基于malloc与free函数的实现代码及分析
用于内存管理的malloc与free这对函数,对于使用C语言的程序员应该很熟悉。前段时间听说有的IT公司以“实现一个简单功能的malloc”作为面试题,正好最近在复习K&R,上面有所介绍,因此花了些时间仔细研究了一下。毕竟把题目做出来是次要的,了解实现思想、提升技术才是主要的。本文主要是对malloc与free实现思路的介绍,蓝色部分文字是在个人思考中觉得比较核心的东西;另外对于代码的说明,有一些K&R上的解释,使用绿色加亮。
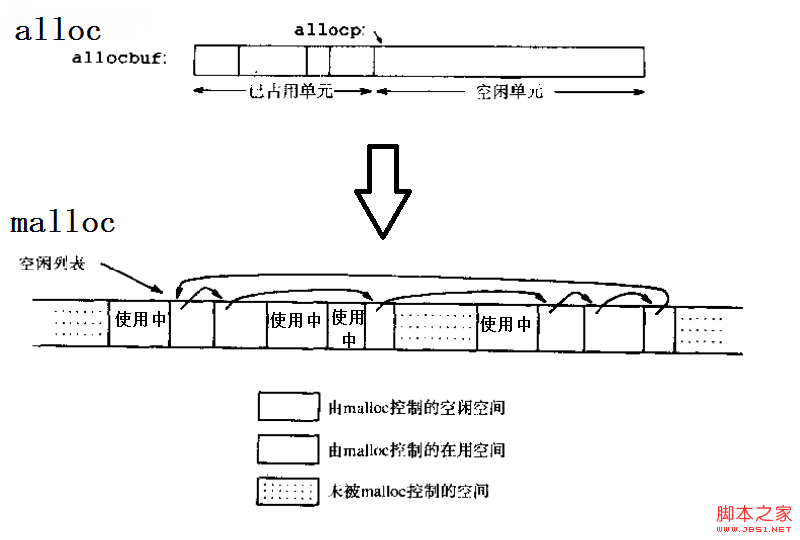
在研究K&R第八章第五节的实现之前,不妨先看看其第五章第四节的alloc/afree实现,虽然这段代码主要目的是展示地址运算。
alloc实现
#define ALLOCSIZE 10000
static char allocbuf[ALLOCSIZE]; /*storage for alloc*/
static char *allocp = allocbuf; /*next free position*/
char *alloc(int n)
{
if(allocbuf+ALLOCSIZE - allocp >= n) {
allocp += n;
return alloc - n;
} else
return 0;
}
void afree(char *p)
{
if (p >= allocbuf && p<allocbuf + ALLOCSIZE)
allocp = p;
}
这种简单实现的缺点:
1.作为代表内存资源的allocbuf,其实是预先分配好的,可能存在浪费。
2.分配和释放的顺序类似于栈,即“后进先出”,释放时如果不按顺序会造成异常。
这个实现虽然比较简陋,但是依然提供了一个思路。如果能把这两个缺点消除,就能够实现比较理想的malloc/free。
仅仅依靠地址运算来进行定位,是限制分配回收灵活性的原因,它要求已使用部分和未使用部分必须通过某个地址分开成两个相邻区域。为了能让这两个区域能够互相交错,甚至其中还包括一些没有分配的地址空间,需要使用指针把同类的内存空间连接起来形成链表,这样就可以处理地址不连续的一系列内存空间。但是为什么只连接了空闲空间而不连接使用中的空间?这么问可能出于在对图中二者类比时的直觉而没有经过思考,这很简单,因为没有必要。前者相互链接是为了能够在内存分配时遍历所有空闲空间,并且在使用free()回收已使用空间时进行重新插入。而对于使用中的空间,由于我们在分配空间时已经知道它们的地址了,回收时可以直接告诉free(),并不用像malloc()时进行遍历。
既然提到了链表,可能对数据结构稍有了解的人会立刻写下一个struct来代表一个内存区域,其中包含一个指向下一个内存区域的指针,但是这个struct的其他成员该怎么写呢?作为待分配的内存区域,大小是不定的,如果把它声明为struct的成员变量显然不妥;如果声明为一个指向某个其他的区域的指针,这似乎又和上面的直观表示不相符合。(当然,这么做也是可以实现的,它看上去是介于上图的两者之间,把管理结构和实际分配的空间相剥离,在文末我会专门的讨论一下这种实现方法)因此,这里仍然把控制结构和空闲空间相分开,但保持它们在内存地址中相邻,形成下图的形式,而正由这个特点,我们可以利用对控制结构指针的指针运算来定位对应的内存区域:
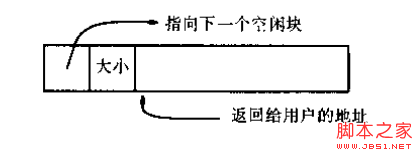
对应地,把控制信息定义为Header:
typedef long Align;/*for alignment to long boundary*/
union header {
struct {
union header *ptr; /*next block if on free list*/
unsigned size; /*size of this block*/
} s;
Align x;
};
typedef union header Header;
这样,malloc的主要工作就是对这些Header和其后的内存块的管理。
malloc()
static Header base;
static Header *freep = NULL;
void *malloc(unsigned nbytes)
{
Header *p, *prevp;
unsigned nunits;
nunits = (nbytes+sizeof(Header)-1)/sizeof(Header) + 1;
if((prevp = freep) == NULL) { /* no free list */
base.s.ptr = freep = prevp = &base;
base.s.size = 0;
}
for(p = prevp->s.ptr; ;prevp = p, p= p->s.ptr) {
if(p->s.size >= nunits) { /* big enough */
if (p->s.size == nunits) /* exactly */
prevp->s.ptr = p->s.ptr;
else {
p->s.size -= nunits;
p += p->s.size;
p->s.size = nunits;
}
freep = prevp;
return (void*)(p+1);
}
if (p== freep) /* wrapped around free list */
if ((p = morecore(nunits)) == NULL)
return NULL; /* none left */
}
}
实际分配的空间是Header大小的整数倍,并且多出一个Header大小的空间用于放置Header。但是直观来看这并不是nunits = (nbytes+sizeof(Header)-1)/sizeof(Header) + 1啊?如果用(nbytes+sizeof(Header))/sizeof(Header)+1岂不是刚好?其实不是这样,如果使用后者,nbytes+sizeof(Header)%sizeof(Header) == 0时,又多分配了一个Header大小的空间了, 因此还要在小括号里减去1,这时才能符合要求。
malloc()第一次调用时建立一个退化链表base,只有一个大小是0的空间,并指向它自己。freep用于标识空闲链表的某个元素,每次查找时可能发生变化;中间的查找和分配过程是基本的链表操作,在空闲链表中不存在合适大小的空闲空间时调用morecore()获得更多内存空间;最后的返回值是空闲空间的首地址,即Header之后的地址,这个接口与库函数一致。
morecore()
#define NALLOC 1024 /* minimum #units to request */
static Header *morecore(unsigned nu)
{
char *cp;
Header *up;
if(nu < NALLOC)
nu = NALLOC;
cp = sbrk(nu * sizeof(Header));
if(cp == (char *)-1) /* no space at all*/
return NULL;
up = (Header *)cp;
up->s.size = nu;
free((void *)(up+1));
return freep;
}
morecore()从系统申请更多的可用空间,并加入。由于调用了sbrk(), 系统开销比较大,为避免morecore()本身的调用次数,设定了一个NALLOC,如果每次申请的空间小于NALLOC,就申请NALLOC大小的空间,使得后续malloc()不必每次都需要调用morecore()。 对于sbrk(),在后面会有介绍。
这里有个让人惊讶的地方:malloc()调用了morecore(),morecore()又调用了free()!第一次看到这里时可能会觉得不可思议,因为按照惯性思维,malloc()和free()似乎应该是相互分开的,各司其职啊?但请再思考一下,free()是把空闲链表进行扩充,而malloc()在空闲链表不足时,从系统申请到更多内存空间后,也要先把它们转化成空闲链表的一部分,再进行利用。这样,malloc()调用free()完成后面的工作也是顺理成章了。根据这个思想,后面是free()的实现。在此之前,还有几个morecore()自身的细节:
1.如果系统也没有空间可以分配,sbrk()返回-1。cp是char *类型,在有的机器上char无符号,这里需要一次强制类型转换。
2.morecore()调用的返回值看上去比较奇怪,别担心,freep会在free()中修改的。使用这个返回值也是为了在malloc()里的判断、p = freep的再次赋值的语句能够紧凑。
free()
void free(void *ap)
{
Header *bp,*p;
bp = (Header *)ap -1; /* point to block header */
for(p=freep;!(bp>p && bp< p->s.ptr);p=p->s.ptr)
if(p>=p->s.ptr && (bp>p || bp<p->s.ptr))
break; /* freed block at start or end of arena*/
if (bp+bp->s.size==p->s.ptr) { /* join to upper nbr */
bp->s.size += p->s.ptr->s.size;
bp->s.ptr = p->s.ptr->s.ptr;
} else
bp->s.ptr = p->s.ptr;
if (p+p->s.size == bp) { /* join to lower nbr */
p->s.size += bp->s.size;
p->s.ptr = bp->s.ptr;
} else
p->s.ptr = bp;
freep = p;
}
free()首先定位要释放的ap对应的bp与空闲链表的相对位置,找到它的的最近的上一个和下一个空闲空间,或是当它在整个空闲空间的前面或后面时找到空闲链表的首尾元素。注意,由于malloc()的分配方式和free()的回收时的合并方式(下文马上要提到),可以保证整个空闲空间的链表总是从低地址逐个升高,在最高地址的空闲空间回指向低地址第一个空闲空间。
定位后,根据要释放的空间与附近空间的相邻性,进行合并,也即修改对应空间的Header。两个if并列可以使得bp可以同时与高地址和低地址空闲空间结合(如果都相邻),或者进行二者之一的合并,或者不合并。
完成了这三部分代码后(注意放到同一源文件中,sbrk()需要#include <unistd.h>),就可以使用了。当然要注意,命名和stdlib.h中的同名函数是冲突的,可以自行改名。
第一次审视源码,会发现很多实现可能原先并没有想到:Header的结构和对齐填充、空间的取整、链表的操作和初始化(边界情况)、malloc()对free()的调用、由malloc()和free()暗中保证的链表地址有序等等,确实很值得玩味。另外再附上前文中提到的两个问题还有一些补充问题的简单思考:
1.Header与空闲空间相剥离,Header中包含一个指向其空闲空间的指针
这样做未必不可,相应地算法需要改动。同时,由于Header和空闲空间不再相邻,sbrk()获得的空间也应该包含Header的部分,内存的分布可能会更加琐碎。当然,这也可能带来好处,即用其他数据结构对链表进行管理,比如按大小进行hash,这样查找起来更快。
2.关于sbrk()
sbrk()也是库函数,它能使堆往栈的方向增长,具体可以参考:brk(), sbrk() 用法详解。
3.可以改进的方
空闲空间的寻找是线性的,查找过程在内存分配中可以看作是循环首次适应算法,在某些情况下可能很慢;如果再建立一个数据结构,如hash表,对不同大小的空间进行索引,肯定可以加快查找本身,并且能实现一些算法,比如最佳匹配。但查找加快的代价是,修改这个索引会占用额外的时间,这是需要权衡的。
morecore()中的最小分配空间是宏定义,在实际使用中完全可以作为参数传递,根据需要设定最小分配下限。
基于malloc与free函数的实现代码及分析相关推荐
- ML之ME/LF:基于不同机器学习框架(sklearn/TF)下算法的模型评估指标(损失函数)代码实现及其函数(Scoring/metrics)代码实现(仅代码)
ML之ME/LF:基于不同机器学习框架(sklearn/TF)下算法的模型评估指标(损失函数)代码实现及其函数(Scoring/metrics)代码实现(仅代码) 目录 单个评价指标各种框架下实现 1 ...
- Rust 阴阳谜题,及纯基于代码的分析与化简
Rust 阴阳谜题,及纯基于代码的分析与化简 雾雨魔法店专栏 https://zhuanlan.zhihu.com/marisa 来源 https://zhuanlan.zhihu.com/p/522 ...
- 用 C 语言开发一门编程语言 — 基于 Lambda 表达式的函数设计
目录 文章目录 目录 前文列表 函数 Lambda 表达式 函数设计 函数的存储 实现 Lambda 函数 函数的运行环境 函数调用 可变长的函数参数 源代码 前文列表 <用 C 语言开发一门编 ...
- malloc和free函数详解
本文介绍malloc和free函数的内容. 在C中,对内存的管理是相当重要.下面开始介绍这两个函数: 一.malloc()和free()的基本概念以及基本用法: 1.函数原型及说明: void *ma ...
- 匿名函数python_基于python内置函数与匿名函数详解
内置函数 Built-in Functions abs() dict() help() min() setattr() all() dir() hex() next() slice() any() d ...
- android 揭示动画_如何使用意图揭示函数名称使代码更好
android 揭示动画 Discover Functional JavaScript was named one of the best new Functional Programming boo ...
- 基于MPI的H.264并行编码代码移植与优化
2010 03 25 基于MPI的H.264并行编码代码移植与优化 范 文 洛阳理工学院计算机信息工程系 洛阳 471023 摘 要 H.264获得出色压缩效果和质量的代价是压缩编码算法复杂度的增加. ...
- Fission:基于 Kubernetes 的 Serverless 函数框架
来自:Kubernetes中文社区 原文:https://blog.csdn.net/qq_34463875/article/details/78042822 本文编译自 Kubernetes 的官方 ...
- c udp文件发送到服务器端,基于UDP的客户端和服务器端的代码设计
实验平台 linux 实验内容 编写UDP服务器和客户端程序,客户端发送消息,服务器接收消息,并打印客户端的IP地址和端口号. 实验原理 UDP是无需连接的通信,其主要实现过程如下: 同样,我们可以按 ...
最新文章
- 不学无数——SpringBoot入门Ⅱ
- C++构造函数和析构函数调用虚函数时都不会使用动态联编
- 【数据结构】线性表的链式表示-循环单链表、循环双链表、静态链表
- 数据库字段属性配置工具界面[用于代码生成]
- postman 使用_Postman简单使用
- Hello,移动WEB—px,dp,dpr像素基础
- Linux系统知识汇总
- 你理解这些Cisco NAT分类和原理吗
- 先进核反应堆 ——新能源概论结课作业
- CAD图纸被设置成只读格式,如何取消?
- 客户价值模型:RFM
- 2021年最新独立版橙色去水印微信小程序-更新2021.8.31
- 【数据结构】(六)树与二叉树
- Nginx实现https反向代理配置
- 【记一次开发油猴插件的过程】——逆水寒
- 提高抗打击能力_如何提高心理承受能力或者抗打击能力?
- UN Comtrade(联合国商品贸易统计数据库)数据爬取Python代码
- About Dfc environment
- 讲述java资源关闭 -莫问身后事
- matlab非同秩矩阵相乘_MATLAB中的矩阵与向量运算