python统计数据指标的常见方法
文章目录
- 实验环境
- 读取csv文件
- 删除数据中我们不需要的列(假设我不需要ID的属性)
- 统计某一列或多列数据有多少种不同的值
- 统计某一列有多少个等于某个值(测试我这里统计第二列[var3]等于32的值的个数)
- 求取去除缺失值的均值
- 关于众数&最大值&最小值&出现频率在前几的数据
在对数据进行挖掘之前,我们得到的数据往往是不太理想的,数据缺失值太严重导致统计数据指标不太容易,这篇文章记录下如何在含有缺失值的情况下统计出我想要的一些数据
实验环境
- ubuntu 18.04
- python 3.6
- numpy scipy pandas
- 随意一个csv文件(当然是要有数据的,我的csv部分数据如下)

- 每个py文件都导入了以下三个依赖
import numpy as np
import pandas as pd
from scipy import stats
读取csv文件
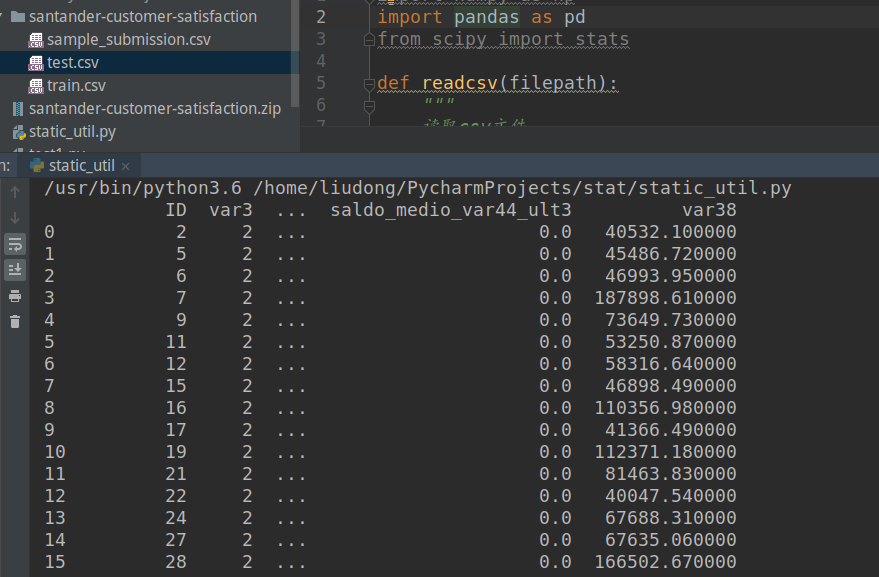
读取csv文件,并在函数中打印出读取的结果,最后返回一个DataFrame对象
def readcsv(filepath):"""读取csv文件:param filpath: 文件路径"""df = pd.read_csv(filepath)print(df)return dffilepath = 'santander-customer-satisfaction/test.csv'
readcsv(filepath)
我的运行结果结果如下:
删除数据中我们不需要的列(假设我不需要ID的属性)
def dropProperty(df, drop_properties):"""传入一个数据表:param df: dataFrame对象:param drop_properties: 想要删除的属性集:return 返回一个删掉了一个或多个属性的df对象,不影响传入的对象"""#axis=0代表删除相应的行,axis=1代表删除相应的列df = df.drop(drop_properties, axis=1)return df
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
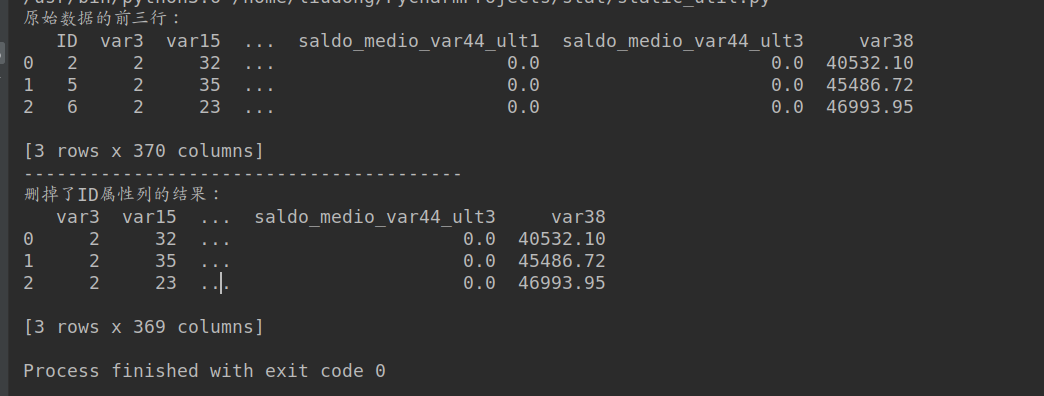
print('原始数据的前三行:')
print(df.head(3))
df = dropProperty(df, ['ID'])
print('--'*20)
print('删掉了ID属性列的结果:')
print(df.head(3))
测试的结果:
统计某一列或多列数据有多少种不同的值
def uniqueCount(df, start, end):"""统计一列或者多列有多少种不同的值:param df: dataframe对象:param start 开始统计的第(start+1)列:param end 最后统计的一列(第end列):return:"""if end <= start:return None
# 冒号是一个切片的意思diffCount = df.iloc[:, start:end].apply(lambda x: len(x.unique()))return diffCount
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
result = uniqueCount(df, 0, 3)
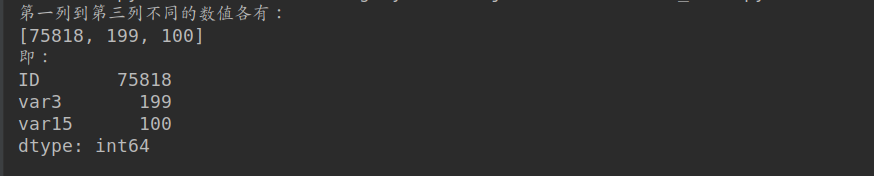
print('第一列到第三列不同的数值各有:')
print(list(result))
print('即:')
print(result)
测试结果:
统计某一列有多少个等于某个值(测试我这里统计第二列[var3]等于32的值的个数)
def countValue(df, col_start, col_end, value):"""统计第col+1列中等于value的数量:param df: dataframe对象:param col_start: 开始列数(从零开始):param col_end: 结束列数:param value: 等于的某个值:return: 个数(如果是多个列,那么返回一个序列)"""if col_start >= col_end:return Noneelse:count = df.iloc[:, col_start:col_end].apply(lambda x: np.sum(x == 0))return count
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
count = countValue(df, 1, 2, 32)
print(count)
测试结果

求取去除缺失值的均值
def meanValue(df, col_start, col_end, miss_set):"""求取各列去除了缺失值的均值:param df:dataframe对象:param col_start: 开始列:param col_end: 结束列:param miss_set: 缺失值的集合:return: 返回各个列的均值"""if col_start >= col_end:return Noneelse:# ~ 代表取反操作,不属于miss_set里面的值的就属于正常的情况# 对正常的值进行mean()操作就是去除了缺失值的均值mean = df.iloc[:, col_start:col_end].apply(lambda x: np.mean(x[~np.isin(x, miss_set)]))return mean
简单测试
filepath = 'santander-customer-satisfaction/test.csv'
df = readcsv(filepath)
# 假设32, np.nan和111是属于不正常的值
mean = meanValue(df, 0, 3, [32, np.nan, 111])
print('去除了不正常值的均值:')
print(mean)
测试结果

关于众数&最大值&最小值&出现频率在前几的数据
- 统计众数需要借助 scipy的stats中的mode函数即
stats.mode(list) - 统计最大值&最小值借助numpy中的max&min
- 统计出现频率最高的几位使用形如
df.iloc[:, :].value_counts().iloc[0:5]的函数
如有问题,请指教
python统计数据指标的常见方法相关推荐
- 数据预处理的常见方法
数据预处理 定义内涵 用户从多种渠道收集的数据可能包含噪音,或是存在不一致.不完整等问题,无法直接 进行训练.为了提高数据的质量,在将数据交给模型训练之前,需要对数据预处理.数据预 处理是指在数据分析 ...
- Python统计词频的几种方法
本文介绍python统计词频的几种方法,供大家参考 目录 方法一:运用集合去重方法 方法二:运用字典统计 方法三:使用计数器 方法一:运用集合去重方法 def word_count1(words,n) ...
- Python中re模块的常见方法
re模块的常见方法 1.pattern.match(从头找一个) ret = re.match("[1-9]?\d$","08") 2.pattern.sear ...
- python统计数据画概率曲线_统计学入门级:常见概率分布+python绘制分布图
基本概念 离散型随机变量 如果随机变量X的所有取值都可以逐个列举出来,则称X为离散型随机变量.相应的概率分布有二项分布,泊松分布. 连续型随机变量 如果随机变量X的所有取值无法逐个列举出来,而是取数轴 ...
- Python数据分析之初识numpy常见方法使用案例
声明与简介 numpy是python数据科学计算的基础包,这个包有多维数据对象ndarray,以及诸多它的派生对象(如:掩码数组.矩阵),同时这些对象还提供了数学,逻辑,形状处理,排序,选择,离散傅立 ...
- 数据标准化的常见方法(Min-Max标准化、Z-Score标准化等)
数据的标准化: 将数据按比例缩放,使之落入一个小的特定区间,一般目的在于:去除数据的单位限制,转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权.数据的归一化便是一个典型的案例. 数据的 ...
- Python保存数据到文件的方法
方法一:open函数保存#保存数据open函数 with open('D:/PythonWorkSpace/TestData/pinglun.txt','w',encoding='utf-8') as ...
- python三维数据可视化的多种方法
目录 用 Matplotlib 实现带颜色映射的三维散点图 代码 效果图 用 Seaborn 绘制三维散点图 代码 效果图 用 Plotly 绘制三维表面图 代码 效果图 Python 中的一些库,如 ...
- Python 中的 os 模块常见方法
os.remove()删除文件 os.rename()重命名文件 os.walk()生成目录树下的所有文件名 os.chdir()改变目录 os.path.split()返回(dirname(),ba ...
- Python 中的 os 模块常见方法?
1 os.remove() 删除文件 2 os.rename() 重命名文件 3 os.walk() 生成目录树下的所有文件名 4 os.chdir() 改变目录 5 os.mkdir/makedir ...
最新文章
- 解决 PermGen space Tomcat内存设置
- 点击鼠标左键 自动锁定计算机图标,鼠标一按左键桌面图标就消失了怎么办_为什么按鼠标左键时桌面图标都不见了...
- java IO 解析
- 一条正确的Java职业生涯规划,顺利拿到offer
- vs已停止工作的解决方案
- oracle当前用户创建的表不可见?
- gd库多点画图 php_用 PHP 实现身份证号码识别
- 差分形式的阻滞增长模型matlab,差分形式的阻滞增长模型.ppt
- steam社区、好友列表无法打开问题通解
- TRNSYS与CONTAM3.4耦合过程
- [Pytorch系列-26]:神经网络基础 - 多个带激活函数的神经元实现非线性回归
- 弘辽电商专题三:打赢店铺翻身仗,提升淘宝权重很重
- 粘包现象以及如何处理粘包
- 服务器如何预防入侵问题
- C++类的交叉引用问题
- 【python】微博热点话题舆情聚类分析
- 以图搜图新体验:图片谷歌和百度识图
- Java算法(八)详细解析:寻找完数
- HTML下拉框、二级联动 select多级联动
- php数字签名算法,PHP生成ECDSA算法数字签名