T 检验 (T test)
数据出来了要做三件事:1,检验一下数据是否符合正态分布;2,如果符合正态分布,就进行T检验,看P值是否小于0.05;3,如果数据不符合正态分布,就用另外的“非参数检验”。但是我完全不明白这些名词背后是什么原理。
这些原理是这样的:
举个例子:好比我们有一个H0假设(不希望出现的假设)说:“抽烟人群的肺活量和非抽烟人群没有差异”。我们已经知道非抽烟人群的肺活量均值是u0。因此H0假设就意味着:如果在抽烟人群中抽一个足够大的样本,这个样本的均值应该来自一个均值为u0的正态分布。
为什么样本的均值会服从正态分布呢?当然是因为高大上的“中心极限定理”。
好的,现在我们真的去抽了一个抽烟者样本,算出一个肺活量均值,发现它比非抽烟者的肺活量均值u0低了不少。但是这个时候我们还不能说H0假设就是错的。因为H0假设可以自我辩解说:本来嘛,你的样本均值是来自我这个正态分布,那当然有可能高有可能低。没准你这次只是碰巧抽到一帮肺活量低的人,是你运气不好。
面对这种狡辩,我们……竟然毫无办法!因为这种可能性确确实实是存在的,而且基本上是永远不可能排除掉的。我们任何一个基于统计做出的研究结论,都无法完全否定这样的质疑:你的样本并不能代表“真实”情况,你得到这个结果只是“碰巧”。除非你像超人一样抽样,拿到了全世界所有抽烟者的肺活量数据,才能排除这种所谓“第一类错误”。
但如果要这样想的话,那所有的研究都没法做了。所以我们找了一个现实一点的妥协方案:确实,在你H0假设之下,我是有可能抽样抽到这个均值;但只要让我发现抽到这样的均值的概率小于0.05,我就认为这里面有问题。我认为0.05这么小概率的事情是不可能发生在我身上的。所以如果我们的抽烟者肺活量均值在H0假设之下发生的概率小于0.05,我们就拒绝H0假设,认为抽烟者的平均肺活量和非抽烟者相比,是下降的。
基本上,上面几段只是重复了我第一篇笔记里的内容。所以如果你看过我第一篇笔记的话,可以跳过前面,从这里开始阅读。(那你一开始为什么不说咧!)
那么,我们怎么计算:“在H0假设之下,抽到这个均值的概率”呢?上面说了,H0假设认为,样本均值u来自一个均值为u0的正态分布。我们手里也有样本标准差S。样本的容量是n。那么这就结了,我们把这个正态曲线画出来,把我们的均值标在横坐标上,马上就得到了:在抽样中,抽到的均值小于(或者大于)这个均值的概率。然后我们拿这个概率p去和0.05相比。
这是一个思路,另一个思路是:我们先把0.05所对应的均值在曲线上标出来,这样我们就得到了“可以拒绝H0假设的均值取值范围”。只要我们的均值落在这个范围之内,就说明它悲剧了,它的概率小于0.05;而我们就喜剧了,就可以拒绝H0假设了。而这个范围,我们把它命名为“置信区间”。你把均值“置”入,我就“信”你,这样一个区间。(呃,其实置信区间这个名字另有出处,我以后再另写一篇吧。)
以上这种检验方法是基于正态分布的,我们把它叫做“Z检验”。“Z”代表“正态”的“正”的拼音。(并不是!“Z”在统计学上代表“标准正态分布”。)
但是要应用这种“Z检验”,有个前提:样本容量n要足够大。为什么?同样是因为高大上的“中心极限定理”。我看到课程中举的例题里,使用Z检验的样本容量一般都在100以上。(好像科研实践中是20以上?我忘了。)
那你说我的样本容量只有7啊8啊的,老鼠不给力啊样本收集不上来啊怎么办?没关系,如果你满足另一个前提,你就可以选择我们的另一个优惠套餐。如果你所抽样的那个总体,比如“全体吸烟者的肺活量”,本身服从正态分布的话,就算样本容量小了点,我也可以勉强认为:你的样本均值服从另一种叫做 Student T 的分布。(所以这个优惠套餐是叫学生套餐吗?)
这就是在科研中被大量使用(看来大家的样本数量都不怎么多撒)的:T检验。
注意这里有个容易混淆的概念。Z检验是说:当样本容量足够大时,你的“样本均值”服从某个正态分布。通俗点说:你们实验室去抽了一个样本,得到一个均值;某某大学也做这项研究,也抽了一个样本得到一个均值……这么多均值放在一起,它们是服从正态分布的。为什么?“中!心!极!限!定!理!”
而T检验是说:当样本——那一个个抽烟者的肺活量数字——服从正态分布时,均值服从Student T分布。为什么?抱歉,老师没教……
Student T的分布曲线和正态分布有点像,当然公式不一样。T分布在样本量极大的时候趋近于正态分布。正态分布只要知道均值和标准差就可以画出曲线,T分布还要知道一个值叫“自由度”df,df=n-1。我不知道什么是自由度,但我知道为什么它是n-1而不是n:因为,好比说你的样本里有n个数,你告诉我它们的均值,然后让我猜这n个数是多少。这种情况下,对我来说,前n-1个数都可以“自由”取值,但最后一个却不行。因为一旦前n-1个数确定了,然后根据均值,我就可以算出最后一个数来。所以最后一个数不“自由”。所以自由度是n-1。
自由度在Student T分布和另一种叫“卡方分布”的分布里都有出现。
以上就是Z检验和T检验背后的原理。上面举例举的是一个样本的情况,两个样本的情况可以以此类推。
两个配对样本本质上就是一个样本:比如一个班的学生,期中考的成绩和期末考的成绩,表面上看是两个样本,实际上在做统计的时候,我们是用每个人的期末考减去他本人的期中考,最后还是一个样本。这种情况下H0一般就是两次考试分数没有差异,也就是说期末减期中之后产生的这个样本,其样本均值来自一个均值为0的分布。
两个独立样本情况略复杂,主要是公式里的标准差部分有点变化,均值就拿来直接相减了。具体公式就不写了,其实没必要了解,交给软件或者R就可以了。
T检验的步骤[2]
1、建立虚无假设H0:μ1 = μ2,即先假定两个总体平均数之间没有显著差异;
2、计算统计量t值,对于不同类型的问题选用不同的统计量计算方法;
1)如果要评断一个总体中的小样本平均数与总体平均值之间的差异程度,其统计量t值的计算公式为:
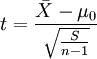
2)如果要评断两组样本平均数之间的差异程度,其统计量t值的计算公式为:
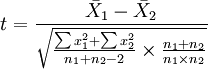
3、根据自由度df=n-1,查t值表,找出规定的t理论值并进行比较。理论值差异的显著水平为0.01级或0.05级。不同自由度的显著水平理论值记为t(df)0.01和t(df)0.05
4、比较计算得到的t值和理论t值,推断发生的概率,依据下表给出的t值与差异显著性关系表作出判断。
| T值与差异显著性关系表 | ||
|---|---|---|
| t | P值 | 差异显著程度 |
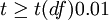
|
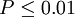
|
差异非常显著 |
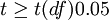
|
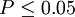
|
差异显著 |
| t < t(df)0.05 | P > 0.05 | 差异不显著 |
5、根据是以上分析,结合具体情况,作出结论。
另附一篇详细公式解释http://wiki.mbalib.com/wiki/T%E6%A3%80%E9%AA%8C
T 检验 (T test)相关推荐
- c语言括号匹配的检验,检验括号匹配的算法
用栈实现检验括号匹配的算法没啥具体描述,数据结构的知识,急用,有重赏 思想是 先进栈,获取第一个半边括号,标记一下,继续进栈直到获取到第二个与之匹配的另一外括号,然后出栈,取出内容.就这样.. 数据结 ...
- 对输入框以及选择框集体的数据检验
对于一个档案输入框,有很多输入框是需要输入数据的,但有时候我们会在输入的时候遗留一些必填的项,如果不做数据校验,这时候点击保存按钮,就悲剧了,报错不说,我们前面填写的数据也就没有了. 所以数据校验非常 ...
- python 检验数据正态分布程度_python 实现检验33品种数据是否是正态分布
我就废话不多说了,直接上代码吧! # -*- coding: utf-8 -*- """ Created on Thu Jun 22 17:03:16 2017 @aut ...
- 用spss做多组两两相关性分析_两独立样本T检验及如何利用SPSS实现其操作
上一篇文章我们讲解了有关单样本T检验的相关内容(如何使用SPSS进行单样本检验),其实论文中除了常用到的单样本T检验以外,还有另外一种T检验的方法也是经常用到的统计方法,也就是两独立样本T检验 说到T ...
- Miller方法产生、检验素数
有关Miller方法过程 设n为被检验的整数,n=m*2^t+1,期中m为n-1的最大奇因子,t>=1.记检测n是否为素数的算法为F(l,k),其中l为正整数,是算法的输入,Pass为布尔型变量 ...
- 用栈实现形如a+bb+a@的中心对称字符的检验
用栈实现形如a+b&b+a@的中心对称字符的检验 将&前字符依次入栈与@前字符进行比较即可,下面是方法 Status match(char *a){ //match方法 SqStack ...
- 用队列实现形如a+b@b+a#的中心对称字符的检验
用队列实现形如a+b@b+a#的中心对称字符的检验 我用网上提供的一种思想,用循环队列实现了这个操作,具体代码如下. /*函数名match,严格来说它并不是Status型*/ Status match ...
- 点滴积累【C#】---检验编号在本表中自动生成,与其他表无关
检验编号在本表中自动生成,与其他表无关 效果: 描述:在本表中自动生成编号,与其他表无关. 调用: 1 protected void Page_Load(object sender, EventArg ...
- 量子力学又一突破,中国科学家首次实现量子纠缠态自检验
这也是国际上首个具有"高可靠.抗干扰"特性的纠缠态自检验实验. 最近,量子力学领域又传来好消息,中国科学技术大学的郭光灿院士团队在实验中首次实现了量子纠缠态的自检验,推动了自检验在 ...
- 学习笔记53—Wilcoxon检验和Mann-whitney检验的区别
Wilcoxon signed-rank test应用于两个related samples Mann–Whitney U test也叫Wilcoxon rank-sum test,应用于两个indep ...
最新文章
- leetcode--Two Sum
- 程序员每周该做的事情!
- sqlserver中的查询两个结果集的差的运算
- 支付宝商户代扣2.0文档
- Java 中 10 大坑爹功能!
- python调用dll函数_关于从加载的DLL调用函数的Python基本问题
- java标识符和关键字相关概念
- QT每日一练day2:day1优化以及QT内存管理机制
- Spark SQL External DataSource外部数据源操作流程
- js键盘相关知识总结
- ICCV2013 录用论文(目标跟踪相关部分)
- Big5和Gb编码转换
- 跳转指定位置(HTML)
- Squid代理服务器应用及配置(图文详解)
- 区块链+珠宝供应链金融:除了解决信任问题,他们想让数字资产流动起来
- 计算机双工模式,100M 全双工、100M 半双工、10M全双工几种模式分别测试
- Visual Studio 快速统一设置项目属性(以VS2017为例)
- 快手伸手“供给侧”,找到直播电商的“源头活水”?
- 变量相关性分析(决策变量和目标函数之间的关系-决策变量可加可分离性)
- 如此正经,日本首部让人流泪的VR电影诞生