MySQL数据库常见存储引擎(一)
熟悉mysql数据库的朋友,肯定会喜欢mysql强大的插件式存储引擎,能够支持太多存储引擎,当目前的存储引擎不能满足你的需求时,你可以根据自己的需求选择合适的引擎,将相关的文件拷贝到相关路径,甚至不需要重启数据库,就可以使用。真的很强大。
1 常见存储引擎
memory存储引擎
硬盘上存储表结构信息,格式为.frm,数据存储在内存中
不支持blob text等格式
创建表结构,
支持表锁
支持B树索引和哈希索引
支持数据缓存 数据 缓存
插入速度快
分配给memory引擎表的内存不会释放,由该表持有,删除数据也不会被回收,会被新插入数据使用
CSV存储引擎
所有列必须制定为Not NULL
CSV 引擎不支持索引 不支持分区
文件格式 .frm 表结构信息
.CSV 则是数据文件 是实际的数据
.CSM 报错表的状态和表中的数据
可以直接更改.csv文件 更改数据, check table 检查 repair table (注:在手动更改.csv文件后 可以使用 repair table 加载数据)
例如:
#创建表结构 存储引擎为CSVcreate table csv2 (id int not null,name char(20) not null default "ZN")engine=csv charset utf8;#检查表结构:mysql> desc csv1;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | char(20) | NO | | ZN | |
+-------+----------+------+-----+---------+-------+
2 rows in set (0.02 sec)
#插入数据
mysql> insert into csv1 values(3,'linux'),(20,"MYSQL");
Query OK, 2 rows affected (0.05 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> insert into csv1 values(9,'linux'),(8,"MYSQL");
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from csv1;
+----+-------+
| id | name |
+----+-------+
| 3 | linux |
| 20 | MYSQL |
| 9 | linux |
| 8 | MYSQL |
+----+-------+
4 rows in set (0.00 sec)#手动更改文件vim /var/lib/mysql/test/csv1.CSV #(RPM包安装路径 其他路径根据自己安装情况)
8,"MYSQL"
9,"linux"
99,"docker"
200,"baidu"
44,"openstack"
155,"facebook"
121,"ansible"
#检查表
mysql> check table csv1;
+-----------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------+-------+----------+----------+
| test.csv1 | check | error | Corrupt |
+-----------+-------+----------+----------+
1 row in set (0.03 sec)
#修复表
mysql> repair table csv1;
+-----------+--------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------+--------+----------+----------+
| test.csv1 | repair | status | OK |
+-----------+--------+----------+----------+
1 row in set (0.05 sec)
#检查修复
mysql> check table csv1;
+-----------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------+-------+----------+----------+
| test.csv1 | check | status | OK |
+-----------+-------+----------+----------+
1 row in set (0.03 sec)
#检查数据 更改生效
mysql> select * from csv1;
+-----+-----------+
| id | name |
+-----+-----------+
| 9 | linux |
| 99 | docker |
| 200 | baidu |
| 44 | openstack |
| 155 | facebook |
| 121 | ansible |
+-----+-----------+注意事项:check语句会检查CSV文件的分隔符是否正确,数据列和定义的表结构是否相同,发现不合法的行会抛出异常,在使用修复时,会尝试从当前的CSV文件中复制合法数据,清楚不合法数据,但是需要注意 修复时发现文件中有损坏的记录行,那么后面的数据全部丢失,不管是否合法。
ARCHIVE 存储引擎
适用场景 归档
支持大量数据压缩 插入的列会被压缩,ARCHIVE 引擎使用Zlib无损数据压缩算法
还可以使用optimze table 分析表并打包成更小的格式
仅支持insert、update语句而不支持delete replace update truncate 等语句 能支持order by操作 blob列类型
支持行级锁 但是不支持索引
archive 引擎表文件.frm定义文件 .arz的数据文件,执行优化操作时可能还会还会出现一个扩展名的.arn文件。
简单测试:
先创建一个myisam存储引擎的表,插入数据,然后创建ARCHIVE 存储引擎的表插入数据,检查其存储空间的大小。
#创建测试表和相关的数据mysql> create table archive2 engine=myisam as select TABLE_CATALOG,TABLE_SCHEMA,TABLE_NAME,COLUMN_NAME from information_schema.columns;
Query OK, 3362 rows affected (0.10 sec)
Records: 3362 Duplicates: 0 Warnings: 0mysql> select count(*) from archive2;
+----------+
| count(*) |
+----------+
| 3362 |
+----------+
1 row in set (0.00 sec)
#继续再插入数据(执行多次)
mysql> insert into archive2 select * from archive2;
Query OK, 107584 rows affected (0.23 sec)
#检查数据量
mysql> select count(*) from archive2;
+----------+
| count(*) |
+----------+
| 860672 |
+----------+
1 row in set (0.00 sec)
#检查数据大小mysql> show table status like "archive2"\G;
*************************** 1. row ***************************Name: archive2Engine: MyISAMVersion: 10Row_format: DynamicRows: 860672Avg_row_length: 53Data_length: 45790208
Max_data_length: 281474976710655Index_length: 1024Data_free: 0Auto_increment: NULLCreate_time: 2017-05-16 13:35:26Update_time: 2017-05-16 13:38:14Check_time: NULLCollation: gbk_chinese_ciChecksum: NULLCreate_options: Comment:
1 row in set (0.00 sec)ERROR:
No query specified#数据大小45790208新创建存储引擎为archive类型的表
mysql> create table archive3 engine=archive as select * from archive2;
Query OK, 860672 rows affected (2.69 sec)
Records: 860672 Duplicates: 0 Warnings: 0mysql> select count(*) from archive3;
+----------+
| count(*) |
+----------+
| 860672 |
+----------+
1 row in set (0.11 sec)
检查大小
mysql> show table status like "archive3"\G;
*************************** 1. row ***************************Name: archive3Engine: ARCHIVEVersion: 10Row_format: CompressedRows: 860672Avg_row_length: 6Data_length: 5801647
Max_data_length: 0Index_length: 0Data_free: 0Auto_increment: NULLCreate_time: NULLUpdate_time: 2017-05-16 13:42:35Check_time: NULLCollation: gbk_chinese_ciChecksum: NULLCreate_options: Comment:
1 row in set (0.00 sec)
大小:5801647对比结果相差8倍的存储值,差距还是很大。
BLACKGOLE存储引擎
是一个比较特殊的存储引擎,只管写入,但不管存储,尽管能像其他存储引擎一样接受数据,但是所有数据都不会保存,BLACKGOLE存储引擎永远为空,有点类似Linux下的/dev/null。
#创建表试试
mysql> create table black engine=blackhole as select * from archive2;
Query OK, 860672 rows affected (0.65 sec)
Records: 860672 Duplicates: 0 Warnings: 0mysql> select * from black ;
Empty set (0.00 sec)mysql> insert into black select * from archive2;
Query OK, 860672 rows affected (0.62 sec)
Records: 860672 Duplicates: 0 Warnings: 0mysql> select * from black ;
Empty set (0.00 sec)多次测试发现真的这么神奇,插入什么都成功了,但就是找不到数据,很神奇的存储引擎吧?看看多次测试,结果就是那么神奇,插入都是成功的,但就是找不到数据,这个存储引擎神奇吧,看看这个神奇的存储引擎有哪些用途呢??
1、尽管BLACKHOLE存储引擎不会保存数据,但是启用binlog,那么执行得SQL语句还是实际上被记录,也就是说能复制到SLAVE端。如下图:
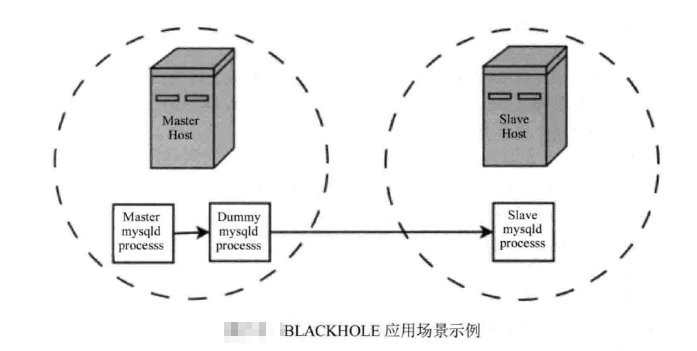
结合复制特性中的replicete-do-* 或者reolicate-ignore-*规则,可以实现对日志的过滤,通过这一巧妙的设计,就可以实现相同的写入,但是主从间的数据不一致。
BLACKHOLE对象中的insert触发器会按照标准触发,不过由于BLACKHOLE对象是空,那么UPdate和delete绝对不可能触发,对于触发器中FOR EACH RAW语句并不会有任何影响。
其他应用情形:
其他应用:
验证dump文件语法
通过对比启动一级禁用二进制日志文件时的性能,来评估二进制日志对负载的影响。
BLACKHOLE存储引擎 支持事务,提交事务会写入二进制日志 但回滚则不会
BLACKHOLE存储引擎与自增列
BLACKHOLE引擎是no-op无操作引擎,所有在BLACKHOLE对象上的操作是没有效果的,那么久需要考虑主见自增列的行为,该引擎不会自动增加自增列值,实际上也不会保存自增字段的状态,对于复制来说,这一点很重要。
考虑以下复制场景
1、Master端BLACKHOLE表拥有一个自增的主键列
2、Slave端表存储引擎为Myisam
3、Master端对该表对象的插入操作没有明确知道自增列的列值
该场景下 Slave端就会出现主键列的重复键错误,再给予语句的复制(SBR)模式下,每次插入事件的INSERT_ID都是相同的,因此复制就会触发插入重复键的错误。
在基于行的复制模式下,该引擎返回的列值总是相同的,那么在Slave端就会出现尝试插入相同值的错误。
MySQL的插件式存储引擎是功能很丰富的,同样也是适用于不用的应用情景,当你深入了解其原理后,才能发挥出MySQL更好的性能。
转载于:https://blog.51cto.com/dreamlinux/1926304
MySQL数据库常见存储引擎(一)相关推荐
- mysql 修改时间段内_详解mysql数据库MyISAM存储引擎如何转为Innodb及其中的注意点...
概述 mysql数据库存储引擎为MyISAM的时候,在大访问量的情况下数据表有可能会出现被锁的情况,这就会导致用户连接网站时超时而返回502,此时就需要MySQL数据库MyISAM存储引擎转为Inno ...
- MySQL数据库:存储引擎
一.什么是存储引擎: 存储引擎是MylSQL的核心,是数据库底层软件组织,数据库使用存储引擎进行创建.查询.更新和删除数据.不同的存储引擎提供不同的存储机制.索引技巧.锁级别.事务等功能.存储引擎是基 ...
- MySQL 数据库常用存储引擎的特点
数据库的存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建.查询.更新和删除数据.不同的存储引擎提供不同的存储机制.索引技巧.锁定水平等功能,使用不同的存储引擎,还可以 获得 ...
- MySQL数据库的存储引擎
目录 1.存储引擎概念 2.常用存储引擎 2.1MyISAM 2.1.1MyISAM的特点 2.1.2MyISAM表支持3种不同的存储格式: 2.1.3MyISAM适用的生产场景举例 2.2InnoD ...
- mysql数据库federated存储引擎
1.概述 msyql数据库federated存储引擎是本场端访问.修改远端mysql数据库表数据,与oracle数据库database link类似,但也存在着如下差异: 每个federated表都有 ...
- Mysql数据库之存储引擎
一.存储引擎概念 MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制.索引技巧.锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎. ...
- MySQL的常见存储引擎介绍与参数设置调优
MySQL常用存储引擎之MyISAM 特性:1.并发性与锁级别2.表损坏修复check table tablenamerepair table tablename3.MyISAM表支持的索引类型①.全 ...
- MySQL的常见存储引擎介绍与参数设置调优(转载)
原文地址:http://www.cnblogs.com/demon89/p/8490229.html MySQL常用存储引擎之MyISAM 特性:1.并发性与锁级别2.表损坏修复check table ...
- MySQL数据库MyISAM存储引擎转为Innodb
之前公司的数据库存储引擎全部为MyISAM,数据量和访问量都不是很大,所以一直都没什么问题.但是最近出现了MySQL数据表经常被锁的情况,直接导致了用户连接网站时超时而返回502,于是决定把存储引擎转 ...
最新文章
- 编写安全的ASP代码
- Python--matplotlib 绘图可视化练手--折线图/条形图
- 《深入理解mybatis原理》 MyBatis的一级缓存实现详解 及使用注意事项
- 007_CSS ID选择器
- 第五篇T语言实例开发,数组空间使用(版本5.3)
- 经典递归——斐波那契数列,汉诺塔
- QT的QMultiHash类的使用
- 大学c语言程序设计实训课实验报告,大学一年级下学期C语言程序设计实验报告答案 完整版...
- 7天拿到阿里Android岗位offer,都是精髓!
- 20165203 2017-2018-2 《Java程序设计》第一周学习总结
- [密码学基础][每个信息安全博士生应该知道的52件事][Bristol Cryptography][第13篇]概述投影点表达的用途的优点
- CODING 受邀参加《腾讯全球数字生态大会》
- vue 跳转页面带对象_vue跳转页面的几种方法(推荐)
- mysql如何加快备份和恢复速度_加速mysql备份和恢复
- 使用VBA,优化处理Excel表格
- 基于SpringBoot的后台管理系统(Encache配置、全局异常处理(重点))(四)
- android textview得到文字的长度,Android TextView 文字长度控制
- 在edge浏览器找不到internet选项?
- cv2.imread不能正常读取gif格式图片
- Unity小地图的实现