深度解析Apollo无人车感知和定位技术
原文地址:http://www.realli.net/archives/26639
有关无人车的定位有两种,一种称之为绝对定位,不依赖任何参照物,直接给出无人车相对地球坐标或者说WGS84坐标系,也就是坐标(B,L,H),其中B为纬度,L为经度,H为大地高即是到WGS-84椭球面的高度, WGS-84坐标系是美国国防部研制确定的大地坐标系,是一种协议地球坐标系。
WGS-84坐标系的定义是:原点是地球的质心,空间直角坐标系的Z轴指向BIH(1984.0)定义的地极(CTP)方向,即国际协议原点CIO,它由IAU和IUGG共同推荐。X轴指向BIH定义的零度子午面和CTP赤道的交点,Y轴和Z,X轴构成右手坐标系。
WGS-84椭球采用国际大地测量与地球物理联合会第17届大会测量常数推荐值,采用的两个常用基本几何参数: 长半轴a=6378137m;扁率f=1:298.257223563。坐标系非常复杂,GPS的测量结果与我国的54系或80系坐标相差几十米至一百多米,随区域不同,差别也不同。
经粗略统计,我国西部相差70米左右,东北部140米左右,南部75米左右,中部45米左右。在中国,国家出于安全的考虑,在地图发布和出版的时候,对84坐标进行了一次非线性加偏,得到的坐标我们称之为GCJ02坐标系。国内许多地图公司,可能是由于业务的需求,或者是商业竞争的某些原因,在GCJ02坐标的基础上又进行了一次非线性加偏,得到了自己的坐标系统。百度就是这么一家公司。百度在GCJ02的基础上进行了BD-09二次非线性加偏,得到了自己的百度坐标系统。
传统的GPS定位精度只有3-7米,我国城市主干道单一车道宽一般是3.75米,也就是说GPS无法做到车道线级定位。在城市道路或峡谷中,精度会进一步下降。即便是美国及北约国家,民用系统也不可能用GPS获得亚米级定位。GPS卫星广播的信号包括三种信号分量:载波、测距码和数据码。测距码又分为P码(精码)和C/A码,通常也会把C/A码叫做民码,P码叫军码。P码会再分为明码和W码,想要破解是完全不可能的。后来在新一代GPS上老美又提出了专门的M(Military)码,具体细节仍处于高度保密中,只知道速率为5.115 MHz,码长未知。北斗的定位精度目前还不如GPS。
无人车的车道线级绝对定位是个难题,无人车需要更高精度的厘米级定位。日本为解决这个问题,研发准天顶卫星系统(QZSS),在2010年发射了一颗卫星,2017年又陆续发射了3颗卫星,构成了三颗人造卫星透过时间转移完成全球定位系统区域性功能的卫星扩增系统,今年4月1日将正式商用,配合GPS系统,QZSS可以做到6厘米级定位。QZSS系统的L5信号频点也是采用1176.45MHz,而且采用的码速率与GPS在该频点的码速率一样,都是10.23MHz。意味着芯片厂商在原有支持GPS系统芯片上无需改动硬件,只需在软件处理上作更改就可以实现对Galileo、QZSS系统的兼容,相当于软件实现上需要多搜索几颗导航卫星。几乎不增加成本,而北斗系统是需要改硬件的,非常麻烦。因为日本国土面积小,4颗卫星就够了,如果换成中国或美国,可能需要35颗-40颗卫星。
国内大部分厂家都采用GPS RTK做绝对定位,不过RTK缺点也是很明显的。RTK确定整周模糊度的可靠性为95~99%,在稳定性方面不及全站仪,这是由于RTK较容易受卫星状况、天气状况、数据链传输状况影响的缘故。首先,GPS在中、低纬度地区每天总有两次盲区(中国一般都是在下午),每次20~30分钟,盲区时卫星几何图形结构强度低,RTK测量很难得到固定解。其次,白天中午,受电离层干扰大,共用卫星数少,因而初始化时间长甚至不能初始化,也就无法进行测量。根据实际经验,每天中午12点~13点,RTK测量很难得到固定解。再次,依赖GPS信号,在隧道内和高楼密集区无法使用。
Apollo的定位技术
先进的无人车方案肯定不能完全基于RTK,百度Apollo系统使用了激光雷达、RTK与IMU融合的方案,多种传感器融合加上一个误差状态卡尔曼滤波器使得定位精度可以达到5-10厘米,且具备高可靠性和鲁棒性,达到了全球顶级水平。市区允许最高时速超过每小时60公里。
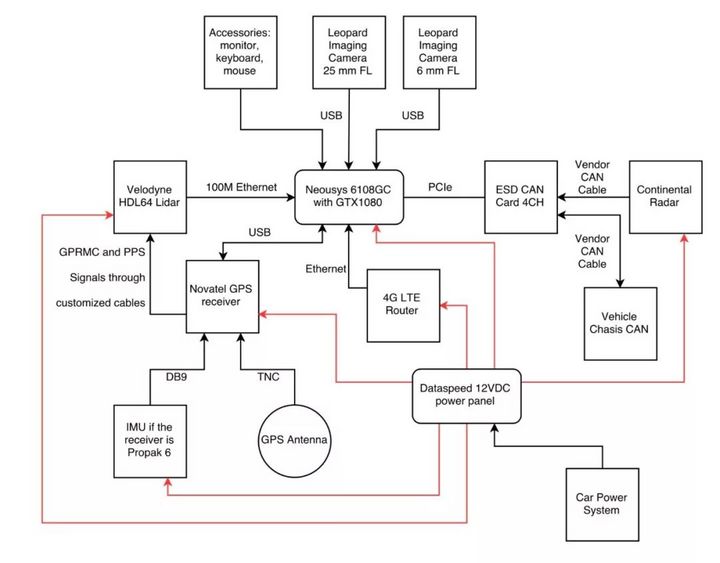
上图为百度Apollo自动驾驶传感器、计算单元、控制前的连接图,计算系统使用台湾Neousys Nuvo-6108GC工控机,这款工控机使用英特尔双至强E5-2658 V3 12核CPU。主要用来处理激光雷达云点和图像数据。
GPS定位和惯性测量单元方面,IMU 为NovAtel IMU-IGM-A1 ,GPS接收机为NovAtelProPak6。激光雷达使用的是Velodyne HDL-64E S3,通过以太网连接工控机,水平视野360°,垂直视野26.9°,水平角度分辨率为0.08°,距离精度小于2cm,可探测到120m的汽车或树木。视觉系统使用Leopard ImagingLI-USB30-AR023ZWDR with 3.0 case,通过USB连接到工控机。使用安森美的200万像素1080p传感器AR0230AT和AP0202 ISP。FOV为广角58度,有效距离大约60-70米。毫米波雷达采用的是Continental ARS408-21,连接至CAN卡。CAN卡为德国ESD CAN-PCIe/402-B4。
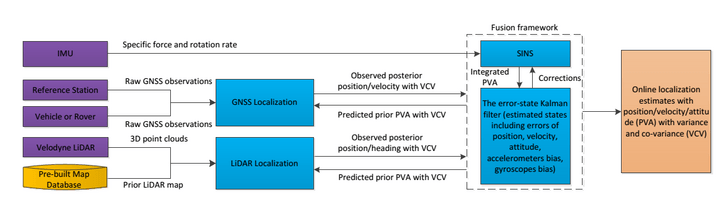
上图为百度无人车定位模块框架,融合了IMU、GNSS和激光雷达等传感器(紫色),以及一个预先制作好的定位地图(黄色)。最上层的是SINS系统,就是Strap-down InertialNavigation。捷联惯导系统是在平台式惯导系统基础上发展而来的,它是一种无框架系统,由三个速率陀螺、三个线加速度计和处理器组成。SINS使用IMU测量得到的加速度和角速度积分得到位置、速度、姿态等,在卡尔曼滤波器的传播阶段作为预测模型;相应地,卡尔曼滤波器会对IMU的加速度和角速度进行矫正,位置、速度和姿态等误差也反馈给SINS。RTK定位和激光雷达点云定位结果作为卡尔曼滤波器的量测更新。
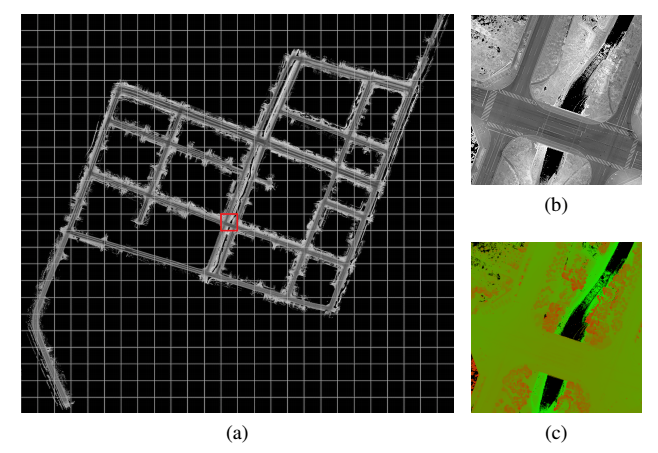
上图为百度的激光雷达点云定位地图。首先要提前制作一幅无人车将要行驶地区的激光雷达点云定位地图,包含有激光雷达强度成像图和高度分布图,这张图通常是地图厂家用测绘级激光雷达完成的。目前全球绝大多数厂家包括Waymo、福特、通用等都是如此。b为激光雷达反射强度成像图,c为高度分布图。这张图覆盖范围3.3*3.1平方公里。
激光点云定位算法描述如下:

表面上看高精度定位很复杂,实际计算中,耗费的运算资源并不算多,基于激光雷达的运算量远低于基于图像的运算量。这套系统在将来也可以用传统的汽车级SoC完成,如瑞萨的R-Car H3,恩智浦的I.MX8或S32A258C。成本有望大幅度降低。64线激光雷达也有望在未来由flash固态激光雷达取代,进而大幅度降低成本。
百度无人车定位团队的一篇关于多传感器融合定位的学术论文“Robust and Precise VehicleLocalization based on Multi-sensor Fusion in Diverse City Scenes”已被机器人顶级会议ICRA 2018录用,初稿可从arXiv上下载。
Apollo的感知技术
在 Apollo 中感知模块有以下几个职能:探测目标(是否有障碍物)、对目标分类(障碍物是什么)、语义分割 (在整帧画面中将障碍物分类渲染)、目标追踪 (障碍物追踪)。
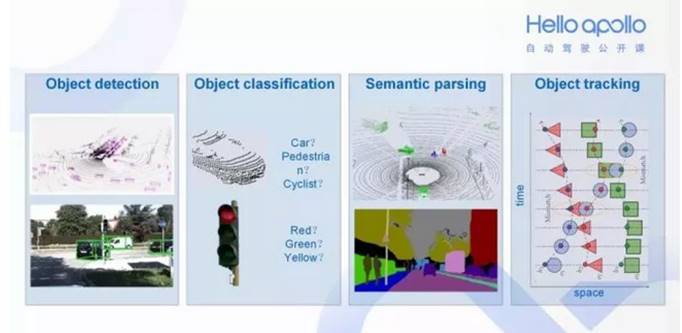
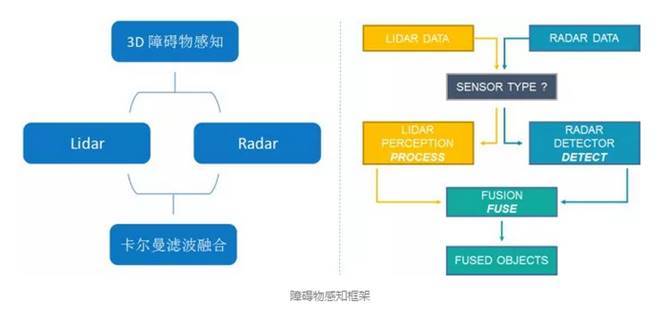
Apollo 2.0系统使用了多传感器融合的方式做环境感知,摄像头负责红绿灯的检测,毫米波雷达最大的作用是提供目标的运动速度,目标识别主要靠激光雷达完成的。
2016年10月,百度与清华联合发表了论文Multi-View 3D ObjectDetection Network for Autonomous Driving ,地址https://arxiv.org/pdf/1611.07759.pdf,论文以激光雷达与摄像头融合的方式做目标识别,不过在2017年5月百度发表的论文Vehicle Detection from 3DLidar Using Fully Convolutional Network,地址https://arxiv.org/pdf/1608.07916.pdf,这篇论文里放弃与摄像头融合。在2017年10月,加入毫米波雷达融合。
2017年11月,苹果发表论文,VoxelNet: End-to-EndLearning for Point Cloud Based 3D Object Detection,也只用激光雷达识别目标,并且与百度和清华Multi-View 3D ObjectDetection Network for Autonomous Driving做了对比,显示出单纯用激光雷达效果更好。究其原因,激光雷达数据处理速度比摄像头要快,时间同步很有难度,两者还需要坐标统一;其次是摄像头对光线太敏感,可靠性低,远距离尤其明显。百度在Apollo 2.0里使用了激光雷达与毫米波雷达融合的方案。
激光雷达物体识别最大的优点是可以完全排除光线的干扰,无论白天还是黑夜,无论是树影斑驳的林荫道,还是光线急剧变化的隧道出口,都没有问题。其次,激光雷达可以轻易获得深度信息,而对摄像头系统来说这非常困难。再次,激光雷达的有效距离远在摄像头之上,更远的有效距离等于加大了安全冗余。最后,激光雷达的3D云点与摄像头的2D图像,两者在做深度学习目标识别时,2D图像容易发生透视变形。简单地说透视变形指的是一个物体及其周围区域与标准镜头中看到的相比完全不同,由于远近特征的相对比例变化,发生了弯曲或变形。这是透镜的固有特性(凸透镜汇聚光线、凹透镜发散光线),所以无法消除,只能改善。而3D就不会有这个问题,所以3D图像的深度学习使用的神经网络可以更加简单一点。
另外,激光雷达也可以识别颜色和车道线。
无人车领域对目标图像的识别不仅仅是识别,还包括分割和追踪。分割就是用物体框框出目标。对于2D图像来说,只能用2D框分割出目标,而激光雷达图像则可以做到3D框,安全性更高。追踪则是预测出车辆或行人可能的运动轨迹。

很明显,3D的分割框要比2D的有价值的多,这也是Waymo和百度都用激光雷达识别车辆的原因之一。
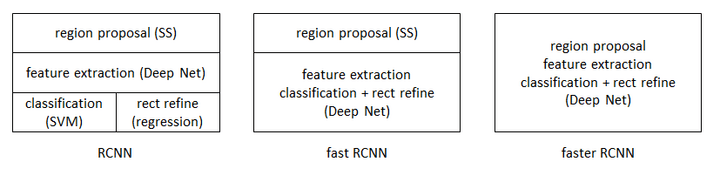
目标检测与识别领域早期用DPM。 2013年11月,目标检测领域公认的大神Ross Girshick推出R-CNN,2015年4月进化为Fast R-CNN,2015年6月进化为Faster R-CNN,成为今日目标检测与识别领域公认最好的方法,也是可以完全端对端地实现。
激光雷达的目标检测与识别也用FasterR-CNN。Faster R-CNN 从2015年底至今已经有接近两年了,但依旧还是ObjectDetection领域的主流框架之一,虽然后续推出了R-FCN,Mask R-CNN 等改进框架,但基本结构变化不大。同时不乏有SSD,YOLO等新作,但精度上依然以Faster R-CNN为最好。从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
图像语义分割可以说是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解,判断可行驶区域)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。图像是由许多像素组成,而「语义分割」顾名思义就是将像素按照图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。语义分割有时会是最难的一部分,因为这要用到NLP自然语言处理领域的技能,而大部分玩CNN的对NLP不甚了解。
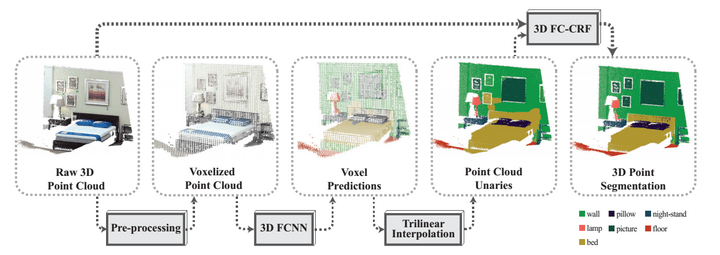
上图为斯坦福大学的激光雷达语义分割流程图,最后是用3D FC-CRF,也就是全连通条件随机场,另一种常用的方法是MRF,马尔科夫随机场。条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果。在中文分词、中文人名识别和歧义消解等任务中都有应用。
百度的语义分割主要是为了更好地理解交通场景,为行为决策提供依据。低成本的无人驾驶也可以用摄像头的2D图像做语义分割,为无人车找出可行驶区域,光线良好的情况下可以用这种低成本的方案。
2018CES展示的Apollo2.0无人车顶部除了激光雷达外,新增了两个摄像头,一个长焦、一个短焦,主要目的是为了识别道路上的红绿灯。
自动驾驶训练数据集
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。
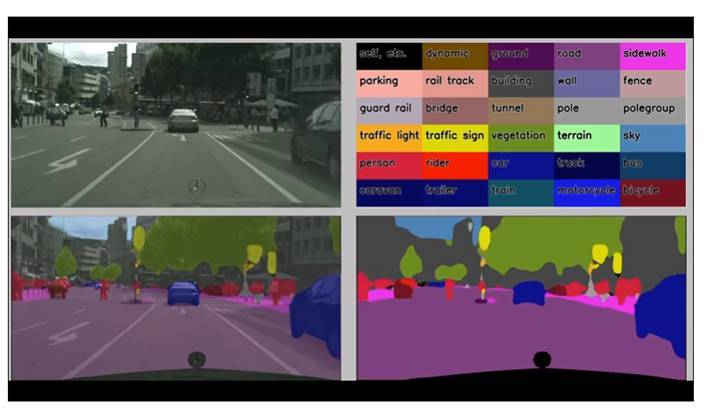
Cityscapes数据集则是由奔驰主推,提供无人驾驶环境下的图像分割数据集。用于评估视觉算法在城区场景语义理解方面的性能。Cityscapes包含50个城市不同场景、不同背景、不同季节的街景,提供5000张精细标注的图像、20000张粗略标注的图像、30类标注物体。
3月8日,百度正式开放ApolloScape大规模自动驾驶数据集。ApolloScape拥有比Cityscapes等同类数据集大10倍以上的数据量,包括感知、仿真场景、路网数据等数十万帧逐像素语义分割标注的高分辨率图像数据,进一步涵盖更复杂的环境、天气和交通状况等。ApolloScape数据集涵盖了更复杂的道路状况,比如单张图像中最高可达162辆交通工具或80名行人 ,同时开放数据集采用了逐像素语义分割标注的方式。
Kitti,Cityscapes和ApolloScape的数据实例对比
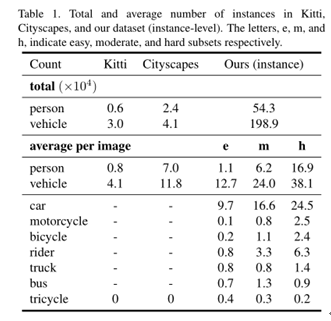
对我国传统车厂来说,自建训练数据集恐怕是最大的难题,与百度合作是最好的选择。
希望对你有帮助。
深度解析Apollo无人车感知和定位技术相关推荐
- 深度学习与无人车导论_深度学习导论
深度学习与无人车导论 改变游戏规则 图片的信誉归功于: https : //www.digitalocean.com/ 深度学习 已经成为许多新应用程序的主要驱动力,是时候真正了解为什么会这样了. 我 ...
- Apollo自动驾驶进阶课(4)——Apollo无人车定位技术
1.无人车自定位系统 1.1自定位系统 无人车的自动定位系统:相对一个坐标系,确定无人车的位置和姿态. 这个坐标系可以是一个局部的坐标系,也可以是一个全局的坐标系,比如全球坐标系,可以知道一个很精确的 ...
- 百度Apollo无人车能力降维释放,打造智能汽车可以像拼乐高
像搭积木一样在汽车中实现智能驾驶,是一种怎样的体验? 现在,只要你想,就可以试着操作起来了. 因为在第二届百度Apollo生态大会现场,百度Apollo全面展示了其在智能交通.智能汽车和自动驾驶领域的 ...
- 百度Apollo无人车能力降维释放,打造智能汽车现在可以像拼乐高
鱼羊 发自 凹非寺 量子位 报道 | 公众号 QbitAI 像搭积木一样在汽车中实现智能驾驶,是一种怎样的体验? 现在,只要你想,就可以试着操作起来了. 因为在第二届百度Apollo生态大会现场,百度 ...
- 文因互联鲍捷:深度解析知识图谱发展关键阶段及技术脉络 | 干货推荐
分享嘉宾 | 鲍捷(文因互联CEO) 出品 | AI科技大本营(公众号ID:rgznai100) 知识图谱是人工智能三大分支之一--符号主义--在新时期主要的落地技术方式.该技术虽然在 2012 年才 ...
- 完整的连接器设计手册_深度解析特斯拉的电池快充连接器技术|附视频
推荐:GSAuto联盟|三电技术专家委员会,初期仅对主机厂.Tirl1等公司新能源汽车三电研发管理制造方面人员.大学及科研机构等新能源汽车三电研究人员,现已招募480+人,主要分布在50+主机厂.50 ...
- 鲍捷 | 深度解析知识图谱发展关键阶段及技术脉络
本文转载自公众号: AI科技大本营 . 分享嘉宾 | 鲍捷(文因互联CEO) 出品 | AI科技大本营(公众号ID:rgznai100) 知识图谱是人工智能三大分支之一--符号主义--在新时期主要的落 ...
- 深度解析MegEngine亚线性显存优化技术
基于梯度检查点的亚线性显存优化方法[1]由于较高的计算/显存性价比受到关注.MegEngine经过工程扩展和优化,发展出一套行之有效的加强版亚线性显存优化技术,既可在计算存储资源受限的条件下,轻松训练 ...
- 深度学习 占用gpu内存 使用率为0_深度解析MegEngine亚线性显存优化技术
作者 | 旷视研究院 编辑 | Linda 基于梯度检查点的亚线性显存优化方法 [1] 由于较高的计算 / 显存性价比受到关注.MegEngine 经过工程扩展和优化,发展出一套行之有效的加强版亚线性 ...
最新文章
- objective-c 面试题
- StackOverflow 上面最流行的 7 个 Java 问题!
- 如何用python画圆形的代码-python – 如何快速绘制数千个圆圈?
- 从Q4财报,看有道如何实现从在线教育“迷途”中脱身?
- Django 3.2.5博客开发教程:用Admin管理后台管理数据
- RTT设备与驱动之PIN设备
- C/C++之内存对齐
- oracle数据库时分秒格式_Oracle如何输出指定格式的日期时间数据呢?
- 听歌也能倍速了!网易云音乐PM怎么想的?
- android背景色显示圆形,android – 如何使文本视图形状的圆形和基于条件设置不同的背景颜色...
- 1042 Shuffling Machine
- 服务器与交换机对接链路聚合mode=0模式传输带宽慢问题
- Java后台开发一:环境搭建
- QEMU 安装与使用
- 互联网最新创新创业项目
- Exiting intel PXE ROM.Operating system not found
- 程序员谈谈返利机器人
- “燕云十六将”之Lion李哲
- 第四章 网络层(TCP/IP称网际层)
- pip安装librosa或audioread长时间无响应