第12课:HA下的Spark集群工作机制解密
Spark HA需要先安装zookeeper,推荐稳定版zookeeper-3.4.6,具体安装如下:
1) 下载Zookeeper
进入http://www.apache.org/dyn/closer.cgi/zookeeper/,你可以选择其他镜像网址去下载,用官网推荐的镜像:http://mirror.bit.edu.cn/apache/zookeeper/

下载zookeeper-3.4.6.tar.gz。
2) 安装Zookeeper
提示:下面的步骤发生在master服务器。
以ubuntu14.04举例,把下载好的文件放到/usr/local/spark目录,用下面的命令解压:
cd /usr/local/spark
tar -zxvf zookeeper-3.4.6.tar.gz
解压后在/usr/local/spark目录会多出一个zookeeper-3.4.6的新目录,解压后配置zookeeper环境变量。
3) 配置Zookeeper
提示:下面的步骤发生在master服务器。
a. 配置.bashrc,添加ZOOKEEPER_HOME环境变量
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.6
b. 将zookeeper的bin目录添加到path中
export PATH=${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:${HIVE_HOME}/bin:
${KAFKA_HOME}/bin:$PATH
c. 使配置的环境变量立即生效:source ~/.bashrc
d. 创建data和logs目录,data目录用来存放元数据信息,logs用来存放运行日志
- cd $ZOOKEEPER_HOME
- mkdir data
- mkdir logs
e. 创建并打开zoo.cfg文件
- cd $ZOOKEEPER_HOME/conf
- cp zoo_sample.cfg zoo.cfg
- vim zoo.cfg
d. 配置zoo.cfg
# 配置Zookeeper的日志和服务器×××号等数据存放的目录。
# 千万不要用默认的/tmp/zookeeper目录,因为/tmp目录的数据容易被意外删除。
dataDir=/usr/local/spark/zookeeper-3.4.6/data
dataLogDir=/usr/local/spark/zookeeper-3.4.6/logs
# Zookeeper与客户端连接的端口
clientPort=2181
# 在文件最后新增3行配置每个服务器的2个重要端口:Leader端口和选举端口
# server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;
# B 是这个服务器的hostname或ip地址;
# C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
# D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,
# 选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
# 如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信
# 端口号不能一样,所以要给它们分配不同的端口号。
server.0=Master:2888:3888
server.1=Work1:2888:3888
server.2=Work2:2888:3888
e. 创建并打开myid文件
- cd $ZOOKEEPER_HOME/data
- touch myid
- vim myid
f. 配置myid
按照zoo.cfg的配置,myid的内容就是0。
4) 同步Master的安装和配置到Work1和Work2
- 在master服务器上运行下面的命令
cd /root
scp ./.bashrc root@Work1:/root
scp ./.bashrc root@sWork2:/root
cd /usr/local/spark
scp -r ./zookeeper-3.4.6 root@Work1:/usr/local/spark
scp -r ./zookeeper-3.4.6 root@Work2:/usr/local/spark
--修改Work1中data/myid中的值
vim myid
按照zoo.cfg的配置,myid的内容就是1。
--修改Work2中data/myid中的值
vim myid
按照zoo.cfg的配置,myid的内容就是2。
5) 启动Zookeeper服务
- 在Master服务器上运行下面的命令
zkServer.sh start
- 在Work1服务器上运行下面的命令
source /root/.bashrc //使配置的zookeeper环境变量生效
zkServer.sh start
- 在Work2服务器上运行下面的命令
source /root/.bashrc //使配置的zookeeper环境变量生效
zkServer.sh start
6) 验证Zookeeper是否安装和启动成功
- 在master服务器上运行命令:jps和zkServer.sh status
root@Master:/usr/local/spark/zookeeper-3.4.6/bin# jps
3844 QuorumPeerMain
4790 Jps
zkServer.sh status //需在安装的各个节点启动zookeeper
root@master:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
- 在Work1服务器上运行命令:jps和zkServer.sh status
source /root/.bashrc
root@Work1:/usr/local/spark/zookeeper-3.4.6/bin# jps
3462 QuorumPeerMain
4313 Jps
root@Work1:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
- 在Work2服务器上运行命令:jps和zkServer.sh status
root@Work2:/usr/local/spark/zookeeper-3.4.6/bin# jps
4073 Jps
3277 QuorumPeerMain
root@Work2:/usr/local/spark/zookeeper-3.4.6/bin# zkServer.sh status
JMX enabled by default
Using config: /usr/local/spark/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
至此,代表Zookeeper已经安装和配置成功。
Zookeeper安装和配置完成后,需配置Spark的HA机制,进入到spark安装目录的conf目录下,修改spark-env.sh文件
vim spark-env.sh
添加zookeeper支持,进行状态恢复:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,Work1:2181,Work2:2181 -Dspark.deploy.zookeeper.dir=/spark"
注释掉:因为用zookeeper进行HA机制,不需要指定Master
#export SPARK_MASTER_IP=Master
将配置好的文件同步到Work1及Work2上面
scp spark-env.sh root@Work1:/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf
scp spark-env.sh root@Work2:/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf
通过完成后,启动spark集群
./start-all.sh
启动后如下所示:
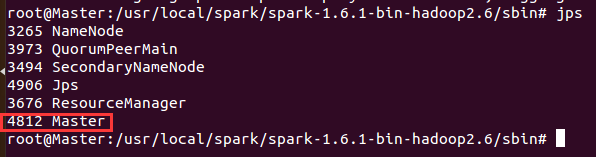
![]() 这里问个问题,我们上面在spark-env.sh中注释掉了SPARK_MASTER_IP=Master,那为什么我们启动spark,会启动Master,为什么?
这里问个问题,我们上面在spark-env.sh中注释掉了SPARK_MASTER_IP=Master,那为什么我们启动spark,会启动Master,为什么?
原因是我们在slaves文件中配置了Work1和Work2节点,故这里默认启动了Master,但是这里我们只有一个Master,我们上面通过zookeeper配置了3台master进行HA,
所以我们需要手动到Work1和Work2上启动Master
./start-master.sh
通过jps查看Master是否启动成功,这时候我们spark集群有3个master。
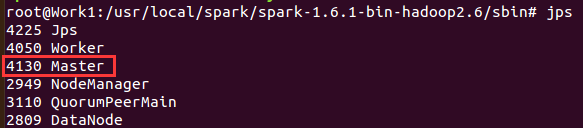
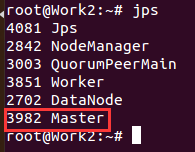
通过Work1:8080和Work2:8080地址查看Master状态为 STANDBY,在等待服务中,暂时什么也没有,只有Master上有。
现在来测试下Spark HA,启动Spark shell,注意:我们现在没有明确指定哪台机器为Master,所以我们不能只写一台,具体命令如下:
./spark-shell --master spark://Master:7077,Work1:7077,Work2:7077
这时候程序运行在集群上,需要向zookeeper去找一台Master=ALIVE的机器,会和3台机器进行连接,最后只会和ALIVE机器进行交互
这时候如果我们手动停止Master,这时候会失去了对Master的连接,这时候会等待被选中的Master去连接他,这时候zookeeper就会在Work1和Work2上去恢复,谁恢复完谁就是Leader,这中间需要时间
适集群情况而定。

这时候可以看到Master从Master机器切换到Work1机器上,也可以通过WebUI去查看,这时候发现Master:7077无法启动,Work1:7077变成了ALIVE,如果在Master机器上重新启动Master,可以发现
Work1:7077还是处于ALIVE状态,Master节点不会进行切换。
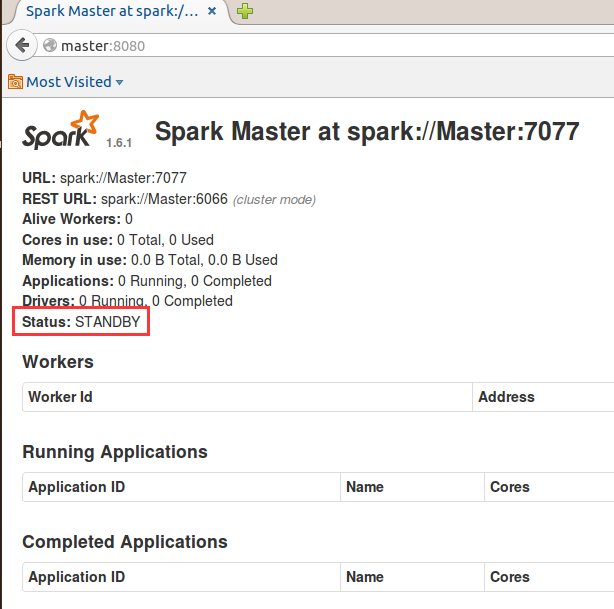
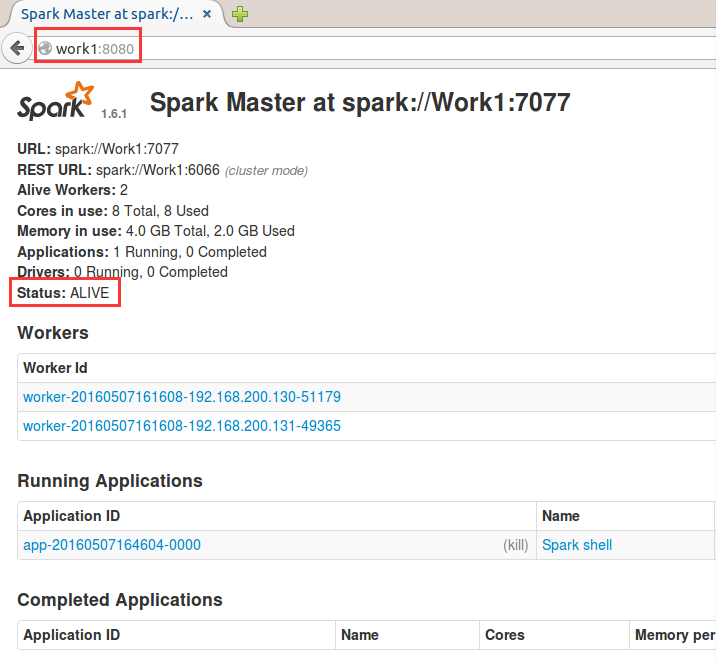
Spark HA机制就分享到这。
备注:
资料来源于:DT_大数据梦工厂(IMF传奇行动绝密课程)-IMF
更多私密内容,请关注微信公众号:DT_Spark
如果您对大数据Spark感兴趣,可以免费听由王家林老师每天晚上20:00开设的Spark永久免费公开课,地址YY房间号:68917580
Life is short,you need to Spark.
转载于:https://blog.51cto.com/18610086859/1771037
第12课:HA下的Spark集群工作机制解密相关推荐
- 第12 课:HA下的Spark集群工作原理解密
第12 课:HA下的Spark集群工作原理解密 本期内容: 1.Spark高可用HA实战 2. Spark集群工作原理详解 1,Spark高可用HA实战 Spark本身是Master/Slaves结构 ...
- 天天用着Redis集群,主从同步该知道吧?集群工作原理是否需要了解下?
作者:z小赵 ★ 一枚用心坚持写原创的"无趣"程序猿,在自身受益的同时也让朋友们在技术上有所提升. 前言 插播一个小插曲,本来文章已经写好准备发布了,手贱清理了缓存导致文本内容全部 ...
- 升腾威讯怎么恢复集群_Redis系列(四):天天用着Redis集群,主从同步该知道吧?集群工作原理是否需要了解下?...
作者:z小赵 ★ 一枚用心坚持写原创的"无趣"程序猿,在自身受益的同时也让朋友们在技术上有所提升. 前言 插播一个小插曲,本来文章已经写好准备发布了,手贱清理了缓存导致文本内容全部 ...
- docker下的spark集群,调整参数榨干硬件
本文是<docker下,极速搭建spark集群(含hdfs集群)>的续篇,前文将spark集群搭建成功并进行了简单的验证,但是存在以下几个小问题: spark只有一个work节点,只适合处 ...
- 干货!Redis集群工作原理解析
作者 | 张小盼 头图 | 下载于东方IC 出品 | CSDN云计算(ID:CSDNcloud) Redis 缓存因其访问性能高.可靠性更高,作为缓存工具在各大互联网公司中广泛使用.今天我们就来看看R ...
- Rocketmq集群工作流程
- docker下,极速搭建spark集群(含hdfs集群)
搭建spark和hdfs的集群环境会消耗一些时间和精力,处于学习和开发阶段的同学关注的是spark应用的开发,他们希望整个环境能快速搭建好,从而尽快投入编码和调试,今天咱们就借助docker,极速搭建 ...
- 【RocketMQ】ubuntu18下部署RocketMQ集群
技术架构 - Producer:消息发布的角色,支持分布式集群方式部署.Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投递,投递的过程支持快速失败并且低延迟. - Con ...
- Spark笔记整理(一):spark单机安装部署、分布式集群与HA安装部署+spark源码编译...
[TOC] spark单机安装部署 1.安装scala 解压:tar -zxvf soft/scala-2.10.5.tgz -C app/ 重命名:mv scala-2.10.5/ scala 配置 ...
最新文章
- 面向对象程序设计第二次作业
- (2)双机调试+符号文件
- 判断用户是否存在再进行新增_MySQL用户行为分析
- C++:两种类实例化
- arcgis批量处理nc文件_ArcGIS处理NetCDF(.nc)的多维科学数据
- Cocos2d-html5 2.2.2的屏幕适配方案
- 自定义Flash背景的相关设置方法以及其与目录下的文件的对应关系
- Java合并流实现简单的文件合并示例
- 高斯消元法 matlab程序
- XML中配置网易云歌手详情滑动效果
- antd组件DatePicker日期国际化错误 中英文都存在问题处理
- 计算机安全培训计划,2018年度计算机学院(软件学院)实验室安全教育培训计划...
- echart象形图-三角锥形/山峰形/三角形--柱子渐变色,x轴换行显示,加单位显示
- ARouter 基础使用详解
- 北风设计模式课程---访问者模式(Visitor)
- 第三篇web前端面试自我介绍(刚毕业的菜鸟)
- 如何不通过网络把电脑上的视频上传到手机端
- Spring Cloud在中小型项目中的应用
- matlab做相似矩阵,如何在MATLAB中创建一个相似矩阵?
- nginx(八十三)error_page、proxy_intercept_errors深究
热门文章
- 腾讯开工日1.5亿美元领投Reddit,美国贴吧最新估值30亿美元
- 真·干货!这套深度学习教程整理走红,从理论到实践的带你系统学习 | 资源...
- 吴恩达新研究:AI看心电图,诊断心律失常准确率超过人类医生丨Nature
- 女神被打码了?一笔一划脑补回来,效果超越Adobe | 已开源
- NASA好奇号发来战报,32368张火星路况实拍数据集上线 | 资源
- 机器人能力再进化,组装宜家椅子只需20分钟! | Science Robotics论文
- Python 用Django创建自己的博客(2)
- How MapReduce Works
- .Net页面缓存OutPutCache详解
- ubuntu上安装rsync+sersync