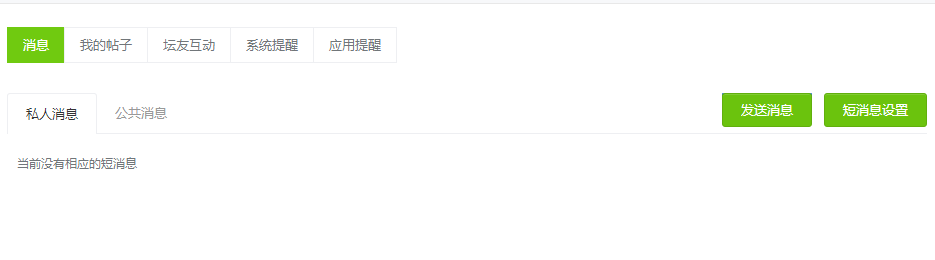
下面先模拟登陆,获取cookie,然后利用cookie访问个人信息网页。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657 |
if __name__ == '__main__': #登陆地址 login_url = 'http://www.lesmao.cc/member.php?mod=logging&action=login&referer=' #User-Agent信息 user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0' #Headers信息 head = {'User-Agnet': user_agent, 'Connection': 'keep-alive'}
#登陆Form_Data信息 Login_Data = {} Login_Data['formhash'] = '5ea0f6e4' Login_Data['referer'] = 'http://www.lesmao.cc/./' Login_Data['loginfield'] = 'username' Login_Data['username'] = 'second' Login_Data['password'] = '18301' Login_Data['loginsubmit'] = 'true' Login_Data['questionid'] = '0' Login_Data['answer'] = ''
#使用urlencode方法转换标准格式 logingpostdata = parse.urlencode(Login_Data).encode('utf-8') #声明一个CookieJar对象实例来保存cookie cookie = cookiejar.CookieJar() #利用urllib.request库的HTTPCookieProcessor对象来创建cookie处理器,也就CookieHandler cookie_support = request.HTTPCookieProcessor(cookie) #通过CookieHandler创建opener opener = request.build_opener(cookie_support) #创建Request对象 req1 = request.Request(url=login_url, data=logingpostdata, headers=head)
#面向对象地址 date_url = 'http://www.lesmao.cc/home.php?mod=space&do=notice&view=system'
req2 = request.Request(url=date_url, headers=head)
try: #使用自己创建的opener的open方法 response1 = opener.open(req1) #print(response1.read().decode('utf-8')) print('.................................') response2 = opener.open(req2) html = response2.read().decode('utf-8') #打印查询结果 print(html)
except error.URLError as e: if hasattr(e, 'code'): print("URLError:%d" % e.code) if hasattr(e, 'reason'): print("URLError:%s" % e.reason) except error.HTTPError as e: if hasattr(e, 'code'): print("URLError:%d" % e.code) if hasattr(e, 'reason'): print("URLError:%s" % e.reason) except Exception as e: print('Exception is : ', e)
|
打印出的html信息和登陆后点击的信息是一致的,所以用cookie登陆并访问其它权限网页成功了。
源码下载地址:
源码下载
我的公众号:

转载于:https://www.cnblogs.com/secondtonone1/p/8109669.html
python学习(十八)爬虫中加入cookie相关推荐
- Python学习笔记(八)爬虫基础(正则和编解码)
知识点 正则 正则匹配url,引用re库,将需要匹配的字段用(.*?)来匹配,可以匹配任何字符串.如果有换行,可以用如下方式解决: 1. ([\s\S]*?) 2. re.findall(reg,ht ...
- python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍
目录 python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍.md 一丶字典 1.字典的定义 2.字典的使用. 3.字典的常用方法. python学习第八讲,python ...
- 二维数组离散程度matlab,(十八)数据分析中的一些概念
(十八)数据分析中的一些概念 HIKAI 29 SEP 2017 0 Comments 矢量.向量.标量 矢量和向量是一个东西,只是在不同领域里面用到的不同称呼.矢量常常用在物理学中,向量在数学.几何 ...
- PyTorch框架学习十八——Layer Normalization、Instance Normalization、Group Normalization
PyTorch框架学习十八--Layer Normalization.Instance Normalization.Group Normalization 一.为什么要标准化? 二.BN.LN.IN. ...
- C1认证学习十八、十九(表单元素、转义字符)
C1认证学习十八.十九(表单元素.语义化标签) 十八 任务背景 HTML的表单用于收集用户的输入,表单元素是指的不同类型的input元素,复选框,单选按钮,提交按钮等等. 任务目标 掌握表单标签以及其 ...
- (私人收藏)python学习(游戏、爬虫、排序、练习题、错误总结)
python学习(游戏.爬虫.排序.练习题.错误总结) https://pan.baidu.com/s/1dPzSoZdULHElKvb57kuKSg l7bz python100经典练习题 pyth ...
- (转)SpringMVC学习(十二)——SpringMVC中的拦截器
http://blog.csdn.net/yerenyuan_pku/article/details/72567761 SpringMVC的处理器拦截器类似于Servlet开发中的过滤器Filter, ...
- ASP.Net学习笔记015--ASP.Net中使用Cookie
ASP.Net学习笔记015--ASP.Net中使用Cookie 表单数据欺骗: 原理跟收到欺骗短信一样,移动信号塔[基站],伪装的移动信号塔会屏蔽移动信号,并且 在信号范围内的手机会自动切换为接收伪 ...
- 漫谈程序员(十八)windows中的命令subst
漫谈程序员(十八)windows中的命令subst 用法格式 一.subst [盘符] [路径] 将指定的路径替代盘符,该路径将作为驱动器使用 二.subst /d 解除替代 三.不加任何参数键入 ...
- [深度学习]Part1 Python学习进阶Ch23爬虫Spider——【DeepBlue学习笔记】
本文仅供学习使用 Python高级--Ch23爬虫Spider 23. 爬虫Spider 23.1 HTTP基本原理 23.1.1 URI与URL 23.1.2 超文本 23.1.3 HTTP 和 H ...
最新文章
- 关于TensorFlow报错ModuleNotFoundError: No module named ‘imutils‘
- ExtJs4 笔记(8) Ext.slider 滚轴控件、 Ext.ProgressBar 进度条控件、 Ext.Editor 编辑控件...
- SOA与云计算相结合推动企业发展
- 【Python】分享几个用Python给图片添加水印的方法,简单实用
- android system.out.println,为什么“System.out.println”在Android中不起作用?
- ssis for循环容器_SSIS包中的序列容器
- 统一沟通-技巧-10-Lync-公网证书-Go Daddy-Buy
- java控制zebra打印机_从Zebra打印机读取状态
- python实现matlab_python 实现matlab的mapminmax方法
- 进程间的通信方式(六种)
- matlab shift 详解,MeanShift算法详解以及matlab源码
- Docker系列(8) Docker网络(3)-- 单机Docker网络配置
- 一枚菜鸟前端工程师月度工作总结
- 如何运行计算机学报的LaTeX模板?
- python如何与access配合使用_使用Python对Access读写操作方法详解
- location属性和prototype属性介绍
- Unity Andriod调试
- 微信小程序大转盘抽奖
- UVA11584---区间DP
- matlab 读取mdf文件路径,访问 MDF 文件 - MATLAB Simulink Example - MathWorks 中国